







注意 tcp_ack 是来处理接收到的ACK的,那么到底怎么去做呢?看下面:
先还上把tcp_sock的结构放在这里,下面一些数据的分析需要用到:
struct tcp_sock {
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
u16 tcp_header_len; /* Bytes of tcp header to send */ // tcp头部长度
u16 xmit_size_goal_segs; /* Goal for segmenting output packets */// 分段数据包的数量
/*
* Header prediction flags
* 0x5?10 << 16 + snd_wnd in net byte order
*/
__be32 pred_flags; // 头部预置位(用于检测头部标识位处理ACK和PUSH之外还有没有其他位,从而判断是不是可以使用快速路径处理数据)
/*
* RFC793 variables by their proper names. This means you can
* read the code and the spec side by side (and laugh ...)
* See RFC793 and RFC1122. The RFC writes these in capitals.
*/
u32 rcv_nxt; /* What we want to receive next */ // 下一个想要收到的第一个数据的字节编号
u32 copied_seq; /* Head of yet unread data */ // 没还有读出的数据的头
u32 rcv_wup; /* rcv_nxt on last window update sent */ // rcv_nxt在最后一个窗口更新时的值
u32 snd_nxt; /* Next sequence we send */ // 下一个发送的第一个字节编号
u32 snd_una; /* First byte we want an ack for */ // 对于发出的数据,都需要对方的ACK,这里标示当前需要被确认的第一个字节
u32 snd_sml; /* Last byte of the most recently transmitted small packet */ // 最近发送的小数据包的最后一个字节
u32 rcv_tstamp; /* timestamp of last received ACK (for keepalives) */ // 最后一次接收到ACK的时间戳
u32 lsndtime; /* timestamp of last sent data packet (for restart window) */ // 最后一次发送数据包时间戳
u32 tsoffset; /* timestamp offset */ // 时间戳偏移
struct list_head tsq_node; /* anchor in tsq_tasklet.head list */ //
unsigned long tsq_flags;
// 注意下面这个ucopy:就是将用户数据从skb中拿出来放进去,然后传给应用进程!!!
/* Data for direct copy to user */
struct {
struct sk_buff_head prequeue; // 预处理队列
struct task_struct *task; // 预处理进程
struct iovec *iov; // 用户程序(应用程序)接收数据的缓冲区
int memory; // 用于预处理计数
int len; // 预处理长度
#ifdef CONFIG_NET_DMA
/* members for async copy */
struct dma_chan *dma_chan;
int wakeup;
struct dma_pinned_list *pinned_list;
dma_cookie_t dma_cookie;
#endif
} ucopy;
// snd_wl1:记录发送窗口更新时,造成窗口更新的那个数据报的第一个序号。 它主要用于在下一次判断是否需要更新发送窗口。
u32 snd_wl1; /* Sequence for window update */ // 窗口更新序列号( 每一次收到确认之后都会改变 )
u32 snd_wnd; /* The window we expect to receive */ // 我们期望收到的窗口
u32 max_window; /* Maximal window ever seen from peer */ // 从对方接收到的最大窗口
u32 mss_cache; /* Cached effective mss, not including SACKS */ // 有效的MSS,SACKS不算
u32 window_clamp; /* Maximal window to advertise */ // 对外公布的最大的窗口
u32 rcv_ssthresh; /* Current window clamp */ // 当前窗口值
u16 advmss; /* Advertised MSS */ // 对外公布的MSS
u8 unused;
u8 nonagle : 4,/* Disable Nagle algorithm? */ // Nagle算法是否有效
thin_lto : 1,/* Use linear timeouts for thin streams */ // 使用线性超时处理
thin_dupack : 1,/* Fast retransmit on first dupack */ // 收到第一个重复的ACK的时候是否快速重传
repair : 1,
frto : 1;/* F-RTO (RFC5682) activated in CA_Loss */
u8 repair_queue;
u8 do_early_retrans:1,/* Enable RFC5827 early-retransmit */ // 是否可以使用之前的重传
syn_data:1, /* SYN includes data */ // data中是否包含SYN
syn_fastopen:1, /* SYN includes Fast Open option */ // SYN选项
syn_data_acked:1;/* data in SYN is acked by SYN-ACK */ // SYN回复
u32 tlp_high_seq; /* snd_nxt at the time of TLP retransmit. */ // tlp重传时候snd_nxt的值
/* RTT measurement */
u32 srtt; /* smoothed round trip time << 3 */ // 往返时间
u32 mdev; /* medium deviation */ //
u32 mdev_max; /* maximal mdev for the last rtt period */ // 最大mdev
u32 rttvar; /* smoothed mdev_max */
u32 rtt_seq; /* sequence number to update rttvar */
u32 packets_out; /* Packets which are "in flight" */ // 已经发出去的尚未收到确认的包
u32 retrans_out; /* Retransmitted packets out */ // 重传的包
u16 urg_data; /* Saved octet of OOB data and control flags */ // OOB数据和控制位
u8 ecn_flags; /* ECN status bits. */ // ECN状态位
u8 reordering; /* Packet reordering metric. */ // 包重排度量
u32 snd_up; /* Urgent pointer */ // 紧急指针
u8 keepalive_probes; /* num of allowed keep alive probes */
/*
* Options received (usually on last packet, some only on SYN packets).
