







在前面两篇文章中,我们分别介绍了序列建模用户兴趣和辅助排序损失,都是实用性内容,非常容易集成到自己的模型中,其中某些内容会在本篇文章中重现。
Ads Recommendation in a Collapsed and Entangled World
KDD‘2024:https://arxiv.org/abs/2403.00793
今天这篇文章同样是腾讯在2024年KDD中发表的一篇论文,讲述了腾讯在广告系统上的一些工作,并且是汇集了几篇论文的精华,个人认为里面存在许多实质性的干货内容。我们先整体地抛出论文的主要三个研究方面:
- 先验知识的表征:真实的工业场景中,推荐/广告系统围绕着多种类型的特征,并且来自不同的源,包括序列特征(如用户点击/转化历史)、数值特征(如保留语义的IDs)、来自外部模型的预训练embeddings(如GNN或LLM)。在进行特征编码的时候,保留这些特征内在的先验知识便是关键
- 维度塌缩:编码过程会将所有的特征映射到embeddings,一般是K维的向量表征,然后在模型训练的时候会对这些embeddings进行学习。然后,论文发现许多特征embeddings会塌缩到低维的子空间,而不是完全地利用到完整的K维空间。这个问题不仅导致了参数的浪费,还会限制了模型的扩展性
- 兴趣纠缠:在推荐/广告系统中,用户的反馈取决于复杂的潜在因素,特别是在多任务和多场景的联合训练中。目前的主流方法都是使用共享的embeddings,这使得无法充分地拆分这些影响因素,因为每个特征是依赖于单个纠缠的embeddings。
1. 整体结构
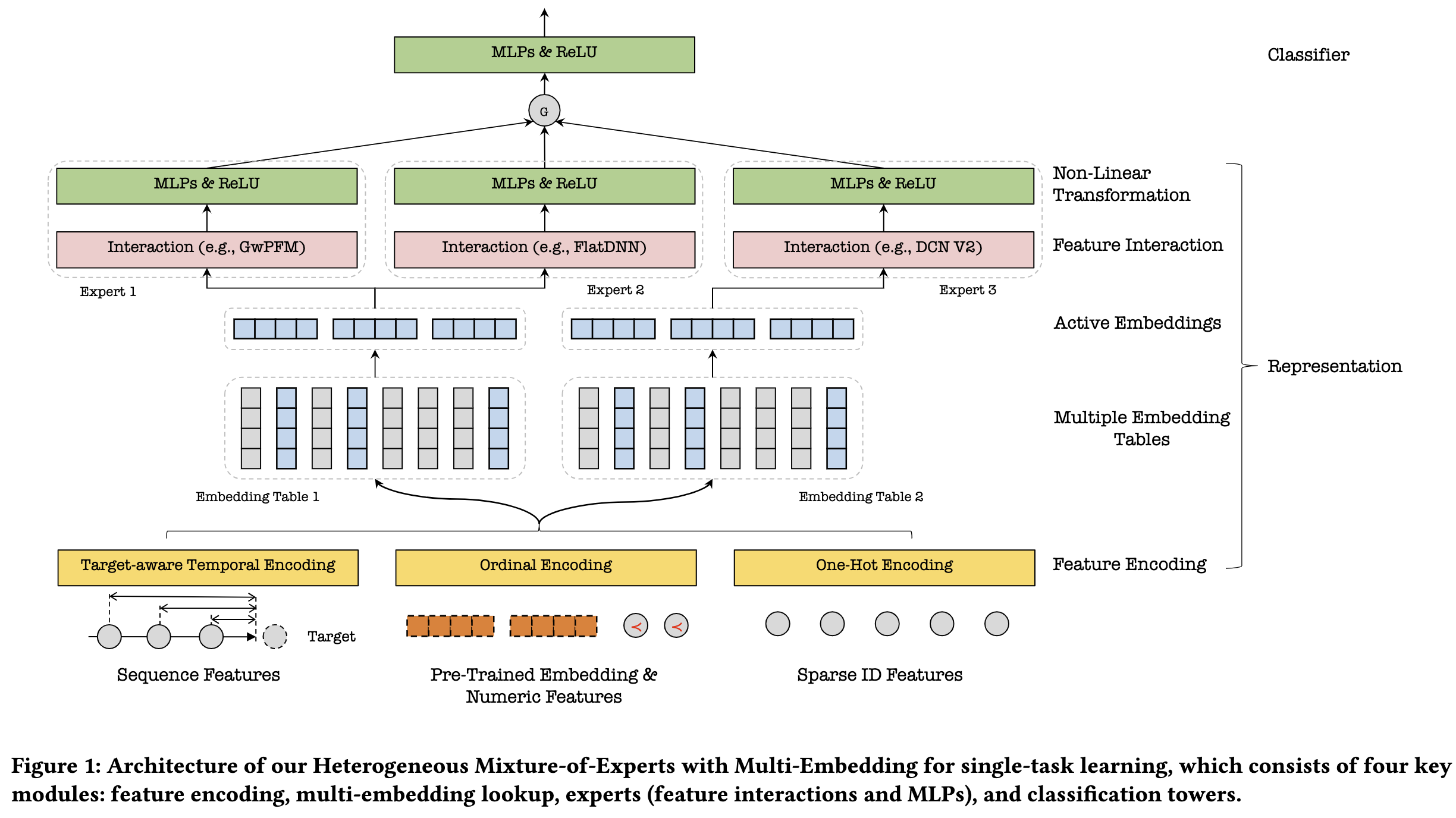
如上第1张图-[单任务结构]、第2张图-[多任务结构]分别对应论文提出的单任务和多任务的模型结构:
- 对于单任务学习,如CTR,模型只会有一个单独的tower;
- 对于多任务学习,如CVR(转化率预估),每一种类型的转化都会被当作一种单独的任务,模型则会使用多个tower和对应的门控(gates),每一个tower专注于一组特定的转化类型,能够兼容任务特定(task-specific)预估。
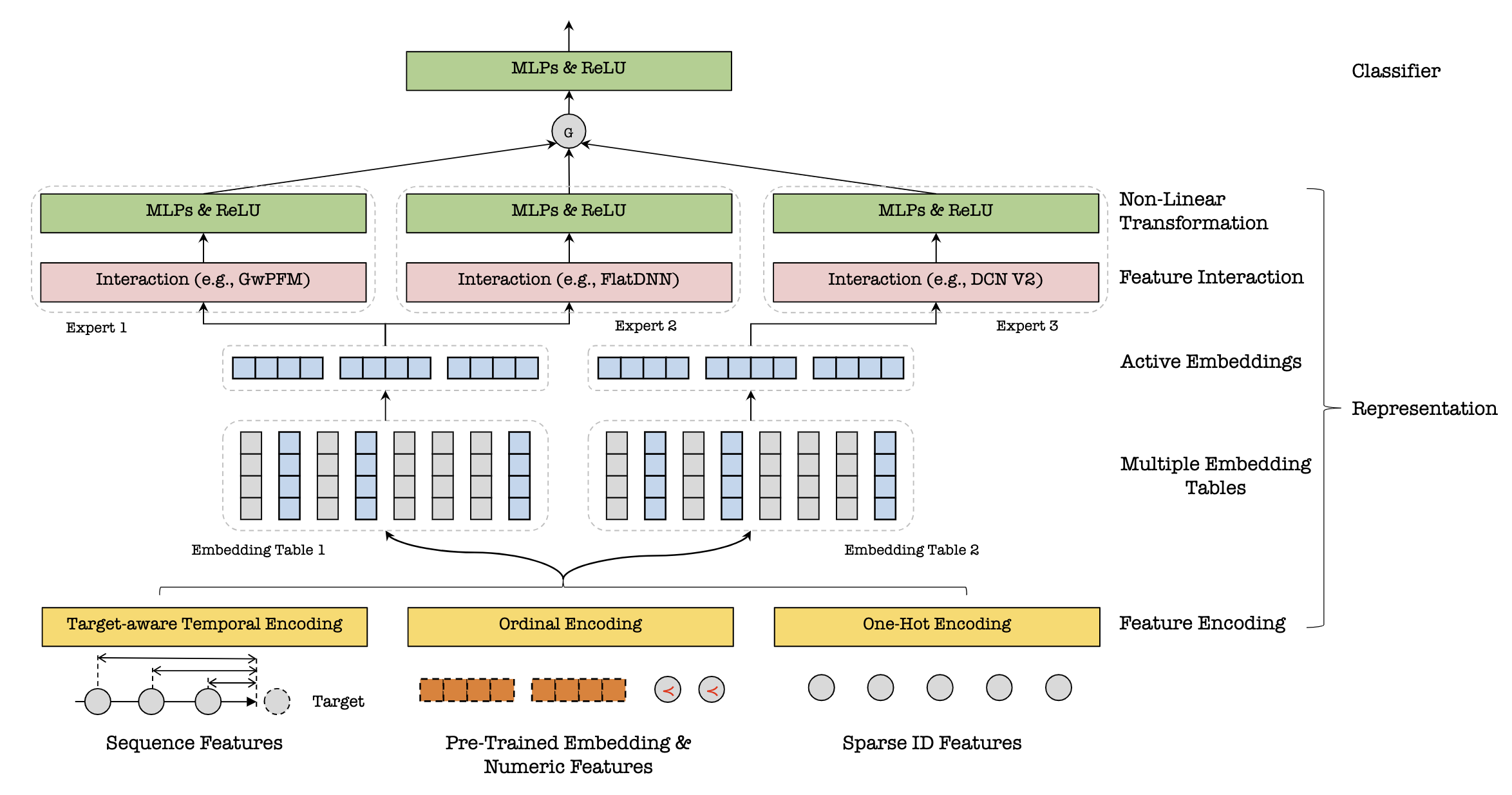
可以看到,模型还是遵循着Embedding&显式交互(Explicit Interaction)的框架,包含了四个关键的模块:
- 特征编码:根据不同的特征类型定制特定的特征编码方法
- 多embedding映射(multi-embedding lookup):得到特征编码后的IDs,会使用多个独立的embedding tables将每一个特征映射为多个embeddings
- experts:主要是特征交互和MLPs。同一个table的embeddings会彼此进行显式交互,然后再传入到带有非线性函数的多层感知机MLPs
- 分类towers:接收gate产出的权重对多个experts输出的求和,然后使用sigmoid函数去生成最后的预估概率
2. 特征编码
2.1 序列特征
Temporal Interest Network for User Response Prediction
WWW’2024:https://arxiv.org/abs/2308.08487
用户的历史行为能够反应出他们的兴趣,这让类似的序列特征成为了推荐系统中极为关键的特征。其中,这种序列特征一个重要的特性就是历史行为与target存在着高度的语义和时序相关性,比如给定一个target item,那些与之语义上更相关(如分类相同)或者时序上更接近的行为能够为预测用户对target item的反馈提供更多信息。
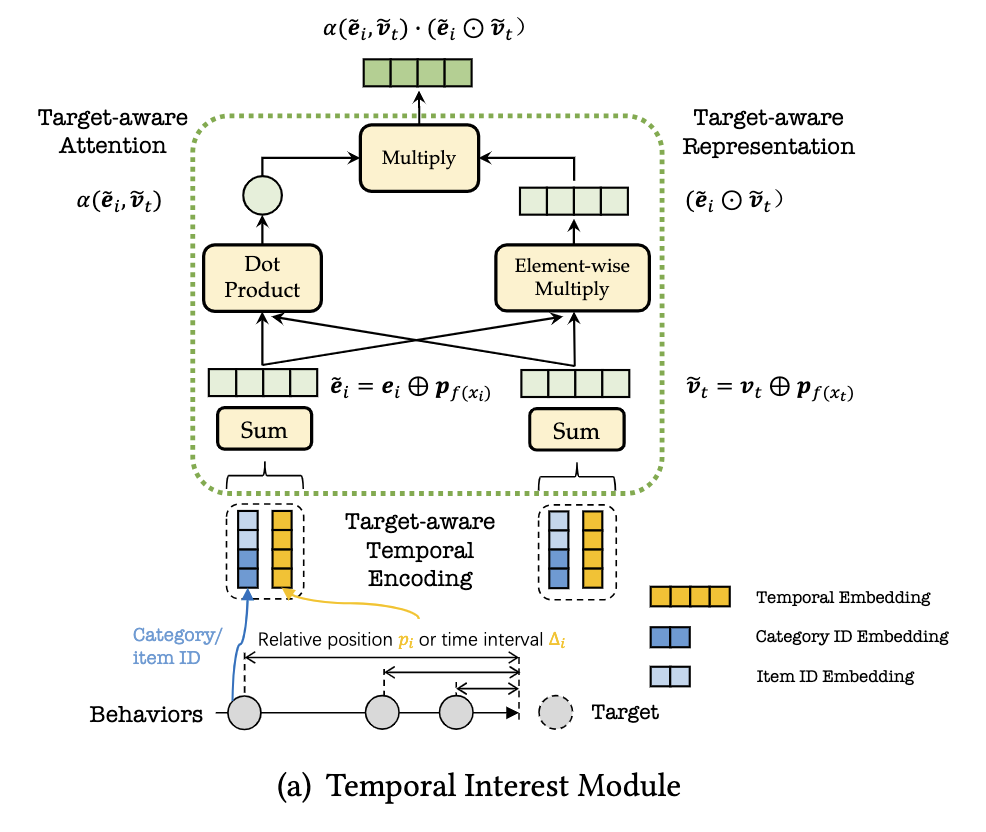
