







一、信息检索的核心任务:
从文档集合中找到与查询最相关的文档。
二、信息检索的核心问题:
-
如何表示文档和查询(例如,使用词袋模型、TF-IDF、嵌入等)。
-
如何计算文档与查询的相关性(例如,通过 RSV(dj,q), Retrieval Status Value)。
-
如何根据相关性对文档进行排序,返回最相关的结果。
三、检索状态值(RSV)从二元值扩展为连续值:
二元值:
布尔模型:
-
词汇表:M=3词项,"A" (t1=100),"B" (t2=010),"C" (t3=001)。
-
查询:q=A∧(B∨¬C)。
-
查询转换为合取范式:
q=(A∧B∧C)∨(A∧B∧¬C)∨(A∧¬B∧¬C)用向量表示为:
q=111∨110∨100 -
匹配文档:任何形式为 111、110 或 100 的文档都匹配查询。例如:
-
"AAA"(111)匹配。
-
"AAB"(110)匹配。
-
"CCC"(001)不匹配。
-
连续值:
词袋模型(Bag of words):
词袋模型是一种将文本表示为词项(terms)集合的方法,忽略词序和结构(如段落、标题等),只关注词项的出现频率。
词频(Term Frequency, TF):
词频衡量一个词项在文档中出现的频率,假设词项出现次数越多,它对文档的代表性越强。
term frequency,tf:
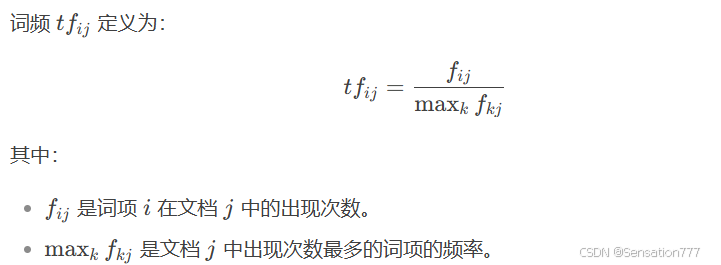
逆文档频率(Inverse Document Frequency, IDF)
逆文档频率衡量一个词项在整个文档集合中的区分能力。如果一个词项出现在很多文档中,它的区分能力较低。
Inverse document frequency, idf:

TF-IDF 加权方案:
TF-IDF 是一种常用的加权方案,结合了词频(TF)和逆文档频率(IDF),用于衡量词项在文档中的重要性。


-
每行对应一个词项。M 是词汇表中词项的总数。
-
每列对应一个文档。
-
元素 wij 表示词项 i 在文档 j 中的 TF-IDF 权重。
TF-IDF 的应用
-
文档嵌入:TF-IDF 将文档表示为向量,可以用于计算文档之间的相似度(如余弦相似度)。
-
词项嵌入:TF-IDF 也可以将词项表示为向量,用于分析词项在文档集合中的分布。
学习资源来源:日内瓦大学计算机系 Stéphane Marchand-Maillet 教授课程《Information Retrieval》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









