






一.各浏览器对于字符编码别名支持的宽泛程度存在差异
根据 HTML4.01 规范中的描述,服务端应该提供给用户端文档的字符编码(character encoding)信息,最直接的方式为通过 HTTP 协议中的 "Content-Type" 头字段的 "charset" 将文档的字符编码告诉用户端。例如以下 HTTP 头声明了字符编码为 ISO-8859-1:
Content-Type: text/html; charset=ISO-8859-1
但是处于某种情况无法访问服务器时,HTML 文档可以包含有关文档的字符编码的明确信息,
META
元素可以用来为用户端提供这些信息。例如指定当前文档的字符编码为 ISO-8859-1,文档中应包含如下 META 声明:
<META http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
当 HTTP 协议与 META 元素均没有提供有关一个文档的字符编码信息时,HTML 还为一些元素提供了
charset
属性。结合这些机制,作者可以在很大程度上提高当用户获取资源时用户端识别字符编码的机会。
如何确定一个文档的字符编码
用户代码必须遵守下面的优先级顺序(优先级由高至低):
1、HTTP "Content-Type" 字段中的 "charset" 参数。
2、META 声明中 "http-equiv" 为 "Content-Type" 对应的值中的 "charset" 的值。
3、元素的 charset 属性。
问题描述:
各浏览器对于字符编码别名支持的宽泛程度有差异,当指定了浏览器无法识别的字符编码别名时,浏览器会以
确定编码的优先级顺序采用设置的更低优先级
的字符编码,以此类推。
而 Chrome Safari Opera 中对字符编码别名有着比其他浏览器更宽泛的支持。
造成的影响:
若字符编码别名设置不当,则会造成页面在某些浏览器中出现文字编码错误,导致页面无法阅读。
问题分析:
我们通常情况下为页面设定的字符编码信息所对应到浏览器内部大多是字符编码别名,如 ISO-8859-1。
1、首先分析当 HTTP "Content-Type" 头字段的 "charset" 参数与页面中 META 元素声明中 "http-equiv" 为 "Content-Type" 对应的值中的 "charset" 的值不同时各浏览器所采用的字符编码。
<?php
header("Content-Type: text/html; charset=
BIG5
");
?>
<!DOCTYPE HTML>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=
UTF-8
"/>
</head>
<body>
<script>
document.write((document.charset || document.characterSet).toUpperCase());
</script>
</body>
</html>
上面是一段 PHP 代码,HTTP "Content-Type" 头字段设置了字符编码为 BIG5,页面中的 META 元素设置了字符编码为 UTF-8,页面本身的编码类型为 GB2312。页面执行时,通过脚本输出了当前浏览器所采用的字符编码类型。
这个动态页面在各浏览器中运行时均显示出了 BIG5,可见此时所有浏览器均遵照 HTML4.01 规范所述,以更高优先级的 HTTP "Content-Type" 头字段的 "charset" 参数的值作为字符编码类型。
2、在继续接下来的分析之前,先统计一下各浏览器对于没有任何字符编码设定的页面所采用的编码类型:
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<script>
document.write((document.charset || document.characterSet).toUpperCase());
</script>
</body>
</html>
上面页面中没有设定任何的字符编码信息,则各浏览器对于这个页面将使用各自的默认编码
1
。页面自身的编码为
GB2312
。
各浏览器中运行效果如下:
|
IE6 IE7 IE8 Firefox
|
Chrome Safari
|
Opera
|
|
字符编码 --- GB2312
|
×Ö·û±àÂë --- ISO-8859-1
|
字符编码 --- GBK
|
当页面没有设置任何字符编码信息或者浏览器无法识别 HTTP 头字段以及 META 元素中所声明的字符编码信息时,所有浏览器均会以各自在当前语言版本下的默认字符编码显示页面。
本例中,因为页面自身的编码为
GB2312
,则 Windows 平台下
IE Firefox Opera
简体中文版的默认字符编码刚好为
GB2312
,所以页面中的字符显示正常。
3、下面看一组特殊的例子:
<?php
header("Content-Type: text/html; charset=maccyrillic");
?>
<!DOCTYPE HTML>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=b.i.g+5"/>
</head>
<body style="font:24px Tahoma;">
字符編碼 ---
<script>
document.write((document.charset || document.characterSet).toUpperCase());
</script>
</body>
</html>
上面的动态页面自身的编码为
BIG5
,HTTP "Content-Type" 头字段设置了字符编码为
maccyrillic
,页面中的 META 元素设置了字符编码为
b.i.g+5
。
各浏览器中运行效果如下:
|
IE6 IE7 IE8 Firefox
|
Chrome Safari
|
Opera
|
|
才絪絏 --- GB2312
|
¶r≤≈љsљX --- X-MAC-CYRILLIC
