







Galaxy Zoo Challenge解决方案小结
1.过拟合
如果不过拟合,说明你的网络不够大。模型过拟合问题缓和:
(1)数据增广(2)Dropout和权重归一化约束
(3)修改网络架构来增加参数共享
2.预处理和数据增广
a.剪裁和下采样
424*424的彩色图像裁剪成207*207,3倍下采样成69*69,使得网络的输入大小可管理。
b.利用空间不变性
空间上没有上下之分,一定程度的旋转和平移不变性。利用已有数据创建新的数据。
旋转:0到360度随机旋转(均匀分布)平移:相对与原始图像(424*424),在x轴或y轴上随机平移-4到4个像素
缩放:随机缩放尺度范围为[-1.3,1.3](log均匀分布)
翻转:是或否(伯努利分布)
由于下采样和随机扰动都是 仿射变换(用scikit-image)。
c.颜色扰动
图像颜色的第一部分特征值远大于其它两个,尺度因子alpha的标准差设为0.5。
d.“实时”增广
GPU在训练当前数据块时,CPU会在多个过程中产生下一个数据块。
e.定中心和重新缩放
提取了 星系的中心和Petrosian半径。把中心移动到图像中心(212,212)并重新缩放至Petrosian半径等于160个像素。缩放因子范围为(1/1.5,1.5),因为有些是异常点。同样可以看作仿射变换。
f.输入=原始像素
3.网络架构
a.利用旋转不变性增加参数共享
图像裁剪成207*207大小加上3倍下采样后,完成后有2个方向:1个常规剪裁和1个旋转45度后的剪裁。两次剪裁都要水平翻转,结果有4张69*69大小的图像。生成的4张图片被分成相互覆盖的45*45大小的部分,每部分都要旋转使得星系在图像的右下角。
综上,每张原始图像最后会提取16张图像。
16张45*45的小图像很相似,由于旋转不变性所以它们应该有着相同的拓扑结构,可以用相同的卷积架构处理,结果是16倍的参数共享,过拟合程度减少。
16部分提取的特征级联和连接到1个或多个密集层,所以信息是汇总的。
这个方法的一个美妙的副作用是网络卷积部分有效块大小增加到16折,因为16部分彼此堆叠,使GPU并行化更加容易。
考虑到图像的覆盖,很多信息在星系中心是有效的,因为它被卷积网络在16个不同方向上被处理。这个很有用因为星系的一些重要属性应该在图像的中心。减少相互的覆盖率将导致性能下降。不选择部分全覆盖,因为会使训练速度大幅减缓。
b.插入输出约束
37个输出要预测的是带权重的附带很多约束的概率。将这些约束插入模型也非常有用。本质上,每个问题的答案应该形成类型分布。另外,它们被要问的问题的概率(即已知问题的全部概率)缩放。
最初的想法是对每个问题使用1个softmax输出,然后使用缩放因子。这并没有太大差别。我相信这个是因为softmax函数预测训练数据中很多0和1比较困难。
如果交叉熵是误差矩阵,这并不是什么大问题。但这个比赛提交的矩阵是均方根误差(RMSE)。结果预测很小和很大的概率会很有用。
最后,我为每个问题归一化分布,通过在顶层添加整流非线性而不是softmax函数,然后使用分裂的归一化。比如,如果问题1的网络顶层的原始线性输出为z1,z2,z3,那么问题1的实际输出为max(z1,0)/(max(z1,0)+max(z2,0),max(z3,0)+epsilon)。epsilon为非常小的常数以防止除0的错误,设置为1e-12。这种方式使得网络预测0更加容易。
Theano闪光之处是:我可以写出它们是什么来简单地将这些约束插入模型-不需要手动计算所有改变的梯度。非常节省时间!
