







前言
最近工作中接触了多表关联,有所感悟,想了很久,在这里将自己理解记录下来。不管对错,形成观点了,等以后再推翻,这看起来是件很有意思的事情。对于多表关联我非常的畏惧,而之前的工作也就是改改bug,在写sql碰到不多,碰到的也是非常简单。这次换了一个新的环境,对写sql要求很高,我意识到有必要先建立sql这方面自己的认识了。看起来这些总结不全面,描述存在错误,可意会不可言传,还不如多实践。但有自己观点即使错误的,心中也安
正文
一张表A 数量为n,表B数量为m,笛卡尔积以后数量变成了 n * m,这n*m的数据肯定不是期望中的。两张关联表需要关联,就存在两张表对应的column,这些column可能是一个,可能是多个,不论多少个,一个有一个的期望需求,多个有多个的期望需求,问问自己,做一个关联,这个范围得到的数据,是不是自己想要的,不想要就再用另外的对应column再次剔除,缩小数据的范围。反正一句话,笛卡尔积得到的结果是杂乱的,当你剔除过数据了,这些数据就满足某种需求了,我们要做的就是确认这些是不是自己期望结果
观点一、多表查询就是笛卡尔积,然后剔除毫无联系的数据
例子
两张表
项目表
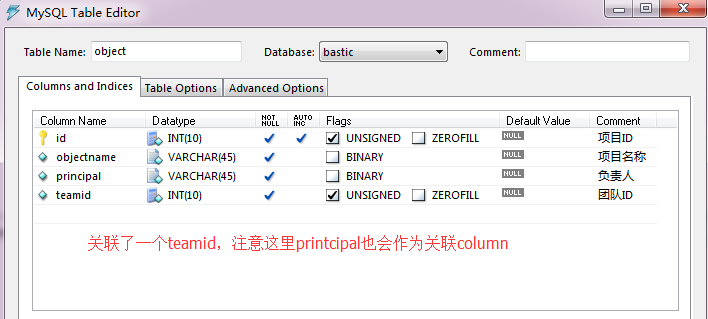
职工表
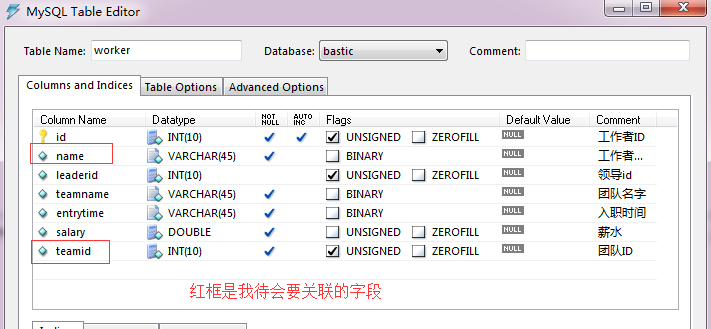
我现在要做的就是对这两张表做关联
很疑惑,这两张表好像不是一对多,有点多对多的味道,可以关联吗?得到的结果是什么? 理论上有对应关系,都可以关联,只是结果能不能符合期望的,就另作处理了
SELECT obj.*,worker.*
FROM object obj, worker worker
WHERE obj.teamid = worker.teamid对笛卡尔积做第一步剔除,obj.teamid = worker.teamid 做剔除什么意思呢?
1、obj 一行数据与worker一行数据连接,形成新的一行,可以理解为,一个项目所执行的团队下面的所有员工。
现在的需求是:一张页面显示项目信息,现在项目信息表里面字段信息太少了,要求我们关联其它表,查询这个项目所执行团队的人数。
那么上面的查询可以满足需求吗? 答案是否定的,我们要求页面每一行数据代表一个项目,这一行后面一些字段只是扩展的信息。而上面查询出来 项目信息+A团队B成员小张为一行,项目信息+A团队C成员为一行,这些数据放到页面上,那么那个页面需要的信息完全变了。如何解决?
观点二、分组、子查询在多表关联中非常有用。子查询可以将看起来与匹配表毫无关系的表与一些表先关联,得到结果集,然后在这些结果集中存在一个与匹配表有对应关系的字段,再进行笛卡尔积,作为剔除条件。 分组可以将关联,并剔除毫无关系的数据后,多出来的数据合并,使最后的结果集数量与匹配表一致
我把sql写了一下
SELECT obj.*,employee.nums
FROM object obj
left join
(select teamid, count(*) nums
from worker worker group by teamid
) employee on employee.teamid = obj.teamid这里需要一个子查询,取到精心设计得到的结果集,通过分组,我们可以将后面因为teamid导致的fork,合在一起,这样就形成了一对一的关系。妈妈再也不担心通过关联得到的数据莫名其妙,而且数量和匹配表(页面要查的数据的表,叫什么没关系,名字只是一个代号)
不一致了(本来匹配表期望有100条,关联一下1000条了,这1000条不能说错,只是不是这里期望中的数据)。
还好上面要求查询的是人数,可以通过分组来解决。如果查询所有成员信息,那么我看是想多了,一行数据代表是项目,你能在一行中fork来存放各个成员信息吗? 这是不可能的。那么何必纠结呢,我们转换一下,将worker作为匹配表,一行表示员工的信息 + 扩展就是这个员工所作的这个项目的信息,这里注意的是这个项目是这个员工所做的唯一一个项目,如果这个员工做过多个项目,又回到上面的情况了,又有fork了。就好比一条直线的路,走着走着,就出现分叉路口了(真有fork,那么只能用分组来合并了,两表形成多对一,一对一的关系)
观点三:需求要求页面每一行代表表A的每一行,后面扩展一些信息,那么以这表A作为匹配表,后面的扩展表要求与表A形成一对多,一对一关系,避免分叉,避免不免就分组,变成一对多,一对一
2、上面也可以理解为:worker表每一行数据与Object表每一行关联一起 意思是:每一个员工所在的团队所做过的所有的项目。其实查询结果都是一样的,我在做关联的时候脑子里从第一张表第一行与第二张表的每一行连在一起,成为新的一行。然后解读它的意思。含义不一样,但是结果是一样的
再次对下面sql改造
SELECT obj.*,worker.*
FROM object obj, worker worker
WHERE obj.teamid = worker.teamid一行关联数据这里理解成:一个项目所执行团队的一个员工的信息
第一行是这个项目执行团队A员工的信息,第二行是这个项目执行团队B员工的信息,也就是所有项目所执行团队的所有成员信息,这个范围符合需求吗?
