






Hadoop
Hadoop3.x在centos上的完全分布式部署(包括免密登录、集群测试、历史服务器、日志聚集、常用命令、群起脚本)
1. 环境准备
- 三台虚拟机,
192.168.68.101、192.168.68.102、192.168.68.103《win10下VMware15安装CentOS7虚拟机》 - JDK(自行准备)
- hadoop安装包(官网下载地址:https://hadoop.apache.org/releases.html)
2. 创建用户
1.创建hadoop用户,并修改hadoop用户的密码
[root@localhost hadoop-3.3.1]# useradd hadoop
[root@localhost hadoop-3.3.1]# passwd hadoop
2.vim /etc/sudoers配置 hadoop 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令,在 %whieel 这行下面添加一行,如下所示:
%wheel ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
3.修改/data目录所有者和所属组
chown -R hadoop:hadoop /data/
4.三台虚拟机依次添加地址映射
vim /etc/hosts
将下面三行加入文件末尾
192.168.68.101 hadoop1
192.168.68.102 hadoop2
192.168.68.103 hadoop3
5.关闭防火墙(生产不能这么搞,生产开通几个指定端口即可)
firewall-cmd --state #查看防火墙状态
systemctl stop firewalld.service #停止firewalld服务
systemctl disable firewalld.service #开机禁用firewalld服务
3. 免密登录
- 到
/home/hadoop/.ssh/目录下,使用 hadoop 用户执行ssh-keygen -t rsa,然后回车三次,会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥) - 执行下面的命令将公钥拷贝到要免密登录的机器上,在另外两台机器上一次重复这两个步骤
ssh-copy-id 192.168.68.101
ssh-copy-id 192.168.68.102
ssh-copy-id 192.168.68.103
3现在三台机器的 hadoop 用户就可以免密登录了,再添加一个192.168.68.101的 root 用户免密登录到另外两台机器,用192.168.68.101的 root 用户,执行下面的命令
cd ~
cd .ssh
ssh-keygen -t rsa
ssh-copy-id 192.168.68.101
ssh-copy-id 192.168.68.102
ssh-copy-id 192.168.68.103
4..ssh文件夹下的文件功能解释
| 文件名 | 功能 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
4. 安装部署
- 将安装包分别上传到三台虚拟机

- 执行命令
tar -zxvf hadoop-3.3.1.tar.gz -C /data/解压到/data目录下

- 三台虚拟机依次添加环境变量,编辑
/etc/profile文件,添加以下内容,然后source /etc/profile保存,执行hadoop version命令检查是否添加成功
#HADOOP_HOME
export HADOOP_HOME=/data/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4.进入/data/hadoop-3.3.1/etc/hadoop路径,执行命令vim core-site.xml,编辑核心配置文件,添加以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置NameNode的URL -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.68.101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录,是hadoop文件系统依赖的基本配置,默认位置在/tmp/{$user}下,是个临时目录,一旦因为断电等外在因素影响,/tmp/${user}下的所有东西都会丢失 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop-3.3.1/data/tmp</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