*/
struct tcp_options_received rx_opt; // tcp接收选项
/*
* Slow start and congestion control (see also Nagle, and Karn & Partridge)
*/
u32 snd_ssthresh; /* Slow start size threshold */ // 慢启动的开始大小
u32 snd_cwnd; /* Sending congestion window */ // 发送阻塞窗口
u32 snd_cwnd_cnt; /* Linear increase counter */ // 线性增长计数器(为了窗口的扩大)
u32 snd_cwnd_clamp; /* Do not allow snd_cwnd to grow above this */ // snd_cwnd值不可以超过这个门限
u32 snd_cwnd_used;
u32 snd_cwnd_stamp;
u32 prior_cwnd; /* Congestion window at start of Recovery. */ // 在刚刚恢复时候的阻塞窗口大小
u32 prr_delivered; /* Number of newly delivered packets to // 在恢复期间接收方收到的包
* receiver in Recovery. */
u32 prr_out; /* Total number of pkts sent during Recovery. */ // 在恢复期间发出去的包
u32 rcv_wnd; /* Current receiver window */ // 当前接收窗口
u32 write_seq; /* Tail(+1) of data held in tcp send buffer */ // tcp发送buf中数据的尾部
u32 notsent_lowat; /* TCP_NOTSENT_LOWAT */
u32 pushed_seq; /* Last pushed seq, required to talk to windows */ // push序列
u32 lost_out; /* Lost packets */ // 丢失的包
u32 sacked_out; /* SACK'd packets */ // SACK包
u32 fackets_out; /* FACK'd packets */ // FACK包
u32 tso_deferred;
/* from STCP, retrans queue hinting */
struct sk_buff* lost_skb_hint; // 用于丢失的包
struct sk_buff *retransmit_skb_hint; // 用于重传的包
struct sk_buff_head out_of_order_queue; /* Out of order segments go here */ // 接收到的无序的包保存
/* SACKs data, these 2 need to be together (see tcp_options_write) */
struct tcp_sack_block duplicate_sack[1]; /* D-SACK block */
struct tcp_sack_block selective_acks[4]; /* The SACKS themselves*/
struct tcp_sack_block recv_sack_cache[4];
struct sk_buff *highest_sack; /* skb just after the highest
* skb with SACKed bit set
* (validity guaranteed only if
* sacked_out > 0)
*/
int lost_cnt_hint;
u32 retransmit_high; /* L-bits may be on up to this seqno */
u32 lost_retrans_low; /* Sent seq after any rxmit (lowest) */
u32 prior_ssthresh; /* ssthresh saved at recovery start */
u32 high_seq; /* snd_nxt at onset of congestion */
u32 retrans_stamp; /* Timestamp of the last retransmit,
* also used in SYN-SENT to remember stamp of
* the first SYN. */
u32 undo_marker; /* tracking retrans started here. */
int undo_retrans; /* number of undoable retransmissions. */
u32 total_retrans; /* Total retransmits for entire connection */
u32 urg_seq; /* Seq of received urgent pointer */
unsigned int keepalive_time; /* time before keep alive takes place */
unsigned int keepalive_intvl; /* time interval between keep alive probes */
int linger2;
/* Receiver side RTT estimation */
struct {
u32 rtt;
u32 seq;
u32 time;
} rcv_rtt_est;
/* Receiver queue space */
struct {
int space;
u32 seq;
u32 time;
} rcvq_space;
/* TCP-specific MTU probe information. */
struct {
u32 probe_seq_start;
u32 probe_seq_end;
} mtu_probe;
u32 mtu_info; /* We received an ICMP_FRAG_NEEDED / ICMPV6_PKT_TOOBIG
* while socket was owned by user.
*/
#ifdef CONFIG_TCP_MD5SIG
/* TCP AF-Specific parts; only used by MD5 Signature support so far */
const struct tcp_sock_af_ops *af_specific;
/* TCP MD5 Signature Option information */
struct tcp_md5sig_info __rcu *md5sig_info;
#endif
/* TCP fastopen related information */
struct tcp_fastopen_request *fastopen_req;
/* fastopen_rsk points to request_sock that resulted in this big
* socket. Used to retransmit SYNACKs etc.
