







Hadoop HA(High Available)经过同时配置两个处于Active/Passive模式的Namenode来解决上述问题,分别叫Active Namenode和Standby Namenode。 Standby Namenode做为热备份,从而容许在机器发生故障时可以快速进行故障转移,同时在平常维护的时候使用优雅的方式进行Namenode切换。Namenode只能配置一主一备,不能多于两个Namenode。
一、HA的原理
HA问题中需要解决的两个问题:
- 元数据一致性:Standby节点和Active节点的元数据一致性。
- 主备自动切换:Active节点服务中断时,Standby节点可以立即启动对外提供服务。
Active Namenode处理全部的操做请求(读写),而Standby只是做为备用,保证和Active节点的元数据一致性,使得故障时可以快速切换到Standby。为了使Standby Namenode与Active Namenode数据保持同步,两个Namenode都与一组Journal Node进行通讯。当主Namenode进行任务的namespace操做时,都会确保持久会修改日志到Journal Node节点中的大部分。Standby Namenode持续监控这些edit,当监测到变化时,将这些修改应用到本身的namespace。在Active节点服务中断需要切换时,Standby在成为Active Namenode以前,会确保本身已经读取了Journal Node中的全部edit日志,从而保持数据状态与故障发生前一致。
为了确保故障转移可以快速完成,Standby Namenode须要维护最新的Block位置信息,即每一个Block副本存放在集群中的哪些节点上。为了达到这一点,Datanode同时配置主备两个Namenode,并同时发送Block报告和心跳到两台Namenode。确保任什么时候刻只有一个Namenode处于Active状态很是重要,不然可能出现数据丢失或者数据损坏。当两台Namenode都认为本身的Active Namenode时,会同时尝试写入数据(不会再去检测和同步数据)。为了防止这种脑裂现象,Journal Nodes只容许一个Namenode写入数据,内部经过维护epoch数来控制,从而安全地进行故障转移。
二、元数据一致性保证
Hadoop 2.x元数据:
Hadoop的元数据主要作用是维护HDFS文件系统中文件和目录相关信息。元数据的存储形式主要有3类:内存镜像、磁盘镜像(FSImage)、日志(EditLog)。在Namenode启动时,会加载磁盘镜像到内存中以进行元数据的管理,存储在NameNode内存;磁盘镜像是某一时刻HDFS的元数据信息的快照,包含所有相关Datanode节点文件块映射关系和命名空间(Namespace)信息,存储在NameNode本地文件系统;日志文件记录client发起的每一次操作信息,即保存所有对文件系统的修改操作,用于定期和磁盘镜像合并成最新镜像。
HA其本质上就是要保证主备NN元数据是保持一致的,即保证fsimage和editlog在备NN上也是完整的。元数据的同步很大程度取决于EditLog的同步,而这步骤的关键就是共享文件系统,下面开始介绍一下共享存储机制。
有两种方式能够进行edit log共享:
- 使用QJM(Quorum Journal Manager)共享edit log
- 使用NFS(Network File System)共享edit log(存储在NAS/SAN)
1. NFS 原理
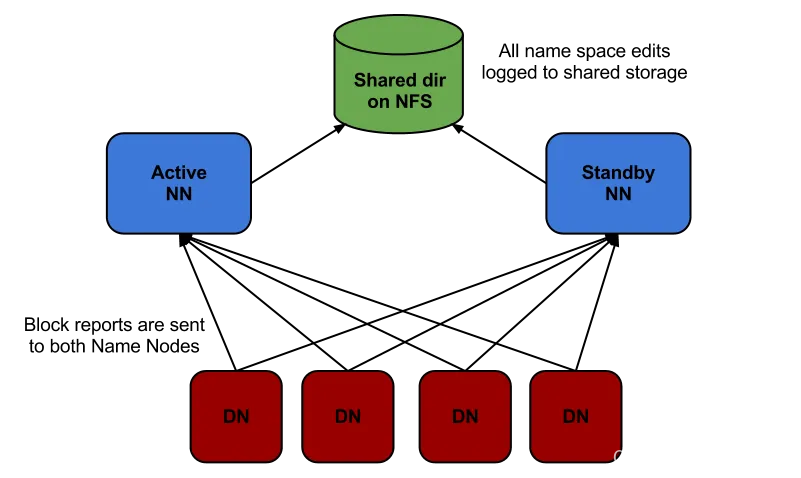
如上图所示:NFS做为主备Namenode的共享存储。这种方案可能会出现脑裂(split-brain),即两个节点都认为本身是主Namenode并尝试向edit log写入数据,这可能会致使数据损坏。经过配置fencin脚原本解决这个问题,fencing脚本用于:
- 将以前的Namenode关机
- 禁止以前的Namenode继续访问共享的edit log文件
使用这种方案,管理员就能够手工触发Namenode切换,而后进行升级维护。但这种方式存在如下问题:
- 只能手动进行故障转移,每次故障都要求管理员采起措施切换。
