







1.摘要
ShuffleNet是旷视科技提出的一种计算高效的CNN模型,其和MobileNet和SqueezeNet等一样主要是应用在移动端。所以,ShuffleNet的设计目标也是如何利用有限的计算资源来达到最好的模型精度,这需要很好地在速度和精度之间做平衡。ShuffleNet的核心是采用了两种操作:Pointwise group convolution和Channel shuffle,这在保持精度的同时大大降低了模型的计算量,同时这种结构能够允许网络使用更多的通道,通道之间可以交流信息,帮助 encode 阶段提取更多的信息,这点对极小的网络非常关键。目前移动端CNN模型主要设计思路主要是两个方面:模型结构设计和模型压缩。ShuffleNet和MobileNet一样属于前者,都是通过设计更高效的网络结构来实现模型变小和变快,而不是对一个训练好的大模型做压缩或者迁移。
2. 引言
对于Group convolution 是将输入层的不同特征图进行分组,然后采用不同的卷积核对各个组进行卷积,这样一来确实能够降低计算量,但是都是针对组内的channel进行信息交流,而组与组之间是没有信息交流的。一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection)。而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。但是该网络存在一个很大的弊端是采用了密集的1x1卷积,或者说是dense pointwise convolution,这里说的密集指的是卷积是在所有通道上进行的。比如ResNeXt模型中1x1卷积基本上占据了93.4%的乘加运算。那么不如也对1x1卷积采用channel sparse connection,那样计算量就可以降下来了。
