







1.下载Kafka和Flume安装包
Kafka安装包下载(用到的Kafka安装包为:kafka_2.11-2.2.0.tgz):Apache Kafka
Flume安装包下载(用到的flume安装包为:apache-flume-1.9.0-bin.tar.gz):
2.通过工具上传Kafka和flume压缩包(三台机均需要上传)
3.解压kafka和flume(三台机均执行解压命令)
[hadoop@master software]$ tar zxvf kafka_2.11-2.2.0.tgz -C /opt/module/
[hadoop@master software]$ tar zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/module/
4.配置Kafka
配置kafka环境变量,首先打开profile文件
vim /etc/profile
按i进入编辑模式,在文件末尾添加kafka环境变量
#set kafka environment
export KAFKA_HOME=/opt/module/kafka_2.11-2.2.0
PATH=${KAFKA_HOME}/bin:$PATH
保存文件后,让该环境变量生效
source /etc/profile
在master主机中修改server.properties配置文件
打开配置文件
vim /opt/module/kafka_2.11-2.2.0/config/server.properties
修改配置如下(IP地址应该根据实际情况填写)
broker.id=1
listeners=PLAINTEXT://master:9092
zookeeper.connect=master:2181,slave1:2181,slave2:2181
在slave1主机中修改server.properties配置文件
打开配置文件
vim /opt/module/kafka_2.11-2.2.0/config/server.properties
修改配置如下(IP地址应该根据实际情况填写)
broker.id=2
listeners=PLAINTEXT://master:9092
zookeeper.connect=master:2181,slave1:2181,slave2:2181
在slave2主机中修改server.properties配置文件
打开配置文件
vim /opt/module/kafka_2.11-2.2.0/config/server.properties
修改配置如下(IP地址应该根据实际情况填写)
broker.id=3
listeners=PLAINTEXT://master:9092
zookeeper.connect=master:2181,slave1:2181,slave2:2181
启动kafka(要确保zookeeper已启动)
在每台主机上分别启动kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
创建topic
./bin/kafka-topics.sh --create --zookeeper master:2181,slave2:2181,slave3:12181 --partitions 3 --replication-factor 3 --topic test
显示所有topic
./bin/kafka-topics.sh --list --zookeeper master:2181
查看topic详情
./bin/kafka-topics.sh --describe --zookeeper master:2181 --topic test
删除topic
./bin/kafka-topics.sh --delete --zookeeper master:2181 --topic test
生产者发布消息
./bin/kafka-console-producer.sh --broker-list master:9092 --topic test
消费者消费消息
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic test --from-beginning
5.使用Flume
测试:使用flume将slave1和slave2的数据实时监控,然后发送到master节点,由master节点的flume把数据上传到hdfs。
在slave1节点操作,进入到conf文件夹下
[root@slave1 flume]# cd apache-flume-1.8.0-bin/conf/
配置slave.conf文件
在conf下创建一个新的slave.conf文件
[root@slave1 conf]# vi slave.conf
写入配置内容
# 主要作用是监听目录中的新增数据,采集到数据之后,输出到avro (输出到agent)
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#具体定义source
a1.sources.r1.type = spooldir
#先创建此目录,保证里面空的
a1.sources.r1.spoolDir = /opt/module/apache-flume-1.9.0-bin/log
#a1.sources.r1.basenameHeader = true
#a1.sources.r1.basenameHeaderKey = fileName
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