*/
struct request_sock *fastopen_rsk;
};关于窗口的操作值snd_una,snd_wnd等可以看下面的图形:
先看发送窗口:
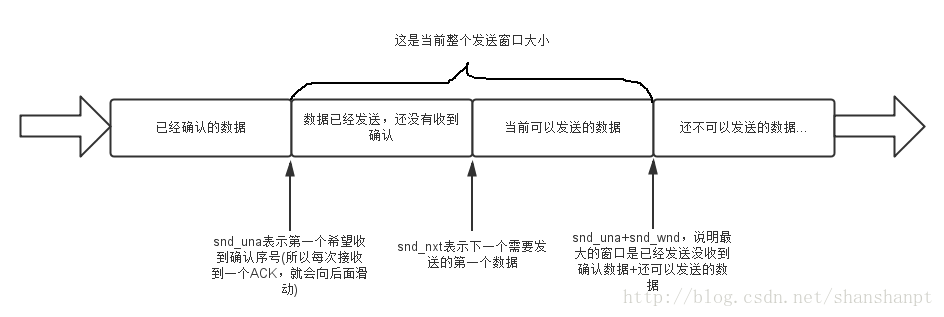
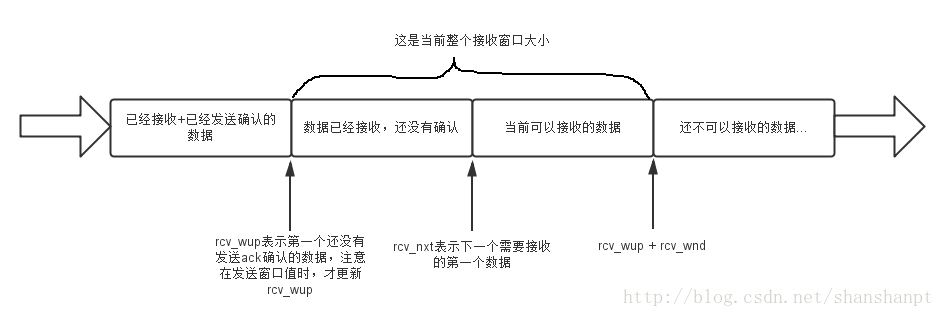
再看接收窗口:
还有tcp_skb_cb结构:
struct tcp_skb_cb {
union {
struct inet_skb_parm h4;
#if defined(CONFIG_IPV6) || defined (CONFIG_IPV6_MODULE)
struct inet6_skb_parm h6;
#endif
} header; /* For incoming frames */
__u32 seq; // 当前tcp包的第一个序列号
__u32 end_seq; // 表示结束的序列号:seq + FIN + SYN + 数据长度len
__u32 when; // 用于计算RTT
__u8 flags; // tcp头的flag
__u8 sacked; // SACK/FACK的状态flag或者是sack option的偏移
__u32 ack_seq; // ack(确认)的序列号
};
关于tcp头的标识(flags)可以取:
#define TCPCB_FLAG_FIN 0x01 // FIN 结束符
#define TCPCB_FLAG_SYN 0x02 // SYN 握手
#define TCPCB_FLAG_RST 0x04 // RST 重置
#define TCPCB_FLAG_PSH 0x08 // PSH 接收方要立即处理
#define TCPCB_FLAG_ACK 0x10 // ACK ack段有效
#define TCPCB_FLAG_URG 0x20 // URG 紧急指针
#define TCPCB_FLAG_ECE 0x40 // ECE 有拥塞情况(可能是传播线路上的拥塞,例如路由器提供的信息)
#define TCPCB_FLAG_CWR 0x80 // CWR (发生某种拥塞,例如ICMP源抑制、本地设备拥塞)sack的标识:
#define TCPCB_SACKED_ACKED 0x01 // tcp的cb结构上是被sack确认的
#define TCPCB_SACKED_RETRANS 0x02 // 重传帧
#define TCPCB_LOST 0x04 // 丢失
#define TCPCB_TAGBITS 0x07 // tag bits ?
#define TCPCB_EVER_RETRANS 0x80
#define TCPCB_RETRANS (TCPCB_SACKED_RETRANS|TCPCB_EVER_RETRANS)OK,回到tcp_ack函数,函数的主要功能是:
1 更新重传队列。
2 更新发送窗口。
3 从sack的信息或者重复ack来决定是否进入拥塞模式。
/* This routine deals with incoming acks, but not outgoing ones. */
static int tcp_ack(struct sock *sk, struct sk_buff *skb, int flag)
{
struct inet_connection_sock *icsk = inet_csk(sk); // 获得连接sock
struct tcp_sock *tp = tcp_sk(sk); // 获得tcp_sock
u32 prior_snd_una = tp->snd_una; // 获得未发送确认的序号
u32 ack_seq = TCP_SKB_CB(skb)->seq; // 获得数据序号
u32 ack = TCP_SKB_CB(skb)->ack_seq; // 获得ack序号(用于确认的序号)
u32 prior_in_flight;
u32 prior_fackets;
int prior_packets;
int frto_cwnd = 0;
/* If the ack is newer than sent or older than previous acks
* then we can probably ignore it.