这些都是在 Temporal Interest Network 中提出的东西,其中的时序兴趣模块(TIM)便是针对序列特征的。TIM能够学习到四部分语义-时序相关性(行为语义、target语义、行为时序、target时序)。具体地,TIM为每一个行为应用了Target-aware Temporal Encoding(行为与target的相对位置或时间间隔)来实现时序编码;再通过Target-aware Attention 和 Target-aware Representation来实现行为与target的注意力和表征的交互,以此来捕获这四部分语义-时序相关性,达到了4阶交互的效果。
TIM的公式和结构如下图所示:
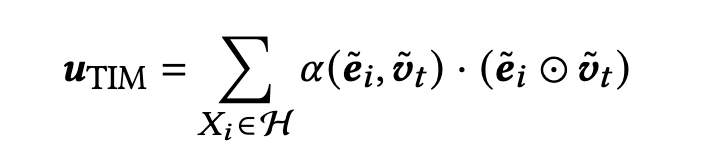
- α ( e ~ i , v ~ t ) \alpha(\tilde{e}_i,\tilde{v}_t) α(e~i,v~t) 表示第i个行为与target的target-aware注意力
- ( e ~ i ⊙ v ~ t ) (\tilde{e}_i \odot \tilde{v}_t) (e~i⊙v~t) 表示第i个行为的target-aware表征
- e ~ i = e i ⊗ p f ( X i ) \tilde{e}_i=e_i \otimes p_{f(X_i)} e~i=ei⊗pf(Xi) 表示第i个行为的时序编码embedding,即第i个行为的语义embedding与target的相对位置或者离散的时间间隔的position embedding的逐位相加(element-wise summation)
- 细节可以前往前面的文章:CTR之行为序列建模用户兴趣:Temporal Interest Network
部署细节:
- 在腾讯的实践使用中,TIM会同时应用相对位置和时间间隔的时序编码
- TIM的输出会拼接到特征交互模块的输出中,如上图-[单任务结构]中的DCN V2或GwPFM(后续会详细阐述)
- TIM是应用在不同场景的用户点击/转换分类序列,而不是点击/转换的items/ads序列
还发现了模型在时间间隔的embeddings上学习到了更强的衰退,相比于相对位置的embeddings,这是因为在广告系统中,用户的点击广告行为是非常稀疏的,使得时间间隔能够提供更多的信息。
2.2 数值特征
与独立的ID特征不同,数值/序数特征是存在自有的顺序,比如Age_30 > Age_20。为了保留这些顺序的先验知识,论文提出了一种基于NaryDis编码的变体,称之为Multiple Numeral Systems Encoding (MNSE):
- 首先将这些数值特征编码为不同进制的code,比如二进制、三进制、十进制
- 然后,根据这些code分配多个可以学习训练的embedding
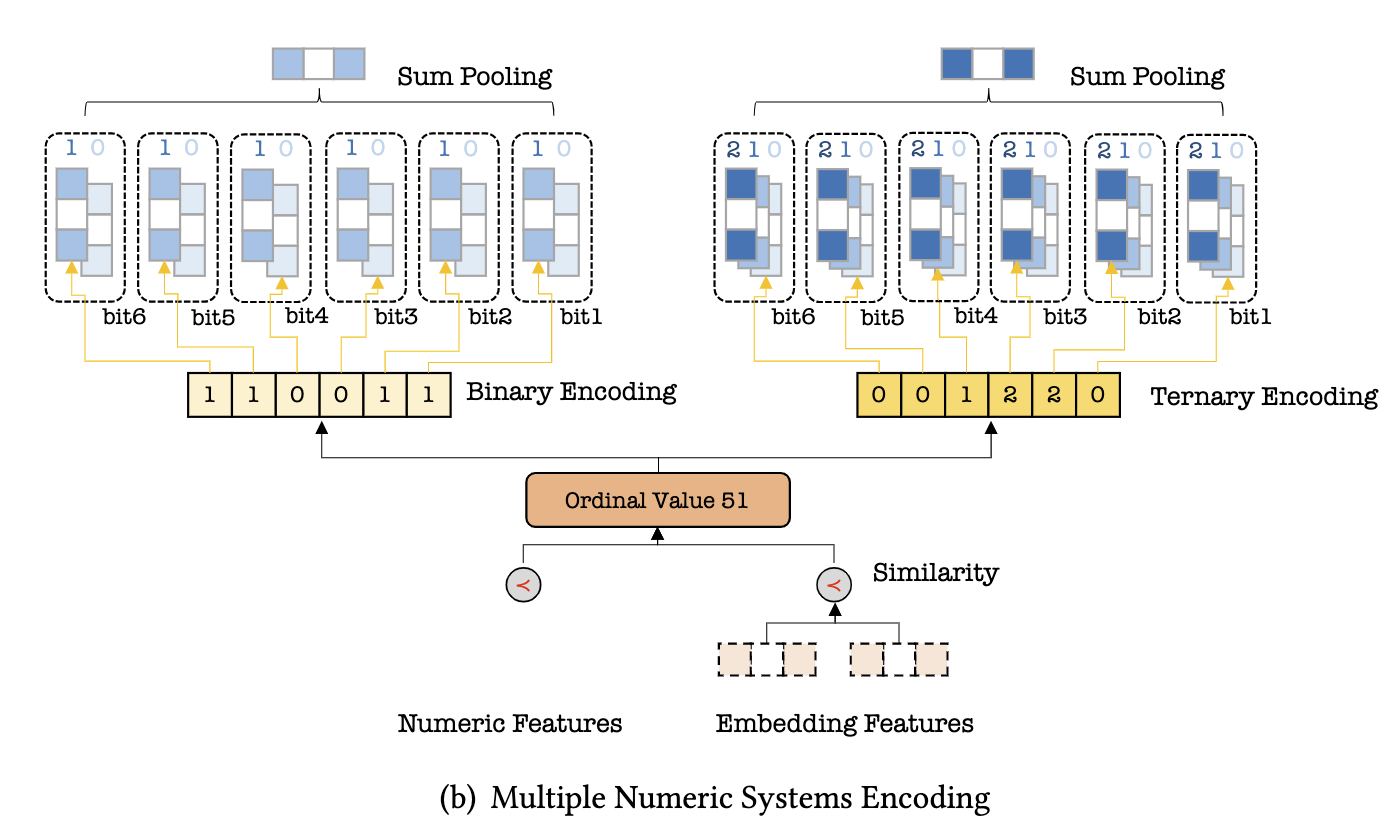
为了更好地理解,以特征值“51”为例子:
- 根据二进制可以换算为“110011”,其对应的编码为:{6_1, 5_1, 4_0, 3_0, 2_1, 1_1},结合上图来说,长度为6的二进制编码表,bit6则取第1个embedding,bit4则取第0个embedding
- 同理,三进制换算为“001220”,其对应的编码为“{6_0, 5_0, 4_1, 3_2, 2_2, 1_0}”,结合上图,长度为6的三进制编码表,bit4取第1个embedding,bit3取第2个embedding
- 每一种进制编码embedding会进行相加求和,作为其对应进制的编码结果
- 最后,所有进制的编码embedding进行拼接便是MNSE的结果
公式表达则如下式:
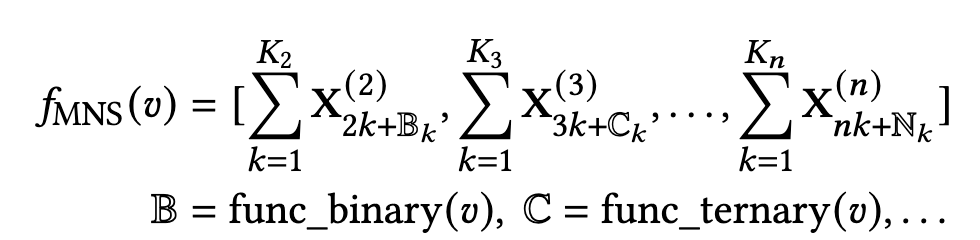
- X 2 k + B k ( 2 ) , X 3 k + C k ( 3 ) X^{(2)}_{2k+\mathbb{B}_k},X^{(3)}_{3k+\mathbb{C}_k} X2k+Bk(2),X3k+Ck(3) 分别对应二进制和三进制的embeddings映射表,并且长度分别为 K 2 , K 3 K_2,K_3 K2,K3