所以本篇文章就提出了Pointwise group convolution和Channel shuffle,具体做法如下:
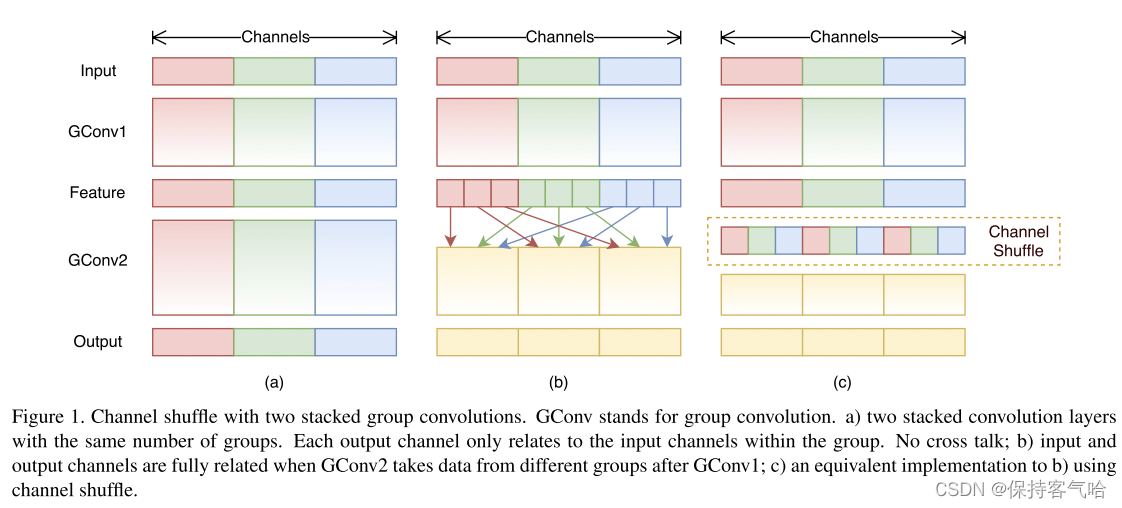
- 使用 point-wise 卷积来降低 1x1 卷积的计算量
- 使用 channel shuffle 能够让不同通道的信息进行交互
附上几个概念:
- 分组卷积:AlexNet 中提出的概念,在 ResNeXt 中有使用,也就是将特征图分为 N 个组,每组分别进行卷积,然后将卷积结果 concat 起来
- 深度可分离卷积:和 MobileNet 中都有使用,也就是每个特征图使用一个卷积核来提取特征,之后使用 1x1 的卷积进行通道间的特征融合
- channel shuffle:shuffle 可以翻译为重新洗牌,也就是把不同组的 channel 再细分一下,打乱重新分组
- 模型加速:加速推理时候的速度,如剪枝、量化
3.ShuffleNet architecture
3.1 ShuffleNet Unit
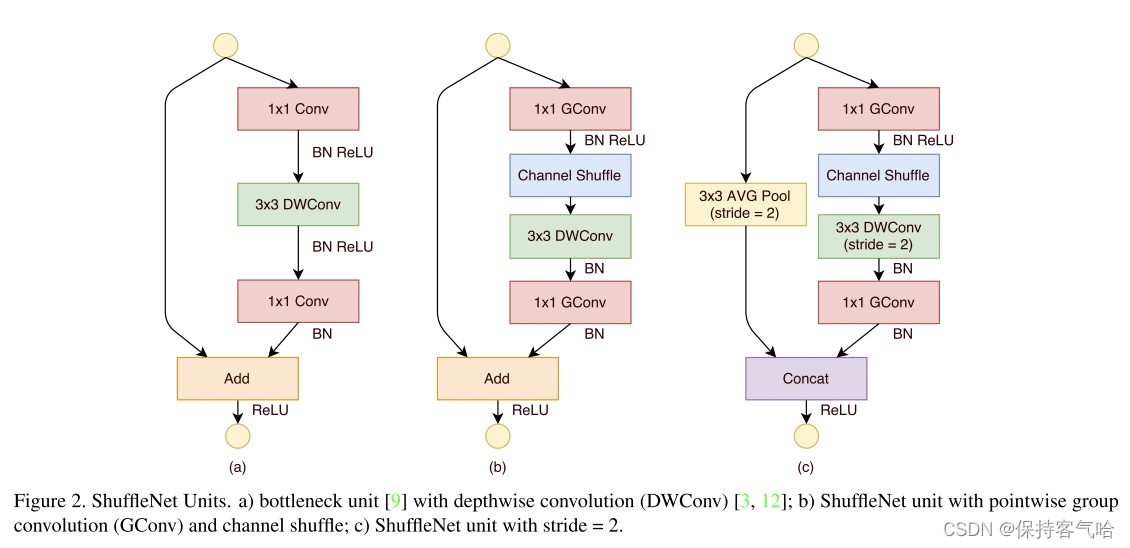
- 图a:这是一个包含三层的残差单元首先是1x1卷积,然后是3x3的DW卷积(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
- 图b:对图a进行了改进,将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按作者的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。
