






在监督学习中权衡偏差-方差(bias–variance)对于防止过拟合是重要的问题,理想情况下,我们想要选取一个模型,这个模型即能精确的捕获到训练数据的规律性,同时也能推演到未知的数据。不幸的是,不可能同时满足这2个条件。具有高方差的学习模型可能很好的表示训练集,但是有过拟合的风险,因为训练数据可能有噪声或者不具有代表性。相反的,带有高偏差的模型产生简单的模型,不会有过拟合(overfit)现象,但是可能在训练集上欠拟合(underfit),失败的捕获重要的规律。
带有低偏差的模型通常更复杂,能更精确的代表训练集,但是在测试集上正确率不高。相反的,带有高偏差的模型相对简单些。
我们有一个包含
x1,x2,...,xn
训练集,每个
xi
对应一个
yi
,我们假设有个函数并带有噪声
yi=f(xi)+e
,e是一个均值为0。
我们想找到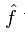
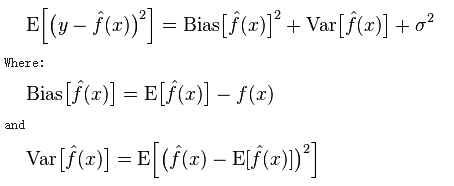
来自wikipedia: https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff
如果你的模型有很高的偏差,那么试着增加更多的特征。
如果你的模型有很高的方差,那么你能删除一些特征。另外一个解决方案是获取更多的数据(如果可以的话)。
保持模型复杂度常量,越多的数据,越难过拟合。
另外一个方面,越多的数据不会帮助我们(bias),如果你的模型不使用足够的特征获取数据的规律,那么再多的数据也帮不了你。















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









