







1. 概述
Understanding the Ranking Loss for Recommendation with Sparse User Feedback
SIGKDD‘2024:https://arxiv.org/abs/2403.14144
在搜广推系统中,CTR预估无疑是一个关键的研究领域,二分类交叉熵(BCE,binary cross entropy)是最为广泛使用的应对二分类问题的优化目标,非常贴合CTR预估任务。
但是,最新的研究已经表明BCE loss结合辅助的ranking loss能够显著地提升效果:
- 其中,作为其中的先驱者,Twitter Timeline 尝试使用pairwise loss结合pointwise loss;
- Google 提出了结合回归loss和ranking loss来更好地平衡回归和排序目标;
- Alibaba 提出了使用两个logits来联合优化排序和校准目标
论文揭示了在正样本稀疏的场景下BCE loss存在的挑战:负样本导致的梯度消失。针对CTR预估任务加入辅助的排序loss的有效性提出了新颖的论点:负样本会产生较大的梯度,因此引入排序loss能够减轻仅使用BCE loss的优化困难,从而产生更好的效果。
2. CTR 损失
众所周知,CTR预估一般被用于搜广推系统的排序阶段,而针对排序问题,优化目标分为三类:pointwise、pairwise和listwise。
2.1 Binary Cross Entropy
对于pointwise方法,每一个item都是被独立对待的,其目标就是优化每一个item的预估或者相关分数。而CTR预估任务最为常用的目标函数便是BCE loss了:
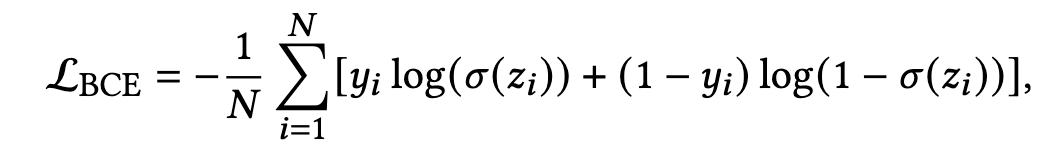
- N是样本的数量
- y i y_i yi 是第i个样本的二分类标签,即1是点击,0是非点击
- z i z_i zi 是第i个样本的模型输出的logit, σ \sigma σ 是sigmoid函数,将logit映射为0-1的预估点击概率
2.2 排序学习
然而,pointwise方法通常是次优化的,它独立地对待每一个item,但是排序阶段往往是同时输出一批items,因此pointwise是忽略了items之间的相对顺序的,并且是无法考虑到当次排序(query-level)和位置属性的评估指标。而排序学习(LTR,Learning-to-rank)正是应对这个情况的有效方法,可以增强排序效果。pairwise和listwise是排序学习的两个主要分支。
其中,pairwise方法的目标是确保每一对正负样本中的正样本预估值要大于负样本的预估值,而其中比较有代表性的是 RankNet,有着清晰的公式,能够高效捕获pairwise的本质,如下式:
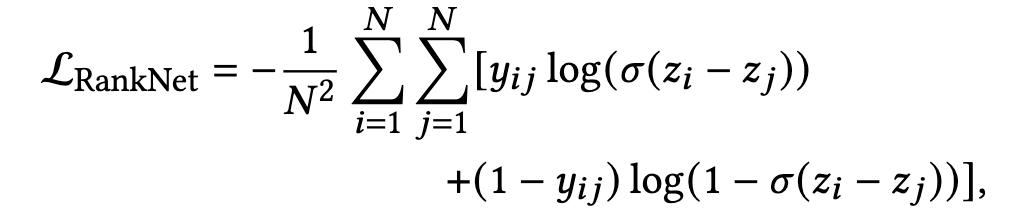
- y i j ∈ { 0 , 0 , 5 , 1 } y_{ij} \in \{0,0,5,1\} yij∈{0,0,5,1} 分别对应着 y i < y j , y i = y j , y i > y j y_i<y_j,y_i=y_j,y_i>y_j yi<yj,yi=yj,yi>yj
Listwise方法则是鼓励列表里所有样本中的正样本有着更高的排序值,比如ListNet 定义的loss如下式:
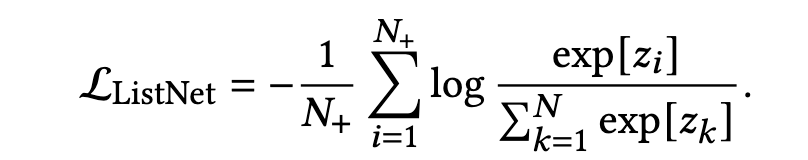
3.3 组合损失
在实时广告系统的背景下,一些研究认为单靠一个形式的目标函数难以取到理想的整体效果,因为一些实践工作便提出了分类loss和排序loss结合的模式:
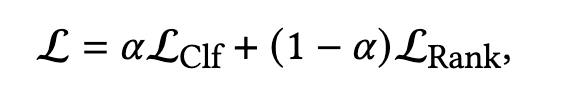
- L C l f , L R a n k \cal{L}_{Clf},\cal{L}_{Rank} LClf,LRank 分别表示分类loss和排序loss
基于这种组合损失的优化范式,研究人员们提出了许多类似的方法,比如针对回归任务进行MSE(Mean Squared Error)和排序loss的组合。