- 图c:对于一个残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加(如图·b),而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。但是在ShuffleNet中,却采用了不一样的策略,如图c所示:对原输入采用stride=2的3x3 avg pool,这样得到和输出一样大小的特征图,然后将得到特征图与输出进行连接(concat),而不是相加。这样做的目的主要是降低计算量与参数大小
3.2 ShuffleNet architecture详情
所对应的ShuffleNet architecture如下:
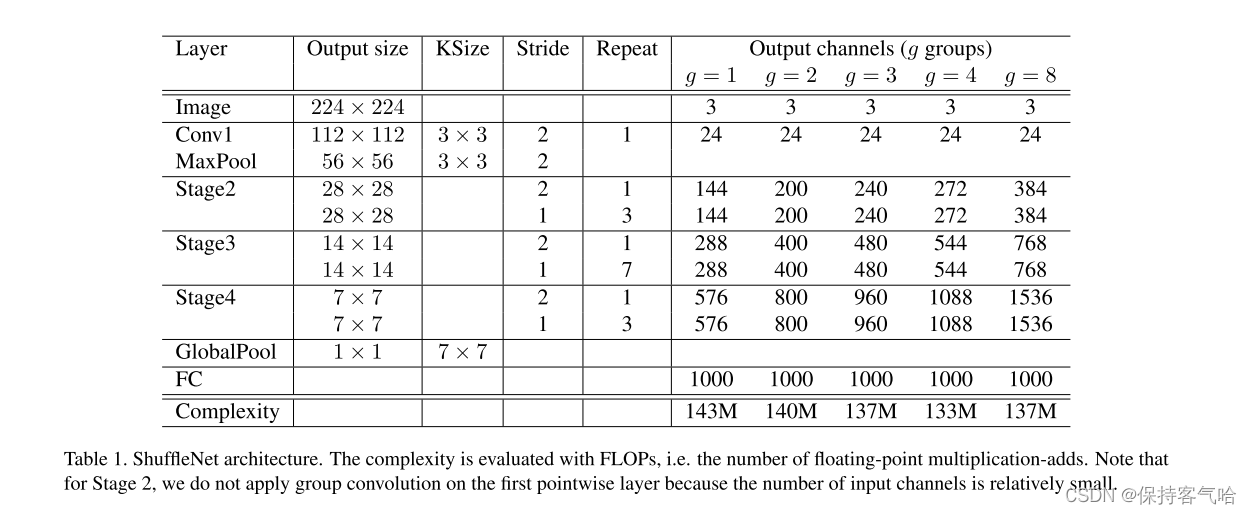
由上表可以看出一开始就是通过卷积和池化层,然后经过三个stage ,其中每个stage就是重复堆积了几个ShuffleNet的基本单元。对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍。后面的基本单元都是stride=1,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的。当完成三阶段后,采用global pool将特征图大小降为1x1,最后是输出类别预测值的全连接层。
4.实验结果
4.1 参数量
FLOPS 全大写,指的是每秒浮点数运算次数,可以理解为计算的速度是衡量硬件性能的一个指标(硬件)
FLOPs s小写,指的是浮点运算数,理解为计算量,可以用来衡量算法/模型的复杂度(模型)
论文中常用的 MFLOPs,1MFLOPs = 10^6 FLOPs
论文中常用的 GFLOPs,1GFLOPs = 10^9 FLOPs
但是计算复杂度不能只看 FLOPs,还要参考一些其他指标
文中对比了ResNet,ResNeXt,ShuffleNet三者的参数量:
