







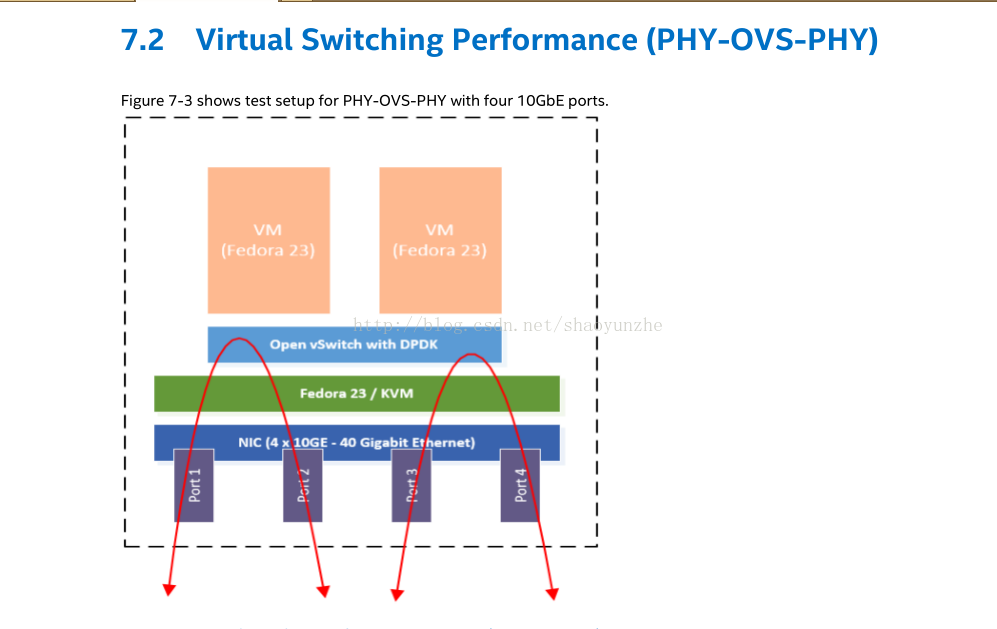
intel的实验《Intel_ONP_Release_2.1_Performance_Test_Report_Rev1.0》,测出的数据和文档基本吻合
在ovs里配置流表和不配置流表,转发效果区别很大
默认流表:正常启动ovs,不做流表配置
配置流表: ovs-ofctl del-flows br-bond_virt (删除默认流表)
ovs-ofctl add-flow br-bond_virt in_port=1,dl_type=0x800,idle_timeout=0,action=output:2
ovs-ofctl add-flow br-bond_virt in_port=3,dl_type=0x800,idle_timeout=0,action=output:1
命令中的port编号解释:1代表dpdk物理口,2代表进入vm的tap/vhostuser,3代表vm转出来的tap/vhostuser,由于我的实验环境只有一个物理口,所以数据进出都是同一个物理口。
vm接收数据包实验,pc发包1400万pps
实验1:pc->nic->nic->ovs->tap->vm 配置流表和默认流表vm接收都是80万pps左右,差距不大
实验2:pc->nic->nic->ovs+dpdk->vhostuser->vm 默认流表时,vm收包90万pps,配置流表600万pps
ovs+dpdk看转发效率可以使用ovs-appctl dpif-netdev/pmd-stats-show,查看每个数据包的cpu周期,配置流表后,每个数据包大概是400个cpu周期,默认流表一般是几千个cpu周期

















 1621
1621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









