







转自:http://www.cnblogs.com/itech/archive/2011/03/27/1996883.html
python技巧26[str+unicode+codecs]
一 python2.6中的字符串
1) 字符串的种类和关系 (在2.x中,默认的string为str)
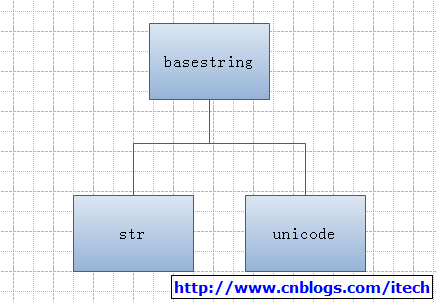
2) python的全局函数中basestring,str和unicode的描述如下
basestring()
This abstract type is the superclass for str and unicode. It cannot be called or instantiated, but it can be used to test whether an object is an instance of str or unicode. isinstance(obj, basestring) is equivalent to isinstance(obj, (str, unicode)).
str([object])
Return a string containing a nicely printable representation of an object. For strings, this returns the string itself. The difference with repr(object) is that str(object) does not always attempt to return a string that is acceptable to eval(); its goal is to return a printable string. If no argument is given, returns the empty string, ''.
unicode([object[, encoding[, errors]]])
Return the Unicode string version of object using one of the following modes:
If encoding and/or errors are given, unicode() will decode the object which can either be an 8-bit string or a character buffer using the codec for encoding. The encoding parameter is a string giving the name of an encoding; if the encoding is not known, LookupError is raised. Error handling is done according to errors; this specifies the treatment of characters which are invalid in the input encoding. If errors is 'strict' (the default), a ValueError is raised on errors, while a value of 'ignore' causes errors to be silently ignored, and a value of 'replace' causes the official Unicode replacement character, U+FFFD, to be used to replace input characters which cannot be decoded. See also the codecs module.
If no optional parameters are given, unicode() will mimic the behaviour of str() except that it returns Unicode strings instead of 8-bit strings. More precisely, if object is a Unicode string or subclass it will return that Unicode string without any additional decoding applied.
For objects which provide a __unicode__() method, it will call this method without arguments to create a Unicode string. For all other objects, the 8-bit string version or representation is requested and then converted to a Unicode string using the codec for the default encoding in 'strict' mode.
二 print
2.6中print函数的帮助:(print()函数基本等价于print ‘’ 语句)
print([object, ...][, sep=' '][, end='n'][, file=sys.stdout])
Print object(s) to the stream file, separated by sep and followed by end. sep, end and file, if present, must be given as keyword arguments.
All non-keyword arguments are converted to strings like str() does and written to the stream, separated by sep and followed by end. Both sep and end must be strings; they can also be None, which means to use the default values. If no object is given, print() will just write end.
The file argument must be an object with a write(string) method; if it is not present or None, sys.stdout will be used.
Note
This function is not normally available as a builtin since the name print is recognized as the print statement. To disable the statement and use the print() function, use this future statement at the top of your module:
from __future__ import print_function
print 函数支持str和unicode。 python的print会对输出的文本做自动的编码转换,而文件对象的write方法就不会做,例如如下代码中包含中英文,但是能够正确的输出:
print 'AAA' + '中国' # AAA中国
#print u'AAA' + u'中国' # SyntaxError: (unicode error) 'utf8' codec can't decode bytes in
print u'AAA' + unicode('中国','gbk') # AAA中国
三 codecs
函数 decode( char_set )可以实现 其它编码到 Unicode 的转换,函数 encode( char_set )实现 Unicode 到其它编码方式的转换。
codecs模块为我们解决的字符编码的处理提供了lookup方法,它接受一个字符编码名称的参数,并返回指定字符编码对应的 encoder、decoder、StreamReader和StreamWriter的函数对象和类对象的引用。 为了简化对lookup方法的调用, codecs还提供了getencoder(encoding)、getdecoder(encoding)、getreader(encoding)和 getwriter(encoding)方法;进一步,简化对特定字符编码的StreamReader、StreamWriter和 StreamReaderWriter的访问,codecs更直接地提供了open方法,通过encoding参数传递字符编码名称,即可获得对 encoder和decoder的双向服务。

