







这篇文章主要介绍可以快速掌握正则表达式的一些技巧,需要的朋友可以参考一下。
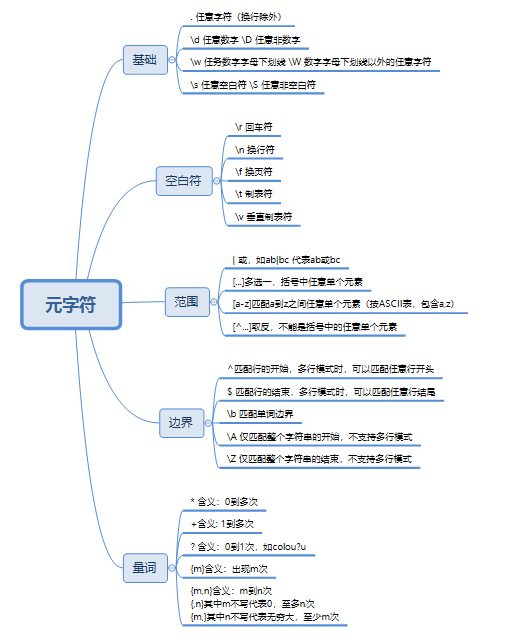
1、正则表达式的分类
正则表达式中,元字符非常多,在这里,我给大家介绍一个方法,就是分类记忆法。
正则表达式中的大部分都是元字符,我们可以把元字符分为以下几个分类:
2、贪婪和非贪婪
贪婪:表示次数的量词,默认是贪婪的、尽可能多地去匹配。
非贪婪:"数量"元字符后加?(英文问号)找出长度最小且满足要求的。
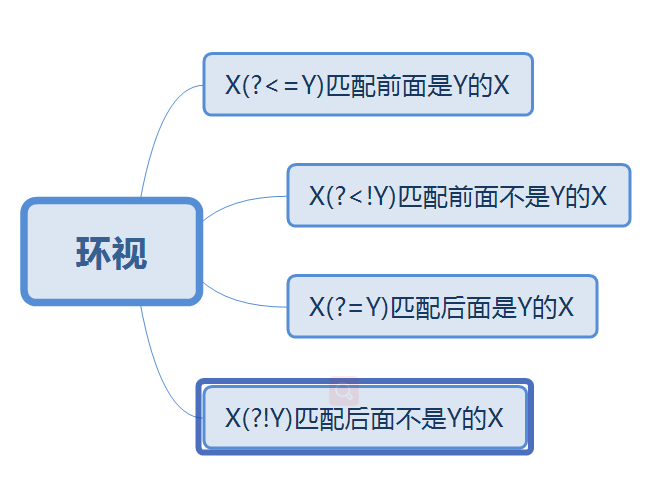
3、环视
环视:简单来说就是我们给定的规则
3、子组
子组:把多个字符当一个单独单元进行处理的方法,它通过对括号内的字符分组来创建,可以通过调用 matcher 对象的 groupCount 方法来查看表达式有多少个分组。groupCount 方法返回一个 int 值,表示matcher对象当前有多个捕获组。还有一个特殊的组(group(0)),它总是代表整个表达式。该组不包括在 groupCount 的返回值中。

4、正则表达式使用案例
- 正则表达式 .regex. 用于查找字符串中是否包了 regex子串:
package com.test.regex;
import java.util.regex.Pattern;
public class RegexText {
public static void main(String[] args) {
String context = "I am regex from regex.com";
String pattern = ".*regex.*";
boolean isMatch = Pattern.matches(pattern, context);
System.out.println("字符串中是否包含了'regex'子字符串? " + isMatch);
}
}
- 从一个给定的字符串中找到数字串:
package com.test.regex;
import lombok.extern.slf4j.Slf4j;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Slf4j
public class RegexMatches {
public static void main(String[] args) {
String line = "This order was placed for QT3000! OK?";
String pattern = "(\\D*)(\\d+)(.*)";
Pattern compile = Pattern.compile(pattern);
Matcher matcher = compile.matcher(line);
if (matcher.find()) {
log.info("Found value0:{} value1:{} value2:{} value3:{}", matcher.group(0), matcher.group(1), matcher.group(2), matcher.group(3));
} else {
log.info("no match values");
}
}
}
输出如下所示:
Found value0:This order was placed for QT3000! OK? value1:This order was placed for QT value2:3000 value3:! OK?
如果您觉得有帮助,欢迎点赞哦 ~ ~ 多谢~ ~














 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









