






 文章介绍了作者在QQ后台开发的UnifiedCache系统,该系统具有自动回填、数据过滤、PB存储、自定义容灾级别等特点,旨在降低前端业务对数据源的压力,支持快速业务接入和高性能运作。
文章介绍了作者在QQ后台开发的UnifiedCache系统,该系统具有自动回填、数据过滤、PB存储、自定义容灾级别等特点,旨在降低前端业务对数据源的压力,支持快速业务接入和高性能运作。
引言
本人在QQ后台工作期间,主导设计和开发了支持任意数据结构的树型缓存系统UnifiedCache,其主要特性包括:
1)自动回填
通过数据源拉取插件拉取数据后回填到Cache,业务可以自定义从数据源拉取并处理数据的方法,放到UnifiedCache中运行。
2)数据过滤
通过数据过滤插件对缓存数据进行处理过滤或排序后再返回给前端,允许用户自定义数据过滤插件。
3)任意存储类型
底层采用树型协议PB存储和传输,基于KNV对树型协议处理引擎,可以在不需要理解数据结构定义的情况下高性能处理PB数据。
4)自定义容灾级别
可以支持单副本、单中心多副本、多中心单副本、多中心多副本等多种容灾级别
一、系统介绍
1. 需求来源
为了减少前端业务(主要来源是消息后台,包括群消息和C2C消息,用户每次发送一条消息,推送给对方前都要拉一下昵称/备注/群备注,计算一个综合显示名称放到消息里面进行下发)对OIDB(QQ后台提供给全公司访问QQ资料关系链服务的接入平台)后端的频繁调用,节省机器资源,需要开发一套用于缓存Session热点数据的Cache,这就是Unified Cache(起初叫Session Cache)。
刚开始的需求主要考虑这几个业务:
- 群消息:消息中需要带用户昵称,推送给群成员的每条消息(一个100人的群,有人发一条消息就要拉100次,因为每个人看到发消息的人的昵称都可能不一样)都要到OIDB拉用户昵称,给OIDB的数据后台造成极大的压力,OIDB侧希望有一个Cache层减少对数据层的压力。
