







引题
使用Praat进行语音标注,这是Praat使用者最基础的功能。在较原始的语音生产阶段,我们开始用Praat标音,打开一个句子,一个时间点一个时间点的加蓝条条,还要调整,还要听,好不容易标完了一层,没想到你的方案决策者或许还会让你标几层,十多层。。。!?希望看到此处的你没有在眼科挂号。
毕业之后,你可能去了一家大厂,你发现这里标注的是上万句,这是什么鬼,毕业的目的应该不是来这里标蓝条条吧?!很显然,在所谓的大数据时代,这些大厂用的是自动标注。根据不同的使用情况和范围,不同层次的人的需求,这里将这个技术分为四个阶段:
第一,傻乎乎的自动标注,
第二,使用脚本的自动标注,
第三,使用诸如SPPAS的自动标注,
第四,较为专业的自动标注。
本篇从第一层次讲起,希望挖了这个坑,以后慢慢填完四个部分。
这里的“傻乎乎”不是意味着在评价个人能力。其实这不算是自动标注,只是叫自动加了标注条而已。如果你对技术操作,软件,脚本,都比较陌生,但,自己急着需要一种快速的方法,帮助自己完成标注,怎么办?怎么办?还有一种情况是做了少量的偏僻方言,或者稀缺语种的不太多的数据,这时候用后面高级的自动标注反而没办法用得上。
假定我们这里有一些音频,本例中用两个例子代替:
000001.wav
000002.wav
首先我们要明确这两个音频的内容,这里第一句话是“卡尔普陪外孙玩滑梯”,第二句话,我们为了更好的表达,用的是“卡尔普”这个词,下面做发音字典要说明为什么。那么我们要建立两个文本文件,写出这两句话的文本。
000001.txt
sent
卡 尔 普 陪 外 孙 玩 滑 梯
000002.txt
sent
卡 尔 普