部署细节:广告IDs一般使用的是自增或者随机的ID,没有什么有用的信息。但是,每一个广告都包含着丰富的视觉语义,因为腾讯会使用视觉语义IDs来代替自增或随机的IDs。具体地做法是:
- 从视觉模型中得到广告图片的表征embeddings,然后使用哈希算法比如LSH(Locality-Sensitive Hashing,局部敏感哈希),来保留视觉的相似性
- 最后,使用上述的MNSE对视觉语义ID进行编码,来保留其先验的顺序信息
论文还发现曝光给同一个用户的相似广告的预估分数的变异系数(coefficient of variation)显著下降了(2.44% -> 0.30%),这也证实了这个方法能够保留广告的视觉相似度的先验知识。
2.3 Embedding 特征
除了推荐主模型外,还会分开训练一些相关的模型,比如上一小节提到的视觉模型,更常见的比如GNN或LLM,来学习实体(用户/items)的embeddings,它们往往能够从不同的角度捕获用户和items的关联,而且这些模型是由更大或者不同的数据集训练而来的,因此能够为推荐模型提供其它的额外信息。
但是,一个关键的问题是这些预训练embeddings空间与推荐系统的embeddings空间存在着语义gap,也即它们捕获的语义是不同于推荐模型的协同语义的,因此直接使用可能产生负效果。
论文提出了一种相似度编码Embedding的方法来缓解这样的语义gap。以GNN为例,一旦训练好了GNN的模型,那么便得到了每一对item-user对(u, i)的预训练embedding e ˉ u , e ˉ i \bar{e}_u,\bar{e}_i eˉu,eˉi:
- 首先,计算它们的相似度,比如使用cosine函数: w s i m ( u , i ) = s i m ( e ˉ u , e ˉ i ) w_{sim}(u,i)=sim(\bar{e}_u,\bar{e}_i) wsim(u,i)=sim(eˉu,eˉi)
- 那么,它们的相似分数便是一个有顺序的数值,因此,与上一小节的数值特征一样,便可以使用Multiple Numeral Systems Encoding(MNSE),然后映射到可学习的embedding e s i m = f M N S ( w s i m ( u , i ) ) e_{sim}=f_{MNS}(w_{sim}(u,i)) esim=fMNS(wsim(u,i))
- 最终,经过这种方式编码的embedding便可以与其他ID embeddings进行联合训练了
论文提出的这种编码方式,原始的embedding空间中的相似度先验知识在经过相似分数计算和编码之后仍能进行保留,然后,这种先验知识又通过对齐相似度编码embedding e s i m e_{sim} esim与其他ID embeddings,来迁移到推荐系统中。
除此之外,腾讯还更深入地研究embedding编码策略,通过引入LLM知识:
- 首先,一个LLM模型会被转换为encoder-only结构,然后通过代理任务进行训练,比如next-sentence prediction(个人理解这里应该是使用用户的点击/转换序列,前面的items作为输入,去预测后面的items)
- 这样,LLM encoder便有了编码语义embedding的能力
- 接着,使用高质量的广告领域的item-user的正负样本对去微调。通过这样的对比学习对其,让LLM能够生成高质量的预训练用户和item/广告 embedding e ˉ u , e ˉ i \bar{e}_u,\bar{e}_i eˉu,eˉi
- 那么,到这一步,便与上述的GNN预训练embedding一样了,可以进行相似度编码embedding
部署细节:
- 腾讯在用户-广告/内容的二分图之上训练了一个 GraphSage 模型,同时点击了广告和推荐系统的内容的点击作为边
- 对GNN embeddings进行相似度编码之后,将其与特征交互网络层进行拼接的表征结果进行拼接。
3. 维度塌缩
On the Embedding Collapse when Scaling up Recommendation Models
ICML’2024:https://arxiv.org/abs/2310.04400
进行上一节讲述的编码之后,所有的特征都会被转换为embeddings,然后通过FM形式的模型进行显式地交互。但是,显式特征交互的一个关键副作用是embeddings的维度塌缩。
3.1 塌缩现象
目前,大预言模型领域的scaling law是被普遍认可接受的,例如GPT-4、LLaMA这种transformer基座的大规模参数的模型,能够取得惊人的效果。论文也尝试着去扩大推荐模型,在推荐模型中,模型的参数大头都是特征embeddings,腾讯生成环境的模型embeddings的参数占比甚至达到了99.99%。因此,论文尝试着提升embeddings的维度 K,比如K从64增加到192,然后这并不能带来预期中的显著效果提升,反而会导致效果下降。
论文使用 奇异谱分析 来分析每一个field学习到的embedding矩阵,并观察到了维度塌缩:
- 许多的奇异值非常小,表明了许多fields的embeddings最后是在一个低维的子空间的跨度范围,而不是整一个可用的embedding空间。
- 这种维度塌缩导致模型容量的极大浪费,因为许多的embedding维度是塌缩,也即毫无意义的
- 再进一步说,维度塌缩正是限制了通过简单地增加维度大小来扩大推荐模型
论文认为维度塌缩产生的本质原因是特征交互模块,维度塌缩的fields会使其他fields也产生塌缩:
- 比如,性别这一个field,它的基数 N G e n N_{Gen} NGen 非常小,导致它的embedding只能在一个 N G e n N_{Gen} NGen-维的范围跨度的空间里。
- 因为 N G e n N_{Gen} NGen比embedding的维度 K 小很多,这些低维的embeddings与其他剩余的可能高维的embedding的fields进行交互,会导致后者塌缩为 N G e n N_{Gen} NGen-维度的子空间。
3.2 Multi-Embedding 范式
论文提出一种 multi-embedding范式的方法来缓解扩大推荐模型而出现的塌缩现象:
- 对于每一个field,不同于常规的single-embedding范式只是查找一个embedding,而是学习多个embedding table;
- 然后可以查找得到多个embedding。然后,在对应的专家 I I I 中,来自同一个embedding table的所有特征能够彼此之间进行交互。(其实就是每一个专家里,特征的embedding table是独立的)
对于有 T T T 个embedding table的,整个推荐模型的结构就如第一节的图-[单任务结构],对应的计算表达式如下:
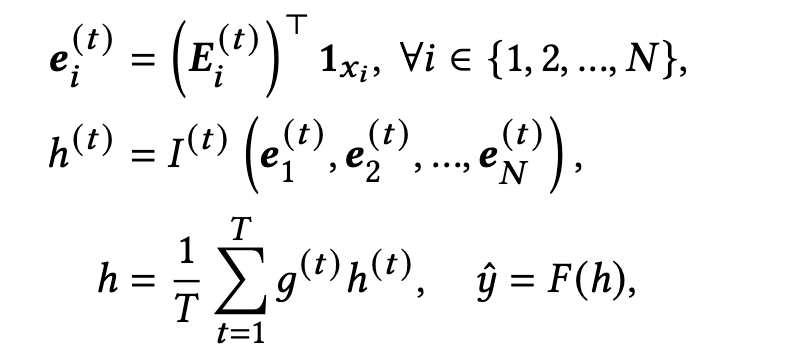
- t表示embedding table的索引
- g为每一个专家的门控函数, F ( ⋅ ) F(\cdot) F(⋅) 表示最终的分类器。
- I I I 是带有非线性函数比如ReLU的交互专家
multi-embedding范式提供了一种有效地扩大推荐模型的方法,不是简单地增加每一个特征的共享embedding的维度,而是为每一个特征学习多个embeddings。通过这种范式,可以实现推荐模型的scaling law(一个经典的挑战性任务):模型的效果随着参数的增加而提升。