*/
if (after(ack, tp->snd_nxt)) // 如果确认序号比我还下一个准备发送的序号还要大,即确认了我们尚未发送的数据,那么显然不合理
goto uninteresting_ack; // 没有意义的ACK
if (before(ack, prior_snd_una)) // 如果ack确认比我期望的确认序号小,那么可能是以前老的ack,丢弃!!!
goto old_ack; // 老的ack
if (after(ack, prior_snd_una)) // 如果ack确认比我期望的第一个ack要大,但是经过上面我们还知道没有超过我没有发送的数据序号,范围
flag |= FLAG_SND_UNA_ADVANCED; // 那么设置标识~
if (sysctl_tcp_abc) { // 是否设置了tcp_abc,若有则我们不需要对每个ack确认都要拥塞避免,所以我们需要计算已经ack(确认)的字节数。
if (icsk->icsk_ca_state < TCP_CA_CWR)
tp->bytes_acked += ack - prior_snd_una; // 已经(确定)ack的字节数增大了( ack - prior_snd_una )大小
else if (icsk->icsk_ca_state == TCP_CA_Loss)
/* we assume just one segment left network */
tp->bytes_acked += min(ack - prior_snd_una,
tp->mss_cache);
}
prior_fackets = tp->fackets_out; // 得到fack的数据包的字节数
prior_in_flight = tcp_packets_in_flight(tp); // 计算还在传输的数据段的字节数,下面会说手这个函数!( 1 )
if (!(flag & FLAG_SLOWPATH) && after(ack, prior_snd_una)) { // 如果不是“慢路径” && ack确认比其需要的第一个大(正确的确认序号)
/* Window is constant, pure forward advance.
* No more checks are required.
* Note, we use the fact that SND.UNA>=SND.WL2.
*/
tcp_update_wl(tp, ack, ack_seq); // 需要更新sock中的snd_wl1字段:tp->snd_wl1 = ack_seq;( 记录造成发送窗口更新的第一个数据 )
tp->snd_una = ack; // snd_una更新为已经确认的序列号!下一次期待从这里开始的确认!!!
flag |= FLAG_WIN_UPDATE; // 窗口更新标识
tcp_ca_event(sk, CA_EVENT_FAST_ACK); // 重要函数!!!进入拥塞操作!这个函数最后看,这里处理的是“正常的ACK”事件(999999)
NET_INC_STATS_BH(LINUX_MIB_TCPHPACKS);
} else {
if (ack_seq != TCP_SKB_CB(skb)->end_seq) // 如果不相等,那么说明还是带有数据一起的~不仅仅是一个ACK的包
flag |= FLAG_DATA; // 说明还是有数据的~
else
NET_INC_STATS_BH(LINUX_MIB_TCPPUREACKS); // 否则仅仅是ACK的包
flag |= tcp_ack_update_window(sk, skb, ack, ack_seq); // 下面需要更新发送窗口~(2)
if (TCP_SKB_CB(skb)->sacked) // 然后判断是否有sack段,有的话,我们进入sack段的处理。
flag |= tcp_sacktag_write_queue(sk, skb, prior_snd_una); // ~~~~~处理SACK(选择确认),以后单独解释
if (TCP_ECN_rcv_ecn_echo(tp, tcp_hdr(skb))) // 判断是否有ecn标记,如果有的话,设置ecn标记。
flag |= FLAG_ECE; // ECE 也是用于判断是否阻塞情况
tcp_ca_event(sk, CA_EVENT_SLOW_ACK); // 重要函数!!!进入拥塞操作!这个函数最后看,这里处理“其他ACK”事件(999999)
}
/* We passed data and got it acked, remove any soft error
* log. Something worked...
