






一、引言
爬虫技术是指利用程序自动获取互联网上的信息的一种技术。通常,爬虫会按照预先设定的规则,自动地访问网页、抓取数据,并将数据保存下来以供后续分析或其他用途。爬虫技术在网络搜索引擎、数据挖掘、信息监测等领域得到广泛应用。
二、如何工作?
- 请求网页:爬虫首先会向目标网站发送HTTP请求,请求特定的页面。
- 获取内容:一旦接收到响应,爬虫会解析HTML页面,并提取其中的信息,如文本、图片、链接等。
- 处理数据:爬虫会对获取的数据进行处理和存储,可能包括数据清洗、结构化等操作。
- 遍历链接:爬虫可能会根据设定的规则,继续访问页面上的链接,形成一个链式抓取的过程。
三、主要应用领域
- 搜索引擎:搜索引擎通过爬虫技术从互联网上抓取网页,并建立索引,以便用户查询时快速检索相关信息。
- 数据挖掘:爬虫可以用来从网页中提取结构化数据,进行分析和挖掘,发现有用的信息或模式。
- 监测与分析:企业可以利用爬虫技术监测竞争对手的动态、舆情信息等,进行市场分析和竞争情报搜集。
- 内容聚合:爬虫可以从多个网站抓取相关内容,进行聚合展示,为用户提供更丰富的信息资源。
四、技术挑战与伦理问题
- 反爬虫技术:为防止数据被未经授权的爬虫获取,网站可能会采取反爬虫技术,如验证码、IP封禁等。
- 数据隐私:爬虫获取的数据可能涉及用户隐私,因此在数据采集和使用过程中需要考虑数据隐私保护的问题。
- 数据质量:网页结构的多样性和变化性可能导致爬虫获取的数据质量参差不齐,需要进行数据清洗和验证。 爬虫技术的发展和应用对于信息获取、数据分析和业务决策等方面都具有重要意义,但在使用过程中需要注意合法合规,避免侵犯他人权益和违反相关法律法规。
五、简单实战
我们以爬取某小说网站的例子开始讲解,如下图所示:
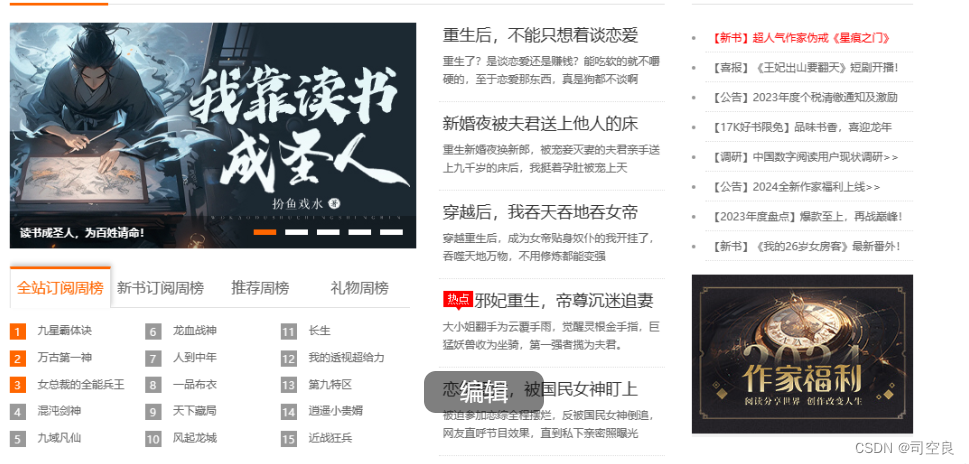
从这幅图我们可以清楚的看出小说的各种分类,爬虫其实说白了就是模仿人为的操作对数据进行收集,只不过是解放了人类的双手和精力,下面上代码。
'''
import pandas as pd
import requests
from lxml import etree
# 发送HTTP请求获取页面内容
def fetch_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
# 使用xpath提取页面数据
def parse_page(html):
tree = etree.HTML(html)
# 在这里使用xpath表达式提取需要的内容
# 这里以提取页面中的标题和链接为例
name = tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/h1/a/text()')
jibie=tree.xpath('//*[@id="bookInfo"]/dd/div[2]/table/tbody/tr[1]/td[1]/span/text()')
object=tree.xpath('//*[@id="bookInfo"]/dd/div[2]/table/tbody/tr[1]/td[2]/a/text()')
zhou=tree.xpath('//*[@id="weekclickCount"]')
yue=tree.xpath('//*[@id="monthclickCount"]')
zhoug=tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/dl/dd/div[2]/table/tbody/tr[3]/td[1]')
yueg=tree.xpath('//*[@id="hb_month"]')
zhout=tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/dl/dd/div[2]/table/tbody/tr[4]/td[1]')
yuet=tree.xpath('//*[@id="flower_month"]')
readpeople=tree.xpath('//*[@id="howmuchreadBook"]')
numbers=tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/div[2]/p[2]/em')
line=tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/div[2]/p[3]/em')
return name,jibie
# 主函数
def main():
urls = pd.read_csv('17k小说url.csv') # 替换为你的CSV文件路径和名称
urls = urls['url']
results = {'name': [], 'line': []} # 用于保存提取到的字段结果
for url in urls:
html = fetch_page(url) # 获取页面内容
if html:
name, line = parse_page(html) # 解析页面数据
results['name'].extend(name) # 将提取到的标题添加到结果列表里
results['line'].extend(line) # 将提取到的链接添加到结果列表里
# 将结果保存到CSV文件
df = pd.DataFrame(results)
df.to_csv('17k小说.csv', index=False) # 替换为你想要保存结果的CSV文件路径和名称