- NAS/SAN设置部署复杂,容易出错,且NAS自己是单点故障。
- Fencing 很复杂,常常会配置错误。
- 没法解决意外(unplanned)事故,如硬件或者软件故障。oop
所以须要另外一种方式来处理这些问题:
- 自动故障转移(引入ZooKeeper达到自动化)
- 移除对外界软件硬件的依赖(NAS/SAN)
- 同时解决意外事故及平常维护致使的不可用
2. QJM原理
QJM(Quorum Journal Manager)是Hadoop专门为Namenode共享存储开发的组件,一般是奇数点结点组成。其集群运行一组Journal Node,每一个Journal 节点暴露一个简单的RPC接口,容许Namenode读取和写入数据,数据存放在Journal节点的本地磁盘。当Namenode写入edit log时,NameNode会同时向所有JournalNode并行写文件,当超过半数节点回复确认成功写入以后,edit log就认为是成功写入。
2.1 QJM 写过程分析
NameNode 会把 EditLog 同时写到本地和 JournalNode 中。写本地由配置中的参数dfs.namenode.name.dir来控制,写JN由参数dfs.namenode.shared.edits.dir控制,在写EditLog时会由两个不同的输出流来控制日志的写过程,分别是:
- EditLogFileOutputStream(本地输出流)
- QuorumOutputStream(JN输出流)
NameNode在写EditLog时,并不是直接写到磁盘中,为保证高吞吐,NameNode会分别为EditLogFileOutputStream和QuorumOutputStream定义两个同等大小的Buffer,大小大概是512KB,一个写Buffer(buffCurrent),一个同步Buffer(buffReady),这样可以一边写一边同步,所以EditLog是一个异步写过程,同时也是一个批量同步的过程,避免每写一笔就同步一次日志。
这个是怎么实现边写边同步的呢,这中间其实是有一个缓冲区交换的过程,即bufferCurrent和buffReady在达到条件时会触发交换,如bufferCurrent在达到阈值同时bufferReady的数据又同步完时,bufferReady数据会清空,同时会将bufferCurrent指针指向bufferReady以满足继续写,另外会将bufferReady指针指向bufferCurrent以提供继续同步EditLog。上面过程用流程图就是表示如下:
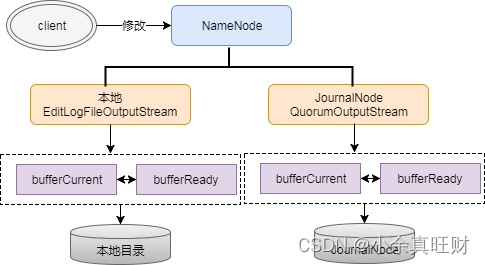
这里有一个问题,既然EditLog是异步写的,怎么保证缓存中的数据不丢呢,其实这里虽然是异步,但实际所有日志都需要通过logSync同步成功后才会给client返回成功码,假设某一时刻NameNode不可用了,其内存中的数据其实是未同步成功的,所以client会认为这部分数据未写成功。
另一个问题是,EditLog怎么在多个JN上保持一致的呢
(1)隔离双写
在Active NN每次同步EditLog到JN时,先要保证不会有两个NN同时向JN同步日志。这个隔离是怎么做的。这里面涉及一个很重要的概念Epoch Numbers,很多分布式系统都会用到。
成为Active结点时,其会被赋予一个EpochNumber,每个EpochNumber是惟一的,不会有相同的EpochNumber出现。EpochNumber有严格顺序保证,每次NN切换后其EpochNumber都会自增1,后面生成的EpochNumber都会大于前面的EpochNumber。QJM是怎么保证上面特性的呢,主要有以下几点:
- 在对EditLog作任何修改前,QJM(NameNode上)必须被赋予一个EpochNumber;
QJM把自己的EpochNumber通过newEpoch(N)的方式发送给所有JN结点;
当JN收到newEpoch请求后,会把QJM的EpochNumber保存到一个lastPromisedEpoch变量中并持久化到本地磁盘;
ANN同步日志到JN的任何RPC请求(如logEdits(),startLogSegment()等),都必须包含ANN的EpochNumber;