*/
sk->sk_err_soft = 0;
tp->rcv_tstamp = tcp_time_stamp;
prior_packets = tp->packets_out; // 获得发出去没有收到确认的包数量
if (!prior_packets) // 如果为0,则可能是0窗口探测包
goto no_queue;
/* See if we can take anything off of the retransmit queue. */
flag |= tcp_clean_rtx_queue(sk, prior_fackets); // 清理重传队列中的已经确认的数据段。(3)
if (tp->frto_counter) // 处理F-RTO (4)
frto_cwnd = tcp_process_frto(sk, flag); // 处理超时重传,暂时先不多说
/* Guarantee sacktag reordering detection against wrap-arounds */
if (before(tp->frto_highmark, tp->snd_una))
tp->frto_highmark = 0;
if (tcp_ack_is_dubious(sk, flag)) { // 判断ack是否可疑,其实本质就是判断可不可以增大拥塞窗口,下面会有详细解释(5)
/* Advance CWND, if state allows this. */
if ((flag & FLAG_DATA_ACKED) && !frto_cwnd && // 如果是数据确认包
tcp_may_raise_cwnd(sk, flag)) // 检测flag以及是否需要update拥塞窗口的大小!!!(6)--->被怀疑也有可能增大窗口哦~~~
tcp_cong_avoid(sk, ack, prior_in_flight); // 为真则更新拥塞窗口,拥塞避免算法(7)--->如果允许增大窗口,那么拥塞算法处理窗口
tcp_fastretrans_alert(sk, prior_packets - tp->packets_out, // 这里进入拥塞状态的处理,非常重要的函数(对于拥塞处理来说)!!!(8)
flag); // 处理完窗口变化之后,进入快速重传处理!!!
} else { // 没有被怀疑(说明是正常的确认ACK)
if ((flag & FLAG_DATA_ACKED) && !frto_cwnd)
tcp_cong_avoid(sk, ack, prior_in_flight); // 如果没有被怀疑,直接拥塞算法处理窗口变化
}
if ((flag & FLAG_FORWARD_PROGRESS) || !(flag & FLAG_NOT_DUP))
dst_confirm(sk->sk_dst_cache);
return 1;
no_queue:
icsk->icsk_probes_out = 0;
/* If this ack opens up a zero window, clear backoff. It was
* being used to time the probes, and is probably far higher than
* it needs to be for normal retransmission.
*/
if (tcp_send_head(sk)) // 这里判断发送缓冲区是否为空,如果不为空,则进入判断需要重启keepalive定时器还是关闭定时器
tcp_ack_probe(sk); // 处理定时器函数~(暂时不看)
return 1;
old_ack:
if (TCP_SKB_CB(skb)->sacked) // 如果有sack标识
tcp_sacktag_write_queue(sk, skb, prior_snd_una); // 进入sack段处理(暂时不看)
uninteresting_ack:
SOCK_DEBUG(sk, "Ack %u out of %u:%u\n", ack, tp->snd_una, tp->snd_nxt);// 没有意义的包~
return 0;
}-----------------------------------------------------------------------------------------------------------------------------------------
看看这个函数:tcp_packets_in_flight,就是计算还在传输中的字节数:
static inline unsigned int tcp_packets_in_flight(const struct tcp_sock *tp)
{
return tp->packets_out - tcp_left_out(tp) + tp->retrans_out;
}static inline unsigned int tcp_left_out(const struct tcp_sock *tp)
{
return tp->sacked_out + tp->lost_out;
}
-----------------------------------------------------------------------------------------------------------------------------------------
下面我们看一下“发送窗口”的更新tcp_ack_update_window:
static int tcp_ack_update_window(struct sock *sk, struct sk_buff *skb, u32 ack,
u32 ack_seq)
{
struct tcp_sock *tp = tcp_sk(sk); // 获得tcp_sock
int flag = 0;
u32 nwin = ntohs(tcp_hdr(skb)->window); // 获得skb发送方的可以接收的窗口值
if (likely(!tcp_hdr(skb)->syn)) // 如果不是建立连接时候,即是普通传递数据时候,窗口缩放
nwin <<= tp->rx_opt.snd_wscale; // 接收方要求对窗口进行缩放
// 下面正式更新窗口
if (tcp_may_update_window(tp, ack, ack_seq, nwin)) { // 可能需要更新窗口大小,在函数tcp_may_update_window中实际处理(1)
flag |= FLAG_WIN_UPDATE; // 窗口更新成功
tcp_update_wl(tp, ack, ack_seq); // 更新snd_wl1
if (tp->snd_wnd != nwin) { // 如果发送窗口!=缩放后的新窗口(注意skb发送方的接收窗口和本tp的发送窗口应该一致)
tp->snd_wnd = nwin; // 改变窗口值
/* Note, it is the only place, where
* fast path is recovered for sending TCP.
*/
tp->pred_flags = 0;
tcp_fast_path_check(sk); // 检验是否能够开启“快速路径”(2)看下面
if (nwin > tp->max_window) { // 如果调整之后的窗口大于从对方接收到的最大的窗口值
tp->max_window = nwin; // 调整为小的
tcp_sync_mss(sk, inet_csk(sk)->icsk_pmtu_cookie); // 改变mss_cache
}
}
}
tp->snd_una = ack; // 下一个第一个需要确认就是所有当前已经确认序号之后~~~~
return flag;
}
下面看这个函数:tcp_may_update_window
/* Check that window update is acceptable.
