Spark
4. 环境搭建-Standalone HA
- Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。

4.1 高可用HA
- 如何解决这个单点故障的问题,Spark提供了两种方案:
- 基于文件系统的单点恢复(Single-Node Recovery with Local File System)–只能用于开发或测试环境。
- 基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)–可以用于生产环境。
- ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。

4.2 基于Zookeeper实现HA

4.3 测试运行
4.3.1 Wordcount测试
resultRDD = sc.textFile("hdfs://node1:8020/pydata/words.txt") \
.flatMap(lambda line: line.split(" ")) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: a + b)
resultRDD.collect()

- 停止集群:/export/server/spark/sbin/stop-all.sh
4.3.2 关闭Master验证HA
- 关闭活跃的Master进程, 等待30秒左右
- 查看standby是否接管集群.
4.4 总结
- StandAlone HA的原理
- 基于Zookeeper做状态的维护, 开启多个Master进程, 一个作为活跃,其它的作为备份,当活跃进程宕机,备份Master进行接管.
- 为什么需要Zookeeper?
- 分布式进程是分布在多个服务器上的, 状态之间的同步需要协调,比如谁是master,谁是worker.谁成了master后要通知worker等, 这些需要中心化协调器Zookeeper来进行状态统一协调.
5. 环境搭建-Spark on YARN(重点)
- 按照前面环境部署中所学习的, 如果我们想要一个稳定的生产Spark环境, 那么最优的选择就是构建:HA StandAlone集群.
- 不过在企业中, 服务器的资源总是紧张的, 许多企业不管做什么业务,都基本上会有Hadoop集群. 也就是会有YARN集群.
- 对于企业来说,在已有YARN集群的前提下在单独准备Spark StandAlone集群,对资源的利用就不高. 所以, 在企业中,多数场景下,会将Spark运行到YARN集群中.
- YARN本身是一个资源调度框架, 负责对运行在内部的计算框架进行资源调度管理.
- 作为典型的计算框架, Spark本身也是直接运行在YARN中, 并接受YARN的调度的.
- 所以, 对于Spark On YARN, 无需部署Spark集群, 只要找一台服务器, 充当Spark的客户端, 即可提交任务到YARN集群中运行.
5.1 SparkOnYarn本质
- Spark On Yarn的本质?
- Master角色由YARN的ResourceManager担任.
- Worker角色由YARN的NodeManager担任.
- Driver角色运行在YARN容器内 或 提交任务的客户端进程中
- 真正干活的Executor运行在YARN提供的容器内
- Spark On Yarn需要啥?
- 需要Yarn集群:已经安装了
- 需要Spark客户端工具, 比如spark-submit, 可以将Spark程序提交到YARN中
- 需要被提交的代码程序:,如spark/examples/src/main/python/pi.py此示例程序,或我们后续自己开发的Spark任务

5.2 配置spark on yarn环境
5.2.1 部署
- 确保:
- HADOOP_CONF_DIR
- YARN_CONF_DIR
- 在spark-env.sh 以及 环境变量配置文件中即可
5.2.2 连接到YARN中
bin/pyspark --master yarn --deploy-mode client|cluster
bin/spark-shell --master yarn --deploy-mode client|cluster
bin/spark-submit --master yarn --deploy-mode client|cluster /xxx/xxx/xxx.py 参数
5.3 部署模式DeployMode
- Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式.
- 这两种模式的区别就是Driver运行的位置.
- Cluster模式即:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
- Client模式即:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
5.3.1 Cluster模式
- 如图, 此为Cluster模式
- Driver运行在容器内部

5.3.2 Client模式
- 如图, 此为Client模式
- Driver运行在客户端程序进程中(以spark-submit为例)

5.3.3 两种模式的区别

5.3.4 client 模式测试
假设运行圆周率PI程序,采用client模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
${SPARK_HOME}/examples/src/main/python/pi.py \
10

5.3.5 cluster 模式测试
假设运行圆周率PI程序,采用cluster模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
${SPARK_HOME}/examples/src/main/python/pi.py \
10