接着,Twitter Timeline的Combined-Pair作为将该范式应用到广告系统应用中的鼻祖,提出了整合BCE loss和pairwise的排序loss。受Combined-Pair启发,其他形式的排序loss也被提出,比如hinge loss,triple-wise loss。
当然,也包括listwise排序损失,比如Google提出的 RCR:
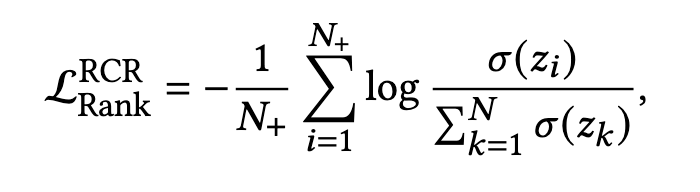
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是sigmoid函数
再比如,阿里提出的 JRC
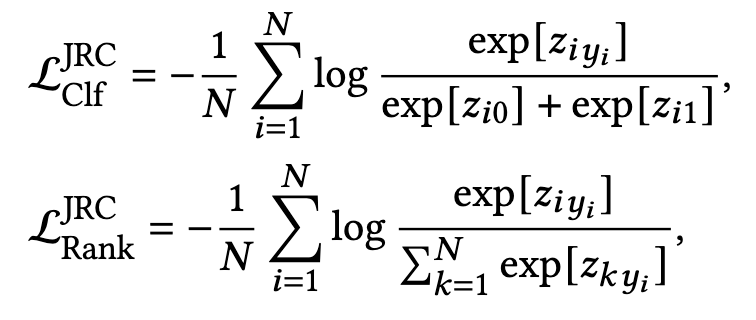
- z i 0 , z i 1 z_{i0},z_{i1} zi0,zi1 分别是第i个样本点击和未点击的logit
- z k y i z_{ky_{i}} zkyi 表示当i个样本是正样本时,第k个样本的点击logit;否则,则为第k个样本的未点击logit
3. 分类能力
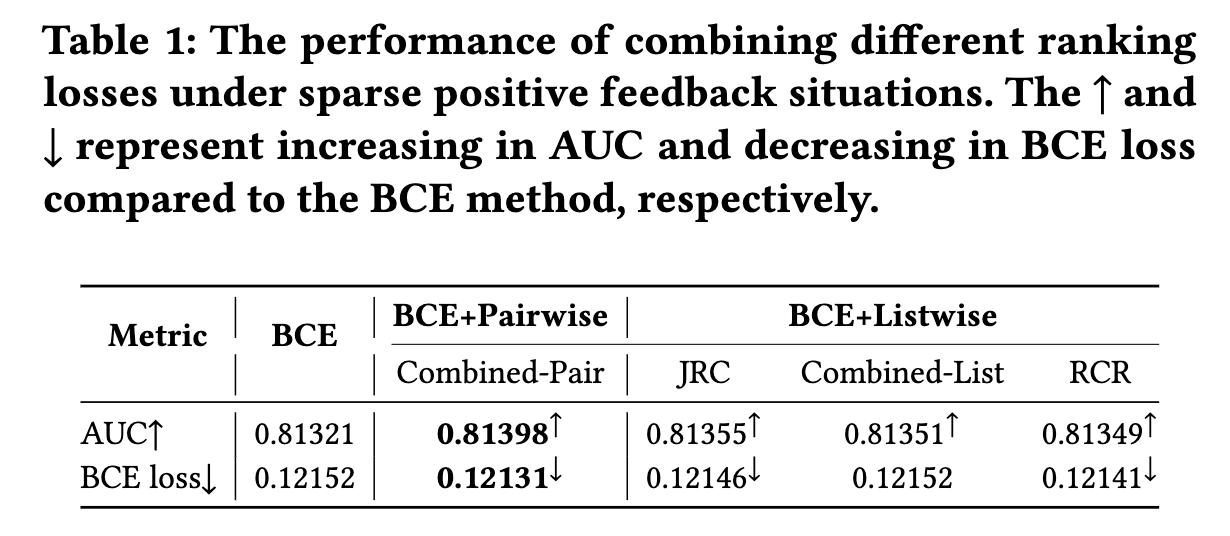
由于是针对广告系统的点击率任务,BCE loss便是必不可少的,因此论文最后使用的组合损失为BCE+排序loss,并且采用的是基于 hinge loss 的形式,具体如下式:
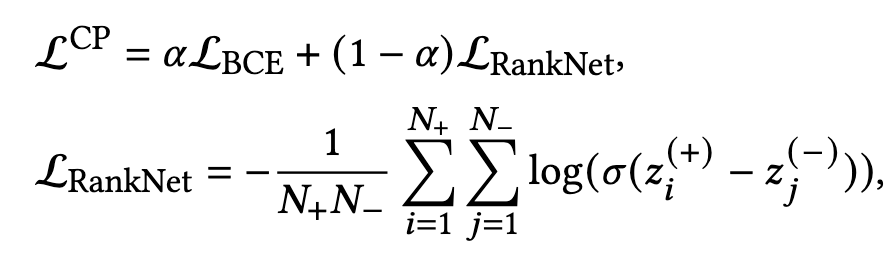
- N + , N − N_{+},N_{-} N+,N− 分别表示正样本和负样本的数量
- 后面会经常提及BCE和排序loss的组合方法,因此将组合损失称之为Combined-Pair方法,而仅使用BCE loss的称为BCE方法
上面提及的研究推断了BCE loss主要是提供了点击概率的推理能力,而在BCE loss的基础上加入排序loss可以提升排序能力。论文进一步试图去理清排序loss对主目标-CTR预估,即分类能力的影响。
于是,论文使用了Criteo数据集分别训练BCE和组合loss的模型,得到下图的结果:
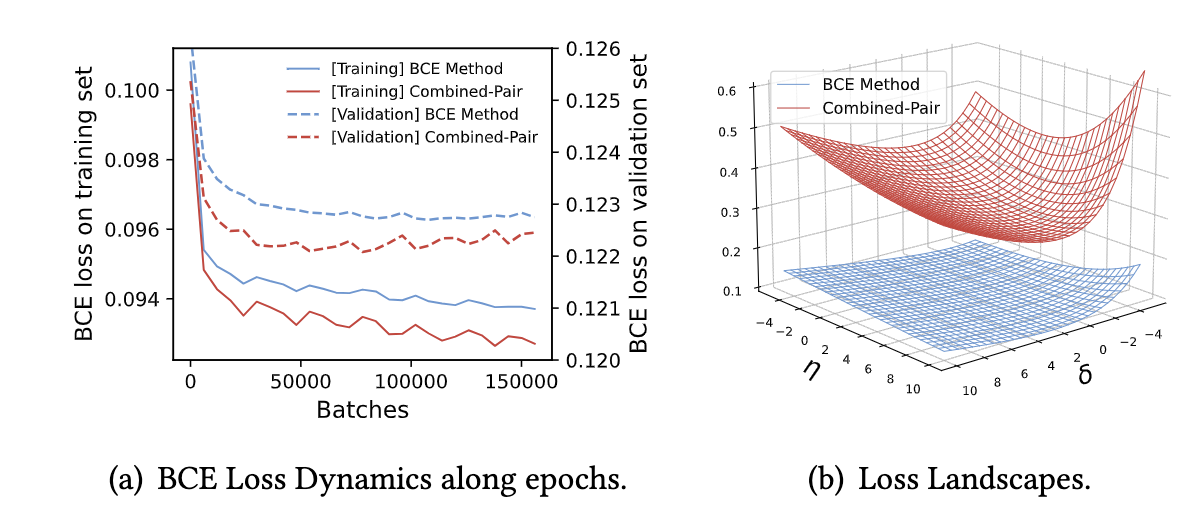
根据实验结果图,可以总结论文的两个发现点:
- 发现1:在验证集上,Combined-Pair方法的BCE loss下降得更快,并且比BCE方法获得更低的BCE loss,表明Combined-Pair方法不仅仅是提升了模型的排序能力,还提升了模型的分类能力
- 发现2:在训练集上,Combined-Pair方法的BCE loss下降得更快,并且也取得了更低的BCE loss,表明加入辅助的排序loss可以帮助BCE loss的优化
4. 梯度分析
除了数据实验,论文还从更深入的角度去分析这些实验结果背后的原因,从梯度入手去分析Combined-Pair和BCE方法。根据链式法则,每一层网络参数的梯度都是与logits的梯度成比例,因此可以从logits梯度入手去分析。
4.1 BCE 梯度
4.1.2 负样本的BCE loss梯度
对于负样本来说,BCE loss其实就需要取后面那一部分即可,且 y j = 0 y_j=0 yj=0,因此第j个负样本的 z j ( − ) z_j^{(-)} zj(−)梯度如下式:
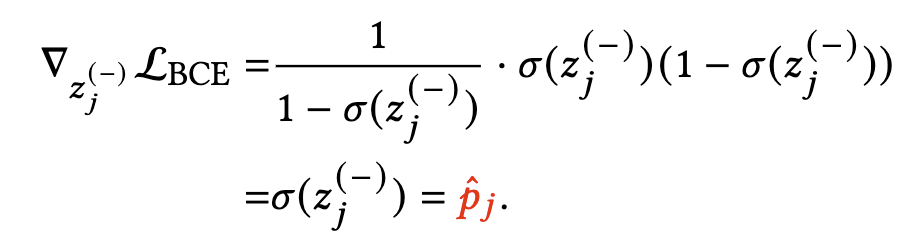
- 根据这个公式,可以看到负样本的梯度其实就等于模型预估的CTR p ^ j \hat{p}_j p^j
- 而 p ^ j \hat{p}_j p^j 的期望其实与全局CTR是接近,基本等于点击样本(正反馈)与全部样本的比率,这是因此BCE loss的全局最小化便是 σ ( z ) = E [ y ∣ x ] \sigma(z)=E[y|x] σ(z)=E[y∣x]
基于这个分析,可以得到:
发现3:当正反馈是稀疏(比如广告系统的CTR往往会低于2%)的,负样本会发生梯度消失,因为它们的梯度是与预估的正样本比率成正比的,而预估的正样本比率是一个非常小的预估值 p ^ j \hat{p}_j p^j 。
4.1.2 正样本的BCE loss梯度
那么,正样本是否也会出现同样的情况呢?