* The function assumes that snd_una<=ack<=snd_next.
*/ // 这个函数是检查窗口是否可变,只要确认ack在snd_una~下一个需要发送的数据之间,就是需要改变窗口的!
static inline int tcp_may_update_window(const struct tcp_sock *tp,
const u32 ack, const u32 ack_seq,
const u32 nwin)
{
return (after(ack, tp->snd_una) || // snd_una<=ack
after(ack_seq, tp->snd_wl1) || // 看上面的窗口图可以知道
(ack_seq == tp->snd_wl1 && nwin > tp->snd_wnd)); // 调整的新窗口大于原始发送窗口
}
看一下检测是否可以进入“快速路径”处理函数:tcp_fast_path_check
static inline void tcp_fast_path_check(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
if (skb_queue_empty(&tp->out_of_order_queue) &&
tp->rcv_wnd &&
atomic_read(&sk->sk_rmem_alloc) < sk->sk_rcvbuf &&
!tp->urg_data)
tcp_fast_path_on(tp);
}能够进入“快速路径”处理的基本条件是:
1 :是否ofo(乱序包队列)队列为空,如果不为空也就是说有乱序数据不可以进入快速路径。
2: 当前的接收窗口是否大于0.,如果不是,不可以进入。
3 :当前的已经提交的数据包大小是否小于接收缓冲区的大小,能够放的下才可以进入快速路径。
4: 是否含有urgent 数据,不含有才可以进入快速路径。
再看看 为tp开启快速路径函数tcp_fast_path_on:
static inline void tcp_fast_path_on(struct tcp_sock *tp)
{
__tcp_fast_path_on(tp, tp->snd_wnd >> tp->rx_opt.snd_wscale);
}
static inline void __tcp_fast_path_on(struct tcp_sock *tp, u32 snd_wnd)
{
tp->pred_flags = htonl((tp->tcp_header_len << 26) | // 看见没有。本质就是设置pred_flags变量
ntohl(TCP_FLAG_ACK) |
snd_wnd);
}
-----------------------------------------------------------------------------------------------------------------------------------------
下面看进入拥塞操作函数tcp_ca_event:
有必要先看看拥塞控制结构体:
struct tcp_congestion_ops {
struct list_head list;
unsigned long flags;
/* initialize private data (optional) */
void (*init)(struct sock *sk); // 初始化
/* cleanup private data (optional) */
void (*release)(struct sock *sk); // 清除数据
/* return slow start threshold (required) */
u32 (*ssthresh)(struct sock *sk); // 返回慢开始门限
/* lower bound for congestion window (optional) */
u32 (*min_cwnd)(const struct sock *sk); // 拥塞窗口最小值
/* do new cwnd calculation (required) */
void (*cong_avoid)(struct sock *sk, u32 ack, u32 in_flight); // 计算新的拥塞窗口
/* call before changing ca_state (optional) */
void (*set_state)(struct sock *sk, u8 new_state); // 设置拥塞状态
/* call when cwnd event occurs (optional) */
void (*cwnd_event)(struct sock *sk, enum tcp_ca_event ev); // 拥塞事件发生时候处理
/* new value of cwnd after loss (optional) */
u32 (*undo_cwnd)(struct sock *sk); // 丢包之后,拥塞窗口新的值
/* hook for packet ack accounting (optional) */
void (*pkts_acked)(struct sock *sk, u32 num_acked, s32 rtt_us); // 包的ack计数器
/* get info for inet_diag (optional) */
void (*get_info)(struct sock *sk, u32 ext, struct sk_buff *skb); //
char name[TCP_CA_NAME_MAX];
struct module *owner;
};看一下TCP拥塞事件:
/* Events passed to congestion control interface */
enum tcp_ca_event {
CA_EVENT_TX_START, /* first transmit when no packets in flight */
CA_EVENT_CWND_RESTART, /* congestion window restart */
CA_EVENT_COMPLETE_CWR, /* end of congestion recovery */
CA_EVENT_FRTO, /* fast recovery timeout */
CA_EVENT_LOSS, /* loss timeout */
CA_EVENT_FAST_ACK, /* in sequence ack */
CA_EVENT_SLOW_ACK, /* other ack */
