







论文出发点:旨在设计一个轻量级但是保证精度、速度的深度网络
分析当前:
1、直接用FLOP来衡量算力,不够准确。因为不同的网路,即使参数量相同(模型大小相同),但是模型速度还是存在差异。改为直接用速度(speed)来衡量
2、直接影响速度的因素,首先MAC,比如分组卷积,需要强大的算力对设备GPU是个挑战;其次并行度。
因此,设计网络需要考虑:speed和platform
同时提出4条设计准则:注意,这些设计准则是权衡了速度和精度的针对轻量型网络提出的准则。
1、同等通道可以最小化MAC(即:让c1 = c2),所以PW(1x1)卷积的升维降维就影响MAC
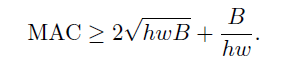
2、过多的分组卷积增大MAC(从公式看出,随着g的增大,MAC增大)
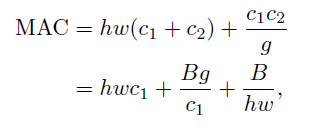
3、网络碎片会影响并行化 (building block中的分支)
4、元组的操作开销是不可忽略的
基于这4条规则,论文设计了shufflenetV2轻量化网络结构。
轻量化网络:
要在给定参数条件下,限制feature map的通道数,那如何在不增加参数量的前提下还能保证feature map的通道数呢?使用分组卷积和深度可分离卷积,但是这两个卷积方式都违背了设计准则。
- shufflenetv2提出了channel split, 将C通道的featur map分离成两branch(C1, C-C1)
- 其中一个branch直连(保留identity)
- 另一个branch连接三个具有同等输入输出通道的卷积,且一头一尾的两个1x1的卷积就是标准的卷积,不是分组卷积
- 最后,两个branch直接拼接
相比, shufflenetv1,不再有元组操作(elt-wise add)
shufflenetV2主要结构如c,d图所示

c图是同feature map尺寸的,有split, concact, shuffle
d图是降采样的,没有split,所以通道数翻倍,feature map大小缩倍
具体可视化后的building block如下图:第一个是D结构,第二个是C结构。

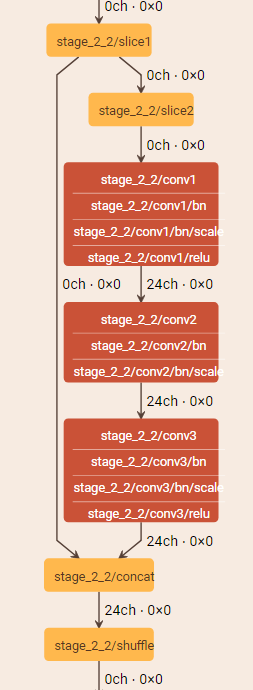
亲测,shuffleNetV2的参数量和算力是碾压式的小!但是训练的时候很占显存,因为网络很深,feature map很多。但是如果只是推理还是很值得一试。
更多案例请关注“思享会Club”公众号或者关注思享会博客:http://gkhelp.cn/
















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