同样地,对于正样本样本来说,BCE loss只需要取前面那一部分即可,且 y i = 1 y_i=1 yi=1,因此第j个正样本的 z i ( + ) z_i^{(+)} zi(+)梯度如下式:
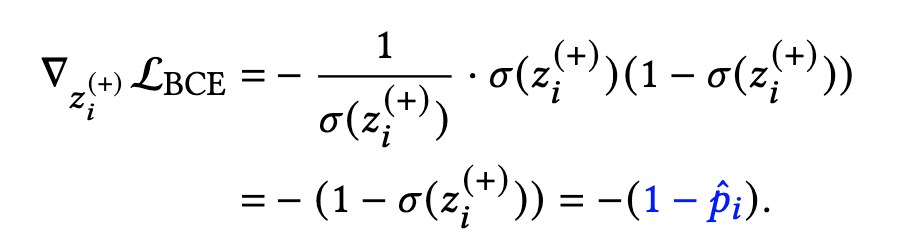
- 而 1 − p ^ i 1-\hat{p}_i 1−p^i 通常是一个比较大的值,如果同样是正反馈稀疏,那么 1 − p ^ i 1-\hat{p}_i 1−p^i甚至会接近于1
- 因此,正样本不会出现像负样本的梯度消失问题
4.2 Combined-Pair 梯度
Combined-Pair方法则包括两部分loss:BCE和排序loss。
首先来看看排序loss,第j个负样本的 z j ( − ) z_j^{(-)} zj(−) 梯度可以推导为下式:
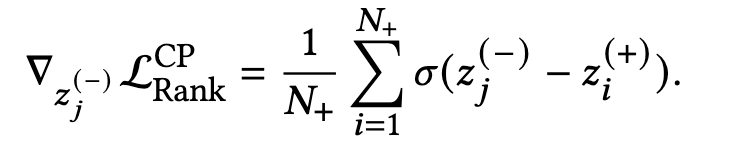
详细的推导过程如下:
∇ z j ( − ) L R a n k = ∇ z j ( − ) [ − 1 N + ∑ i = 1 N + l o g ( σ ( z j ( + ) − z j ( − ) ) ) ] = 1 N + ∑ i = 1 N + 1 σ ( z j ( + ) − z j ( − ) ) ⋅ σ ( z j ( + ) − z j ( − ) ) ( 1 − σ ( z j ( + ) − z j ( − ) ) ) = 1 N + ∑ i = 1 N + [ 1 − σ ( z j ( + ) − z j ( − ) ) ] = 1 N + ∑ i = 1 N + e − ( z j ( + ) − z j ( − ) ) 1 + e − ( z j ( + ) − z j ( − ) ) = 1 N + ∑ i = 1 N + e − ( z j ( + ) − z j ( − ) ) ⋅ e z j ( + ) − z j ( − ) e z j ( + ) − z j ( − ) + e − ( z j ( + ) − z j ( − ) ) ⋅ e z j ( + ) − z j ( − ) = 1 N + ∑ i = 1 N + 1 1 + e z j ( + ) − z j ( − ) = 1 N + ∑ i = 1 N + σ ( z j ( − ) − z j ( + ) ) \begin{align} \nabla_{z_j^{(-)}}\cal{L}_{Rank} &= \nabla_{z_j^{(-)}} [-\frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}}log(\sigma(z_j^{(+)}-z_j^{(-)}))] \\ &= \frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}} \frac{1}{\sigma(z_j^{(+)}-z_j^{(-)})} \cdot \sigma(z_j^{(+)}-z_j^{(-)}) (1-\sigma(z_j^{(+)}-z_j^{(-)})) \\ &= \frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}} [1 - \sigma(z_j^{(+)}-z_j^{(-)})] \\ &= \frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}} \frac{e^{-(z_j^{(+)}-z_j^{(-)})}}{1+e^{-(z_j^{(+)}-z_j^{(-)})}} \\ &= \frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}} \frac{e^{-(z_j^{(+)}-z_j^{(-)})} \cdot e^{z_j^{(+)}-z_j^{(-)}}}{e^{z_j^{(+)}-z_j^{(-)}}+e^{-(z_j^{(+)}-z_j^{(-)})} \cdot e^{z_j^{(+)}-z_j^{(-)}}} \\ &= \frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}} \frac{1}{1+e^{z_j^{(+)}-z_j^{(-)}}} \\ &= \frac{1}{N_+}\overset{N_+}{\underset{i=1}{\sum}} \sigma(z_j^{(-)}-z_j^{(+)}) \end{align} ∇zj(−)LRank=∇zj(−)[−N+1i=1∑N+log(σ(zj(+)−zj(−)))]=N+1i=1∑N+σ(zj(+)−zj(−))1⋅σ(zj(+)−zj(−))(1−σ(zj(+)−zj(