JN在收到RPC请求后,会将之与lastPromisedEpoch对比,如果请求的EpochNumber小于lastPromisedEpoch,将会拒绝同步请求,反之,会接受同步请求并将请求的EpochNumber保存在lastPromisedEpoch;
这样就能保证主备NN发生切换时,就算同时向JN同步日志,也能保证日志不会写乱,因为发生切换后,原ANN的EpochNumber肯定是小于新ANN的EpochNumber,所以原ANN向JN的发起的所有同步请求都会拒绝,实现隔离功能,防止了脑裂。
(2)恢复in-process日志
如果在写过程中写失败了,可能各个JN上的EditLog的长度都不一样,需要在开始写之前将不一致的部分恢复。恢复机制如下:
- Active NN先向所有JN发送getJournalState请求;
- JN会向ANN返回一个Epoch(lastPromisedEpoch);
- Active NN收到大多数JN的Epoch后,选择最大的一个并加1作为当前新的Epoch,然后向JN发送新的newEpoch请求,把新的Epoch下发给JN;
- JN收到新的Epoch后,和lastPromisedEpoch对比,若更大则更新到本地并返回给Active NN自己本地一个最新EditLogSegment起始事务Id,若小则返回NN错误;
- Active NN收到多数JN成功响应后认为Epoch生成成功,开始准备日志恢复;
- Active NN会选择一个最大的EditLogSegment事务ID作为恢复依据,然后向JN发送prepareRecovery; RPC请求,对应Paxos协议2p阶段的Phase1a,若多数JN响应prepareRecovery成功,则可认为Phase1a阶段成功;
- Active NN选择进行同步的数据源,向JN发送acceptRecovery RPC请求,并将数据源作为参数传给JN。
- JN收到acceptRecovery请求后,会从JournalNodeHttpServer下载EditLogSegment并替换到本地保存的EditLogSegment,对应Paxos协议2p阶段的Phase1b,完成后返回Active NN请求成功状态。
- Active NN收到多数JN的响应成功请求后,向JN发送finalizeLogSegment请求,表示数据恢复完成,这样之后所有JN上的日志就能保持一致。 数据恢复后,Active NN上会将本地处于in-process状态的日志更名为finalized状态的日志,形式如editsstart-txidstop-txid。
(3)日志同步
这个步骤上面有介绍到关于日志从Active NN同步到JN的过程,具体如下:
- 执行logSync过程,将ANN上的日志数据放到缓存队列中
- 将缓存中数据同步到JN,JN有相应线程来处理logEdits请求
- JN收到数据后,先确认EpochNumber是否合法,再验证日志事务ID是否正常,将日志刷到磁盘,返回ANN成功码
- ANN收到JN成功请求后返回client写成功标识,若失败则抛出异常
通过上面一些步骤,日志能保证成功同步到JN,同时保证JN日志的一致性,进而备NN上同步日志时也能保证数据是完整和一致的。
2.2 QJM读过程分析
读过程是面向备NN(Standby NN)的,Standby NN定期检查JournalNode上EditLog的变化,然后将EditLog拉回本地。Standby NN上有一个线程StandbyCheckpointer,会定期将Standby NN上FSImage和EditLog合并,并将合并完的FSImage文件传回主NN(Active NN)上,就是所说的Checkpointing过程。下面我们来看下Checkpointing是怎么进行的。
在2.x版本中,已经将原来的由SecondaryNameNode主导的Checkpointing替换成由Standby NN主导的Checkpointing。下面是一个CheckPoint的流向图:
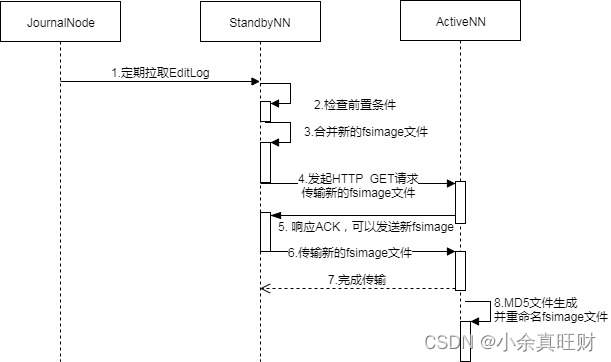