- C2C消息:消息流程越来越重、依赖的系统负载越来越高、空转率很高,希望将数据缓存同Session逻辑分离出来。
- wtLogin(QQ登录组件)海外部署:如果全量号段部署在海外,则需要浪费大量机器资源,如果各个业务搭建自己的Cache,则需要的人力投入很多,因此,一个统一的接受多字段多来源的通用Cache变得对海外部署很有意义。
2. 使用情景
以C2C消息为例:消息中心把Cache直接当做数据层,需要频繁拉取的数据就到Cache拉取。
- 用户登录后发送第一条消息时,Cache自动帮忙到后端拉取所有可能被访问的数据(根据domain由配置文件配置),然后返回用户请求的数据(如果用户希望对数据加工后再返回,可以使用filter机制);
- 用户下次请求同个domain数据时,直接返回(或者filter后返回)Cache数据;
- 当用户某个domain数据发生变更时,Cache直接淘汰这个domain的数据,用户后续的拉取按第一条消息处理。
- 当用户某个domain超过一定时限不活跃(没有拉取数据,时间可配置)时,系统对这个domain的数据进行淘汰。
二、系统设计目标
- 支持系统快速上线,新业务接入周期不大于2周。
- 性能指标,支持单机20w/s以上。
- 运维成本,系统搭建、扩容、死机处理都应该非常方便,做到无或极少人工运营。
- 要能够适配各种复杂的业务,要至少支持key-value、key-valuelist、key-key-value、key-key-valuelist、key-key-key-value等等。
三、总体架构
1. 约定
UC : Unified Cache
US : Union Session