部署细节:腾讯平台上的所有pCTR模型都已经采用了这种multi-embedding范式。更具体地,他们会学习多个不同的特征交互专家(比如下文的GwPFM,IPNN,DCN V2或FlatDNN)和多个embedding tables。正如上图-[单任务结构]所示,腾讯指出最有效的模型会有包含GwPFM、FlatDNN和DCN V2三个交互专家,并且GwPFM和FlatDNN共享第一个embedding table,DCN V2使用第二个。
3.3 GwPFM
FFM 其实也是multi-embedding范式的另一种方法,因为FFM为每一个feature学习多个embeddings。假如有M个fields,那么FFM会为每一个feature x i x_i xi 学习M-1个embeddings { e i , F l ∣ F l ≠ F ( i ) } \{e_{i,F_l}|F_l \ne F(i)\} {ei,Fl∣Fl=F(i)}。当feature x i x_i xi 与另外一个feature j 交互时,FFM会选择对应 field j 的embedding e i , F j , F ( j ) e_{i,F_j},F(j) ei,Fj,F(j) 表示feature j 的field。
即使FFM能够取得更优秀的效果,但它其实并不被业界广泛使用,因为它的巨大计算空间,相比于FM,FFM引入了M-2倍的参数量,而M通常是千级别的。
为了解决这种高度计算复杂度,论文采用了减少embeddings的数量的方法,将所有fields分为P个部分(field parts),为每一个feature学习P个embeddings,每一个embedding对应一个field part,并且P可以是比较小的数字。
再深入一点,论文还希望像**FwFM一样能够捕获到field-pair-wise相关性来进一步提升效果**,直接地实现方法便是FwFM为每一个field对分配一个权重,但论文认为这增加 O ( M 2 ) O(M^2) O(M2) 的计算开销,是无法接受的。那么,同样的道理,可以进行分组,每一个field group pair分配一个权重。
论文将这两者结合起来的方法称为GwPFM(Group-weighted Part-aware Factorization Machines),其表达式如下:
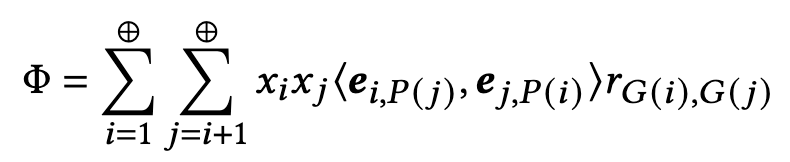
- ⊗ \otimes ⊗ 表示element-wise相加
- P ( i ) , G ( i ) P(i),G(i) P(i),G(i) 分别表示feature i所属的field part 和group
- r G ( i ) , G ( j ) r_{G(i),G(j)} rG(i),G(j) 为field group pair ( G ( i ) , G ( j ) ) (G(i),G(j)) (G(i),G(j)) 的可学习权重
部署细节:实际应用上,会把所有fields分为两部分,第一部分是与目标广告无法的,而第二部分是与其相关的。第一部分fields会根据专家知识,使用上述的方法划分为G个组,并且G通常是低于50的。而第二部分fields则不进行分组。
3.4 缓解塌缩的特征交互
正如前面一直提到的,像常规的做法,比如FM,两个特征embeddings的交互方式是采用内积(element-wise inner product): f ( e i , e j ) = e i ⊙ e j f(e_i,e_j)=e_i \odot e_j f(ei,ej)=ei⊙ej,会造成维度塌缩。
而在内积操作之前,为embeddings加入一个映射矩阵的做法也已经被证实是有效缓解维度塌缩的手段,这也正是FiBiNET、FmFM和DCN V2采用的方法。
加入映射矩阵 M F ( i ) → F ( j ) M_{F(i) \to F(j)} MF(i)→F(j) 之后的embeddings pair交互函数为下式:
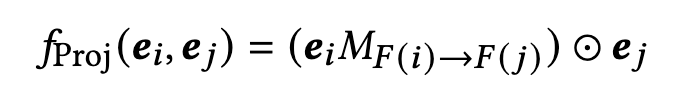
4. 兴趣纠缠
STEM: Unleashing the Power of Embeddings for Multi-task Recommendation
AAAI’2024:https://arxiv.org/abs/2308.13537
在广告推荐系统中,用户的反馈的驱动是他们在一个特定的任务或场景下的兴趣。目前,同时训练多个任务或场景来利用多个任务/场景的信息,从而提升预估的准确率已经是一个趋势了。然而,当前的研究,如 MMoE和PLE 都是采用一个共享embedding的范式,为每一个广告和用户学习一个embedding表征,这会造成因用户在多个任务或场景的兴趣可能是存在矛盾的,而带来的embedding纠缠,从而引起负向的迁移。
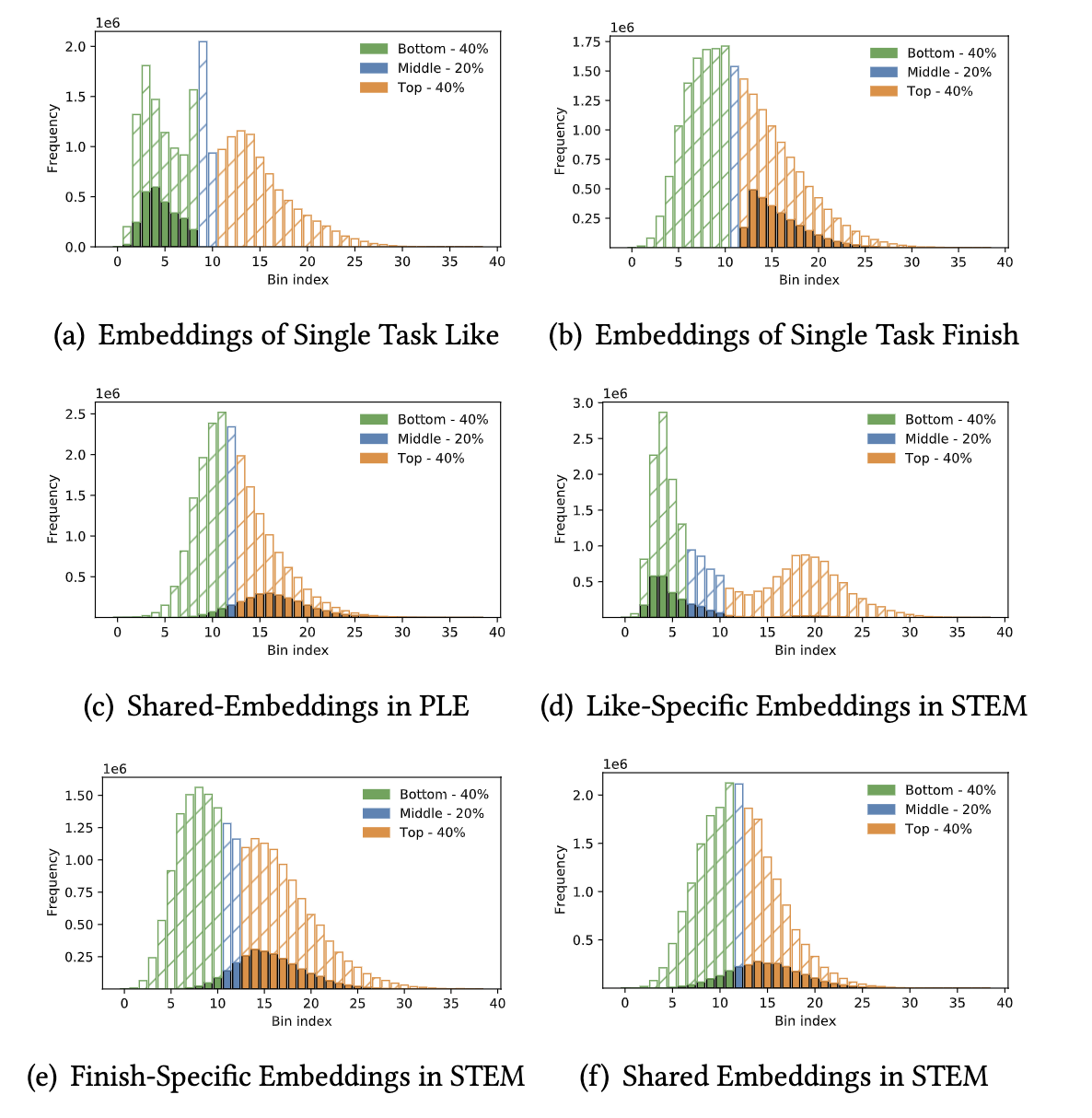
论文使用公开的TikTok数据集,包含了Like和Finish两个任务,并从中选择一批存在矛盾性的user-item pair S S S 的集合:
-
对于Like任务,它们的embeddings的欧氏距离比较相近,分布在底部40%(如上图-a),而对于Finish任务,它们的欧氏距离比较远,分布在顶部40%(如上图-b),其实简单理解就是user-item的embeddings在这两个不同的任务中分布差距很大。
-
对于上图-c,可以看到PLE从中学习到了比较多的距离远,这与单任务Finish的分布是相似的,但这与单任务Like确是矛盾的,即PLE学习到更多的知识是来自Finish任务,而很少来自Like任务。
-
而对于上图-d和上图-e,可以看出论文提出的STEM可以尽可能地在不同任务中保留特定的用户兴趣,也即能保留单任务Like中的相近距离,又能保留单任务Finish中的远距离。
4.1 多任务学习-STEM
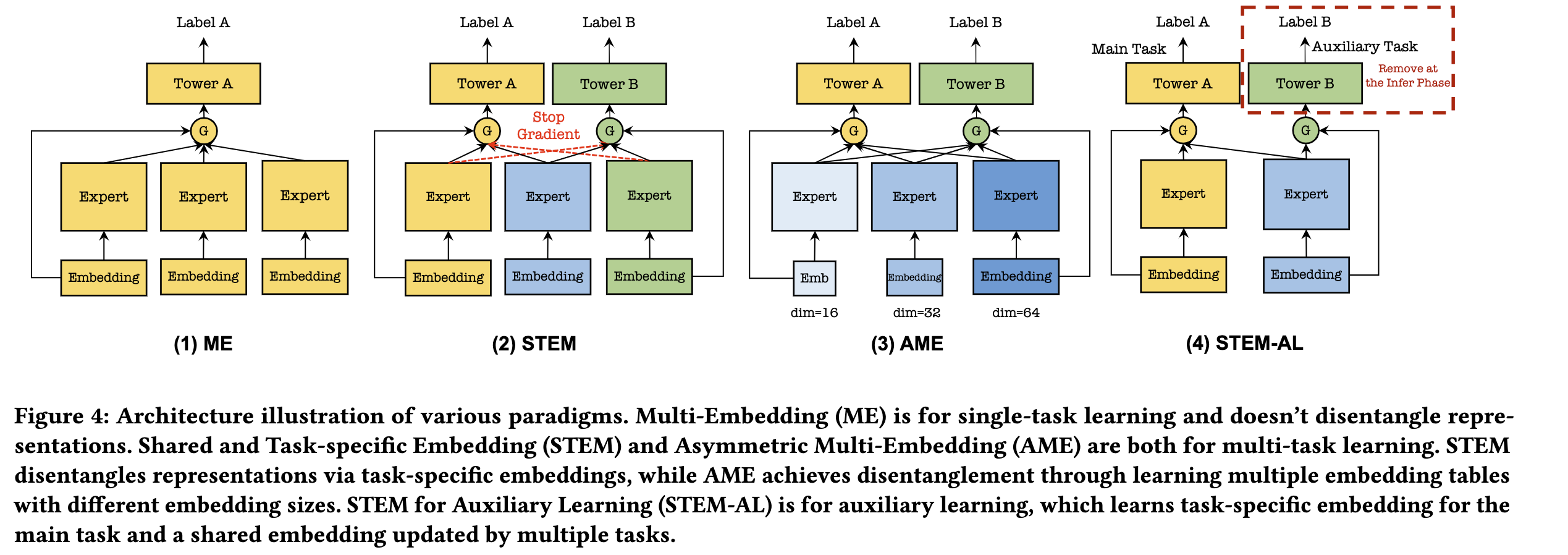
为了解决这种兴趣纠缠的问题,论文提出了一种共享和任务特定的Embedding范式(STEM,Shared and Task-specific EMbedding),包含一个任务特定的embedding来学习对应任务的用户和item的表征,还附带着一个共享的embedding,这可以尽可能地在不同任务中保留特定的用户兴趣,缓解上述的兴趣纠缠问题,正如上图[兴趣纠缠现象]-d和上图-e所示。
基于此,论文会使用多个experts,每一个expert都是所有任务共享的或者任务特定的,并提出了全部前向传播,任务特定反向传播的门控机制(All Forward Task-specific Backward gating mechanism),应用到每一个任务特定的towers,这样每一个任务tower都会接收来自所有experts的前向传播,但梯度只会反向传播到对应任务的expert和共享的expert,正如下图[Embedding范式]-(2)所示。
然而,真实的广告推荐系统中会存在许多的任务,比如每一种转换类型都会当作一个任务,但如果像腾讯可能存在着数百个转换类型,这导致为每一个任务学习一个embedding table变得不可行了。因此,在实践中,会将转换类型进行分组,然后把每一个分组当作一个任务。另一方面,还可以把分组数量与embedding tables数量解耦,学习一个固定数量的embedding tables,使用门控机制来控制embedding tables与分组之间的路由。
4.2 AME
但是,由于对称性,这些embedding tables同样会出现类似上述的纠缠问题。针对这个问题,可以为不同的embedding tables设置不同的维度,来缓解它们的纠缠,因此,便有了另一种embedding范式:AME(Asymmetric Multi-Embedding paradigm),正如上图[Embedding范式]-(3)所示。
