







| 主题 | 概要 |
|---|---|
| Tesseract-OCR | Tesseract-OCR训练工具 |
| 编辑 | 时间 |
| 新建 | 20161008 |
| 更正训练步骤序号 | 20161225 |
| 序号 | 参考资料 |
| 1 | http://vietocr.sourceforge.net/training.html |
| 2 |
最近参加了一个人工智能的竞赛,主要完成的工作是扫描识别广告牌、包装盒上的文字,包括中文、英文、和数字,后续会有些编辑、翻译的功能。
先看几张要识别的样张:


第一张是比较正规的图片,下面主要以它们为例讲解这个工具的实现思路。
训练步骤
网上关于tesseract-OCR的训练工具都是清一色的jTessBoxEditor,但这工具对于中文字符的训练太过繁琐,特别是像这种广告牌,有背景,有艺术字,根本就找不到对应的box,就算找到了还要自己人工输入打标签,而且工具对utf-8格式的汉字还不能正常显示。
为了一劳永逸的解决这种问题,花了几天工夫写了个训练工具,虽然还是会有大量手工的操作,但是这些步骤都是必不可少的,已经找不到太好的方法省掉了。
首先看下工具的输入和输出:
输入是大量的从广告素材中剪切下来的图片:

输出是tesseract-OCR需要的box和tif文件:
Box文件中是标签和位置信息:

Tif中是归一化后的字符信息:

用jTessBoxEditor器打开这个box,观察可看出结果非常好:

有了这个box文件和tif文件,接下来就能用tesseract进行训练了,训练步骤网上有很多,下面主要说下这个工具的实现思路,说穿了就一文不值。
这个工具分成两个阶段。
第一阶段从广告牌图片中切出包含文字的部分,对于中文只能一行一行的切,而对于英文可以多行多行的切,这是因为两者使用的提取算法不一样导致的。这部分需要手工去操作。
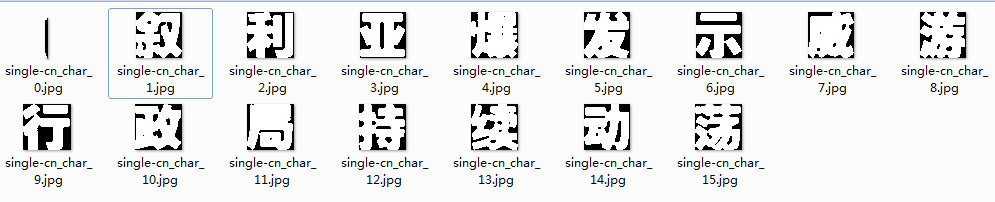
第一阶段输出的结果是二值化后的黑底白字的单个字符块:



第二个阶段就是以这些黑底白字的字符作为输入,需要给每个字符打上标签,即以这个字符开头重命名图片,第一个字符就代表了这个字符的标签。输出就是前文提到的box文件和tiff文件。这一阶段也是需要人工费时的去做,一方面需要一个一个正确的打标签,一方面对于有些第一阶段切下来的字符,效果不好的要去掉。
算法思想
下面来分析,拿到一张图片,比如:

这张图片,是怎么样把字符切割开来并写入到box文件和tif图片里面的?
这个过程涉及到了简单的图像处理,需要用到openCV库。
首先把图片进行灰度化、均衡化,最后进行大津阀值二值化:

二值化的结果统一转化成黑底白字。
下面要把文中的字符切割开来,对于英文和数字,直接取轮廓操作,并取最小外接矩形就行。对于中文,由于存在上下、左右结构,轮廓不连续,需要特殊处理。
处理步骤说来也简单,通过统计图片中每列像素为1的个数,从左到右扫描,遇到像素为1的个数大于某个值(我设为3个),就假定为一个字符的左边界;遇到像素为1的个数小于等于某个值(我设为3个),就假定为一个字符的右边界;字符的上下边界还是使用原来图片的边界。遇到左右结构的汉字时,这样可能会把偏旁部首分开,因此需要把前面个字符的右边界和后面个字符的左边界间隔小于某个阀值(2或3像素)的合并成一个字符。
接着遍历每个确定好左右边界的字符,从上到下扫描确定字符的上边界,从下到上扫描确定字符的下边界。也是通过统计像素为1的个数来确定。
边界确定好后,通过openCV取出ROI区域并输出即可,作为第一阶段的结果,如下图所示:
对于第二阶段,给上面第一阶段输出的字符打好标签并后怎么输出tesseract训练需要的box和tif文件?