5.执行命令vim hdfs-site.xml,编辑 HDFS 配置文件,添加以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- NameNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop-3.3.1/data/namenode</value>
</property>
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop-3.3.1/data/datanode</value>
</property>
<!-- NameNode web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.68.101:9870</value>
</property>
<!-- SecondaryNameNode web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.68.103:9868</value>
</property>
</configuration>
6.执行命令vim yarn-site.xml编辑 YARN 配置文件,添加以下内容:
<?xml version="1.0"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.68.102</value>
</property>
<!-- 为每个容器请求分配的最小内存限制资源管理器(512M) -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 为每个容器请求分配的最大内存限制资源管理器(4G) -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- 虚拟内存比例,默认为2.1,此处设置为4倍 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
7.执行命令vim mapred-site.xml编辑 MapReduce 配置文件,添加以下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 执行MapReduce的方式:yarn/local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.在/data/hadoop-3.3.1/etc/hadoop路径下,执行命令vim workers配置 workers(注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行)
192.168.68.101
192.168.68.102
192.168.68.103
9.创建对应目录
mkdir /data/hadoop-3.3.1/data/datanode
mkdir /data/hadoop-3.3.1/data/tmp
10.执行以下命令将配置好的 hadoop 安装包分发到另外两台机器
scp -r hadoop-3.3.1 root@192.168.68.102:/data/
scp -r hadoop-3.3.1 root@192.168.68.103:/data/
11.集群第一次启动,需要在主节点格式化 NameNode(均使用 hadoop 用户)(**注意:**格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化)
hdfs namenode -format
12.使用 hadoop 用户启动 HDFS
sbin/start-dfs.sh
13.在192.168.68.102上启动 YARN
sbin/start-yarn.sh
14.jps查看三台虚拟机的服务进程是否如下表所示
| 192.168.68.101 | 192.168.68.102 | 192.168.68.103 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| Yarn | NodeManager | ResourceManager NodeManager | NodeManager |
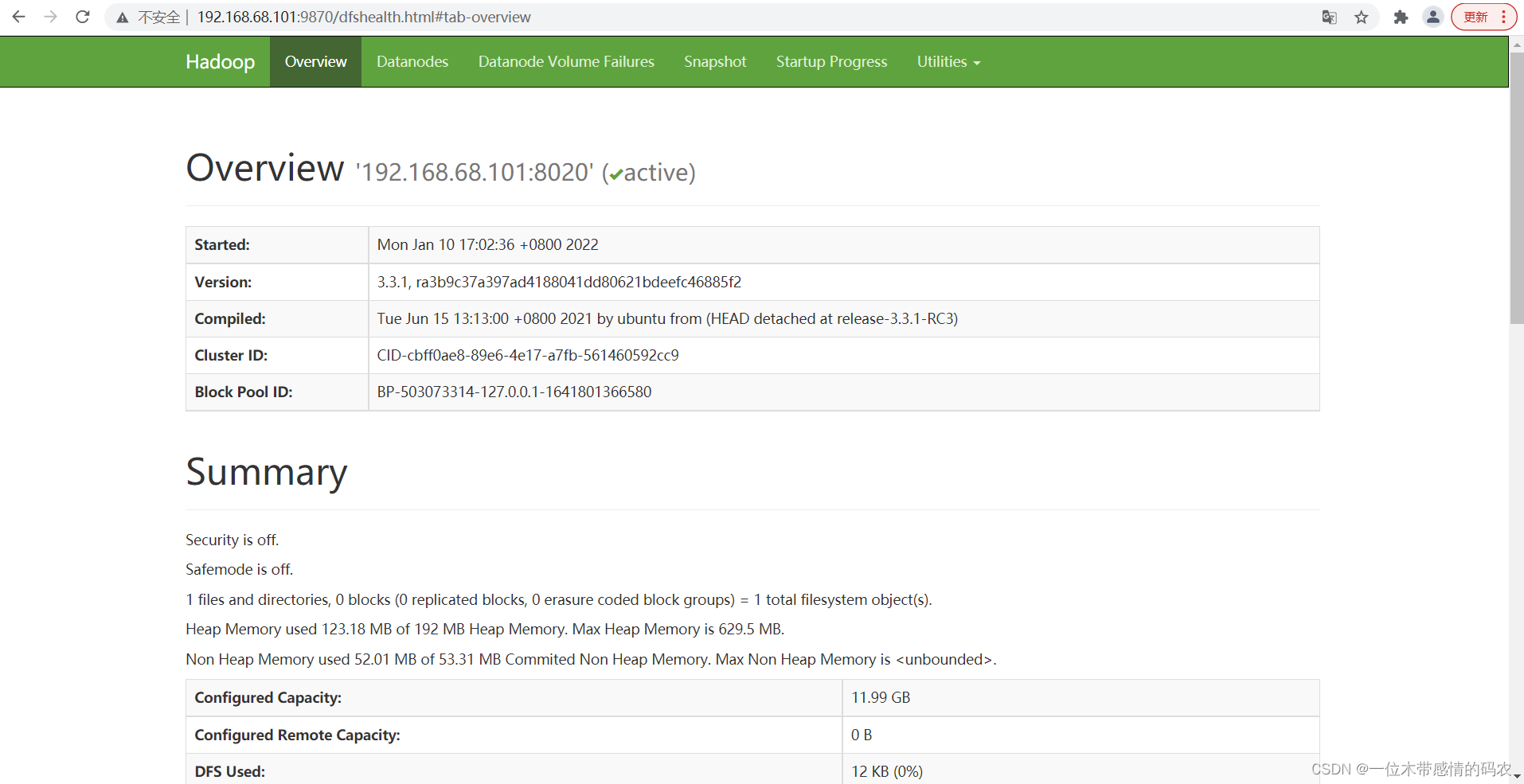