- 对于那些数量更少的小任务,需要更少的模型容量,可以通过门控被路由到小维度的embedding table
- 其他的有着更多数量,需要更多模型容量的任务,便可以被路由到大维度的embedding table
上一节提到的ME(Multi-Embedding 范式)是解决单任务学习中的embedding维度塌缩问题,而这一节的STEM和AE都是解决多任务/场景中的用户兴趣表征纠缠问题。论文也尝试了应用AME到单任务学习中(比如点击预估),这带来了小幅度的额外的效果提升,同样地,将ME应用多任务/场景中,相比STEM和AME,会取得更差的效果,因为embedding的对称性,可能仍然存在纠缠。
部署细节:腾讯的转换预测模型会同时对超过100种转换进行预测,并将其划分成了约30个towers,使用了AME范式,设置了3个embedding tables,对应的维度分别为16,32和64,这比单个维度为64的embedding table的PLE基线带来了一些提升,并且对于那些小任务的提升更大。
4.3 辅助学习-STEM
有时候,存在着这种一种场景需求:我们需要更多地关注一个主任务,并且希望能够利用其他任务的信号来提升主任务的效果。比如,点击预估中的主任务是预测转换点击,可以为登录页面带来更多的转换。除了这个主要的用户反馈之外,还会收集其他的行为数据,比如点赞、收藏、评论等。我们会希望通过对这些额外的任务的辅助学习来提升转换点击的效果。
为了避免辅助任务与主任务引起兴趣纠缠,论文使用了STEM范式,并且采用了STEM底座的辅助学习结构,称之为STEM-AL(STEM-based Auxiliary Learning)。
正如上图[Embedding范式]-(4)所示:
- 不同于STEM和AME同等关注所有任务,STEM-AL是将任务A当作主任务,而把任务B当作辅助任务来提升任务A的效果;
- STEM-AL引入两个embedding tables和对应任务的两个交互experts
- 第一个embedding table是主要embedding table,仅会被主任务A使用(即前向传播和反向传播优化仅与主任务A相关),保证保留主任务的特定,而不被其他任务影响
- 第二个embedding table是一个共享的,会同时被多个任务使用,这个共享的embedding table能够让主任务A从任务B的知识之中获得收益,并且这个embedding table会在预测阶段被移除
部署细节:腾讯部署STEM-AL,从其他场景采样,来提升一个主场景的pCTR。例如,Applet场景的pCTR作为主任务,而Moments场景的pCTR作为辅助任务,能够为Applet带来1.16%的pCTR提升,甚至同时使用Moments和Channel的pCTR作为辅助任务,能够为Applet带来更高的效果提升(2.93%)
5. 模型训练
5.1 梯度消失|排序loss
这一部分就不再赘述,在上一篇文章 推荐模型中辅助排序损失的作用 中已经非常详细地阐述了。
5.2 重复曝光|加权采样
同一个或者相似的广告在短期内,重复展示给用户,虽然能够增强用户对特定广告的感知,但同时也会有损坏用户体验的风险。为了解决这个问题,论文提出了重复曝光权重模板来降低一个给定用户的重复广告的预估分数,来降低曝光。
核心的思想是给重复的曝光(负样本)赋予更高的权重。具体地,对于每一个负反馈的重复曝光,分配一个权重 w r e p ≥ 1 w_{rep} \ge 1 wrep≥1 到原始的BCE loss中:
L = 1 N ∑ i = 1 N w r e p ⋅ B C E ( y i , f ( x i ) ) \mathcal{L} = \frac{1}{N} \sum_{i=1}^N w_{rep} \cdot BCE(y_i,f(x_i)) L=N1∑i=1Nwrep⋅BCE(yi,f(xi))
