







信息检索相关背景、TF-IDF ,参考之前发布的文章:【Information Retrieval】信息检索的任务与方法-CSDN博客
本期开始介绍信息检索的基础模型——向量空间检索模型
一、嵌入(Embedding)
含义:将非结构化的数据(如文本、图像、音频等)映射成结构化的向量表示,通常是低维、连续向量。
目的:通过Embedding将数据的关键特征抽象为向量形式,结构化的向量便于计算机处理分析。
在文本检索模型中的应用:
- 向量空间检索模型:基于文本嵌入的余弦相似度进行几何计算
- 二元独立检索模型:相关性的概率估计(如:BM25模型)
二、向量空间检索模型(Vector Space Retrieval Model)
方式:将文档和查询表示为向量,利用向量之间的相似性来进行检索。
在二进制嵌入空间中,文档和查询的表示是二进制的(0或1):
wij:词项 i 在文档 j 中的权重 wij

相似性计算简化为共同术语的数量。
在连续嵌入空间中:
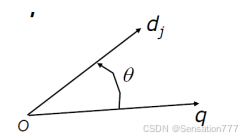
1. 常使用余弦相似度(Cosine Similarity)作为检索状态值RSV:
计算文档嵌入与查询嵌入之间夹角的余弦值来衡量它们的相似性,即衡量两个向量在方向上的相似性,而忽略它们的长度。通过归一化向量的长度,使得相似性度量不受文档长度的影响。
![]()
公式中的分子是向量的点积,分母是向量的范数的乘积。
对于两个相同维度的向量 a=[a1,a2,…,an] 和 b=[b1,b2,…,bn],它们的点积定义为:
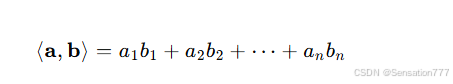
向量的范数(长度,Norm):
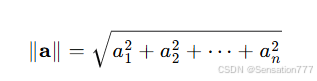
余弦相似度的值范围在 -1 到 1 之间:
-
当两个向量方向完全相同时,余弦相似度为 1。
-
当两个向量方向完全相反时,余弦相似度为 -1。
-
当两个向量正交(垂直)时,余弦相似度为 0。
2. 其他度量方法:如Jaccard相似系数适合短文本,Dice相似系数平衡稀疏数据。
学习资源来源:日内瓦大学计算机系 Stéphane Marchand-Maillet 教授课程《Information Retrieval》

















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