import codecs, sys
# 用codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
bfile = codecs.open( " dddd.txt " , ' r ' , " big5 " )
# bfile = open("dddd.txt", 'r')
ss = bfile.read()
bfile.close()
# 输出,这个时候看到的就是转换后的结果。如果使用语言内建的open函数来打开文件,这里看到的必定是乱码
print ss, type(ss)
上面这个处理big5的,可以去找段big5编码的文件试试。
四 实例
代码:
def TestisStrOrUnicdeOrString():
s = ' abc '
ustr = u ' Hello '
print isinstance(s, str) # True
print isinstance(s,unicode) # False
print isinstance(ustr,str) # False
print isinstance(ustr, unicode) # True
print isinstance(s,basestring) # True
print isinstance(ustr,unicode) # True
def TestChinese():
# for the below chinese, must add '# -*- coding: utf-8 -*-' in first or second line of this file
s = ' 中国 '
# SyntaxError: (unicode error) 'utf8' codec can't decode bytes in position 0-1
# us = u'中国'
us2 = unicode( ' 中国 ' , ' gbk ' )
print (s + ' : ' + str(type(s))) # 中国:<type 'str'>
# print us
print (us2 + ' : ' + str(type(us2))) # 中国:<type 'unicode'>
# UnicodeDecodeError: 'ascii' codec can't decode byte 0xd6
# newstr = s + us2
# UnicodeWarning: Unicode equal comparison failed to convert
# both arguments to Unicode - interpreting them as being unequal
# print 's == us2' + ':' + s == us2
print s3 # AAA中国
s4 = unicode('AAA中国','gbk')
print s4 # AAA中国
def TestPrint():
print ' AAA ' + ' 中国 ' # AAA中国
print u ' AAA ' + unicode( ' 中国 ' , ' gbk ' ) # AAA中国
def TestCodecs():
import codecs
look = codecs.lookup( " gbk " )
a = unicode( " 北京 " , ' gbk ' )
print len(a), a, type(a) # 2 北京 <type 'unicode'>
b = look.encode(a)
print b[ 1 ], b[0], type(b[0]) # 2 北京 <type 'str'>
if __name__ == ' __main__ ' :
TestisStrOrUnicdeOrString()
TestChinese()
TestPrint()
TestCodecs()
五 总结
1)如果python文件中包含中文的字符串,必须在python文件的最开始包含# -*- coding: utf-8 -*-, 表示让python以utf8格式来解析此文件;
2)使用isinstance(obj, basestring) is equivalent to isinstance(obj, (str, unicode))来判断是否为字符串;
3)us = u'中国' 有错误,必须使用us2 = unicode('中国','gbk')来将中文解码为正确的unicode字符串;
4)str和unicode字符串不能连接和比较;
5)print函数能够支持str和unicode,且能够正确的解码和输出字符串;
6)可以使用unicode.encode或str.decode来实现unicode和str的相互转化,还可以使用codecs的encode和decode来实现转化。
7)貌似必须在中文系统或者系统安装中文的语言包后gbk解码才能正常工作。
参考: http://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html
3.一些建议
3.1. 使用字符编码声明,并且同一工程中的所有源代码文件使用相同的字符编码声明。
这点是一定要做到的。
3.2. 抛弃str,全部使用unicode。
按引号前先按一下u最初做起来确实很不习惯而且经常会忘记再跑回去补,但如果这么做可以减少90%的编码问题。如果编码困扰不严重,可以不参考此条。
3.3. 使用codecs.open()替代内置的open()。
如果编码困扰不严重,可以不参考此条。
3.4. 绝对需要避免使用的字符编码:MBCS/DBCS和UTF-16。
这里说的MBCS不是指GBK什么的都不能用,而是不要使用Python里名为'MBCS'的编码,除非程序完全不移植。
http://blog.csdn.net/inte_sleeper/article/details/6676351 http://anchoretic.blog.sohu.com/82278076.html http://www.javaeye.com/topic/560229
完!
感谢,Thanks!
作者:iTech
出处:http://itech.cnblogs.com/
本文版权归作者iTech所有,转载请包含作者签名和出处,不得用于商业用途,非则追究法律责任!














 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