if __name__ == '__main__':
main()
'''''
import pandas as pd
import requests
from lxml import etree
# 发送HTTP请求获取页面内容
def fetch_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
# 使用xpath提取页面数据
def parse_page(html):
tree = etree.HTML(html)
# 在这里使用xpath表达式提取需要的内容
name = tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/h1/a/text()')
jibie = tree.xpath('//*[@id="bookInfo"]/dd/div[2]/table/tbody/tr[1]/td[1]/span/text()')
object = tree.xpath('//*[@id="bookInfo"]/dd/div[2]/table/tbody/tr[1]/td[2]/a/text()')
zhou = tree.xpath('//*[@id="weekclickCount"]/text()')
yue = tree.xpath('//*[@id="monthclickCount"]/text()')
zhoug = tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/dl/dd/div[2]/table/tbody/tr[3]/td[1]/text()')
yueg = tree.xpath('//*[@id="hb_month"]/text()')
zhout = tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/dl/dd/div[2]/table/tbody/tr[4]/td[1]/text()')
yuet = tree.xpath('//*[@id="flower_month"]/text()')
readpeople = tree.xpath('//*[@id="howmuchreadBook"]/text()')
numbers = tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/div[2]/p[2]/em/text()')
line = tree.xpath('/html/body/div[5]/div[1]/div[1]/div[2]/div[2]/p[3]/em/text()')
return name, jibie, object, zhou, yue, zhoug, yueg, zhout, yuet, readpeople, numbers, line
# 主函数
def main():
urls = pd.read_csv('17k小说url.csv') # 替换为你的CSV文件路径和名称
urls = urls['url']
results = {'name': [],
'jibie': [],
'object': [],
'zhou': [],
'yue': [],
'zhoug': [],
'yueg': [],
'zhout': [],
'yuet': [],
'readpeople': [],
'numbers': [],
'line': []} # 用于保存提取到的字段结果
for url in urls:
html = fetch_page(url) # 获取页面内容
if html:
name, jibie, object, zhou, yue, zhoug, yueg, zhout, yuet, readpeople, numbers, line = parse_page(html) # 解析页面数据
results['name'].extend(name)
results['jibie'].extend(jibie)
results['object'].extend(object)
results['zhou'].extend(zhou)
results['yue'].extend(yue)
results['zhoug'].extend(zhoug)
results['yueg'].extend(yueg)
results['zhout'].extend(zhout)
results['yuet'].extend(yuet)
results['readpeople'].extend(readpeople)
results['numbers'].extend(numbers)
results['line'].extend(line)
# 将结果保存到CSV文件
df = pd.DataFrame(results)
df.to_csv('17k小说.csv', index=False) # 替换为你想要保存结果的CSV文件路径和名称
if __name__ == '__main__':
main()
需要原数据的可以呼我。
六、IP池推荐
如果有大量数据需要爬去的小伙伴们推荐可以用这个,性能稳定,前期还可以免费试用。


















 3058
3058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