5.4 Spark On Yarn两种模式总结
- Client模式和Cluster模式最最本质的区别是:Driver程序运行在哪里。
- Client模式:学习测试时使用,生产不推荐(要用也可以,性能略低,稳定性略低)
- Driver运行在Client上,和集群的通信成本高
- Driver输出结果会在客户端显示
- Cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中,和集群的通信成本低
- Driver输出结果不能在客户端显示
- 该模式下Driver运行ApplicattionMaster这个节点上,由Yarn管理,如果出现问题,yarn会重启 ApplicattionMaster(Driver)
5.5 扩展阅读:两种模式详细流程

- 具体流程步骤如下:
1)、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3)、ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
5)、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。

- 具体流程步骤如下:
1)、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
3)、Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册;
5)、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
5.6 总结
- SparkOnYarn本质?
- Master由ResourceManager代替
- Worker由NodeManager代替
- Driver可以运行在容器内(Cluster模式)或客户端进程中(Client模式)
- Executor全部运行在YARN提供的容器内
- Why Spark On YARN?
- 提高资源利用率, 在已有YARN的场景下让Spark收到YARN的调度可以更好的管控
- 资源提高利用率并方便管理
6. PySpark库
6.1 框架 VS 类库

6.2 什么是PySpark
- 我们前面使用过bin/pyspark 程序, 要注意, 这个只是一个应用程序, 提供一个Python解释器执行环境来运行Spark任务
- 我们现在说的PySpark, 指的是Python的运行类库, 是可以在Python代码中:import pyspark
- PySpark 是Spark官方提供的一个Python类库, 内置了完全的Spark API, 可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行.
- 下图是,PySpark类库和标准Spark框架的简单对比

6.3 Anaconda的安装
6.4 PySpark安装
- PySpark是Python标准类库, 可以通过Python自带的pip程序进行安装
或者Anaconda的库安装(conda) - 在合适的虚拟环境下(使用pyspark这个虚拟环境), 执行如下命令即可安装:
- pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
- 或者
- conda install pyspark
- 推荐使用pip
6.5 总结
- PySpark是什么?和bin/pyspark 程序有何区别?
- PySpark是一个Python的类库, 提供Spark的操作API
- bin/pyspark 是一个交互式的程序,可以提供交互式编程并执行Spark计算
- 本课程的Python运行环境由什么来提供?
- 由Anaconda提供,并使用虚拟环境, 环境名称叫做: pyspark
7. 本机开发环境搭建
7.1 本机PySpark环境配置
- Anaconda和PySpark安装

7.2 PyCharm配置Python解释器
7.2.1 配置本地解释器
- 创建PythonProject工程需要设置Python解析器 ,然后点击创建即可

- 如果没有找到conda虚拟环境的解释器,可以:

7.2.2 配置远程SSH Linux解释器
- 刚刚,配置了本地的Python(基于conda虚拟环境)的解释器, 现在我们来配置Linux远程的解释器.
- PySpark支持在Windows上执行,但是会有性能问题以及一些小bug, 在Linux上执行是完美和高效的.
- 所以, 我们也可以配置好Linux上的远程解释器, 来运行Python Spark代码.
- 设置远程SSH python pySpark 环境

- 添加新的远程连接

- 设置虚拟机Python环境路径

7.3 应用入口:SparkContext
- Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
- 第一步、创建SparkConf对象
- 设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
- 第二步、基于SparkConf对象,创建SparkContext对象
- 文档:http://spark.apache.org/docs/3.1.2/rdd-programming-guide.html
7.4 WordCount代码实战
- 本地准备文件word.txt
- hello you Spark Flink
- hello me hello she Spark
- PySpark代码
from pyspark import SparkContext, SparkConf
import os
os.environ['SPARK_HOME'] = '/export/servers/spark'
if __name__ == '__main__':
print('PySpark First Program')
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext(conf=conf)
wordsRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter01_3.8/data/word.txt")
flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" "))
mapRDD = flatMapRDD.map(lambda x: (x, 1))
resultRDD = mapRDD.reduceByKey(lambda a, b: a + b)
res_rdd_col2 = resultRDD.collect()
for line in res_rdd_col2:
print(line)
resultRDD.saveAsTextFile("file:///export/pyfolder1/pyspark-chapter01_3.8/data/output1/")
print('停止 PySpark SparkSession 对象')
sc.stop()
- 原理分析