};static inline void tcp_ca_event(struct sock *sk, const enum tcp_ca_event event) // 第三个参数在上面的来说分别是:CA_EVENT_SLOW_ACK和CA_EVENT_FAST_ACK
{
const struct inet_connection_sock *icsk = inet_csk(sk); // 获得连接sock
if (icsk->icsk_ca_ops->cwnd_event) // 注意这是一个函数指针:结构体struct tcp_congestion_ops中的!当拥塞事件发生时候执行
icsk->icsk_ca_ops->cwnd_event(sk, event); // 执行这个事件
}拥塞窗口事件初始化在这:
if (icsk->icsk_ca_ops == &tcp_init_congestion_ops) { 初始化结构体
rcu_read_lock();
list_for_each_entry_rcu(ca, &tcp_cong_list, list) {
if (try_module_get(ca->owner)) {
icsk->icsk_ca_ops = ca;
break;
}
/* fallback to next available */
}
rcu_read_unlock();
}struct tcp_congestion_ops tcp_init_congestion_ops = {
.name = "",
.owner = THIS_MODULE,
.ssthresh = tcp_reno_ssthresh,
.cong_avoid = tcp_reno_cong_avoid,
.min_cwnd = tcp_reno_min_cwnd,
};
这有点问题!对于这个函数没有进行实现?还是我没有找到处理赋值的地方?无语了~~~~~~~~~~~~~~~~~~~~~~~~
或许这里面初始化:下面是关于cwnd_event所有的初始化
static struct tcp_congestion_ops tcp_veno = {
.flags = TCP_CONG_RTT_STAMP,
.init = tcp_veno_init,
.ssthresh = tcp_veno_ssthresh,
.cong_avoid = tcp_veno_cong_avoid,
.pkts_acked = tcp_veno_pkts_acked,
.set_state = tcp_veno_state,
.cwnd_event = tcp_veno_cwnd_event, ///
.owner = THIS_MODULE,
.name = "veno",
};static struct tcp_congestion_ops tcp_vegas = {
.flags = TCP_CONG_RTT_STAMP,
.init = tcp_vegas_init,
.ssthresh = tcp_reno_ssthresh,
.cong_avoid = tcp_vegas_cong_avoid,
.min_cwnd = tcp_reno_min_cwnd,
.pkts_acked = tcp_vegas_pkts_acked,
.set_state = tcp_vegas_state,
.cwnd_event = tcp_vegas_cwnd_event, ///
.get_info = tcp_vegas_get_info,
.owner = THIS_MODULE,
.name = "vegas",
};static struct tcp_congestion_ops tcp_yeah = {
.flags = TCP_CONG_RTT_STAMP,
.init = tcp_yeah_init,
.ssthresh = tcp_yeah_ssthresh,
.cong_avoid = tcp_yeah_cong_avoid,
.min_cwnd = tcp_reno_min_cwnd,
.set_state = tcp_vegas_state,
.cwnd_event = tcp_vegas_cwnd_event,
.get_info = tcp_vegas_get_info,
.pkts_acked = tcp_yeah_pkts_acked,
.owner = THIS_MODULE,
.name = "yeah",
};-------------------------------------------------------------------------------------------------------------------------------------------
下面清理重传队列中已经确认的数据,看函数tcp_clean_rtx_queue:
看这个链接:tcp_clean_rtx_queue
现在可以看一下tcp_ack_is_dubious函数,来判断是不是进入了拥塞状态:
先可以看一下状态的定义:
#define FLAG_DATA 0x01 /* Incoming frame contained data. */ // 来了一个包含数据的包
#define FLAG_WIN_UPDATE 0x02 /* Incoming ACK was a window update. */ // 来了一个ACK用于更新窗口
#define FLAG_DATA_ACKED 0x04 /* This ACK acknowledged new data. */ // 对于数据的确认
#define FLAG_RETRANS_DATA_ACKED 0x08 /* "" "" some of which was retransmitted. */ // 对于重传数据的确认
#define FLAG_SYN_ACKED 0x10 /* This ACK acknowledged SYN. */ // 对于SYN的确认
#define FLAG_DATA_SACKED 0x20 /* New SACK. */ // 这是对数据的一个选择确认
#define FLAG_ECE 0x40 /* ECE in this ACK */ // 确认中旅带有ECE信息
#define FLAG_DATA_LOST 0x80 /* SACK detected data lossage. */ // SACK检测到数据丢失
#define FLAG_SLOWPATH 0x100 /* Do not skip RFC checks for window update.*/ // slowpath,需要做一些检查