−)))=N+1i=1∑N+[1−σ(zj(+)−zj(−))]=N+1i=1∑N+1+e−(zj(+)−zj(−))e−(zj(+)−zj(−))=N+1i=1∑N+ezj(+)−zj(−)+e−(zj(+)−zj(−))⋅ezj(+)−zj(−)e−(zj(+)−zj(−))⋅ezj(+)−zj(−)=N+1i=1∑N+1+ezj(+)−zj(−)1=N+1i=1∑N+σ(zj(−)−zj(+))
推荐系统或者广告系统中,CTR一般都不会很高,即正反馈都是相对稀疏的,正样本的比例会远低于0.5,那么正样本 z i ( + ) z_i^{(+)} zi(+) 对应的logit就小于0,这便导致了排序loss中负样本的梯度会比BCE loss大:
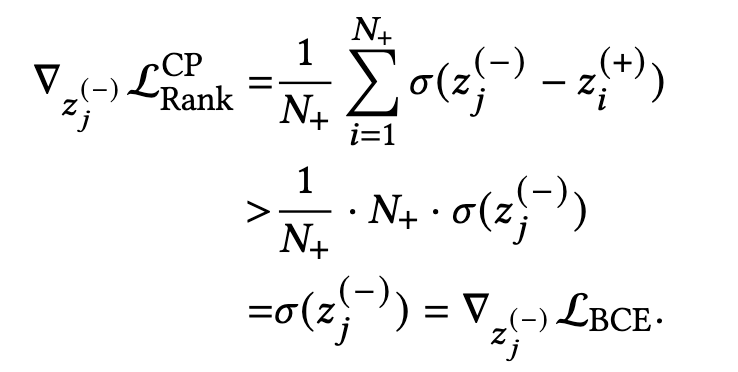
那么,Combined-Pair方法以任意比例去组合排序loss和BCE loss,都可以得到比单纯BCE loss更高的负样本梯度,推导如下式:
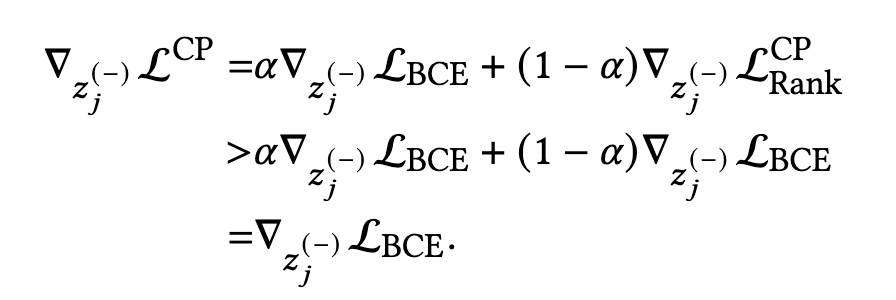
基于上述细致的梯度推导分析,可以得到:
发现4:对于正反馈稀疏的场景,Combined-Pair方法可以比BCE方法获得更大的负样本梯度。
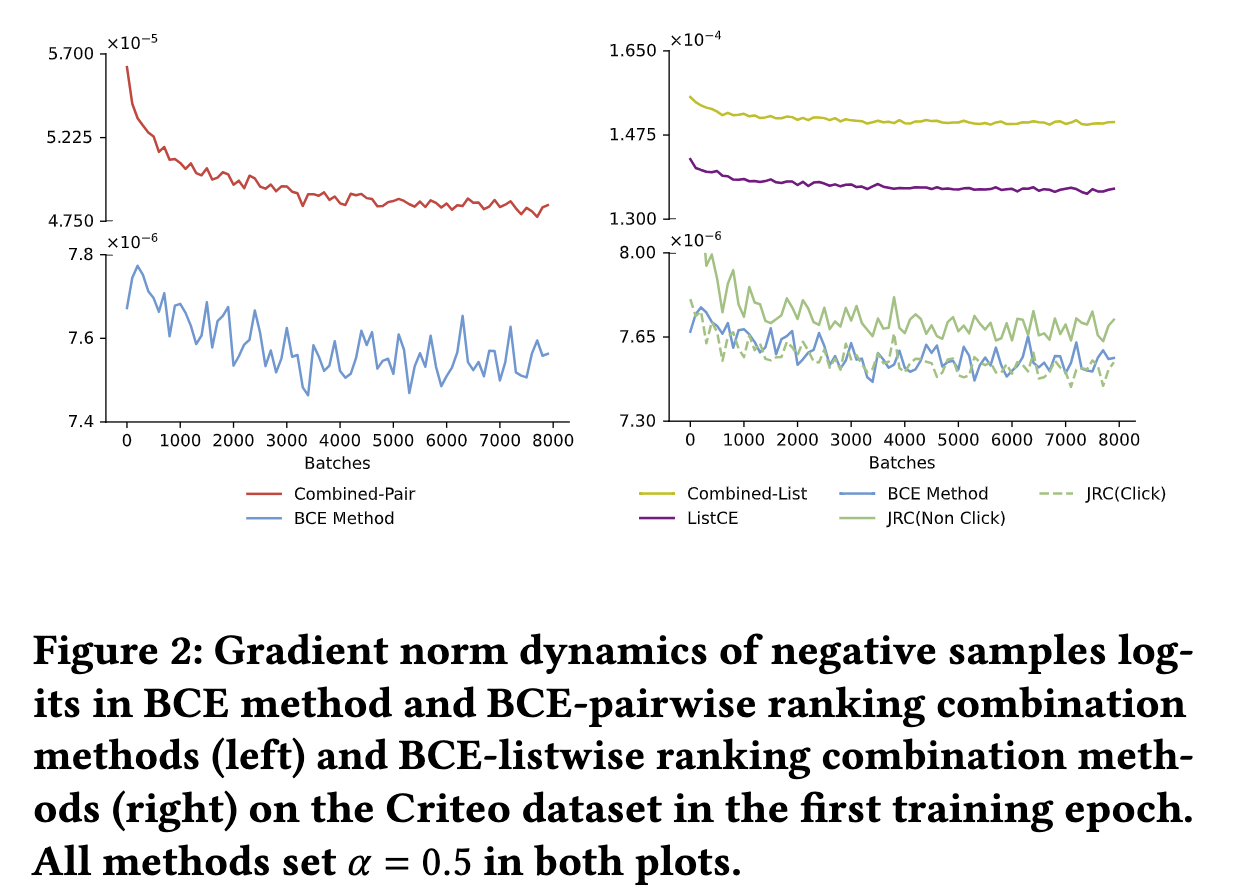
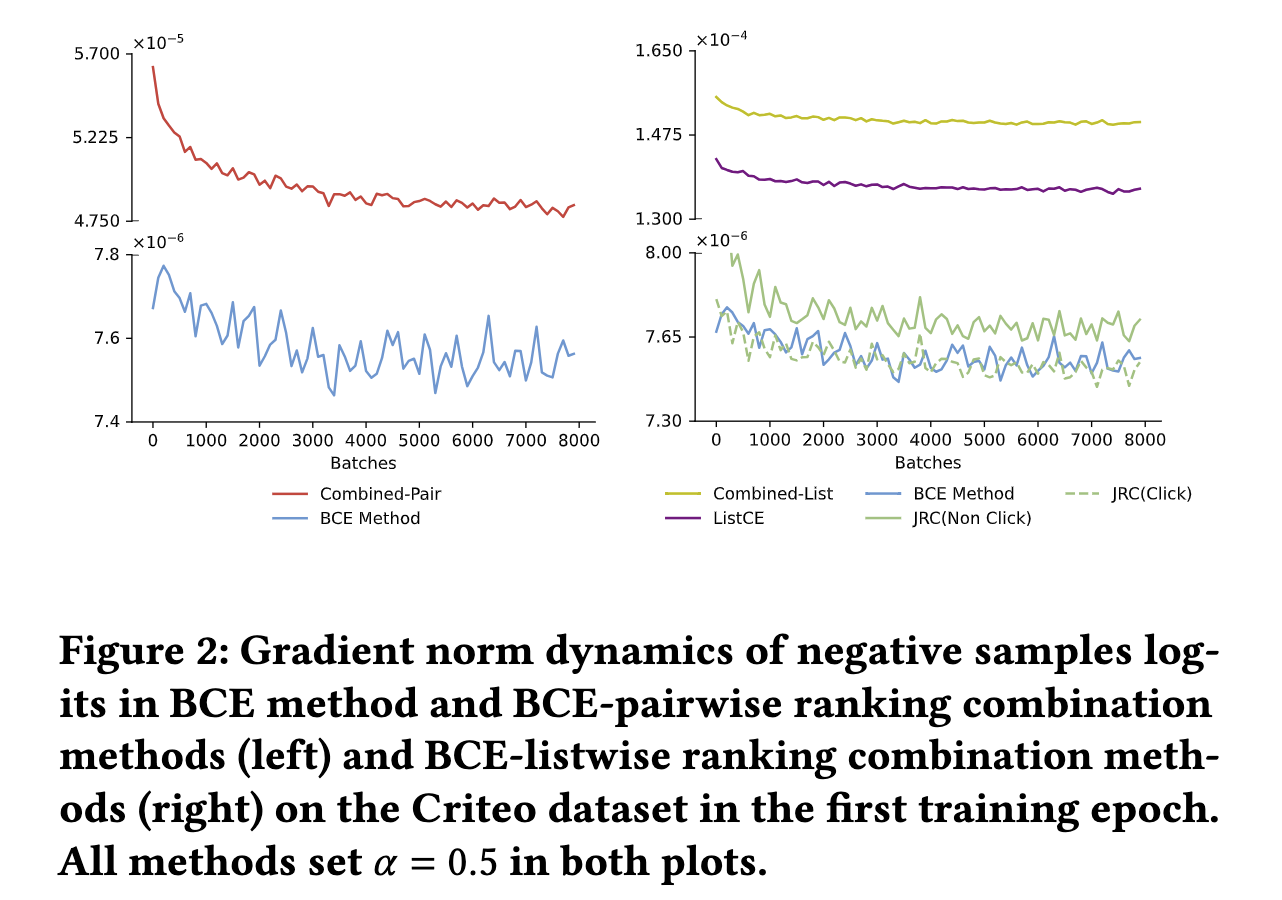
4.3 梯度消失实证
为了验证上述这些分析理论,论文通过实验来观察负样本的梯度norms的变化趋势。具体地,为了更贴近真实场景,将Criteo数据集的CTR调整为大约3.3%,并且观察第一轮训练中负样本logit梯度的变化,其梯度变化情况如下图:
- 可以看出,BCE方法产生的负样本的梯度norms相比于Combined-Pair方法小的许多,这是符合上述关于梯度的分析的。
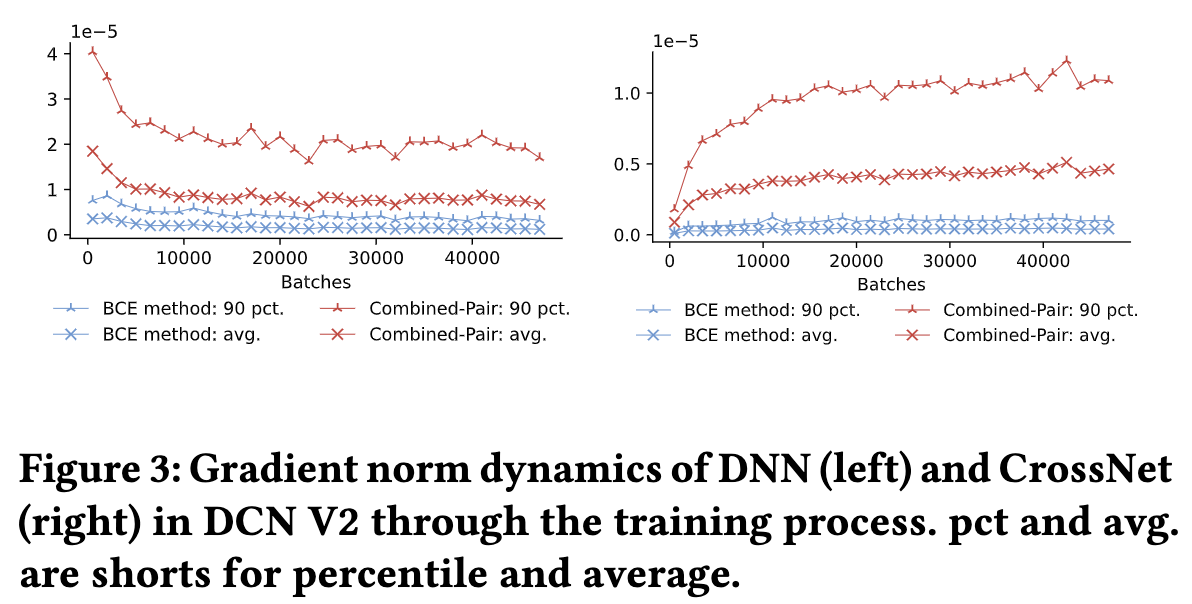
论文还更深入地去探究整个模型的可训练参数的优化过程。具体地,对比BCE方法和Combined-Pair方法,分别检查它们在DNN底部网络层的训练参数和DCN-V2 CrossNet的训练参数的梯度norms,为了更好地理解这个优化过程,论文分别计算梯度norms的90分位数和均值来展示它们的变化趋势,如下图所示:
- 可以看出,Combined-Pair方法仍然比BCE方法取得更高的梯度指标,并且持续了整个训练过程