- w r e p w_{rep} wrep 同时考虑了重复曝光的计数(count)和新近度(recency): w r e p = α ⋅ w c o u n t + ( 1 − α ) ⋅ w r e c e n c y w_{rep}=\alpha \cdot w_{count} + (1 - \alpha) \cdot w_{recency} wrep=α⋅wcount+(1−α)⋅wrecency
- w c o u n t w_{count} wcount 是与曝光给当前用户的同一个或者相似广告的曝光量成正比,且曝光量是时间衰减的
- w r e c e n c y w_{recency} wrecency 则考虑最后一次重复曝光与当前时间的时间间隔
- 不过具体的计算方式论文并没有给出,算是提供了一个思路
不过,需要注意的是,这个加权方法会导致整个模型是存在bias的,因此,还需要对正样本赋予一个能够消除bias的权重: w d e b i a s = ( ∑ i = 1 N w r e p ⋅ ( 1 − y i ) / ( ∑ i = 1 N ( 1 − y i ) ) w_{debias}=(\sum_{i=1}^N w_{rep} \cdot (1-y_i)/(\sum_{i=1}^N (1-y_i)) wdebias=(∑i=1Nwrep⋅(1−yi)/(∑i=1N(1−yi))
5.3 在线训练
这一小节主要讲的是pCTR和pCVR模型在线学习存在的一个特殊挑战:转换延迟反馈。已有的一些工作,如 《Modeling delayed feedback in display advertising》 、《A Feedback Shift Correction in Predicting Conversion Rates under Delayed Feedback》 ,并不适合腾讯的一些场景,由于转换反馈的大幅度波动而导致模型明显的bias,例如,一些特定的广告主可能会在某个特地的时间上报所有先前的所有转换,导致观察到了异常高的CVR,然而在其他时间是没有任何转换上报的。
论文提出了一种动态的在线学习方法来应对这个问题,这个方法是基于转换反馈的方差。具体地,一个很小的方法意味着观察到的CVR与历史的CVR是接近的,这样就可以尽快地收集样本。而当方差很大时,则设置一个等待时间来保证转换到达的稳定,减少转换达到的波动而导致的高风险。
5.4 不确定估计的探索
这一小节主要是针对冷启动广告,论文提出了一种贝叶斯视角的CTR建模,不再是预测一个单独的数据点的CTR,而是预测一个包含了不确定估计的分布。
具体地,需要引入一个高斯过程先验分布来表征未知的真实CTR函数,并且是利用观察数据来获得预测和不确定估计,这是一个后验分布。如下式:
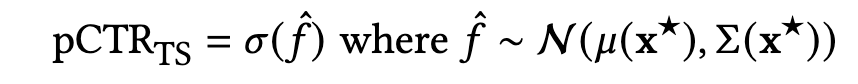
- μ ( x ⋆ ) , ∑ ( x ⋆ ) \mu(x^{\star}),\sum(x^{\star}) μ(x⋆),∑(x⋆) 分别是测试数据点 x ⋆ x^{\star} x⋆ 的后验 logit 值 ( f ( x ⋆ ) ) (f(x^{\star})) (f(x⋆)) 的均值和方差
PS:这一小节论文没有给出任何参考文献,仅是个人理解,欢迎探讨。
代码实现
tensorflow 2.x:STEM & AME、GwPFM、HMoE(Heterogeneous Mixture-of-Experts with Multi-Embedding)
tensorflow 1.x:STEM & AME、GwPFM、HMoE(Heterogeneous Mixture-of-Experts with Multi-Embedding)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