15.Web 端查看 HDFS 的 NameNode(可以在Utilities=>Browse the file system查看 HDFS 目录结构)
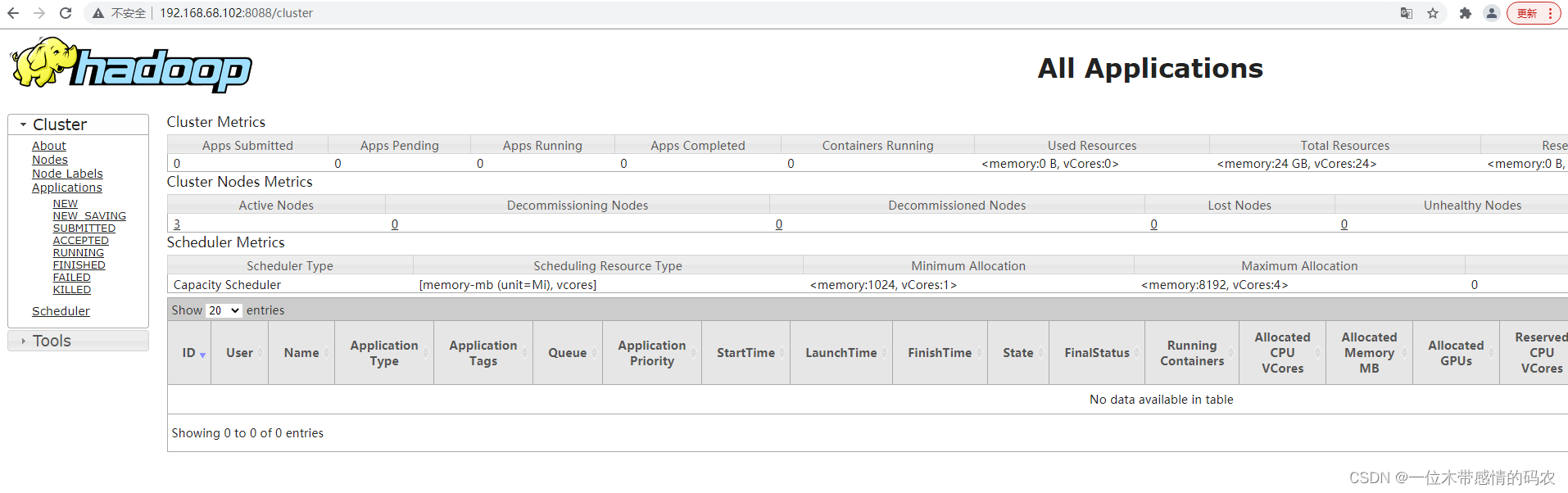
16.Web 端查看 YARN 的 ResourceManager
5. 集群基本测试
- 上传文件到集群
[hadoop@localhost hadoop-3.3.1]$ hadoop fs -mkdir /input
[hadoop@localhost hadoop-3.3.1]$ hadoop fs -put /data/input/1.txt /input
2.前往 HDFS 文件存储路径,查看 HDFS 在磁盘存储文件的内容
[hadoop@localhost subdir0]$ pwd
/data/hadoop-3.3.1/data/dfs/data/current/BP-503073314-127.0.0.1-1641801366580/current/finalized/subdir0/subdir0
[hadoop@localhost subdir0]$ ls
blk_1073741825 blk_1073741825_1001.meta
[hadoop@localhost subdir0]$ cat blk_1073741825
hello hadoop
stream data
flink spark
3.下载文件
[hadoop@localhost hadoop-3.3.1]$ hadoop fs -get /input/1.txt /data/output/
[hadoop@localhost hadoop-3.3.1]$ ls /data/output/
1.txt
[hadoop@localhost hadoop-3.3.1]$ cat /data/output/1.txt
hello hadoop
stream data
flink spark
4.执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
-----------------------------------------------------------------------------------------------------------
查看/output/下的文件内容(windows浏览器web页面拉取文件查看时,需在C:\Windows\System32\drivers\etc\hosts中添加 2.4 节说过的地址映射)
data 1
flink 1
hadoop 1
hello 1
spark 1
stream 1
5.计算圆周率(计算命令中 2 表示计算的线程数,50 表示投点数,该值越大,则计算的 pi 值越准确)
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 2 50
-----------------------------------------------------------------------------------------------------------
Job Finished in 23.948 seconds
Estimated value of Pi is 3.20000000000000000000
6. 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
vim mapred-site.xml编辑 MapReduce 配置文件,添加以下内容(三台虚拟机均需):
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.68.101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.68.101:19888</value>
</property>
2.在192.168.68.101启动历史服务器
开启:mapred --daemon start historyserver
关闭:mapred --daemon stop historyserver
-----------------------------------------------------------------------------------------------------------
#jps
15299 DataNode
15507 NodeManager
15829 Jps
15769 JobHistoryServer
15132 NameNode