#define FLAG_ONLY_ORIG_SACKED 0x200 /* SACKs only non-rexmit sent before RTO */
#define FLAG_SND_UNA_ADVANCED 0x400 /* Snd_una was changed (!= FLAG_DATA_ACKED) */ // snd-una改变
#define FLAG_DSACKING_ACK 0x800 /* SACK blocks contained D-SACK info */ // 包含DSACK信息
#define FLAG_NONHEAD_RETRANS_ACKED 0x1000 /* Non-head rexmitted data was ACKed */
#define FLAG_SACK_RENEGING 0x2000 /* snd_una advanced to a sacked seq */ // snd_una移动到一个sack中的一个位置
#define FLAG_ACKED (FLAG_DATA_ACKED|FLAG_SYN_ACKED) // 表示数据确认或者SYN确认
#define FLAG_NOT_DUP (FLAG_DATA|FLAG_WIN_UPDATE|FLAG_ACKED) // 表示ACK是不重复的
#define FLAG_CA_ALERT (FLAG_DATA_SACKED|FLAG_ECE) // 表示是否在进入拥塞状态的时候被alert(原因可能是SACK丢包或者路由器提示拥塞)
#define FLAG_FORWARD_PROGRESS (FLAG_ACKED|FLAG_DATA_SACKED) // 选择确认
再看一下:
TCP_CA_Open:TCP连接的初始化的状态。TCP连接会在慢启动和拥塞避免阶段(调用tcp_cong_avoid)增加拥塞窗口。每个接收到的ACK都要调用tcp_ack_is_dubious,检查它是否可疑。如果是ACK可疑,就调用 tcp_fastretrans_alert()就切换到其他CA拥塞状态。但是对于可疑的ACK,若窗口也允许增大(tcp_may_raise_cwnd),那么(tcp_fastretrans_alert)仍然可能增大拥塞窗口。
TCP_CA_Disorder:注意如果收到重复的ACK或者SACK,那么可能出现乱序情况,进入这个状态处理。
TCP_CA_CWR:表示发生某些道路拥塞,需要减慢发送速度。
TCP_CA_Recovery:正在进行快速重传丢失的数据包。
TCP_CA_Loss:超时重传情况下,如果接收到的ACK与SACK信息不一样,则阻塞丢包状态。
static inline int tcp_ack_is_dubious(const struct sock *sk, const int flag)
{
return (!(flag & FLAG_NOT_DUP) || (flag & FLAG_CA_ALERT) || // 是重复的ACK 或者 在进入拥塞状态的时候出现警告
inet_csk(sk)->icsk_ca_state != TCP_CA_Open); // 或者拥塞状态不是“增大拥塞窗口”状态
} // 则这个ACK是可疑的,其实意思就是,不是一个正常的ACK,不能随便增大拥塞窗口
下面就两条路:
1:如果被怀疑
2:如果没有被怀疑
先看如果被怀疑了,那么:
先看函数:tcp_may_raise_cwnd
static inline int tcp_may_raise_cwnd(const struct sock *sk, const int flag)
{
const struct tcp_sock *tp = tcp_sk(sk);
return (!(flag & FLAG_ECE) || tp->snd_cwnd < tp->snd_ssthresh) && // 没有其他阻塞 或者 (发送窗口小于门限&&不是Recovery ,也不是CWR)
!((1 << inet_csk(sk)->icsk_ca_state) & (TCPF_CA_Recovery | TCPF_CA_CWR)); // 那么这样还是可以增大窗口的嘛~~~~~ ^_^
}如果可以增大窗口,那么就需要使用tcp_cong_avoid执行这个函数用来实现慢启动和快速重传拥塞避免算法:
这个函数也是在“没有被怀疑”的情况下执行的函数,所以
如果没有被怀疑,执行的也是tcp_cong_avoid,一起解释:
static void tcp_cong_avoid(struct sock *sk, u32 ack, u32 in_flight)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
icsk->icsk_ca_ops->cong_avoid(sk, ack, in_flight); // 这才是重要处理函数
tcp_sk(sk)->snd_cwnd_stamp = tcp_time_stamp; // 发送窗口改变时间戳
}我们看到上面说的拥塞结构体的初始化:
struct tcp_congestion_ops tcp_init_congestion_ops = {
.name = "",
.owner = THIS_MODULE,
.ssthresh = tcp_reno_ssthresh,
.cong_avoid = tcp_reno_cong_avoid, //这个函数
.min_cwnd = tcp_reno_min_cwnd,
};那么实际执行的就是tcp_reno_cong_avoid函数!!!
看这个链接:tcp_reno_cong_avoid
----------------------------------------------------------------------------------------------------------------------------------
OK,下面再看看tcp_fastretrans_alert函数:TCP拥塞状态机主要是在tcp_fastretrans_alert()中实现的,只有在ACK被怀疑的时候才会执行这个提醒函数
此函数被调用的条件也就是怀疑的条件:
1:进来一个ACK,但是状态不是 Open
2:收到的是 SACK 、Duplicate ACK、ECN、ECE 等警告信息
请看这个链接:tcp_fastretrans_alert
到此为止,处理接收到的ACK基本结束。。。。















 1786
1786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