解释一下,首先文本是用空格隔开的,这纯粹是为了方便Praat来分隔每一个字的内容,好添加到层级上。其次,第一行加了一个“sent”,也是为了方便Praat读取。这些操作用Python等编程语言是不需要这么复杂的,这是后话,如果有喜欢这篇文章,想对自己语料更方便的操作的,比如可以通过程序更方便的生成这个格式,可后续留言或者入群,小编将会继续方便大家使用。
假如有一些音频,按照上面的格式,把句子内容都保存为一个文本,我们称这些文件为label,这个操作无论用上述哪种方案都是需要的。包括下面要提到的做一个发音词典,当然对汉语来说,这个可以叫发音字典。而如果你的语料是英语类似的语言,它是有明显空格隔开的,那更是可以使用这个脚本操作。
下面,我们要准备一个发音词典,这个发音字典包括你音频里面所有的词条,或者字,它们的发音音素,注意要空格隔开,这也是为了读取出来增加到一个专门的层级上:
| word | phons |
|---|---|
| 卡 | k a2 |
| 尔 | er2 |
| 普 | p u3 |
| 陪 | p ei2 |
| 外 | w ai4 |
| 孙 | s un1 |
| 玩 | w an2 |
| 滑 | h ua2 |
| 梯 | t i1 |
实际操作中大家在Excel中制作好,拷贝到文本文件中保存就好了,第一行是表头,第一列和第二列之间用Tab隔开,这个也是为了方便Praat读取。
dict.txt
word phons
卡 k a2
尔 er2
普 p u3
陪 p ei2
外 w ai4
孙 s un1
玩 w an2
滑 h ua2
梯 t i1
解释一下,我们没有专门为第2句话制作字典,因为第二句话的三个字,都出现在第一句话里了,这个地方就为了说明你的字典,只要包括你的音频目录出现的所有内容就可以了。同理,制作英语这样语言的发音字典,也是把词和音素或者叫音标,保存起来就好。