- 这个实验更加验证了Combined-Pair方法可以有效地缓解负样本梯度消失的问题
5. 研究问题
Criteo数据集本身的CTR高达25.6%,比真实场景是偏高的,论文通过对正样本降低权重来控制正样本的稀疏程度:
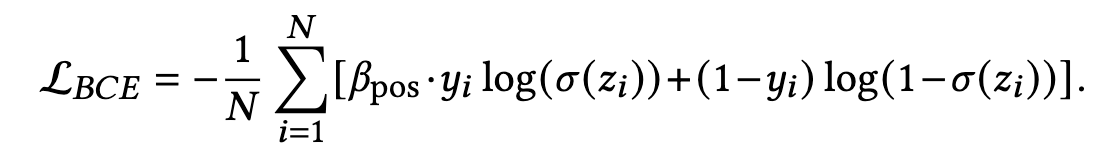
比如, β p o s \beta_{pos} βpos 设置为0.1,那么数据集正样本的稀疏比例就变为了: 25.6 % × 0.1 25.6 % × 0.1 + 1 − 25.6 % = 3.3 % \frac{25.6\% \times 0.1}{25.6\% \times 0.1 + 1 - 25.6\%}=3.3\% 25.6%×0.1+1−25.6%25.6%×0.1=3.3%
5.1 RQ1 不同稀疏比的效果
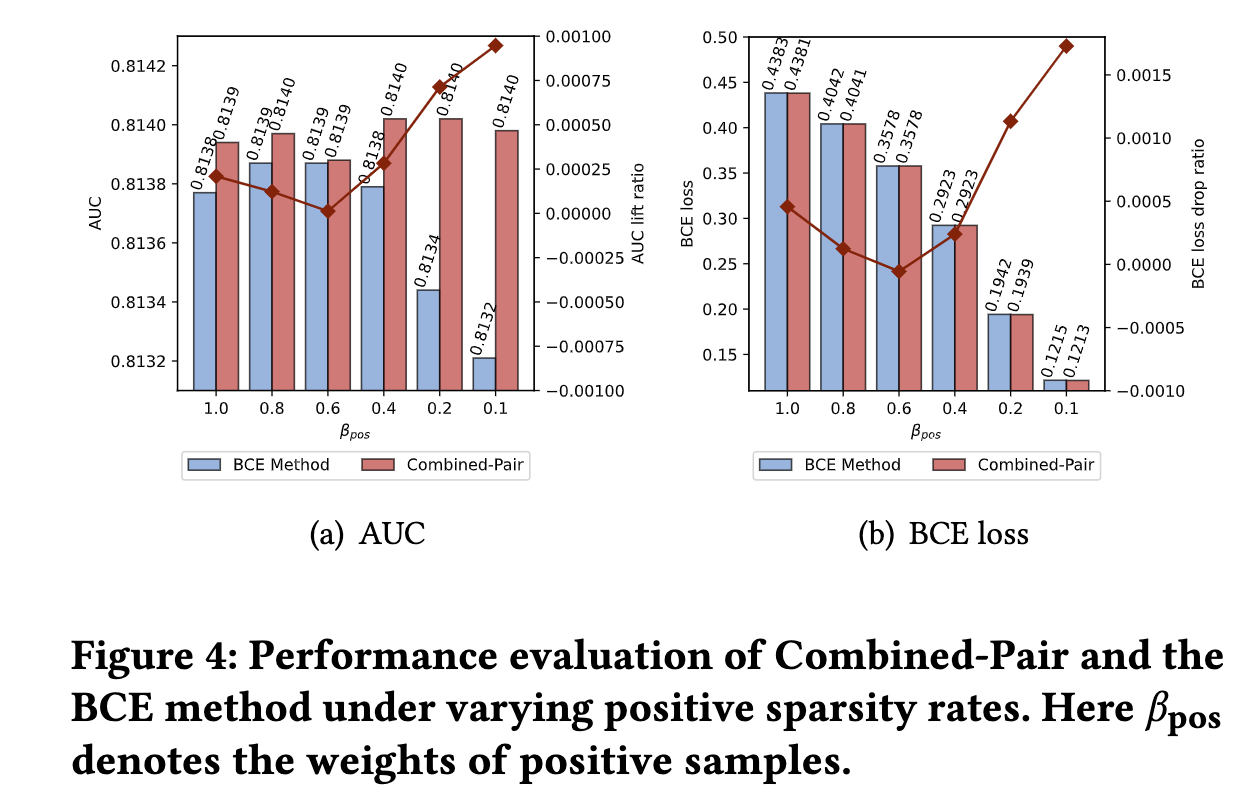
论文通过调整 β p o s \beta_{pos} βpos来获得不同正反馈稀疏比例的数据,期望Combined-Pair方法都能够获得比BCE方法更好的表现。
具体地,分别设置了 β p o s \beta_{pos} βpos为0.8,0.6,0.4,0.2,0.1,显而易见,越小的 β p o s \beta_{pos} βpos,数据集的正反馈越稀疏。最终展现的结果如下图:
- 可以看出,不同的稀疏比例下,Combined-Pair方法都能够取得比BCE方法更好的效果;
- 特别地,当 β p o s = 0.6 \beta_{pos}=0.6 βpos=0.6下降到 β p o s = 0.1 \beta_{pos}=0.1 βpos=0.1,AUC上升比例从0.020%上涨到了0.095%,BCE loss下降比例从0.045%上涨到了0.168%
- 因此,这些实验结果可以验证,当正反馈稀疏比例达到一定的阈值(0.6),Combined-Pair方法可以比BCE方法取得更大的提升效果
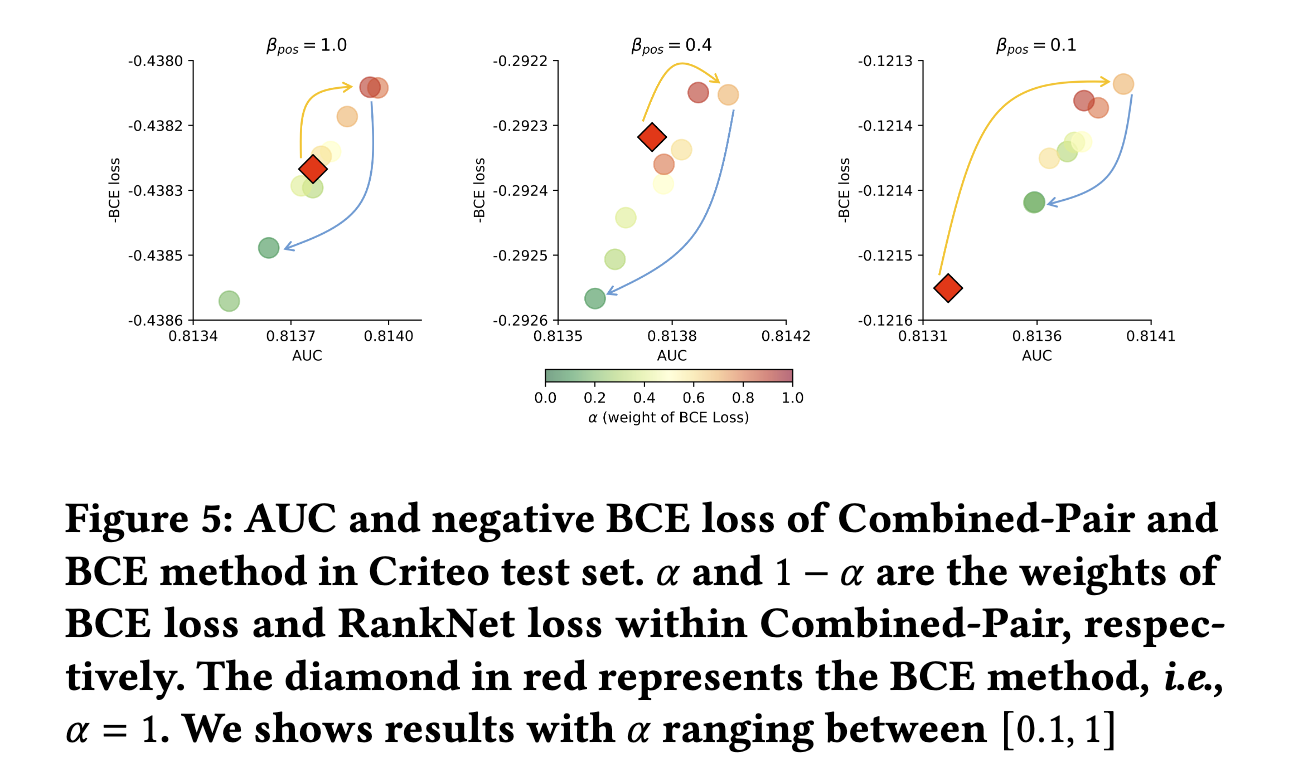
5.2 RQ2 组合损失权重
这个研究问题的目的是检查分类和排序loss之间的均衡。具体地,在Combined-Pair方法,使用一个参数 α \alpha α 从1.0到0.1来控制两个loss的权重。