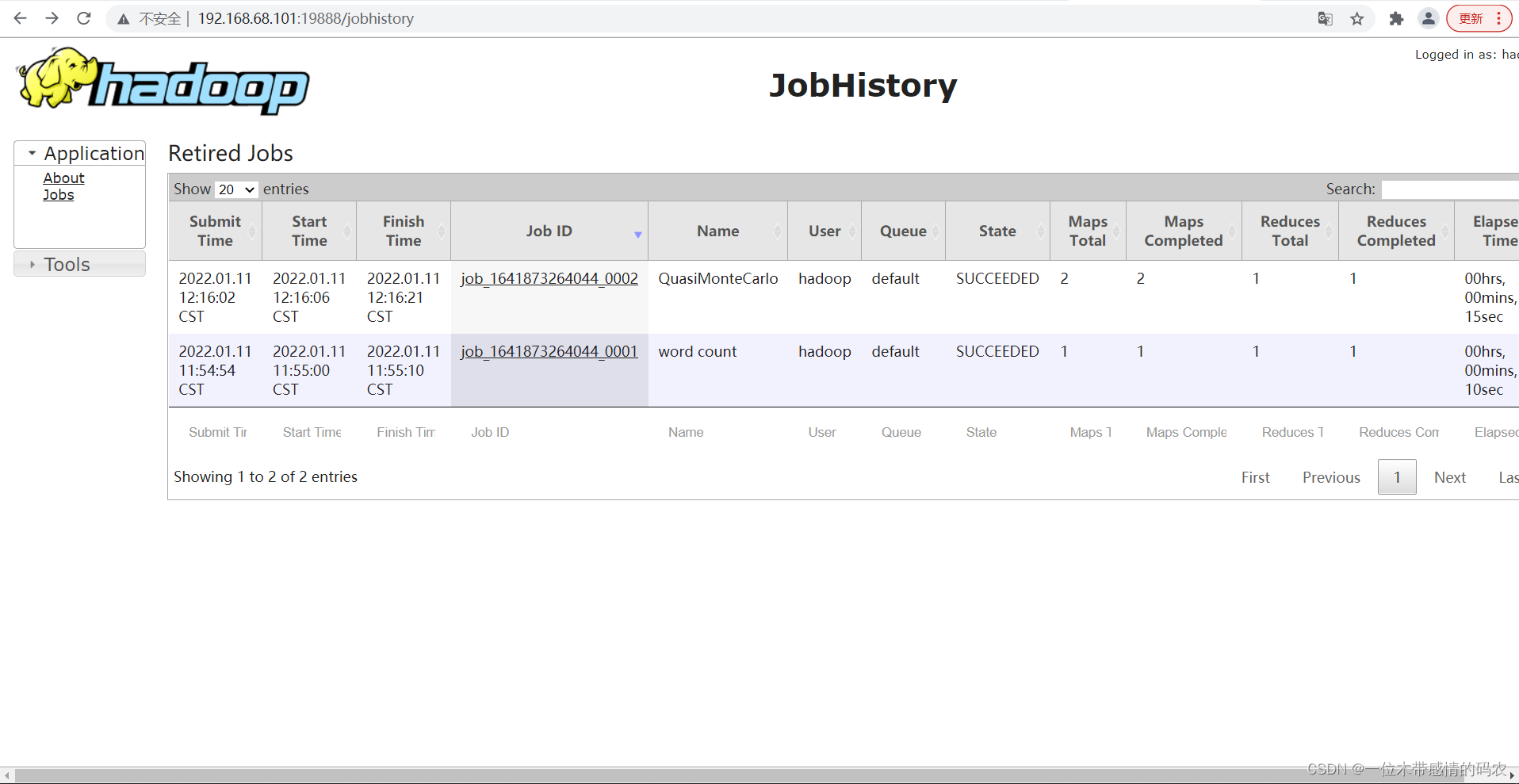
3.查看JobHistory
7. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
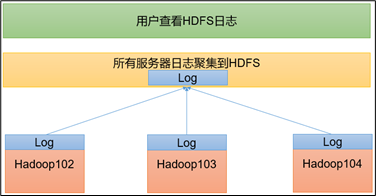
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
vim yarn-site.xml配置 yarn-site.xml,添加下面的内容(三台均需):
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.68.101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<!--<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>-->
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<!--<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>-->
2.重启服务,执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
3.查看日志
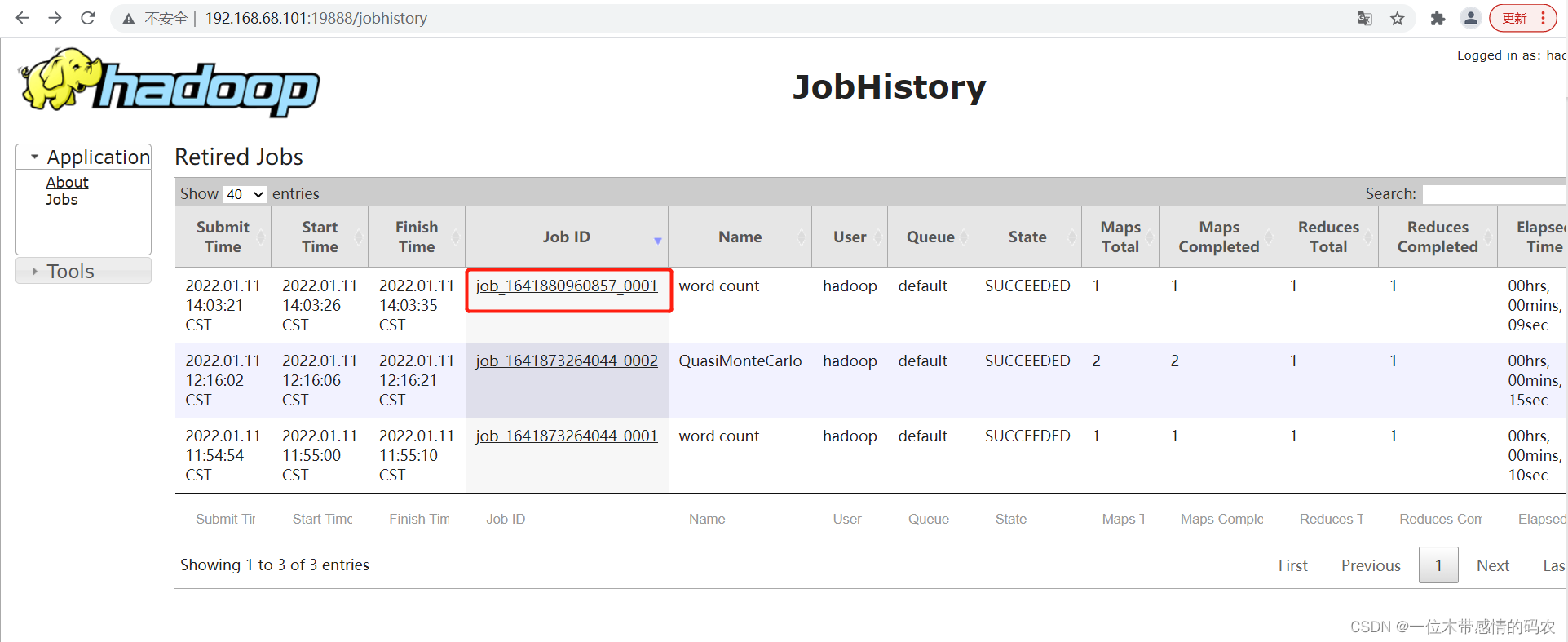
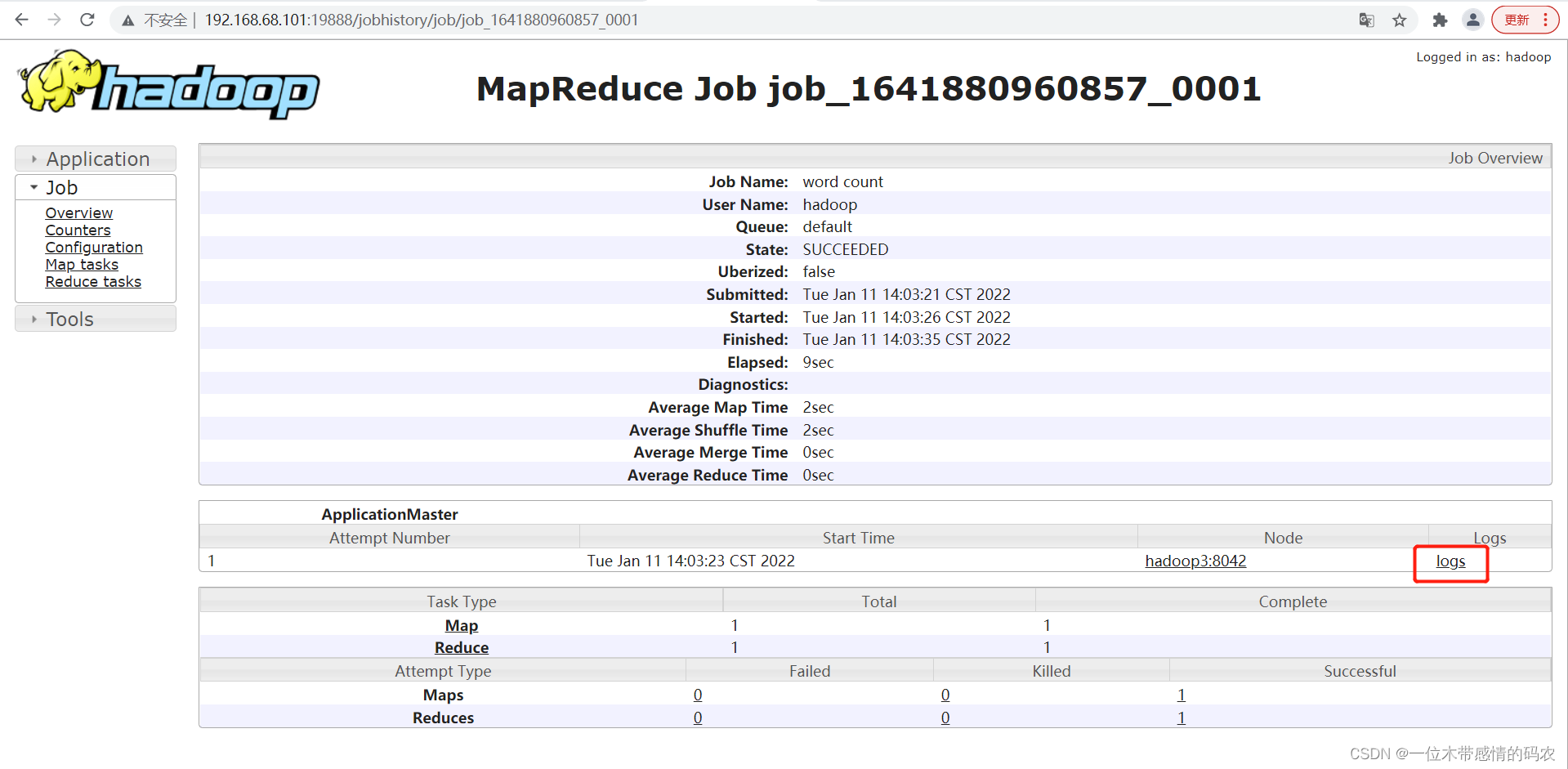
8. 集群启动/停止命令总结
- 各个模块分开启动/停止(前提配置ssh)
- 整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh
2.整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
- 各个服务组件逐一启动/停止
- 分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
2.启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
9. 集群群起脚本
vim myhadoop.sh添加下面内容并保存
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh 192.168.68.102 "/data/hadoop-3.3.1/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh 192.168.68.102 "/data/hadoop-3.3.1/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh 192.168.68.101 "/data/hadoop-3.3.1/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
2.chmod +x myhadoop.sh赋予脚本执行权限
3.启动/停止集群
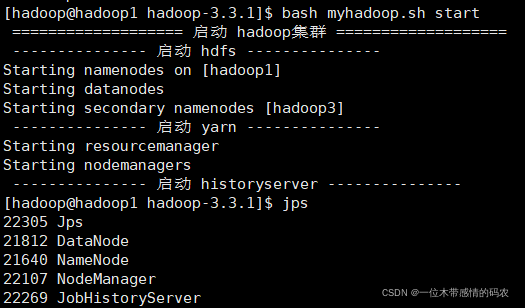
10. 常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000 / 9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
Hadoop 详解
1. Hadoop概述
1.1Hadoop是什么
-
Hadoop 是一个由Apache基金会所开发的
分布式系统基础架构 -
主要解决海量数据的
存储和海量数据的分析计算问题 -
广义上来说,Hadoop 通常是指一个更广泛的概念——
Hadoop生态圈
1.2 Hadoop发展简史
Hadoop 是 Apache Lucene 创始人 Doug Cutting 创建的。最早起源于 Nutch,它是 Lucene 的子项目。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
2003 年 Google 发表了一篇论文为该问题提供了可行的解决方案。论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
2004 年 Google 发表论文向全世界介绍了谷歌版的MapReduce系统。
同时期,以谷歌的论文为基础,Nutch 的开发人员完成了相应的开源实现 HDFS 和 MAPREDUCE,并从 Nutch 中剥离成为独立项目 HADOOP,到 2008 年 1 月,HADOOP 成为 Apache 顶级项目,迎来了它的快速发展期。