操作解释
其实这里的主要操作,是根据这句话有几个字,或者几个词,平均分隔时长,增加上边界条,以及字/词的内容,同样,根据字/词的发音,再把音素也平均分开,增加到上面。所以这里只是增加了边界条,实际的边界是需要你去调整的。
运行脚本
本文的代码下载地址见下文(获取脚本部分)是23-auto_annotation_01/simple_auto_annotation.Praat。脚本里有我的邮箱,有任何问题都可以来信咨询。
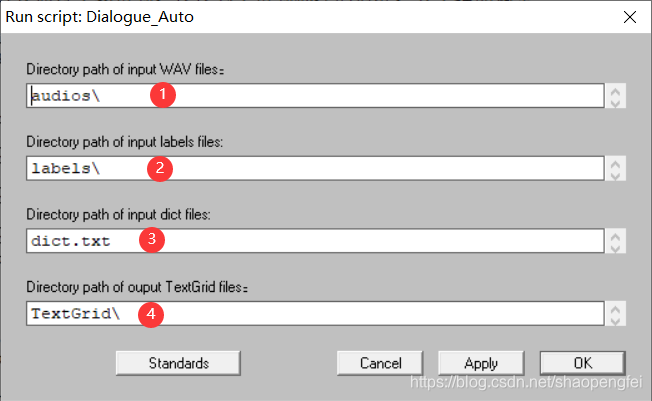
打开Praat之后,选择Praat,Open Praat Script...,打开这个脚本,然后在脚本窗口选择Run,Run,或者直接使用快捷键Ctrl+R,在弹出来的对话框里,设置以下几个地方:
- 设置你的
wav所在的目录,这里因为是在Windows系统,所以路径斜线是\,如果你是在Mac使用,将这个斜线方向反一下就好; - 同样的方法设置下面的
label目录,就是上面提取的文本文件目录; - 接着设置刚才字典的路径;
- 设置提取出来的结果文件的路径,这里就是TextGrid目录。
设置完毕,点击OK,运行脚本,我们分别打开这两个文件查看一下效果。
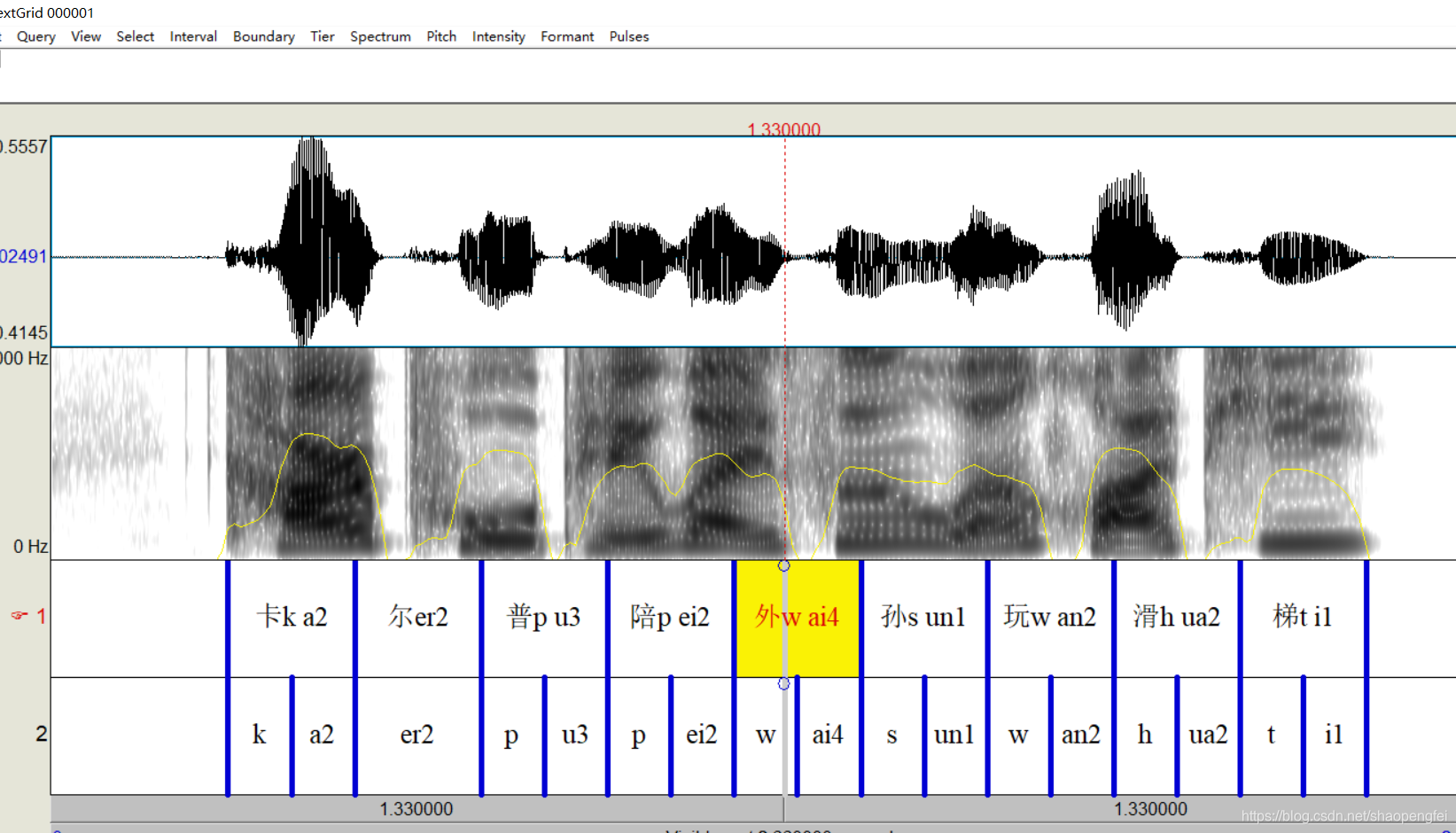
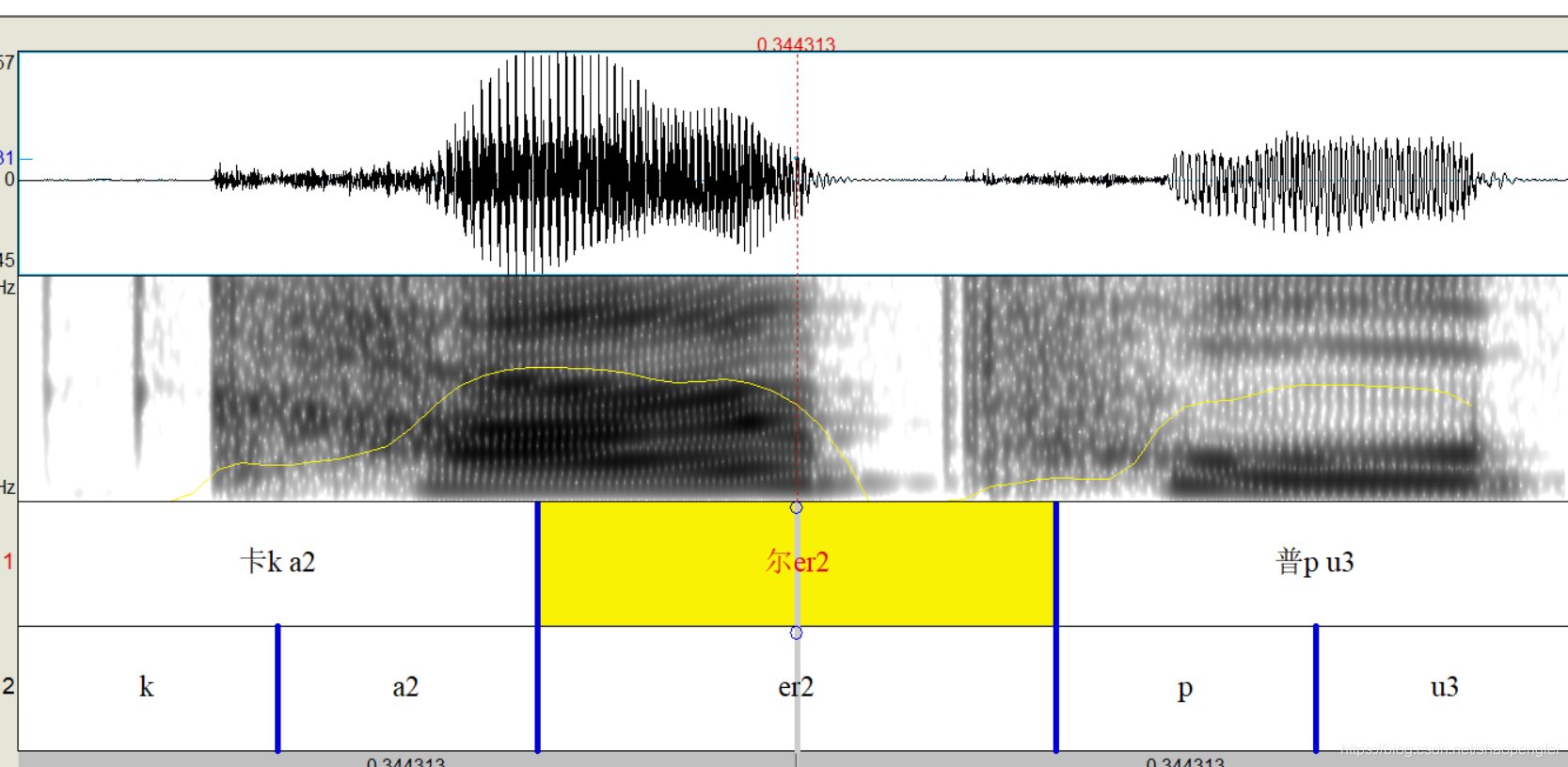
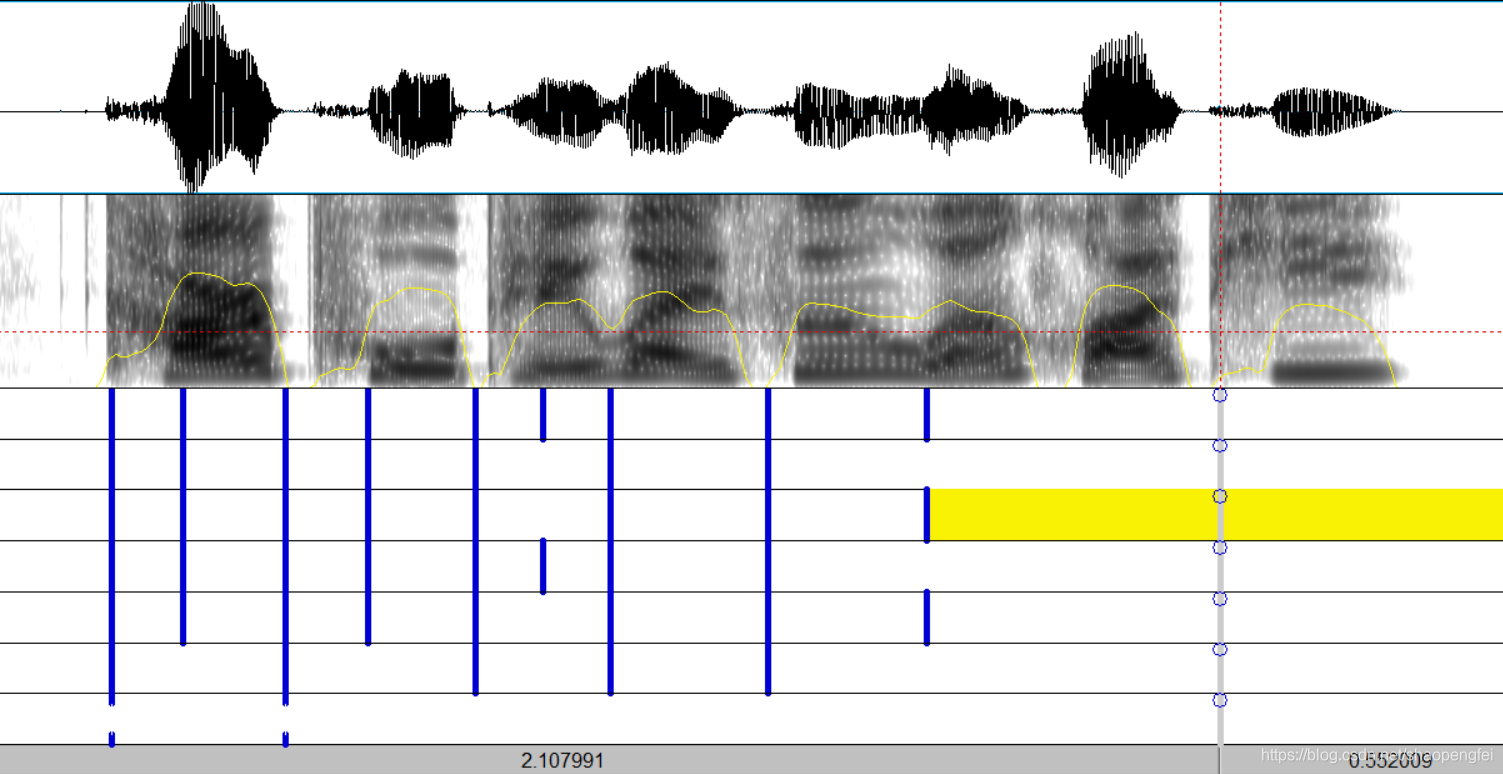
