







抓取工具主要有chrome firefox fidder appium,重点讲一下fidder,基本可以说目前最为全面和强大的抓包工具就是fiddler了,使用也不算麻烦。
Fiddler也在官网上有提供非常详细的文档和教程,如果使用的时候遇到问题,可以直接查阅官网文档。我们可以利用Fiddler详细的对HTTP请求进行分析,并模拟对应的HTTP请求。
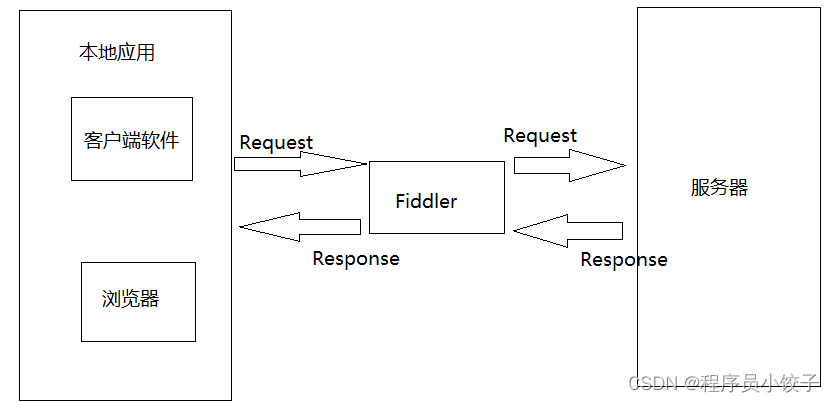
fiddler程序界面
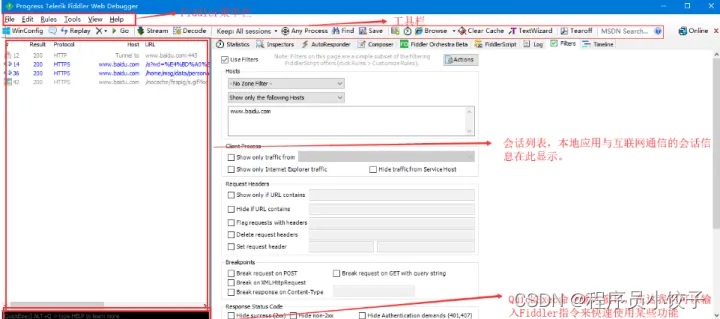
fiddler本质就是一个HTTP代理服务器,功能非常强大,除了可以清晰的了解每个请求与响应之外,还可以进行断点设置,修改请求数据、拦截响应内容。
技巧三:解析数据库
解析库有非常多可以选择,比如CSS、pyqery、re、xpath等,比较建议掌握Beautiful Soup和Xpath
Beautiful Soup解析库
为第三方库需要安装使用,在命令行用pip安装就可以了:

具体用法:变量名称 = BeautifulSoup(需要解析的数据,"html.parser’)
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序,能自动转换编码。
BeautifulSoup支持的解析器
1.Python标准库:内置库、执行速度适中、文档容错能力强;
2.lxml HTML解析器:速度快,文档容错能力强(推荐);
3.lxml XML解析器:速度快,唯一支持xml的解析器;
4.html5lib:最好的容错性、以浏览器方式解析文档,生成HTML5格式的文档。
具体用法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