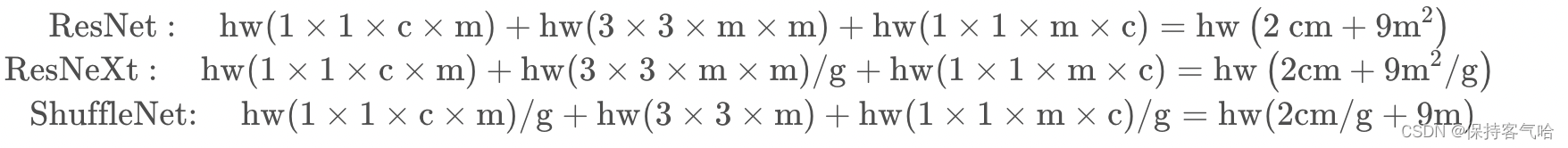
这里假设输入每个特征矩阵是 c × h × w ,假设第一个 1 × 1 卷积和 3 × 3 卷积的输出通道为 m,最终的输出通道数为 c,stride = 1 。我们就能计算出使用 ResNet ,ResNeXt 以及 ShuffleNetV1 中使用的 block的FLOPs。这里注意,组卷积的计算量输入输出通道都要除以组数 g,但是有 g 个组,所以还要乘一个 g,整体而言就是除以一个 g。DW conv 中 g = m。
4.2 实验结果
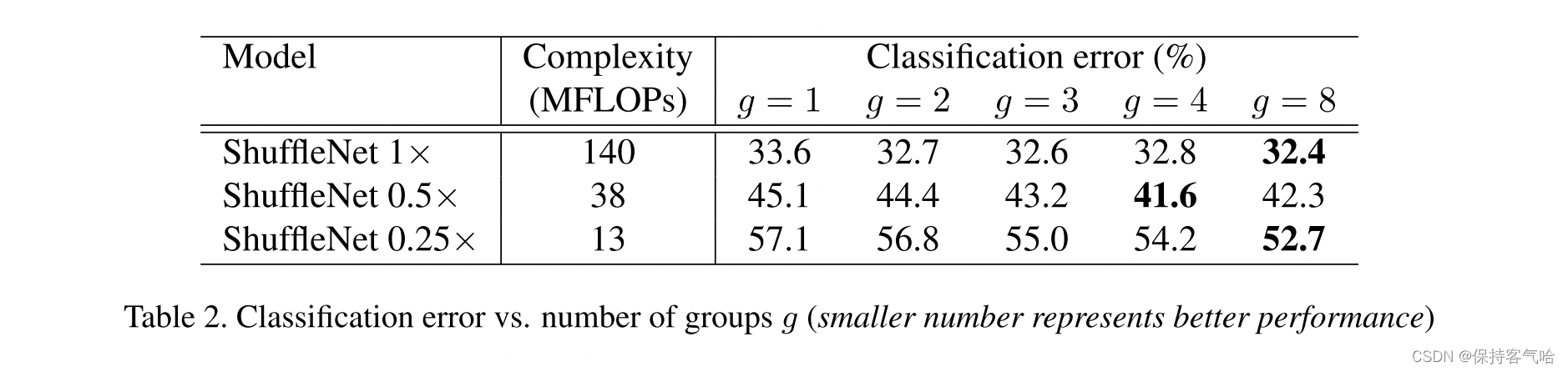
下图是ShuffleNet在ImageNet上的实验结果。可以看到基本上当
g
g
g越大时,效果越好,这是因为采用更多的分组后,在相同的计算约束下可以使用更多的通道数,或者说特征图数量增加,网络的特征提取能力增强,网络性能得到提升。注意Shuffle 1x是基准模型,而0.5x和0.25x表示的是在基准模型上将通道数缩小为原来的0.5和0.25。
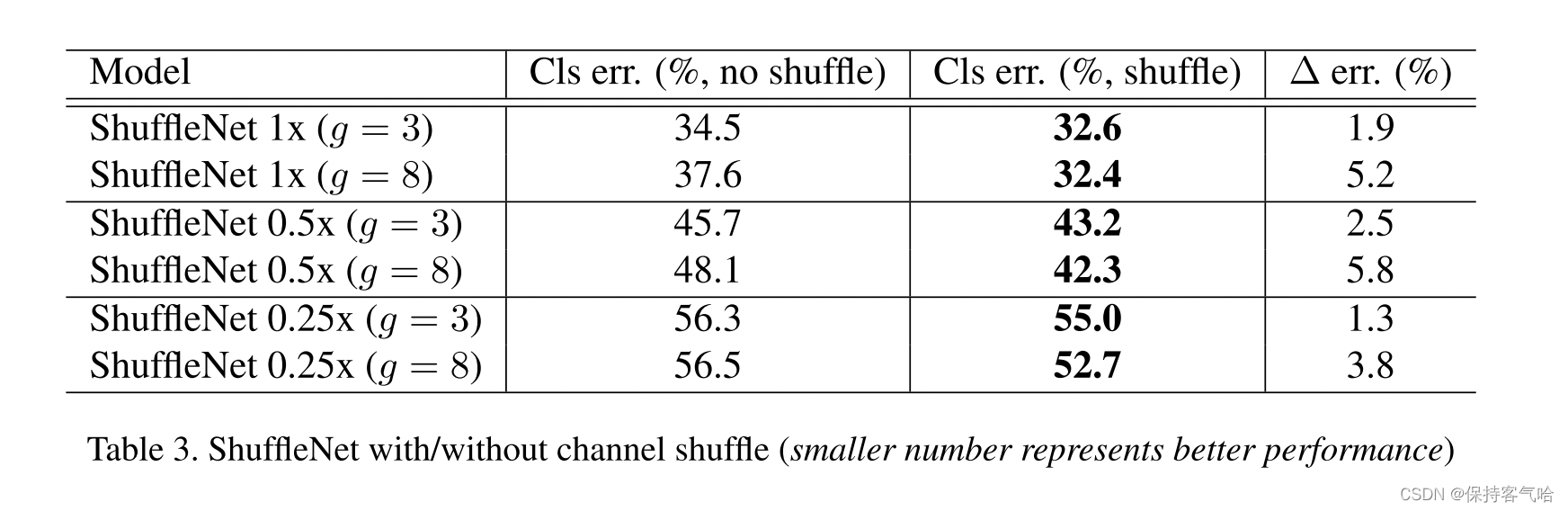
同时者还对比了不采用channle shuffle和采用之后的网络性能对比
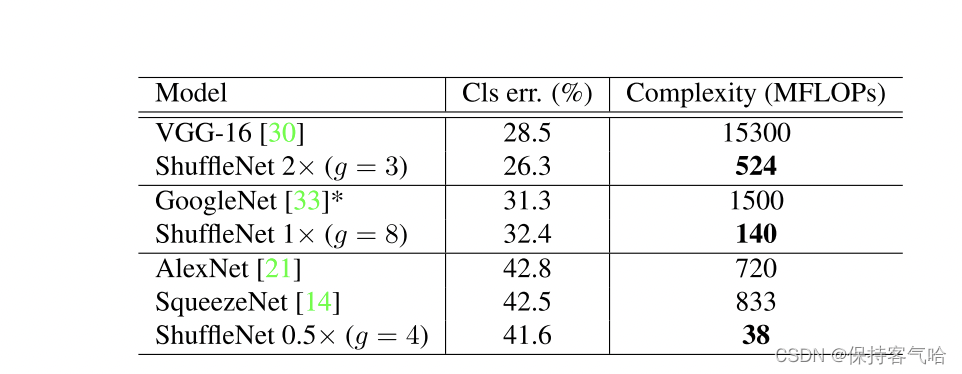
效果的提升如下所示:ShuffleNetV1与AlexNet的错误率相近,在晓龙820处理器上的推理时间上可以看见,ShuffleNetV1只需要15ms,而AlexNet需要184ms,推理时间提升的还是比较高的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