- 切换到远程SSH 解释器执行(在Linux系统上执行)
- 要注意, 远程解释器,本质上是在服务器上执行, 那么读取的文件,也应该是服务器上的文件路径.
7.5 代码结果解析
- 执行结果如下:

7.6 从HDFS读取数据
7.6.1 上传数据到HDFS中:
hdfs dfs -put word.txt /input/words.txt
hdfs dfs -ls /input

7.6.2 需要调整的代码:
wordsRDD = sc.textFile("hdfs://node1:8020/pydata/")
resultRDD.saveAsTextFile("hdfs://node1:8020/pydata/output1/")
print('停止 PySpark SparkSession 对象')
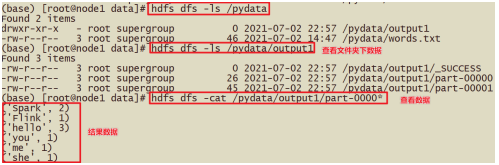
- hdfs dfs -cat /output/output1/*
7.7 提交代码到集群执行
- 现在将代码提交到YARN集群进行测试.
- 提交集群对代码:
- setMaster部分进行删除
- 因为提交到集群可以通过客户端工具的参数指定master, 比如spark-submit工具.
- 所以,我们不在代码中固定master的设置, 不然客户端工具参数无效, 代码的优先级是最高的.
- PySpark程序将Python代码以及数据部分上传到centos集群node1机器上,执行spark-submit就可以执行该任务。
- bin/spark-submit --master local[2] --name wordcount01 /export/pyfolder1/pyspark-chapter01_3.8/main/_03FirstPySparkSubmit.py file:///export/pyfolder1/pyspark-chapter01_3.8/data/word.txt


7.8 总结
- Python语言开发Spark程序步骤?
- 主要是获取SparkContext对象,基于SparkContext对象作为执行环境入口
- 如何提交Spark应用?
- 将程序代码上传到服务器上, 通过spark-submit客户端工具进行提交
8. 分布式代码执行分析
8.1 Spark 集群角色回顾(以YARN为例)

8.2 分布式代码执行分析
- Spark Application应用程序运行时,无论client还是cluster部署模式DeployMode,当Driver Program和Executors
- 启动完成以后,就要开始执行应用程序中MAIN函数的代码,以词频统计WordCount程序为例剖析讲解。

- 第一、构建SparkContex对象和关闭SparkContext资源,都是在Driver Program中执行,上图中①和③都是,如下图所示:

- 第二、上图中②的加载数据【A】、处理数据【B】和输出数据【C】代码,都在Executors上执行,从WEB UI监控页面可以看到此Job(RDD#action触发一个Job)对应DAG图,如下所示:

- 所以对于刚刚的WordCount代码,简单分析后得知:
- SparkContext对象的构建 以及 Spark程序的退出, 由 Driver 负责执行
- 具体的数据处理步骤, 由Executor在执行.
- 其实简单来说就是:
- 非数据处理的部分由Driver工作
- 数据处理的部分(干活)由Executor工作
- 要知道: Executor不仅仅是一个, 视集群规模,Executor的数量可以是很多的.
- 那么在这里一定要有一个概念: 代码中的数据处理部分,是由非常多的服务器(Executor)执行的.
- 这也是分布式代码执行的概念.
8.3 Python On Spark 执行原理
- PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序,其运行时架构如下图所示。


8.4 总结
- 分布式代码执行的重要特征是什么?
- 代码在集群上运行, 是被分布式运行的.
- 在Spark中, 非任务处理部分由Driver执行(非RDD代码)
- 任务处理部分由Executor执行(RDD代码).
- Executor的数量可以很多,所以任务的计算是分布式在运行的.
- 简述PySpark的架构体系
- Python On Spark Driver端由JVM执行, Executor端由JVM做命令转发, 底层由Python解释器进行工作
























 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