|
字符編碼 --- BIG5
|
§ 在
IE6 IE7 IE8 Firefox
中,浏览器无法识别
maccyrillic
这种字符编码别名,所以寻找更低优先级的 META 元素声明的字符编码,但发现也无法识别
b.i.g+5
这种字符编码别名,继而采用了当前语言版本的默认编码 GB2312,与页面自身的字符编码
BIG5
不相符,导致页面中的文字显示异常。
§ 在
Chrome Safari
中,浏览器将
maccyrillic
识别为合法的
X-MAC-CYRILLIC
,则不再理会更低优先级的编码设置,页面采用
X-MAC-CYRILLIC
作为字符的编码,与页面自身的
BIG5
编码不符,导致页面中的文字显示异常。
§ 在
Opera
中,浏览器无法识别
maccyrillic
这种字符编码别名,所以寻找更低优先级的 META 元素声明的字符编码,将
b.i.g+5
这种字符编码别名识别为
BIG5
,刚好与页面自身的
BIG5
字符编码相符,所以页面中的文字显示正常。
出现上述现象的原因主要有三点:
1、各浏览器的字符编码别名表不尽相同,对同一种编码下的各种别名支持的宽泛程度不一样。像 maccyrillic 这种别名在 Chrome Safari 可以识别为通用的 X-MAC-CYRILLIC
1
,但其他浏览器则会将其视作错误的字符编码信息处理。
2、各浏览器在匹配页面的字符编码与别名表中的字符编码时,匹配的方式不同。Chrome Safari Opera 会将编码类型的字符串做一个转换,过滤了除英文大小写字符、数字字符之外的字符(isASCIIAlphanumeric)。如 ISO8859_5 会以转换后的 ISO88595 与别名表中的 ISO-8859-5 转换后的 ISO88595 做比较,b.i.g+5 也会转换为 big5 与别名表中的做比较,所以浏览器可以正确识别这些设置的字符编码为浏览器内部的别名。
3、各浏览器的默认字符编码不同。
解决方案:
1、* 对于动态页面必须确保 HTTP "Content-Type" 头字段的 "charset" 参数与页面自身编码相符,且务必在页面的 META 元素中也声明相符的字符编码信息。
* 对于静态页面,必须保证页面中 META 元素声明中 "http-equiv" 为 "Content-Type" 对应的值中的 "charset" 的值与页面自身编码相符。
2、其次,在设置字符编码别名时,最好使用最通用的、各浏览器均可识别的编码别名。
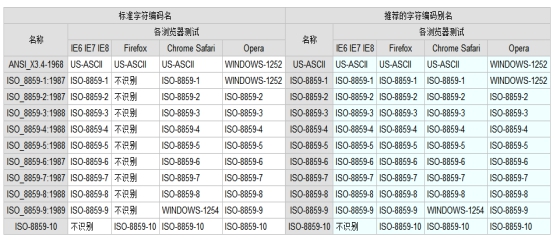
下面列出了部分的字符编码及其推荐的通用的别名在各浏览器中的支持情况:
二.
各浏览器在HTML页面与页面中引入的外部CSS文件编码不一致时表现不同
标准参考
根据 CSS 2.1 规范的描述,应按照以下优先级来确定一个外部 CSS 文件的编码:
1、HTTP 响应头中 "Content-Type" 字段的 "charset" 参数指定的编码。
2、BOM 以及/或者 @charset 定义的编码。
3、<link charset=""> 或其他链接机制提供的元数据(如果有的话)指定的编码。
4、引入该 CSS 文件的 HTML 或另一个 CSS 文件(如果有的话)中已确定的编码。
5、如果以上几步都没能确定编码,则假定其编码为 UTF-8。
问题描述
如果一个外部 CSS 文件的编码与引入该文件的 HTML 文件的编码不一致,并且没有
显式的声明
该 CSS 文件的编码,在某些情况下会造成 CSS 的解析错误。
造成的影响
该问题将造成页面布局在一些浏览器中与预期的效果不符。
问题分析
对于一个未显式声明编码的 CSS 文件,浏览器会将其编码认为与引入该文件的文件的编码一致。在一些特定的情况下,将造成 CSS 代码解析异常。举例如下:
HTML 代码(编码为 UTF-8):
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"/>
<link rel="stylesheet" type="text/css" href="css.css"/>
</head>
<body>
<h1>内容文本</h1>
</body>
</html>
以上页面引入的 css.css 的代码(编码为 GB2312):
h1 {
margin:0;
width:100px;
height:100px;
background:blue;
font:20px/100px "黑体";
text-decoration:underline;
color:red;
}
假设上述两个文件均为在 HTTP 响应头中设定编码,在各浏览器中表现如下:
|
IE6
|
其他浏览器
|
|
|
|


可见,IE6 把 CSS 文件从“黑体”二字到规则结束的样式都没有起作用,其他浏览器中仅“黑体”二字解析错误。
产生这种差异的原因是各浏览器对与这种错误的容错方式不同。
按照规范的规定,在这种情况下,浏览器会认为 CSS 文件的编码与页面一致,即 UTF-8,但 GB2312 编码下的一个中文字符是 2 个字节,在 UTF-8 编码下则为 3 个字节,在把 GB2312 编码下的“黑体”二字当作 UTF-8 编码的文字来解析的时候,得到的是“����”,这并不是预期的值。正是这个值导致了样式定义在各浏览器中都无法按照预期被解析。
解决方案
当 HTML 文件或 CSS 文件要引入一个不同编码的 CSS 文件时,要明确声明被引入的 CSS 文件的编码。
如以上的举例,在 CSS 文件的开头加上一行
1
:
@charset "GB2312";
或者在各文件的 HTTP 响应头中声明该文件实际使用的编码。
注:1. 虽然 CSS 2.1 规范也允许在 LINK 标签上添加 'charset' 属性来
指定编码,但
IE6 IE7 IE8(Q)
不支持。
(前端小白,如有错误,欢迎指正~~)















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