从 α = 1.0 \alpha=1.0 α=1.0开始,即使用BCE方法,逐渐减小 α \alpha α,下降BCE loss的权重,也即提升排序loss的权重,然后观察AUC和BCE loss的变化,如下图:
- 观察橙色剪头,当 α \alpha α从1.0下降到0.7时,AUC从0.8132上升到了0.8139,BCE loss从0.1215下降到了0.1213。这表明** α \alpha α到一个阈值的递减,可以使分类和排序能力递增**
- 观察蓝色剪头,当继续减小 α \alpha α之后,排序loss会变成主导的loss,分类和排序能力都产生退化
- 但,当正反馈极其稀疏的情况下( β p o s = 0.1 \beta_{pos}=0.1 βpos=0.1),即使排序loss占据非常大的权重( 1 − α = 0.9 1-\alpha=0.9 1−α=0.9),Combined-Pair方法表现仍然比BCE方法好
5.3 RQ3 不同排序loss的效果
除了pairwise loss,论文还实验了listwise loss的组合方法,探究能否取得与Combined-Pair相似的结果,从下面两张图可以看出:
- 不同的ranking loss与BCE loss进行组合,都能够提升分类和排序的效果
- 这也再次证明引入排序loss的组合损失方法,能够通过缓解负样本的梯度消失问题,提升最终的效果
5.4 RQ4 Combined-Contrastive
论文还研究了除了排序损失之外的方法,是否也能够缓解负样本的梯度消失问题,进而取到效果的提升。
5.4.1 Focal Loss.
第一个便是Focal loss,我们在以前的文章介绍,有兴趣的可以去这个文章看详细的介绍,其初衷是为了介绍样本分类不均衡的问题:
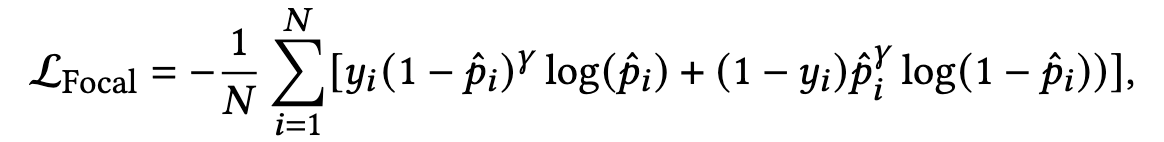
-
γ \gamma γ 是来控制相对权重的
-
论文试图通过Focal loss的范式,让那些BCE中存在梯度消失问题的负样本分配更高的权重 p ^ i γ \hat{p}_i^{\gamma} p^iγ
但,由于 p ^ i γ \hat{p}_i^{\gamma} p^iγ 是必然小于1.0的,因此Focal loss中负样本的梯度norm正常是小于BCE loss的,论文对其进行一些改造,如下式:
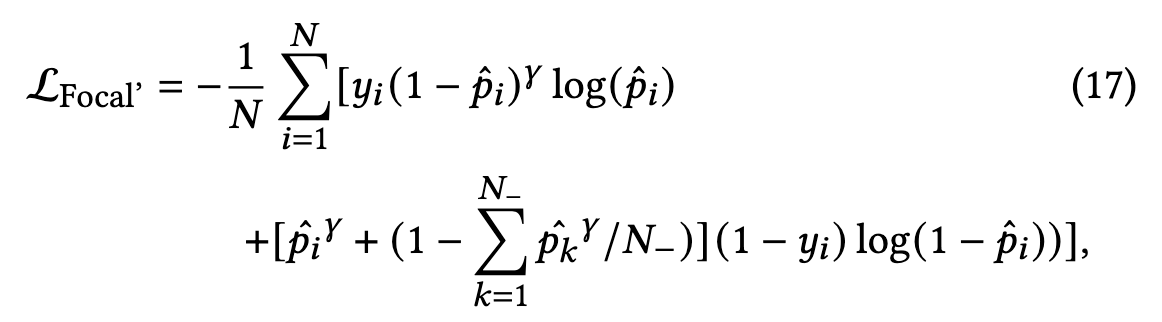
5.4.2 负采样.