2006 年 Google 发表了论文是关于BigTable的,这促使了后来的 Hbase 的发展。
因此,Hadoop 及其生态圈的发展离不开 Google 的贡献。
1.2 Hadoop三大发行版本
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks
- 免费开源版本 Apache,
Apache版本是最原始(最基础)的版本,对于入门学习最好——2006年- 优点:拥有全世界的开源贡献者,代码更新迭代版本比较快
- 缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到
- 免费开源版本HortonWorks,Hortonworks 文档最好,对应产品
HDP(ambari)(Hortonworks 现已被 Cloudera 公司收购,推出新的品牌CDP)——2011年 - 软件收费版本 Cloudera,Cloudera 内部集成了很多大数据框架,对应产品
CDH——2008年- cloudera 主要是美国一家大数据公司在 apache 开源 hadoop 的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题
1…Apache Hadoop
官网地址:http://hadoop.apache.org
下载地址:https://hadoop.apache.org/releases.html
2.Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh
下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
3.Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
- cloudera 主要是美国一家大数据公司在 apache 开源 hadoop 的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题
1.3 Hadoop优势
-
高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
-
高扩展性: 在集群间分配任务数据,可方便的扩展数以千计的节点。
-
高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
-
高容错性: 能够自动将失败的任务重新分配。
-
成本低:Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
1.4 Hadoop的组成
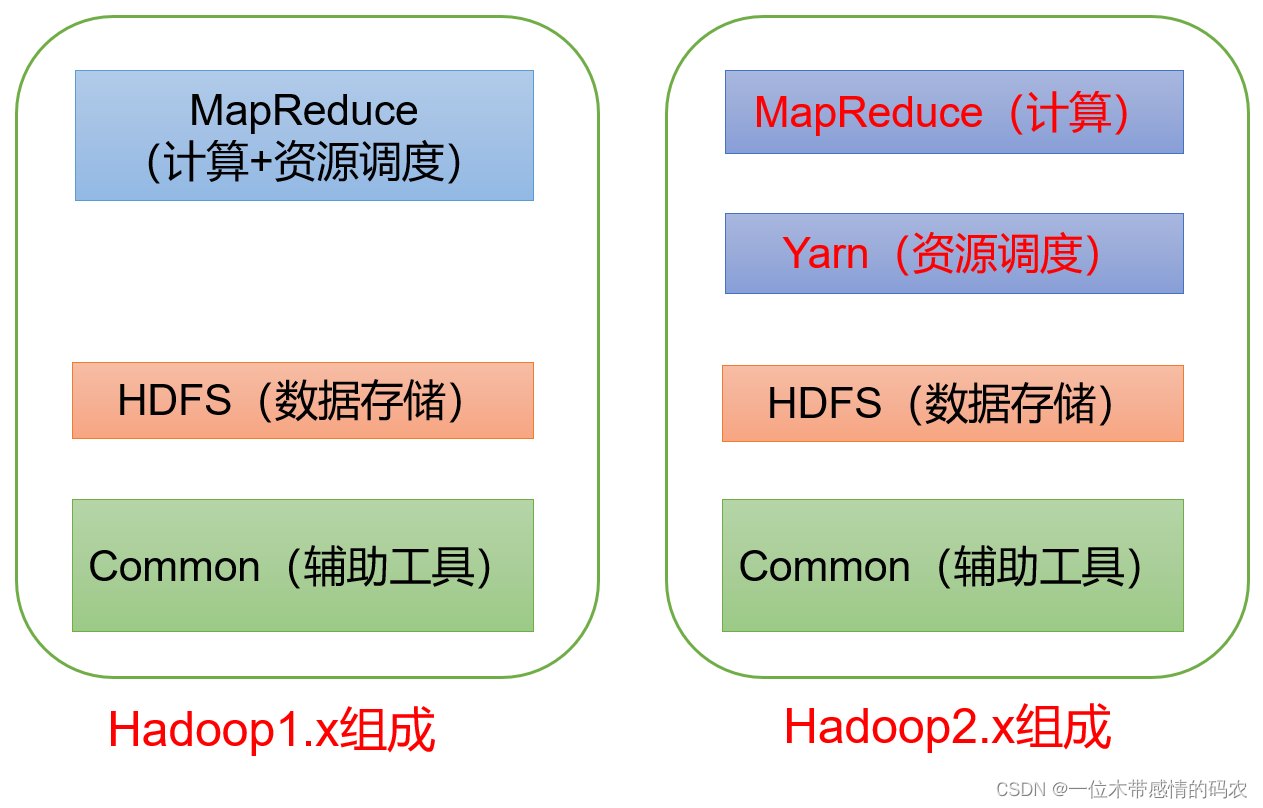
1.4.1 Hadoop1.x、2.x、3.x区别
在 Hadoop1.x 时代,Hadoop 中的 MapReduce 同时处理业务逻辑运算和资源的调度,耦合性较大。
在 Hadoop2.x 时代,增加了 Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。
Hadoop3.x 在组成上没有变化(3.x 的新特性后面再开新章节单独说)。
1.4.3 YARN架构概述
Yet Another Resource Negotiator 简称YARN,另一种资源协调者,是Hadoop的资源管理器,用来解决资源任务调度的问题。

1.ResourceManager (RM):整个集群资源(内存、CPU等) 的老大。
2.NodeManager (NM):单个节点服务器资源老大。
3.ApplicationMaster (AM):单个任务运行的老大。
4.Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、 磁盘、网络等。
1.4.4 MapReduce架构概述
MapReduce 是一个分布式运算编程框架,将计算过程分为两个阶段:Map 和 Reduce,用来解决海量数据计算的问题。
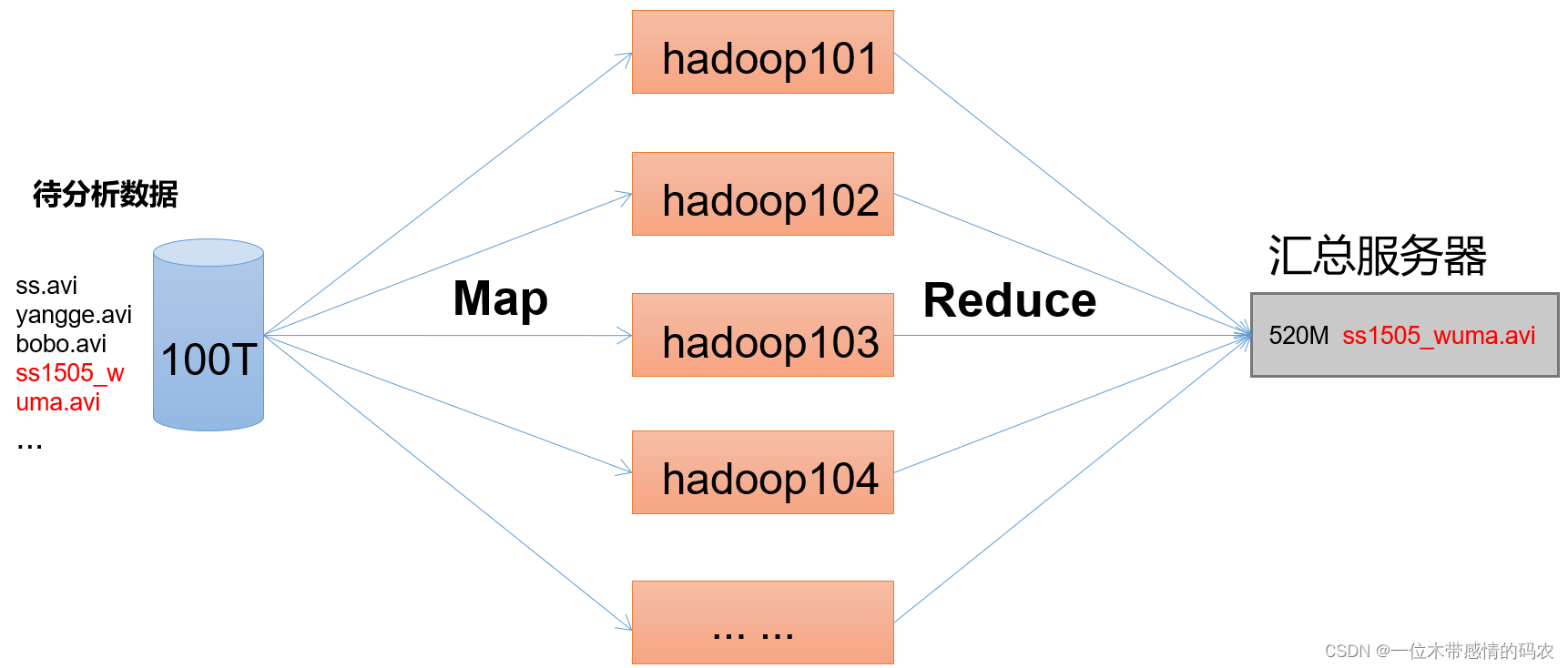
1.Map 阶段并行处理输入数据。
2.Reduce 阶段对 Map 结果进行汇总。
1.4.5 HDFS、YARN、MapReduce三者关系
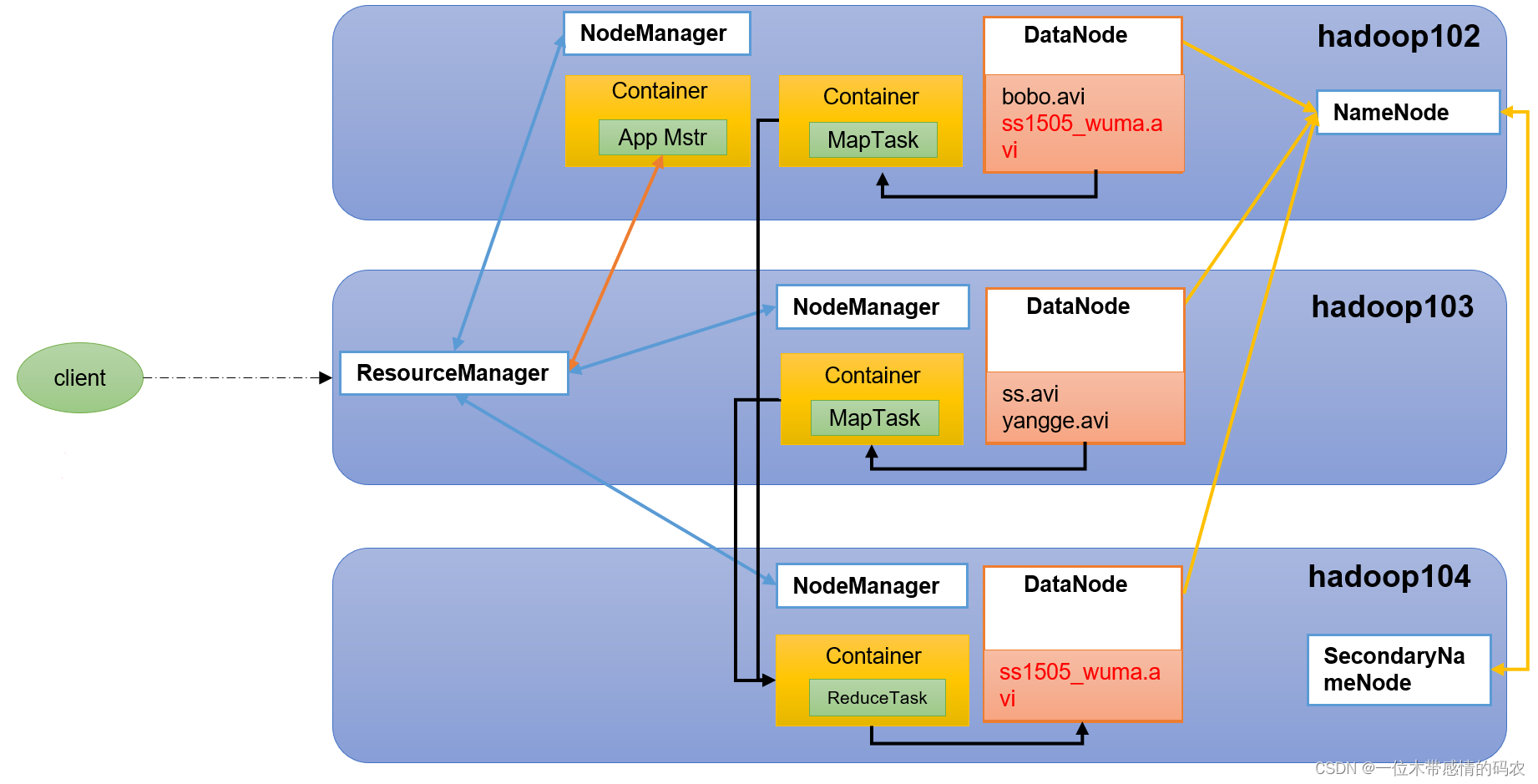
当下的 Hadoop 已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非 Apache 主管的项目,这些项目对 Hadoop 是很好的补充或者更高层的抽象。比如:
| 框架 | 用途 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式运算程序开发框架 |
| ZooKeeper | 分布式协调服务基础组件 |
| HIVE | 基于HADOOP的分布式数据仓库,提供基于SQL的查询数据操作 |
| FLUME | 日志数据采集框架 |
| oozie | 工作流调度框架 |
| Sqoop | 工作流调度框架 |
| Impala | 基于hive的实时sql查询分析 |
| Mahout | 基于mapreduce/spark/flink等分布式运算框架的机器学习算法库 |
东西比较多,博主后面再慢慢更新这些框架的详细介绍和用法。
1.5 Hadoop运行模式
Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
本地模式(standalone mode): 单机运行,仅 1 个机器运行1个java进程,主要用于调试
伪分布式模式(Pseudo-Distributed mode): 也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模拟一个分布式的环境,主要用于调试
完全分布式模式/集群模式(Cluster mode): 多台服务器组成分布式环境,生产环境使用
2.Hadoop的搭建
2.1 集群部署
完全分布式模式部署教程:《Hadoop3.x在centos上的完全分布式部署(包括免密登录、集群测试、历史服务器、日志聚集、常用命令、群起脚本)》
2.2 安装目录结构说明
| 目录 | 说明 |
|---|---|
| bin | Hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 |
| etc | Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml等从Hadoop1.0继承而来的配置文件和yarn-site.xml等Hadoop2.0新增的配置文件。 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 |
| lib | 该目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 |
| libexec | 各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin | Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。 |
| share | Hadoop各个模块编译后的jar包所在的目录,官方自带示例。 |
2.3 Hadoop配置文件详解
- hadoop-env.sh
- 文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME 是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
- core-site.xml
- Hadoop 的核心配置文件,有默认的配置项 core-default.xml。
- core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
- hdfs-site.xml
- HDFS 的核心配置文件,主要配置 HDFS 相关参数,有默认的配置项 hdfs-default.xml。
- hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
- mapred-site.xml
- MapReduce 的核心配置文件,Hadoop 默认只有一个模板文件 mapred-site.xml.template,需要使用该文件复制出来一份 mapred-site.xml 文件
- yarn-site.xml
- YARN 的核心配置文件
- workers
- workers文件里面记录的是集群主机名。一般有以下两种作用:
- 配合一键启动脚本如 start-dfs.sh、stop-yarn.sh 用来进行集群启动。这时候 slaves 文件里面的主机标记的就是从节点角色所在的机器
- 可以配合 hdfs-site.xml 里面 dfs.hosts 属性形成一种白名单机制。dfs.hosts 指定一个文件,其中包含允许连接到 NameNode 的主机列表。必须指定文件的完整路径名,那么所有在 workers中 的主机才可以加入的集群中。如果值为空,则允许所有主机。