SC : Sync Center
TLV:编码格式:Type(两字节) + Length(两字节) + Value(二进制buffer)
2. 架构描述
总体架构采用 BCC + Cache方式,当请求的key(只有一级key时)有多个时,调用方通过BCC服务(QQ后台一个批量聚合拉取服务)进行拉取,否则直接寻址UnifiedCache进行拉取。
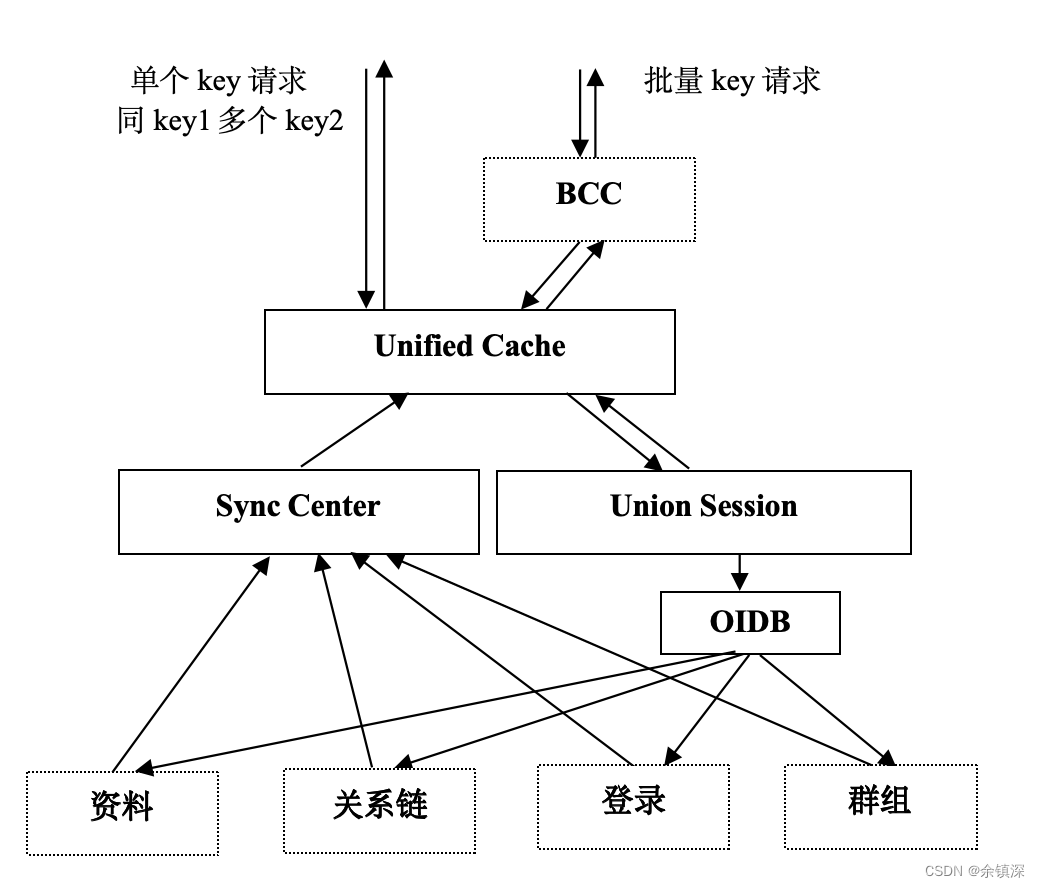
分为三个大的模块:
- UnifiedCache:实现Cache主要逻辑的模块
- SyncCenter:当数据发生变更时,可靠的通知UnifiedCache淘汰相应数据
- UnionSession:实现不同类型的数据聚合和转换,提供统一拉取的功能,通过OIDB访问后端数据层
对于单个请求的情况:
命中Cache时,直接返回,时延和性能可以达到极速(单机20w/s以上,耗时1ms以内),实现高速低成本Cache。
不命中时,Cache访问UnionSession拉回数据并回填,然后返回用户需要的数据。
对于多个请求的情况: 用户访问BCC,由BCC转换成单个请求访问Cache。
四、UnifiedCache实现
1. Cache层架构
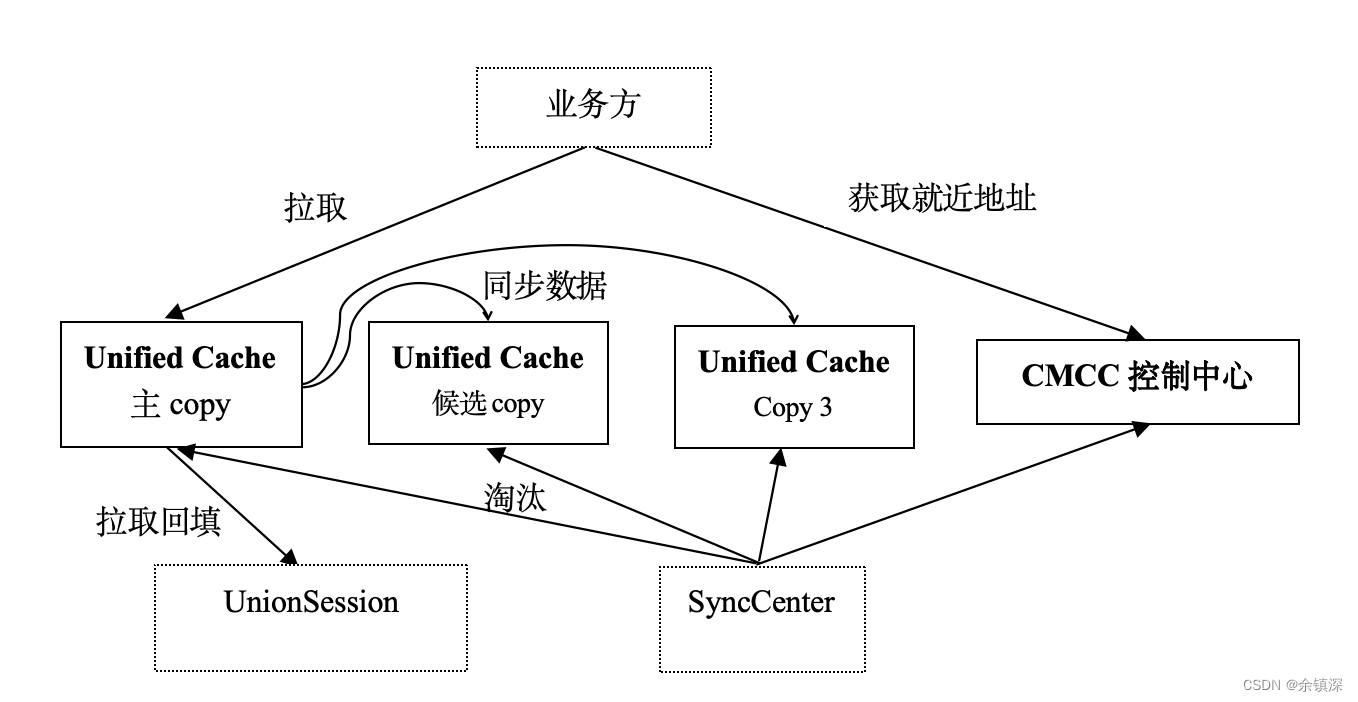
Cache层通过CMCC(QQ后台通用配置中心)进行配置管理,包括机器存活状态检测、机器权重/多中心信息的配置。
一个key具体落到哪台机器由一致性哈希算法结合机器存活状态进行计算,关于一致性哈希的知识这里不再展开,网上有很多文章介绍。
下图是配置了多中心多副本策略后的一致性哈希环分布情况:
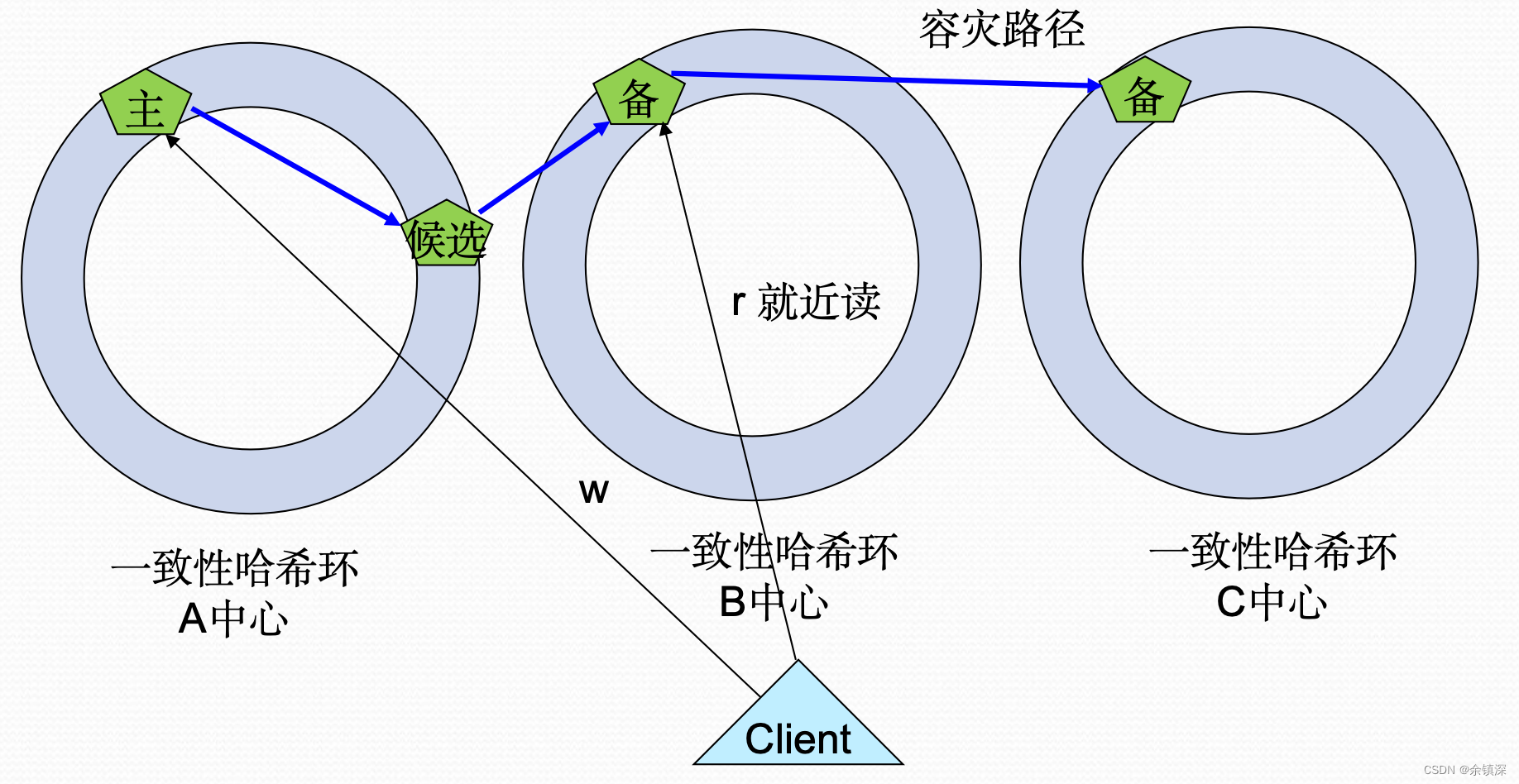