第二个是负采样。通过负样本来降低负样本的比例,从而提高预估CTR。根据文章上述第4节的分析,这可以增加负样本的梯度。但是,负采样往往会造成一些信息的损失。
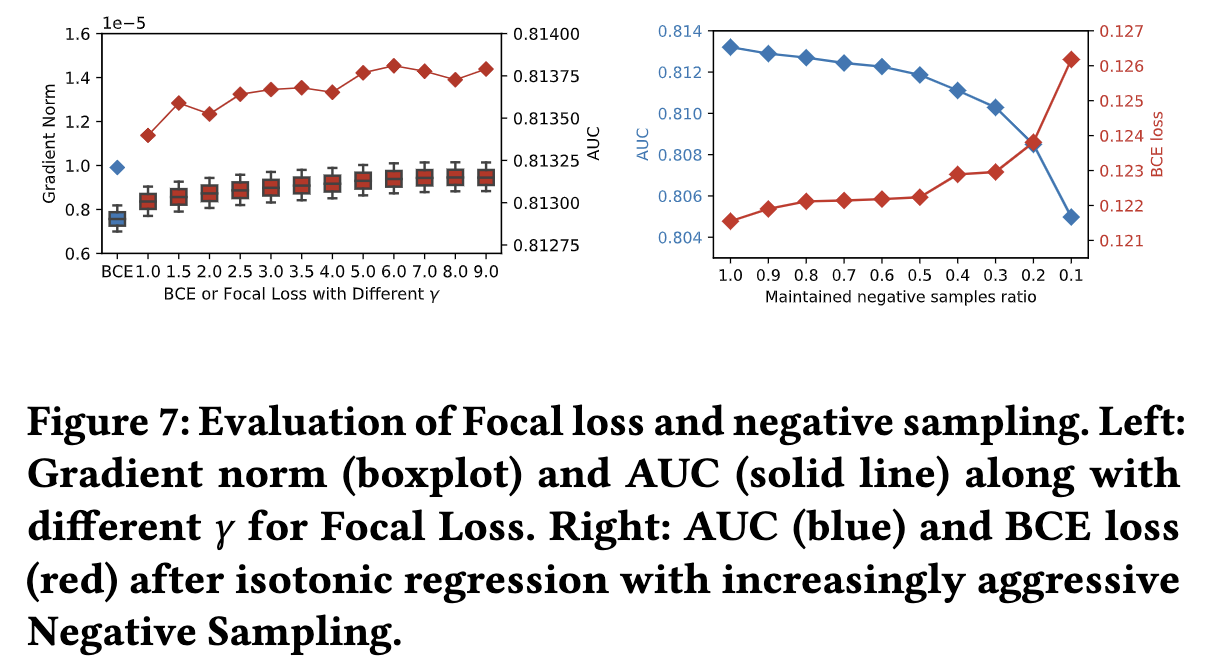
- 从上图左看出,为那些负样本(分类稀疏的样本)分配更大的权重,可以取得比BCE方法更大的负样本梯度,从而提升效果
- 从上图右看出,负样本的力度更大,即下采样的比例更大,会造成排序和分类的能力退化
5.4.3 Combined-Contrastive
除了在现有的方法(Combined-Pair,Focal Loss)上验证上述所提出的观点,基于这些观点,论文还提出了新的方法:Combined-Contrastive。论文推断引入包含label信息的辅助损失,可以提供比BCE方法更大的梯度,从而缓解负样本梯度消失的问题。
Combined-Contrastive是受 Supervised Contrastive Learning 启发,在BCE loss的基础上Contrastive loss,让相同类别的embeddings更相近,而让不同类别的embeddings保证明显的分离。具体公式如下:
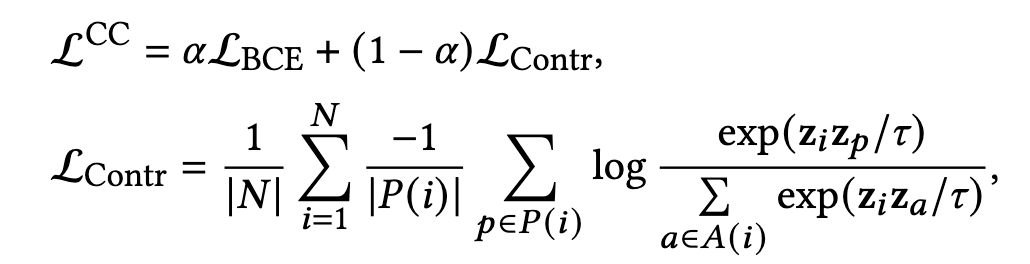
- N N N 是当前批次样本的数量
- A ( i ) A(i) A(i) 是除了第i个样本本身以外的其他全部样本集合
- P ( i ) P(i) P(i) 是 A ( i ) A(i) A(i) 里与第i个样本相同label的样本集合
- z i z_i zi 是第i个样本的embedding
- α = 0.9 , τ = 0.4 \alpha=0.9,\tau=0.4 α=0.9,τ=0.4,最后Combined-Contrastive取得的效果如下图
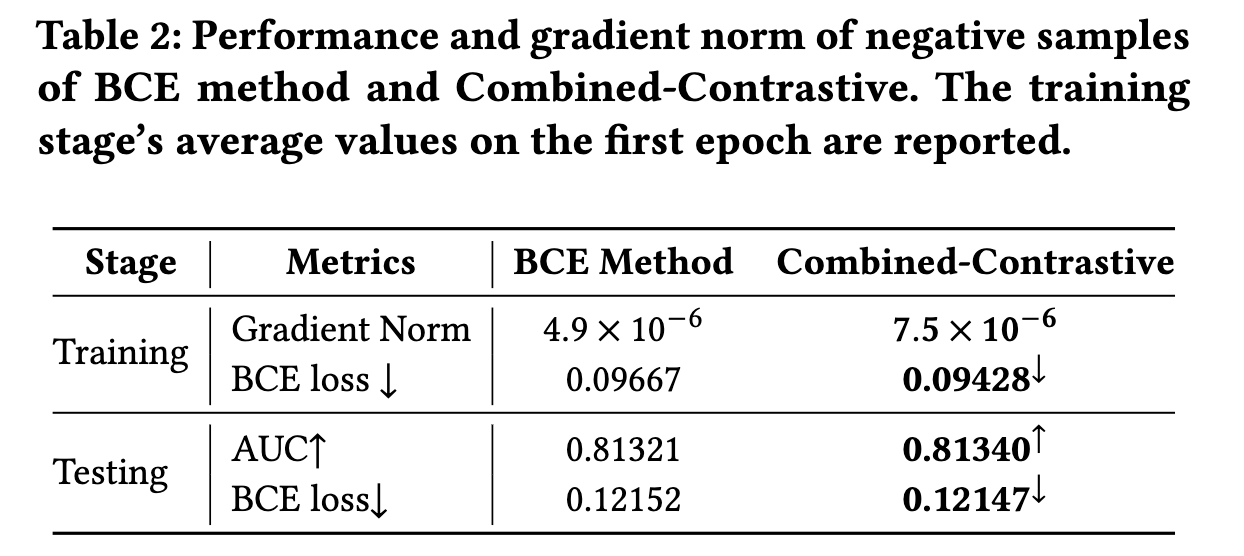
6. 总结
这篇论文的核心思想是在正反馈比较稀疏的场景,比如推荐系统或广告系统等,BCE loss会出现负样本梯度消失的问题。而Combined-Pair方法则是在BCE loss的基础加上排序loss,能够缓解负样本梯度消失的问题,提升模型的分类和排序能力。
代码实现:
tensorflow 2.x:examples/tin_ranking_loss.py
tensorflow 1.x:recommendation/utils/losses.py


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









