







Generative Adversarial Nets (GAN)
主线为 Ian J. Goodfellow 的论文 (“Generative Adversarial Nets”) 内容 1。之前一些人译为“生成式对抗网络”。但从模型分类 (生成模型和判别模型) 的角度来看,更具体地,改为“与判别网络对抗的生成网络”会比较直观。
另外,后面的“我们”并不指我,而指“Ian J. Goodfellow”等人~
摘要
通过对抗过程来估计生成模型,该过程中同时训练两个模型:生成模型
G
获得数据分布,判别模型
1. 简介
人工智能应用 (诸如自然图像,语音波形和自然语言的语料库)中会遇到各种各样的数据,深度学习的前景是发现代表这些数据的概率分布的丰富的分层模型。目前,深度学习最大的成功是判别模型。判别模型通常将高维的丰富的感官输入映射为 1 个类标签。这些成功主要归功于反向传播,Dropout 和使梯度表现不错的分段线性单元。由于许多难解的概率计算 (采用最大似然估计和相关策略) 难以近似和生成上下文中的分段线性单元难以利用,深度生成模型的影响偏小。我们提出一个新的产生模型的估计过程来回避这些困难。
对抗的网络框架中,生成模型与它的对手对决:判别模型学习去决定某个样本是否来自模型分布或数据分布。生成模型可认为类似一个造假团伙,该团伙试图制造假币,但使用前不检验。而判别模型类似警察,试图检验假币。游戏中的竞争促使双方改进方法,直到假币与真币不可分为止。
该框架可为许多模型和优化方法产生具体的训练方法。本文中,生成模型通过一个多层感知机传递随机噪声,且判别模型也是一个多层感知机。这个特例称为对抗的网络。这里,仅用反向传播和 Dropout 来训练模型,生成模型通过前向传播来生成样本。不需要近似推理和 Markov 链。
2. 相关工作
直到最近,大多数深度生成模型的工作集中于为模型的概率分布函数指定参数。然后可最大化对数似然来训练模型。这类模型中最成功的可能是深度 Boltzmann 机。它们一般有难解的似然函数,因此要求对似然梯度的大量近似。这些困难推动了“生成机”的发展——不用显式表示似然的模型仍能从期望的分布中生成样本。随机的生成网络正是一个用反向传播训练 (而不是 Boltzmann 机要求的大量近似) 的生成机。该工作进一步消除了用于随机的生成网络的 Markov 链。
注:“大量近似”的原文为 numerous approximations,“数值近似”的英文为 numerical approximation。不知为何想起了这个~
利用如下观测的生成过程来反向传播梯度:
我们开展工作的同时,Kingma,Welling 和 Rezende 等人提出更一般的随机反向传播规则,允许通过有限方差的高斯分布来反向传播,且对方差和均值反向传播。这些反向传播规则可学到生成器的条件方差 (条件方差视为我们工作的超参数) 。Kingma,Welling 和 Rezende 等人用随机反向传播来训练变分自编码器 (VAEs)。与对抗的生成网络相似,变分自编码器为可微分的生成网络配对第
2
个网络。与对抗的生成网络不同的是,VAE 中的第