- workers文件里面记录的是集群主机名。一般有以下两种作用:
3.HDFS基准测试
实际生产环境当中,Hadoop 的环境搭建完成之后,第一件事情就是进行压力测试,测试 Hadoop 集群的读取和写入速度,测试网络带宽是否足够等一些基准测试。
3.1 测试写入速度
向 HDFS 文件系统中写入数据,10 个文件,每个文件 10MB,文件存放到/benchmarks/TestDFSIO中。
1.执行下面命令,启动写入基准测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
2.MapReduce程序运行成功后,就可以查看测试结果了

可以看到目前虚拟机的 IO 吞吐量为:3.92MB/s
3.2 测试读取速度
测试 HDFS 的读取文件性能,在 HDFS 文件系统中读入 10 个文件,每个文件 10M。
1.执行下面命令,启动读取基准测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
2.查看读取结果

可以看到读取的吞吐量为:53.85MB/s
3.3清除测试数据
测试期间,会在 HDFS 集群上创建/benchmarks目录,测试完毕后,我们可以清理该目录。
1.hdfs dfs -ls -R /benchmarks
2.执行清理命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar TestDFSIO -clean
3.删除命令会将/benchmarks目录中内容删除

Hadoop3.x报错[main] DEBUG [org.apache.hadoop.util.Shell] - Failed to find winutils.exe
在写Hadoop生态圈专栏的博客时,打算给自己的电脑装上 hadoop 环境,结果不出意外的报了[main] DEBUG [org.apache.hadoop.util.Shell] - Failed to find winutils.exe的错,这里记录一下,当做笔记使用,防止以后自己再百度。
之所以出现此报错是因为在 windows 环境下缺少 Hadoop 的一些支持,需要下载一些资源配置之后才能使用,下载地址:https://github.com/cdarlint/winutils
网速慢的可以去网盘下载,我这里的 hadoop 版本是 3.3.1
链接:https://pan.baidu.com/s/1XaZPUOo_Qdk4tHzyg4DsTw
提取码:6666
其中winutils.exe文件放在我们自己 hadoop 安装包的bin目录下,如下所示
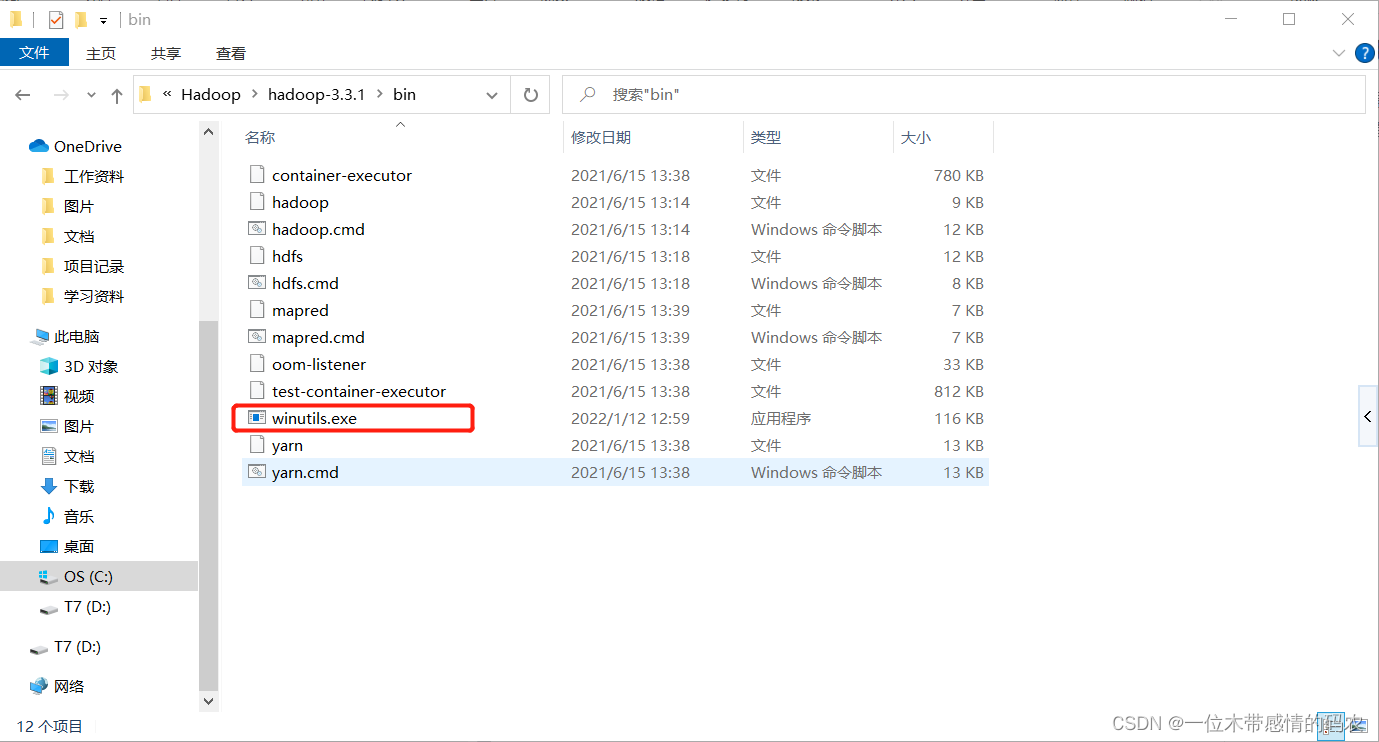
hadoop.dll文件放在我们的C:\Windows\System32目录下,如下所示
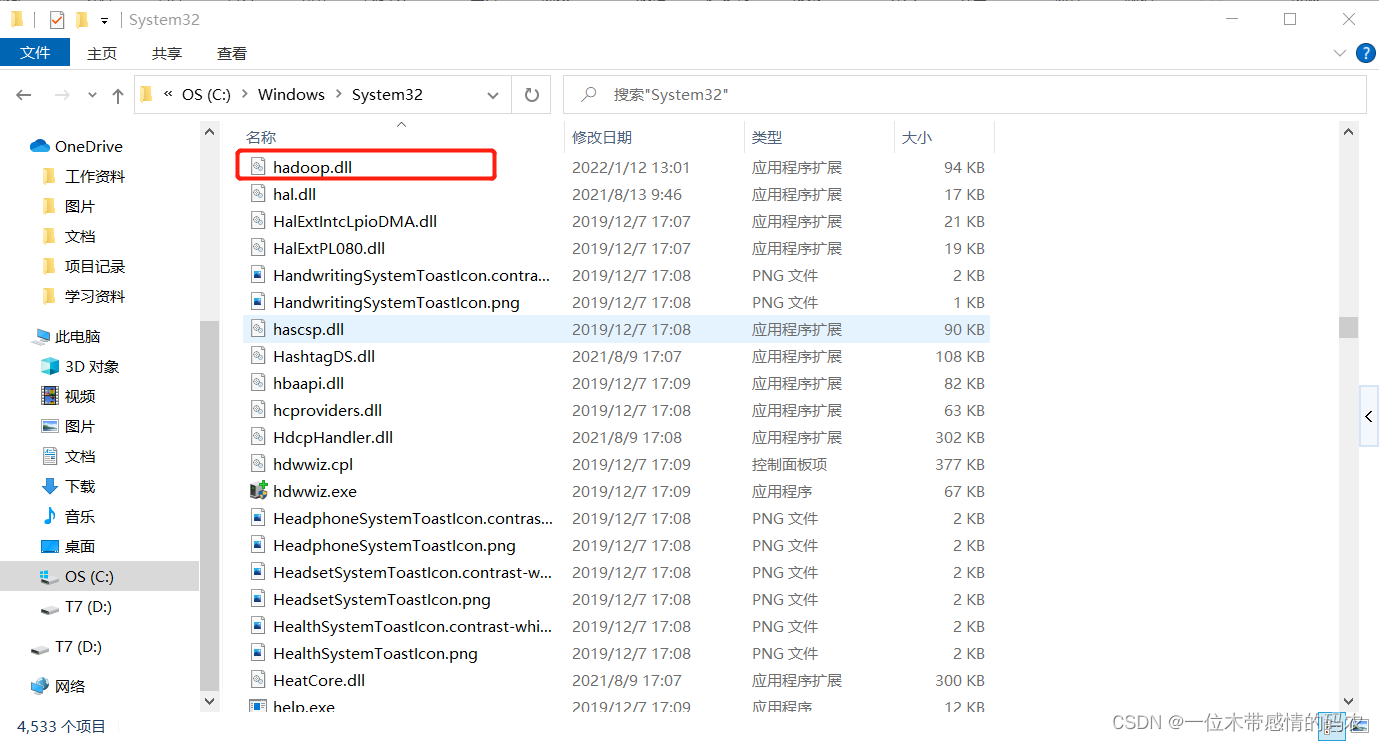
之后重启 IDEA,再次执行程序,就能正常运行了
HDFS 操作详解
1.HDFS概述
1.1 HDFS产生背景及定义
1.1.1 HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
1.1.2 HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。 一个文件经过创建、写入和关闭之后就不需要改变。
HDFS 主要适合去做批量数据出来,相对于数据请求时的反应时间,HDFS 更倾向于保障吞吐量。
1.1.3 HDFS发展史
1.Doug Cutting 在做 Lucene 的时候, 需要编写一个爬虫服务,这个爬虫写的并不顺利,遇到了一些问题, 诸如:如何存储大规模的数据,如何保证集群的可伸缩性,如何动态容错等。
2.2013 年,Google 发布了三篇论文,被称作为三驾马车,其中有一篇叫做 GFS。
3.GFS 是描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统,具有强大的可伸缩性和容错性。
4.Doug Cutting 后来根据 GFS 的论文,创造了一个新的文件系统,叫做 HDFS
1.2 HDFS优缺点
- 优点
- 高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提
高容错性。 - 某一个副本丢失后,它可以自动恢复。
- 数据自动保存多个副本。它通过增加副本的形式,提
适合处理大数据- 数据规模:能够处理数据规模达到GB、TB甚至PB级别的数据。