c.最优的网络架构
找到的最优模型以 Krizhevsky样式的图给出。最后集成的所有其它模型都是这个模型的变种。模型的输入为45*45的RGB彩色图像。
模型有7层:4个卷积层和3个密集层。 所有的卷积层都包含1个ReLU非线性(即f(x)=max(x,0))。第1,2,4卷积层后有2*2的最大池化。层的大小和滤波器的大小如图所示。
如前面所提,网络的卷积部分的输入为输入图像的16个不同的部分。所有这些部分提取的特征都会汇总并连接到网络的密集层。
密集层包含2个带2048个单元的maxout层。两个都采用线性滤波器对(共4096个线性滤波器)的最大值。相对于带4096个线性滤波器的密集层来说,这里 用maxout而不是带ReLU的常规的密集层极大地减少了过拟合。在网络的卷积部分使用maxout计算也很快。
d.变种
4.训练
a.验证
为了验证,我们将训练集分为两个部分。我用前90%作训练且剩余的作验证。比赛的最后试着在包含分离的验证数据的整个训练集上重新训练1个模型,但我注意到在公共排行榜的表现没有增加。然而分离的验证集在模型平均上派上了用场。
b.训练算法
用随机梯度下降和Nesterov动量来训练网络。用16个例子作为小块的大小。这就意味着卷积部分的有效块的大小为256。这个有效是因为 cuda-convnet卷积为128的倍数的小块大小优化。训练网络大约1.5百万次,用两个离散降低的学习率模式。开始时学习率设置为0.04。1.1百万步后减少10折至0.004,然后1.1百万步后再次至0.0004。对前600个梯度步,输出层的离散归一化失能。这是必要的来确保收敛(否则有时将在开头卡住)。
c.初始化
参数初始化的一些摆弄对合理训练网络有益的。大多数层权重初始化值来自均值为0,标准差为0.01的高斯分布,偏差初始化为0.1。最顶层的卷积层增加标准差至0.1。密集层降至0.001,偏差初始化为0.01。
d.正则化
Dropout以1个0.5的Dropout概率被用在这3个密集层。能够训练网络这个绝对是必要的。比赛末尾也为maxout层用模约束正则化。为不带约束常数正则化的基于网络的模的直方图的每层选择最大模(选择它让直方图的尾部剔掉)。不完全确定是否有用。
5.模型平均
a.转换后图像平均
对于每个模型,为测试集图像的60个仿射变换来预测:10个旋转(间隔36度)的结合,3个重缩放(尺度因子为1/1.2,1和1.2)和翻转/不翻转。这些为均匀平均。尽管模型结构已经插入很多方差。为1个模型计算这些平均测试集预测花费4小时。
b.结构平均
6.大杂烩
下面是未用的一些东西-不是因为对性能没有帮助,也不是因为它们对训练速度减缓不少。
a.训练时给输入图像添加高斯噪声来减小过拟合,然并卵。
b.不同的尺度从图像中剪裁,且在它们上训练1个多尺度卷积网络。结果只有细节最多的尺度的网络部分学习到了东西。其它部分没有接收到梯度且不在学习。
c.下采样输入图像(1.5*而不是3*),且在第1层用大步的卷积(步长为2)。但结果没有提高,且大幅增加存储空间的使用。
d.数据增广步骤中增加shear。但也没有用。
7.最优模型的网络结构计算
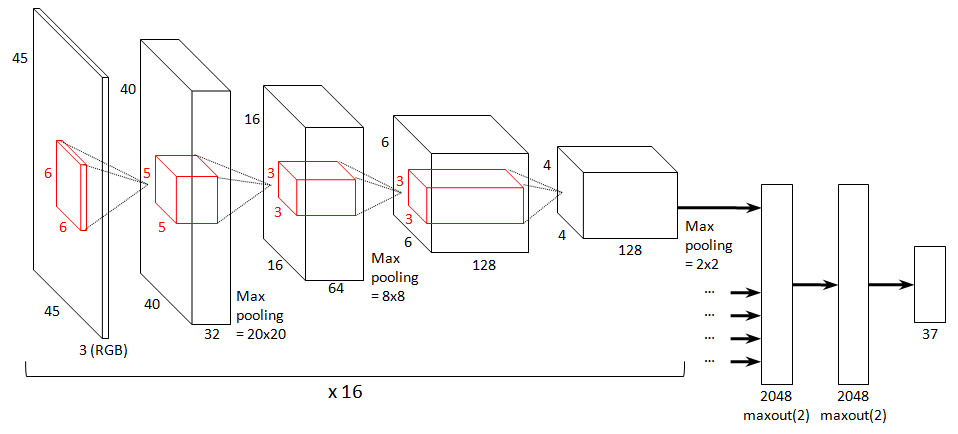
a.输入层
输入图像维度为(1,3,45,45)
b.卷积池化层
卷积输入:batches=1,feature=3,I_h=45,I_l=45,filters=32,f_h=6,f_w=6卷积输出:(1,32,45-6+1=40,45-6+1=40)
池化输入:p_h=2,p_l=2
池化输出:(1,32,40/2=20,40/2=20)
c.卷积池化层
卷积输入:batches=1,feature=32,I_h=20,I_w=20,filters=64,f_h=5,f_w=5卷积输出:(1,64,20-5+1=16,20-5+1=16)
池化输入:p_h=2,p_l=2
池化输出:(1,64,16/2=8,16/2=8)
d.卷积层
卷积输入:batches=1,feature=64,I_h=8,I_w=8,filters=128,f_h=3,f_w=3卷积输出:(1,128,8-3+1=6,8-3+1=6)
e.卷积池化层
卷积输入:batches=1,feature=128,I_h=6,I_w=6,filters=128,f_h=3,f_w=3卷积输出:(1,128,6-3+1=4,6-3+1=4)
池化输入:p_h=2,p_l=2
池化输出:(1,128,4/2=2,16/2=2)
f.maxout网络(2层)
输入:(1,128,2,2),每层经过给定的2048个线性滤波器
输出:分类可能值的集合大小,37
8.参考链接
http://benanne.github.io/2014/04/05/galaxy-zoo.html















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