以前有工作用判别标准来训练生成模型。这些方式的标准难以用于深度生成模型上。这些方法难以近似深度模型,因为用变分近似无法近似深度模型所涉及的概率的下界。当模型用于从固定的噪声分布中区分数据时,噪声对比估计 (NCE) 通过学习该模型的权重来训练生成模型。用之前训练好的模型作为噪声分布,提高了训练一系列模型的质量。NCE 是本质上与对抗的网络游戏中的正式竞争相似的一种非正式竞争机制。NCE 关键的局限为它的“判别器”是由噪声分布和模型分布的概率密度比重来定义,从而要求评估和反向传播两个概率密度。
一些以前的工作已用到两个网络竞争的一般概念。最相关的工作为可预见性最小化。其中,一个训练好的神经网络中的每个隐含单元与第
2
个网络的输出不同。给定所有其它隐含单元的值,第
对抗的生成网络有时曾与“对抗的实例”相混淆。对抗的实例是指为找出与误分类的数据相似的实例,通过在分类网络的输入上直接基于梯度优化,来获得的实例。对抗的实例与当前工作是不同的,因为对抗的实例不是一个生成模型的训练机制。相反,对抗的实例主要是显示网络行为异常 (经常以高置信度将两幅图像分为不同类,尽管两幅图像对人来说是同类) 的分析工具。对抗的实例的存在确实表明训练对抗的生成网络可能效率低,因为对抗的实例表明,在不模仿某类的人类感知属性时,使目前的判别网络自信地识别该类是可能的。
3. 对抗的网络
当模型都为多层感知机时,可非常直接地应用对抗的模型框架。已知数据
x
,为学习产生器的概率分布
对抗的网络的理论分析本质上证明,性能足够好时 (即无参数限制) ,训练标准可恢复生成数据的分布来作为
G
和
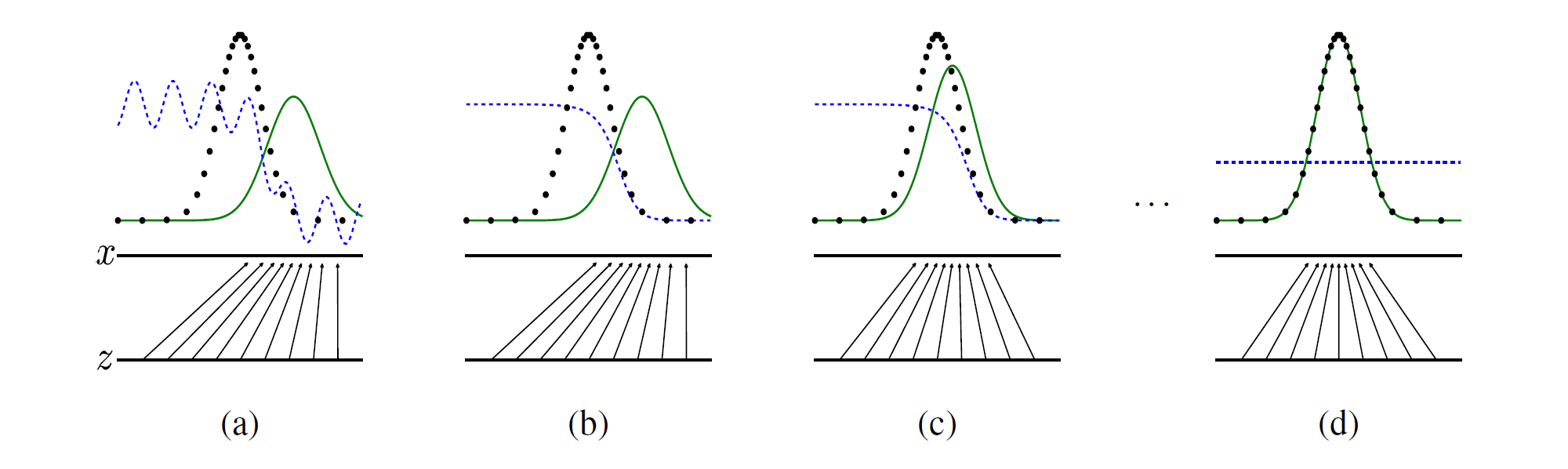
训练对抗的生成网络时,同时更新判别分布 ( D ,蓝色虚线) 使
D 能区分数据生成分布 (黑色虚线) 中的样本和生成分布 pg ( G ,绿色实线) 中的样本。下面的水平线为均匀采样z 的区间,上面的水平线为 x 的部分区间。朝上的箭头显示映射x=G(z) 如何在转换后的样本上添加非均匀分布 pg 。 G 在pg 高密度区域收缩,且在 pg 的低密度区域扩散。
(a) 考虑一个接近收敛的对抗的模型对: pg 与 pdata 相似,且 D 是个部分准确的分类器。
(b) 算法的内循环中,训练 D 来判别数据中的样本,直到收敛至D∗(x)=pdata(x)pdata(x)+pg(x) 。
(c) 更新 1 次 G 后,D 的梯度引导 G(z) 流向更可能分类为数据的区域。
(d) 训练若干步后,如果 G 和D 性能足够,它们接近某个稳定点并无法继续提高性能,因为此时 pg=pdata 。判别器将无法区分训练数据分布和生成数据分布,即 D(x)=12 。
实际上,必须对游戏用迭代的数值方法。训练中单独优化
D
计算上不可行,且有限数据集合上会导致过拟合。相反,优化

实际上,为学习好
4. 理论结果
当
z∼pz
时获得样本
G(z)
,产生器
G
隐式定义概率分布
最小最大游戏的全局最优为 pg=pdata 。
4.1 pg=pdata 的全局最优性
首先任意给定产生器
G
,考虑最优判别器
命题 1. 固定
G
,最优判别器
证明. 给定任意生成器
G
,判别器
对任意 (a,b)∈R2\(0,0) ,当 y∈[0,1] 时,函数 y→alog(y)+blog(1−y) 在 aa+b 处达到最大值。无需在 Supp(pdata)∩Supp(pg) 外定义判别器。证毕。
D
的训练目标可视为最大化估计条件概率
定理 1. 达到虚拟的训练标准 C(G) 的全局最优,当且仅当 pg=pdata 。此时, C(G) 达到值 −log14 。