就是在Standby NN上先检查前置条件,前置条件包括两个方面:距离上次Checkpointing的时间间隔和EditLog中事务条数限制。前置条件任何一个满足都会触发Checkpointing,然后SNN会将最新的NameSpace数据即SNN内存中当前状态的元数据保存到一个临时的fsimage文件( fsimage.ckpt)然后比对从JN上拉到的最新EditLog的事务ID,将fsimage.ckpt_中没有,EditLog中有的所有元数据修改记录合并一起并重命名成新的fsimage文件,同时生成一个md5文件。将最新的fsimage再通过HTTP请求传回ANN。通过定期合并fsimage有什么好处呢,主要有以下几个方面:
- 可以避免EditLog越来越大,合并成新fsimage后可以将老的EditLog删除
- 可以避免主NN(ANN)压力过大,合并是在SNN上进行的
- 可以保证fsimage保存的是一份最新的元数据,故障恢复时避免数据丢失
三、主备自动切换
Hadoop的主备选举依赖于ZooKeeper。
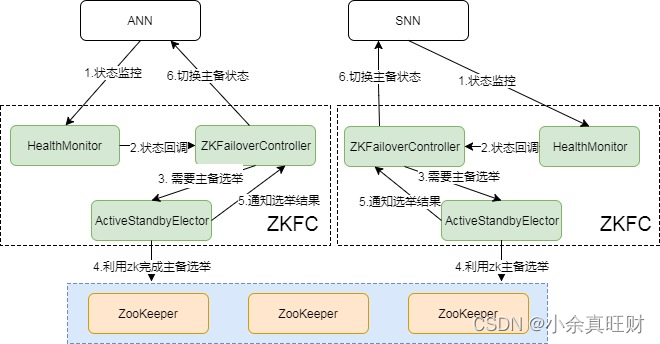
从图中可以看出,整个切换过程是由ZKFC来控制的,ZKFC是实现主备切换的组件。每个运行的NameNode上都会有一个ZKFC进程(实际是一个Hadoop进程)。主要的功能如下:
- 健康检测:ZKFC会使用健康检测命令定期的ping同节点中的NameNode,只要改NameNode及时的回复健康,则任务当前NameNode是健康的;
- Zookeeper会话管理: 当本地NameNode是健康的,ZKFC会保持一个在Zookeeper中打开的会话。如果本地NameNode处于Active状态,ZKFC会保持一个特殊的znode锁,如果回话中断,锁节点讲自动删除;
- 基于Zookeeper的选举: 如果本地的NameNode是健康的,且ZKFC发现没有其他的节点持有当前的znode锁,它会为自己获取该锁。如果成功则进行故障切换,并且确保之前的NameNode的进程中断,将本地NameNode切换为Active;
在故障切换期间,ZooKeeper主要是发挥什么作用呢,有以下几点:
- 失败保护:集群中每一个NameNode都会在ZooKeeper维护一个持久的session,机器一旦挂掉,session就会过期,故障迁移就会触发;
- Active NameNode选择:ZooKeeper有一个选择ActiveNN的机制,一旦现有的ANN宕机,其他NameNode可以向ZooKeeper申请排他成为下一个Active节点;
- 防脑裂: ZK本身是强一致和高可用的,可以用它来保证同一时刻只有一个活动节点;
那在哪些场景会触发自动切换呢,从HDFS-2185中归纳了以下几个场景:
- ActiveNN JVM奔溃:ANN上HealthMonitor状态上报会有连接超时异常,HealthMonitor会触发状态迁移至SERVICE_NOT_RESPONDING, 然后ANN上的ZKFC会退出选举,SNN上的ZKFC会获得Active Lock, 作相应隔离后成为Active结点;
- ActiveNN JVM冻结:这个是JVM没奔溃,但也无法响应,同奔溃一样,会触发自动切换;
- ActiveNN 机器宕机:此时ActiveStandbyElector会失去同ZK的心跳,会话超时,SNN上的ZKFC会通知ZK删除ANN的活动锁,作相应隔离后完成主备切换;
- ActiveNN 健康状态异常: 此时HealthMonitor会收到一个HealthCheckFailedException,并触发自动切换;
- Active ZKFC奔溃:虽然ZKFC是一个独立的进程,但因设计简单也容易出问题,一旦ZKFC进程挂掉,虽然此时NameNode是OK的,但系统也认为需要切换,此时SNN会发一个请求到ANN要求ANN放弃主结点位置,ANN收到请求后,会触发完成自动切换;
- ZooKeeper奔溃:如果ZK奔溃了,主备NN上的ZKFC都会感知断连,此时主备NN会进入一个NeutralMode模式,同时不改变主备NN的状态,继续发挥作用,只不过此时,如果ANN也故障了,那集群无法发挥Failover, 也就不可用了,所以对于此种场景,ZK一般是不允许挂掉到多台,至少要有N/2+1台保持服务才算是安全的;















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









