






一、线性分类与感知机
线性回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
在机器学习领域中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。 但不是所有的预测都是回归问题。
线性模型
一个实际的例子: 我们希望根据房屋的面积和房龄来估算房屋价格。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄,称为训练数据集或训练集。 每行数据(比如一次房屋交易相对应的数据)称为样本, 也可以称为数据样本。 我们把试图预测的目标(比如预测房屋价格)称为标签或目标。 预测所依据的自变量(面积和房龄)称为特征或协变量。
当我们的输入包含y个特征时,我们将预测结果y^ 表示为
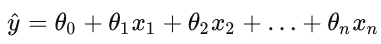
将所有特征放到向量x中, 并将所有权重放到向量w中, 可以简洁地表达模型:

损失函数
在我们开始考虑如何用模型拟合(fit)数据之前,我们需要确定一个拟合程度的度量。 损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。 回归问题中最常用的损失函数是平方误差函数:

目标是找到一个超参数θ使得J(θ)最小,即求解minJ(θ)。令

则
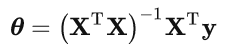
实际应用中,会遇到 XTX 不可逆,或者 J(θ) 不可导的情况,因此不能依赖于求解析解的方法。
线性分类
线性分类就是对线性回归的输出增加了一个激活函数。线性回归的输出是一个具体数值(没有特定的范围);线性分类的输出值是某一类型,或者属于某一类型的概率(0-1之间的数)。对线性回归的输出值做变换:

其中
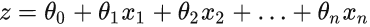
该函数称为Sigmoid函数。同样构造损失函数:
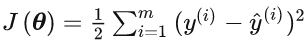
目标是使其最小化。由于上述和线性回归方程一致,因此又被称为Softmax回归。
梯度下降
即使在我们无法得到解析解的情况下,我们仍然可以有效地训练模型。 在许多任务上,那些难以优化的模型效果要更好。 因此,弄清楚如何训练这些难以优化的模型是非常重要的。梯度下降(gradient descent), 这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。构造迭代序列
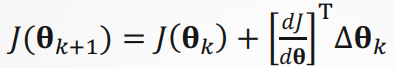
令
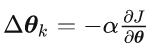
则必然有
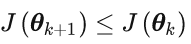
这就是梯度下降法。
二、神经网络模型基础
单神经元网络

图中的模型可以描述为
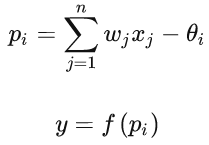
其中 f(x) 称为激活函数,常见的激活函数有:对称和非对称Sigmoid函数、ReLU函数等。
BP网络
误差反向传播神经网络简称为BP网络(Back Propagation),是一种单向传播的多层前向网络。误差反向传播的BP算法简称BP算法,其基本思想是最小二乘法。它采用梯度搜索技术,以期使网络的实际输出值预期输出值的误差均方值最小。
BP网络是一种多层网络,包含输入层、隐含层(可多层)、输出层;权值采用梯度下降法进行调节;神经元激活函数为Sigmoid函数;学习算法由正向传播和反向传播组成;层与层单向连接,信息的传播是双向的。单隐含层的BP网络结构如图所示:
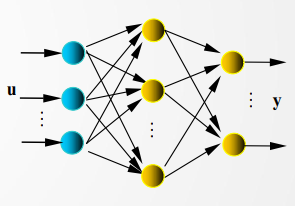
BP网络的前向传播过程,网络输入,即输入层的输入:

隐含层的输出:

输出层的输出,即网络的输出:
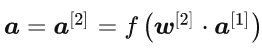
BP网络的训练是使对每一个输入样本, 调整网络参数, 使输出均方误差最小化。 这是一个最优化问题。选取损失函数

设初始权值为 w0 ,k时刻权值为wk,使用Taylor级数展开:

令
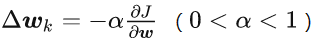
利用梯度下降方法迭代,使损失函数不断收敛到最小。
权值正则化
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting), 用于对抗过拟合的技术称为正则化(regularization)。给定一些训练数据和一种网络结构,很多组权重值(即很多模型)都可以解释这些数据。简单的模型比复杂模型更不容易过拟合。加入正则化项

可计算
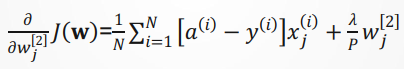
三、性能优化
动量法
SGD问题:病态曲率 图为损失函数轮廓。在进入以蓝色 标记的山沟状区域之前随机开始。 颜色实际上表示损失函数在特定点 处的值有多大,红色表示最大值, 蓝色表示最小值。我们想要达到最 小值点,为此但需要我们穿过山沟 。这个区域就是所谓的病态曲率。

梯度下降沿着山沟的山脊反 弹,向极小的方向移动较慢 。如果把原始的 SGD 想象成一个纸团在重力作用向下滚动,由 于质量小受到山壁弹力的干扰大,导致来回震荡;或者在鞍点 处因为质量小速度很快减为 0,导致无法离开这块平地。 动量方法相当于把纸团换成了铁球;不容易受到外力的干扰, 轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能 离开平地。
自适应梯度算法
参数自适应变化:具有较大偏导的参数相应有一个较大的学习 率,而具有小偏导的参数则对应一个较小的学习率 。具体来说,每个参数的学习率会缩放各参数反比于其历史梯度 平方值总和的平方根。
学习率是单调递减的,训练后期学习率过小会导致训练困难, 甚至提前结束 。需要设置一个全局的初始学习率。
RMSProp算法
RMSprop的思想是,对于梯度震动较大的项,在下降时,减小其下降速度;对于震动幅度小的项,在下降时,加速其下降速度。在应用过程中,可以利用该算法来解决AdaGrad 方法中学习率过度衰减的问题。通过使用指数加权平均计算得到Sdw, Sdb,因此可以快速收敛,同时,RMSProp还加入了超参数 𝜌控制衰减速率。
Adam算法
Adam 在 RMSProp 方法的基础上更进一步: 除了加入历史梯度平方的指数衰减平均(𝑟)外, 还保留了历史梯度的指数衰减平均(𝑠),相当于动量。 Adam 行为就像一个带有摩擦力的小球,在误差面上倾向于平 坦的极小值。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