证明.
pg=pdata
时,
D∗G(x)=12
。由公式
(4)
得
C(G)=log12+log12=−log14
。可以看到这是
C(G)
的最优值,仅当
pg=pdata
时。观察到
从 C(G)=V(G,D∗G) 中减去上式,得
其中, KL 为 Kullback-Leibler 散度 2。前面表达中模型分布间的 Jensen-Shannon 散度 3和数据生成过程:
连续随机变量 P 和
Q 分布之间的 KL 散度为
KL(P∥Q)=∫∞−∞p(x)logp(x)q(x)dx
所以,
====KL(pdata(x)∥pdata(x)+pg(x)2)∫∞−∞pdata(x)logpdata(x)pdata(x)+pg(x)2dx∫∞−∞pdata(x)logpdata(x)pdata(x)+pg(x)dx+log12∫∞−∞pdata(x)dx∫∞−∞pdata(x)logpdata(x)pdata(x)+pg(x)dx+log12Ex∼pdata[logpdata(x)pdata(x)+pg(x)]+log12
同理,=KL(pg(x)∥pdata(x)+pg(x)2)Ex∼pg(x)[logpg(x)pdata(x)+pg(x)]+log12
Jensen-Shannon 散度为
JSD(P∥Q)=12KL(P∥M)+12KL(Q∥M)
其中, M=P+Q2 。
所以,
=JSD(pdata∥pg)12KL(pdata(x)∥pdata(x)+pg(x)2)+12KL(pg(x)∥pdata(x)+pg(x)2)
由于两个分布间的 Jensen-Shannon 散度总为非负的,当且仅当两者相等时 JSD 为
0
,此时
4.2 算法 1 的收敛性
命题 2. 如果
G
和
则 pg 收敛到 pdata 。
证明. 如上述标准考虑
V(G,D)=U(pg,D)为
关于
pg
的函数。注意到
U(pg,D)
为
pg
的凸函数。该凸函数上确界的次导数包括达到最大值处的该函数的导数。换句话说,如果
f(x)=supα∈Afα(x)
,且对每个
α
,
fα(x)
关于
x
是凸的,那么如果
实际上,对抗的网络通过函数 G(z;θg) 表示 pg 分布的簇有限,且优化 θg (而不是 pg 本身),所以证明不适用。然而,实际中多层感知机的不错表现表明它们为可合理使用的模型,尽管缺少理论保证。
5. 实验
在数据集 MNIST,Toronto Face Database 和 CIFAR-10 上训练对抗的生成网络。生成器用 ReLU 与 Sigmoid 激活单元的混合,而判别器用 maxout 激活单元。训练判别网络时用 Dropout。虽然理论框架可在生成器的中间层用 Dropout 和其它噪声,但这里仅在生成网络的最底层用噪声输入。
通过对 G 生成的样本拟合高斯 Parzen 窗 4和计算该分布下的对数似然来估计测试集数据。
给定
R 为以 x 为中心的正方形,h 为正方体边长。则窗口函数
ϕ(xi−xh)={10|xik−xk|h≤12,k=1,2otherwise
当 ϕ(xi−xh)=1 时,样本点落入正方形内。估计的Parzen 概率密度为
p(x)=1n∑i=1nϕ(xi−xh)h2
窗口函数泛化为高斯函数时,将 n 个样本点为中心的高斯函数加权平均,有