需求:列出所有项目信息,扩展列出项目经理信息
那么我们还需要将范围缩小
观点四、关联表剔除毫无关系的数据以后,其实能满足某种需求了,剩下的就是范围缩小的事情了,让它适合当前的需求
SELECT obj.*,worker.*
FROM object obj, worker worker
WHERE obj.teamid = worker.teamid
and obj.principal = worker.name列出了每一个项目信息和这个项目的负责人信息
下面扩展一下,有如下的任务表
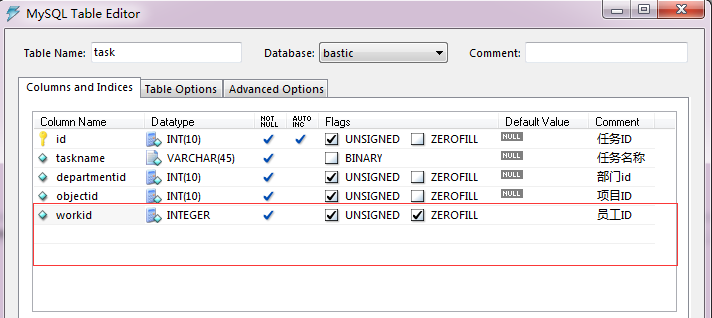
在上面关联查询继续关联这个任务表,比如如下的需求
需求:找出项目信息,后面扩展字段有:这个项目所在团队所有成员的数量,所有的任务
下面是之前写的sql
SELECT obj.*,employee.nums
FROM object obj
left join
(select teamid, count(*) nums
from worker worker group by teamid
) employee on employee.teamid = obj.teamid可以将上面的结果集,想成存放到临时表temp中,现在temp需要和task表做关联,task与temp是多对一的关系,一条temp数据面临多个分叉路口,所以这里将需求改成显示任务数量,这样就可以用分组,将分叉路口合在一起
观点五、多表关联是可插拔式的,只要有几张表存在联系即可
现在我们接上一个子查询,很简单,只要跟上一个left on + 子查询 + 剔除不符合需求的数据
先写第三个子查询
left join (
select workid ,count(*) counts
from task
group by workid
) tk on tk.workid = employee.id发现分组原因,我只能包含task分组字段workid字段,那么我这个结果集,拿什么与上面的temp中的数据做关联? 发现没有可剔除的条件 temp一行的字段有object所有字段 + teamid + nums ,根本就没有workid
解决,没办法,这个表是我之前胡乱设计的,只能往object表填字段了
我在object表添加了如下字段
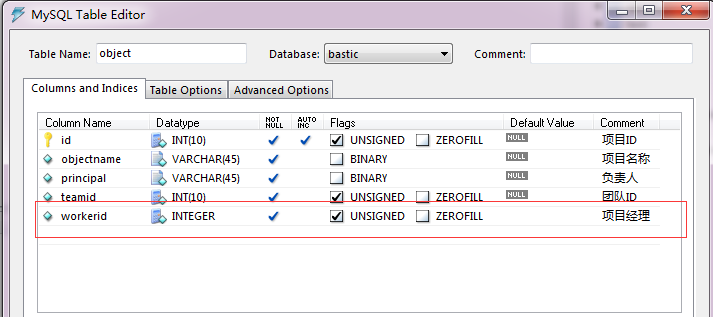
需求更改:
找出项目信息,后面扩展字段有:这个项目所在团队所有成员的数量,以及这个项目的项目经理所有的任务
sql如下
SELECT obj.*,employee.nums,tk.tk.counts
FROM object obj
left join
(select teamid, count(*) nums
from worker worker group by teamid
) employee on employee.teamid = obj.teamid
left join (
select workid ,count(*) counts
from task
group by workid
) tk on tk.workid = obj.workerid最后总结一下:多张表关联,可以将每个表每一行数据连在一起,想想会不会中途出现交叉路口,这些交叉路口导致数量结果增多是不是满足需求? 不满足,能不能通过分组来合并? 多思考
观点六、多表关联,有数据数量不断增多的可能,要非常明确,一条数据代表的是什么
胡言乱语一番,但愿以后回过头查阅能看懂,一个程序员描述问题这个能力需要的,连话都讲不清楚,可知逻辑性多糟糕,努力克服吧















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