先分析box文件的内容,第一列指定了该字符的标签,后面数字指定该字符在tif图片中的坐标位置和长宽信息。因而工具要做的工作就是,每当输出一个字符在tif图片中,就同时输出该字符的信息在box文件中。需要注意的是,第一阶段输出的字符是黑底白字,需要把它转为白底黑字输出到tif图片中,效果更好。另外,第一阶段的字符标签在VS中文环境中使用的是ansi编码,输出到box文件中的时候需转换为utf-8编码。
Tesseract训练及合并字库
利用工具分别得到中文、英文(包含数字)的box和tif文件,分别命名为:
len.ennormal.exp0.tif、len.ennormal.exp0.box、lcn.cnnormal.exp0.tif、lcn.cnnormal.exp0.box。
在pc上安装好tesseract-OCR,并切换到工作目录,按下列步骤进行训练即可得到合并的字库。
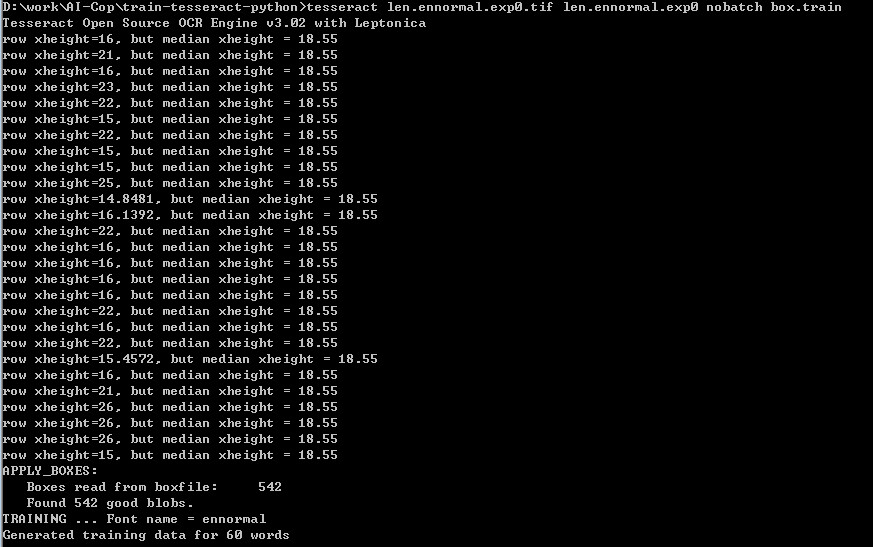
- 进行box train,得到tr特征文件
tesseract len.ennormal.exp0.tif len.ennormal.exp0 nobatch box.train
tesseract lcn.cnnormal.exp0.tif lcn.cnnormal.exp0 nobatch box.train
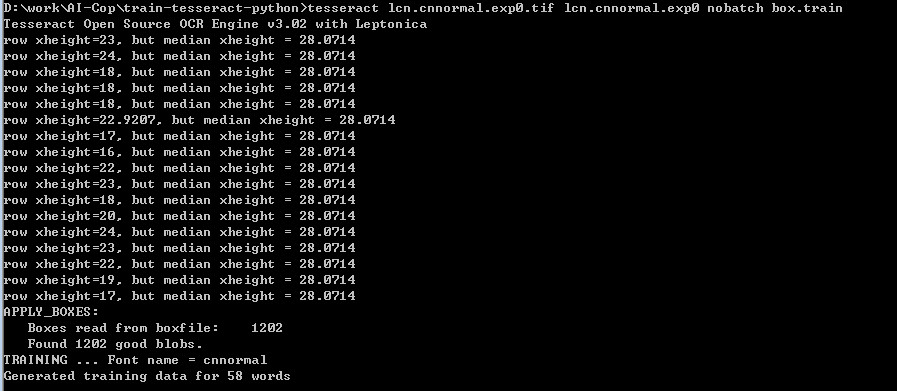
可以看到英文和中文分别多出了len.ennormal.exp0.tr lcn.cnnormal.exp0.tr特征文件。
2.获取中英文的字符集
unicharset_extractor len.ennormal.exp0.box lcn.cnnormal.exp0.box

3.定义字体特征文件
在目录下新建一个名字为“font_properties”的文件,并且输入文本 :
ennormal 0 1 0 0 0
cnnormal 0 1 0 0 0
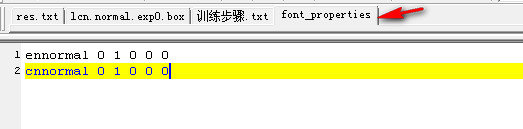
表示中英文字体文件,其中1表示为粗体。
4.聚集字符特征(inttemp、pffmtable、normproto)
mftraining –F font_properties -U unicharset len.ennormal.exp0.tr lcn.cnnormal.exp0.tr

5.Clustering,产生字符形状正常化特征文件normproto
cntraining len.ennormal.exp0.tr lcn.cnnormal.exp0.tr

6.合并训练文件
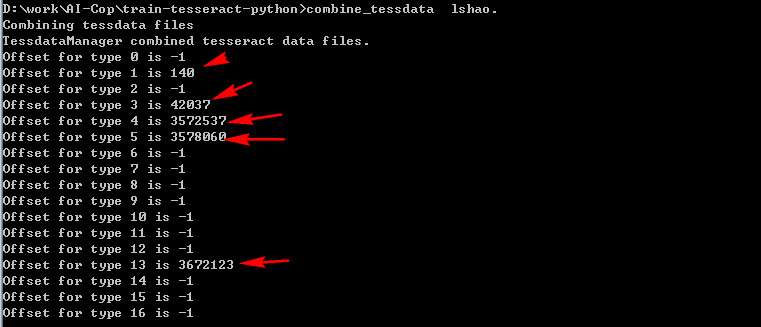
此时,在目录下应该生成若干个文件了,把unicharset, inttemp, normproto, pffmtable这四个文件加上前缀“lshao.”(可任意)。然后 合并训练文件
输入命令:
combine_tessdata lshao.
注意箭头所指的行不为-1,即代表训练成功。
把训练好的lshao.traineddata压缩成zip格式并放到android工程的assets目录中即可。
最后识别结果还是不尽人意,猜测是缺少了进行图像预处理的过程。















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