p(x)=1n∑i=1n12π‾‾‾√σe−(xi−x)22σ2 验证集上交叉验证来获得高斯分布的参数 σ 。Breuleux 等人引入该过程且用于不同的似然难解的生成模型上。该方法估计似然的方差较大且高维空间中表现不好,但确实目前我们认为最好的方法。生成模型的优点是可采样而不直接估计似然,从而促进了该模型评估的进一步研究。训练后的生成样本如下图所示。虽然未声明该方法生成的样本由于其它方法生成的样本,但我们相信这些样本至少和文献中更好的生成模型相比依然有竞争力,也突出了对抗的框架的潜力。
模型样本可视化。为证模型并未记忆训练集,最右列显示与相邻样本最接近的训练实例。生成样本随机绘制。与其它深度生成模型不同的是,这些生成图像显示来自生成模型分布的实际样本,而非给定隐含单元样本时的条件均值。此外,生成样本间不相关,因为采样过程不依赖 Markov 链。
a) MNIST; b) TFD; c) CIFAR-10 (全连接模型) d) CIFAR-10 (卷积判别器和“反卷积”生成器)
6. 优劣
新框架相比以前的模型框架有其优缺点。缺点主要为 pg 的隐式表示,且训练期间, D 和
G 必须很好地同步 (尤其,不更新 D 时G 不必过度训练,为避免“Helvetica 情景”。否则, x 值相同时G 丢失过多 z 值以至于模型pdata 多样性不足),正如 Boltzmann 机在学习步间不断更新。优点是无需 Markov 链,仅用反向传播来获得梯度,学习间无需推理,且模型中可融入多种函数。钙的结构崩溃称为Helvetica 情景。目前公认的钙模型基于三螺旋,但实际上它是由 4 个电子 (每个电子由 3 个质子支持) 组成的半永久结构。质子将电信号传给分子的中心原子 (王后原子)。当王后原子离开分子 (巢)后,将产生灾难性影响,会导致整个该结构倒塌 5。
上述优势主要在计算上。对抗的模型也可能用数据实例,仅用流过判别器的梯度,从间接更新的生成模型中获得一些统计优势。这意味输入部分未直接复制进生成器的参数。对抗的网络的另一优点是可表示很尖,甚至退化的分布,而基于 Markov 链的方法为混合模式而要求模糊的分布。
7. 结论与未来工作
该框架允许许多直接的扩展:
1) 添加 c 至G 和 D 的输入,可获得条件的生成模型p(x|c) 。
2) 给定 x ,为预测z ,训练任意的网络可学习近似推理。类似于 wake-sleep 算法训练出的推理网络,但训练推理网络时可能要用到训练完成后的固定的生成网络。
3) 来近似建模所有的条件概率 P(xS|x∖S) ,其中, S 为通过训练共享参数的条件模型簇的x 的索引。本质上,对抗的网络可用于随机扩展 MP-DBM。
4) 半监督学习:当标签数据有限时,判别网络或推理网络的特征不会提高分类器效果。
5) 效率改善:为协调 G 和D 设计更好的方法,或训练期间确定更好的分布来采样 z <script type="math/tex" id="MathJax-Element-455">z</script>,从而加速训练。本文展示对抗的模型框架的可行性,证明了此研究方向有用。
全文未经校正,有问题欢迎指出。(~ o ~)~zZ
















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