解释一下,第一句,因为音频比较规整,这个脚本加上了一个自动检测首尾静音段的功能,这个功能在第13个脚本自动切除首尾静音段使用过。所以突然看上去好象还比较准确,但是中间部分就是完全的进行了平均设置的。第二个脚本貌似无法用自动预测首尾静音段,所以就拿全部时长平均的,这也能看出来的。
不知道大家有没有对这个基础的标注功能有兴趣呢?如果没有满足你的胃口,可以静待后面更多的自动标注方案。
获取脚本
https://github.com/feelins/Praat_Scripts
说明:近期,貌似遇到了github如果不科学上网无法访问的情况,笔者也发现这个问题,后期有时间会将代码同步在一个国内容易访问的代码管理空间,目前还没有想好,请大家谅解哈,有兴趣可以加文末的QQ群,在群里私信发,会直接发给大家代码。
本站所有Praat脚本都可以在上述github的项目目录里找到,如果日常对代码、脚本操作比较熟练的可通过下载、安装、配置github for windows在自己的电脑上通过git clone将代码下载到本机,这样的好处是可以跟主站及时更新代码。
不想费如此脑筋,可以通过点击如下图Code位置所示,下载整站的代码,可直接使用。

关注
关于对本站脚本的使用咨询,以及功能修改,增加等,都可以扫QQ咨询群,私信群主。

版权说明
1、版权归本公众号“极地语音工作室”,原名“语音处理小站”所有;
2、未经本站或者作者允许, 不得任意转载本文内容,否则将视为侵权;
3、转载或者引用本文内容请注明来源及原作者;
4、对于不遵守此声明或者其他违法使用本站内容者,本人依法保留追究权等。


















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