# hostname是最终传给的主机名称或者ip地址
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 44444
a1.sinks.k1.hdfs.fileType = DataStream
#a1.sinks.k1.hdfs.filePrefix = %{fileName}
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir =/opt/module/apache-flume-1.9.0-bin/checkpoint
a1.channels.c1.dataDirs = /opt/module/apache-flume-1.9.0-bin/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
保存退出
将这个配置文件发送给slave2主机
scp ./slave.conf slave2: /opt/module/apache-flume-1.9.0-bin/conf
在master节点下操作
修改master中flume的配置
在master的flume的conf文件夹下创建一个master.conf文件
[root@master conf]# vi master.conf
写入配置信息
# 获取slave1,2上的数据,聚合起来,传到hdfs上面
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#对于source的配置描述 监听avro
a1.sources.r1.type = avro
# hostname是最终传给的主机名称或者ip地址
a1.sources.r1.bind = master
a1.sources.r1.port = 44444
#a1.sources.r1.basenameHeader = true
#a1.sources.r1.basenameHeaderKey = fileName
#定义拦截器,为消息添加时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#对于sink的配置描述 传递到hdfs上面
a1.sinks.k1.type = hdfs
#集群的nameservers名字
#单节点的直接写:hdfs://主机名(ip):9000/xxx
#ns是hadoop集群名称
a1.sinks.k1.hdfs.path = hdfs://master:9000/user/flume/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
#a1.sinks.k1.hdfs.filePrefix = %{fileName}
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a1.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 60
#对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动测试
首先启动Zookeeper和hadoop集群
然后先启动master上的flume(如果先启动slave上的会导致拒绝连接)
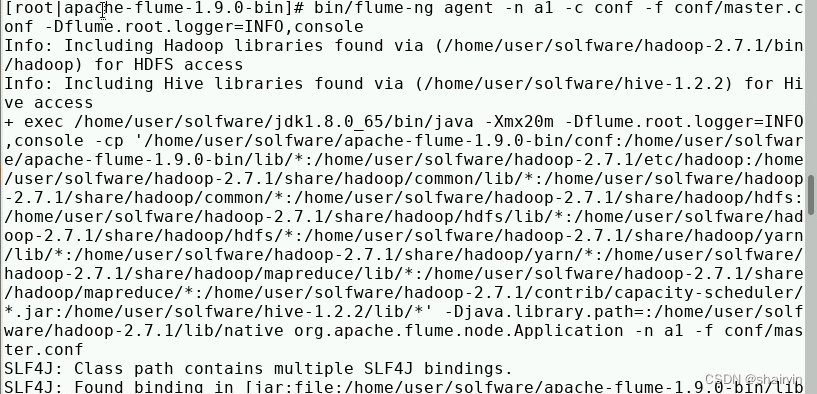
在apache-flume-1.9.0-bin目录下启动(因为没有配置环境变量)
[root@master apache-flume-1.9.0-bin]# bin/flume-ng agent -n a1 -c conf -f conf/master.conf -Dflume.root.logger=INFO,console
再启动slave1,2上的flume
首先在slave1,2的根目录创建los目录,不然会报错
#slave1
[root@slave1 apache-flume-1.9.0-bin]# bin/flume-ng agent -n a1 -c conf -f conf/slave.conf -Dflume.root.logger=INFO,console
#slave2
[root@slave2 apache-flume-1.9.0-bin]# bin/flume-ng agent -n a1 -c conf -f conf/slave.conf -Dflume.root.logger=INFO,console
再打开一个slave1或者slave2节点的窗口
在flume目录下创建一个test文件
[root@slave1 apache-flume-1.9.0-bin]# vi test
随便写入一些内容
test flume!!!
保存退出
将其复制到logs文件夹下
[root@slave1 apache-flume-1.9.0-bin]# mv test ./log
查看master
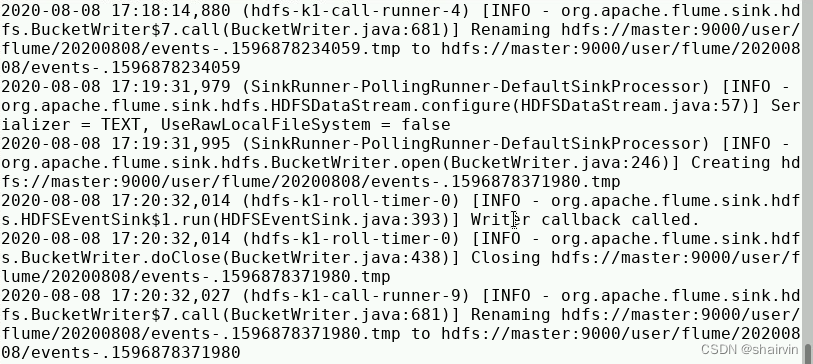
查看hdfs上的文件
hdfs dfs -ls /user/flume

hdfs dfs -ls /user/flume/20200808

查看该文件
hdfs dfs -cat /user/flume/20200808/events-.l596878234059
![]()
如此,flume多节点级联完成!
更多内容请关注公众号“测试小号等闲之辈”~















 1461
1461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