注意这里候选节点和备节点的区别,候选是写入主的时候同步写候选,写成功才算成功,也就是候选节点的数据跟主是时时刻刻保持一致的,而备节点是通过异步同步机制确保数据最终一致的。区分候选跟备的目的,是为了确保在主死机的时候,候选马上就可以升级为主,而不会导致数据丢失。
另外这里容灾路径有几种可能的配置:
1. 没有候选和备,只有一份数据,死机时寻址没有数据的下一跳,所有数据需要重新回源
2. 只从主读数据,备只做冷备
3. 只读写本中心,各个中心是一套独立Cache,各个中心内做主从容灾,各自回填
2. 共享内存存储方式
Unified Cache是基于共享内存的存储,使用多阶哈希+LinkTable的方式存储,数据按照哈希key在多阶哈希中进行索引,key对应的数据存储到LinkTable表中,存储结构如下:
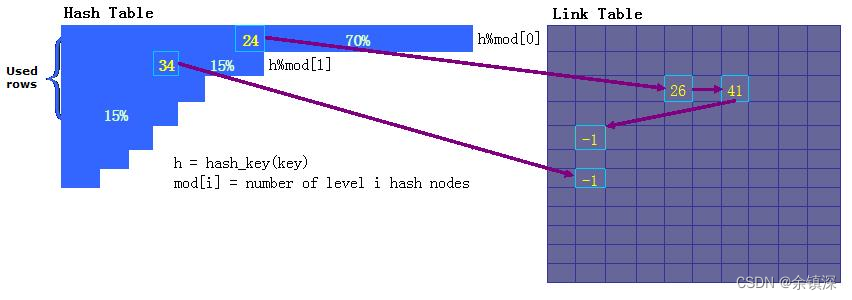
这里多阶哈希的意思是,如果key在第一阶哈希表中出现哈希冲突,就重新计算一个哈希值在二阶哈希表中查找位置,同样的如果第二阶出现冲突,就在第三阶找,直到找到或者所有阶都冲突了返回失败。
这种存储的主要特点包括:
1)第一阶哈希表容量占比很大,确保基本上在第一阶就能访问到数据,因此哈希表的性能很高。
2)后面的阶是用来解决哈希冲突的,当阶数很大时,就退化成普通列表。
3)跟Cache存储相结合,淘汰可以优先淘汰低阶中哈希值相同的节点,可以确保新插入的节点有更高的访问性能。
多阶哈希+LinkTable的共享内存存储方案,已经被封装成一个独立的代码库并开源,这里可以访问:GitHub - shaneyuee/shmhash: A multi level hash based on linux shm, using shmhash, user can put any key-value data in shared memory.
3. 数据的存储格式
Unified Cache是基于KNV(Key-N-Value)存储引擎进行协议和数据处理的,所有存储的数据都以用户传入的PB(Protocol Buffers)格式序列化后的值进行存储,因为KNV支持对任何PB格式的数据进行裸解和修改,用户只需要根据PB构造KNV支持的请求树(叶子节点的值由0/1构成的树型路径图),KNV可以根据请求树对存储数据进行提取、更新、删除等操作,从而达到访问Unified Cache存储数据的目的。
因为协议是原生的PB格式,Unified Cache的客户端用户只需要使用谷歌的PB库,并按UnifiedCache对请求树对要求定制好.proto文件,就可以访问Unified Cache了,而不需要直接使用KNV库。
因为使用KNV库的原因,Unified Cache可以支持格式类型的数据,包括:
1)key + TlvList
只有一级key,比如QQ基础资料
2)一级key + 二级key + TlvList
二级key,比如QQ所有好友的资料
3)一级key + 二级key + 三级key + TlvList
三级key,比如QQ群好友备注:我 - QQ群号码 - 群好友号码 - 群好友备注,同一个人在不同的群可以设置不同的备注。
这里有专门的文章介绍KNV:
Key-N-Value--基于Protocol Buffers的树型协议处理引擎-CSDN博客
github开源地址:
4. 数据同步方式
Unified Cache支持同城、多地多种级别的容灾,数据的一致性采用最终一致性的方案,即主拷贝接收数据写入请求,处理完数据写入后先回包告诉用户写成功,再通过异步方式将数据同步给其他备拷贝。
具体的同步由Sync Center完成,采用Sequence+Binlog的方式,Cache写服务按key的哈希值分成很多个分片,并对每个写请求按分片维度分配一个递增的Seq,先跟Sync Center通信,确保Seq+Binlog写入成功,才写本地Cache。Sync Center的工作流程如下:
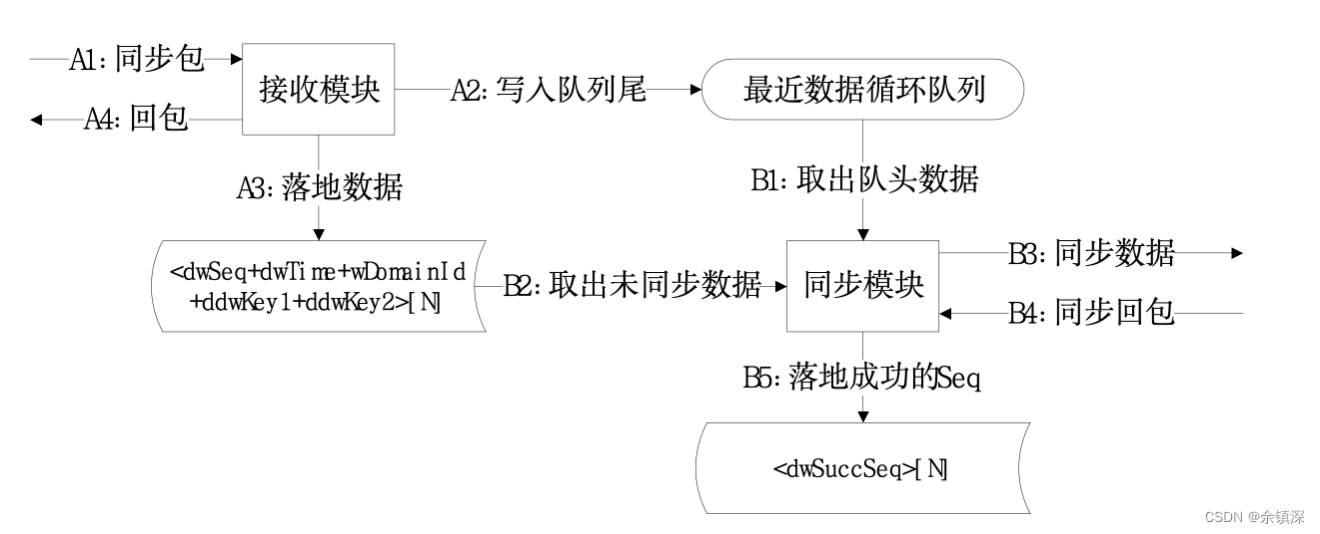
同步支持增量和全量两种方式:
1)增量同步:binlog里面记录请求树、请求树对应的数据、操作类型,备拷贝收到同步数据后,按seq顺序重做binlog,就可以得到最新数据。
2)全量同步:同步内容包含修改后的全量数据,备拷贝覆盖主key数据即可。















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