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
可构建在廉价机器上,通过多副本机制,提高可靠性。
- 高容错性
- 缺点
不适合处理低延时数据访问,比如毫秒级的存储数据,是做不到的。无法高效的对大量小文件进行存储- 存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件目录和块信息。这样是不可取的,因为 NameNode 的内存总是有限的。
- 小文件存储的寻址时间会超过读取时间,它违反了 HDFS 的设计目标。
不支持并发写入、文件随机修改- 一个文件只能有一个写,不允许多个线程同时写。
- 仅支持数据 append,不支持文件的随机修改。
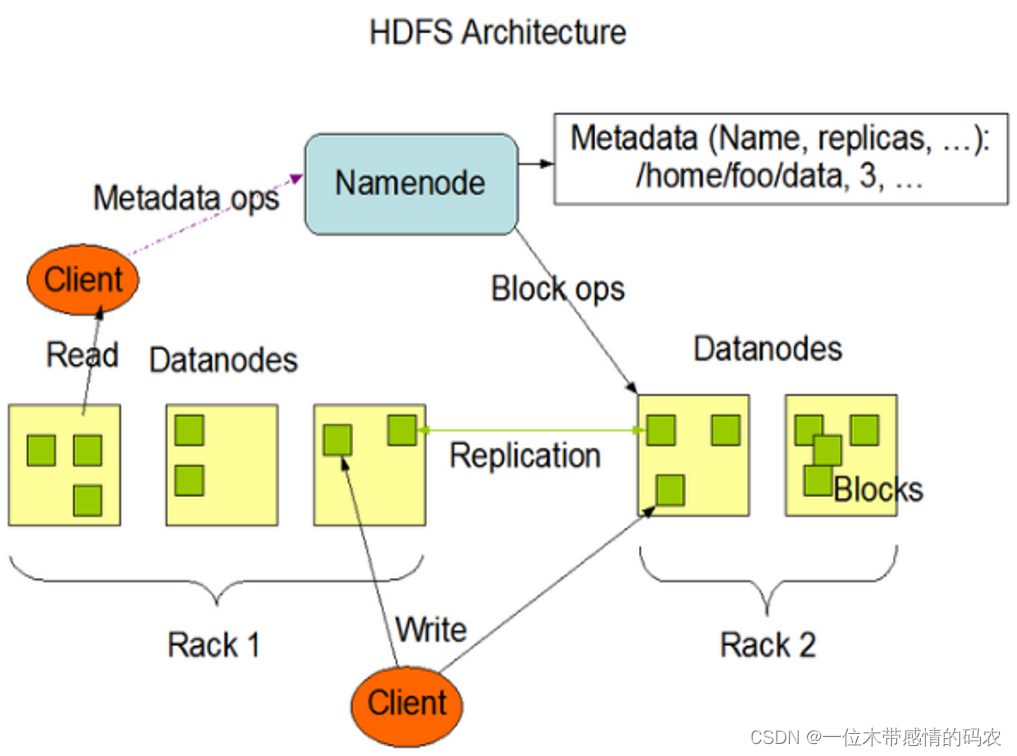
2.HDFS组成架构
NameNode: Master,它是一个主管、管理者。
管理 HDFS 的名称空间;
配置副本策略;
管理数据块(Block)映射信息;
处理客户端读取请求;
DataNode: Slave,NameNode赋值下达命令,DataNode执行实际的操作。
存储实际的数据块;
执行数据块的读/写操作;
Client: 客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行上传;
与 NameNode 交互,获取文件的位置信息;
与 DataNode 交互,读取或者写入数据;
Client 提供一些命令来管理 HDFS,比如对 NameNode 格式化;
Client 可以通过一些命令来访问 HDFS,比如对 HDFS 增删改查操作;
SecondaryNameNode: 并非 NameNode 的热备,当 NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量,比如定期合并 Fsimage 和 Edits,并推送给 NameNode;
在紧急情况下,可辅助恢复 NameNode;
3.HDFS的重要特性
3.1 主从架构
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。

3.2分块机制
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于 hdfs-default.xml 中:dfs.blocksize。默认大小在 Hadoop2.x/3.x 是128M(134217728),1.x 版本中是 64M。
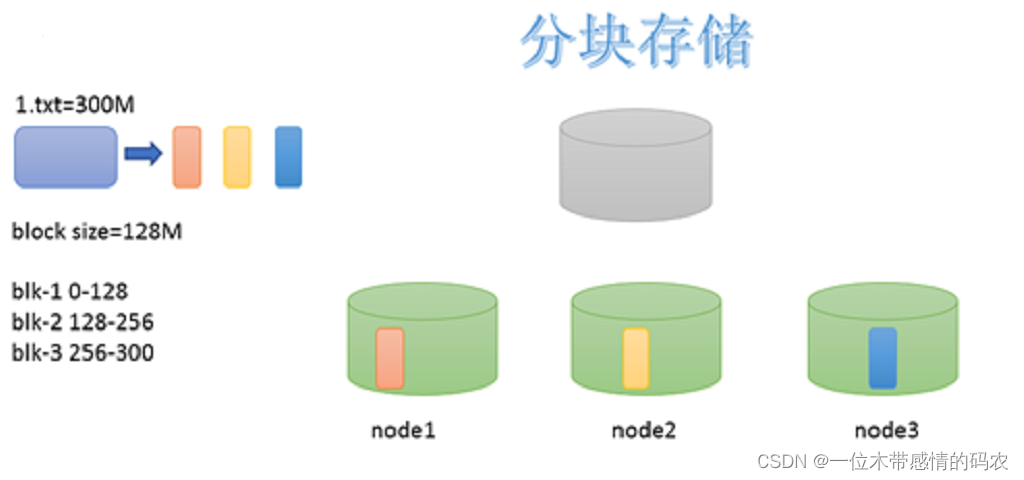
3.2.1 HDFS文件块大小设置
HDFS 的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间,导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
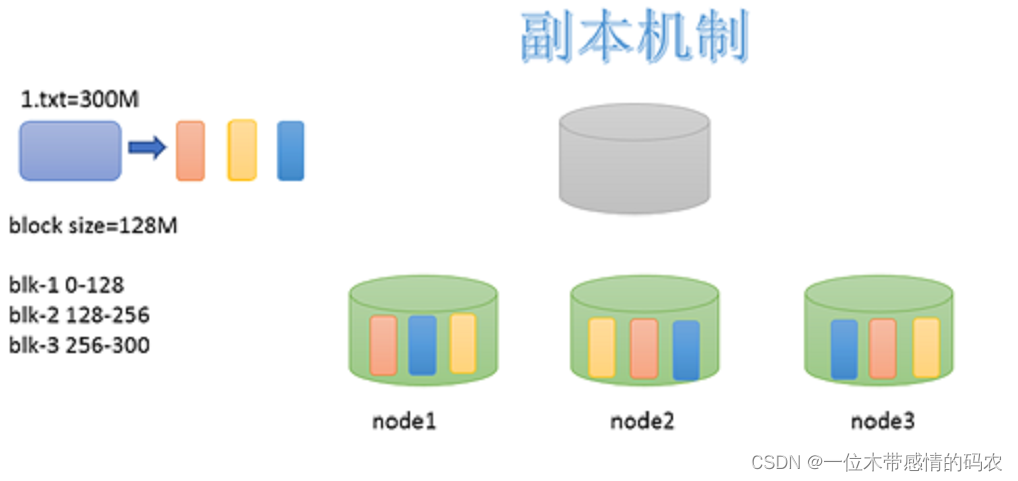
3.3 副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认dfs.replication的值是3,也就是会额外再复制 2 份,连同本身总共 3 份副本。
3.4 Namespace
HDFS 支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的 namespace 名称空间,任何对文件系统名称空间或属性的修改都将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
3.5 元数据管理
在 HDFS 中,Namenode 管理的元数据具有两种类型:
文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
文件块位置映射信息
记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上。
3.6 数据块存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以在多个 DataNode 上存储。
4.HDFS的Shell操作
4.1基本语法
hadoop fs 具体命令 OR hdfs dfs 具体命令
4.2 上传
-moveFromLocal:从本地剪切粘贴到 HDFS
hadoop fs -moveFromLocal ./1.txt /test
-copyFromLocal:从本地文件系统中拷贝文件到 HDFS 路径去
hadoop fs -copyFromLocal ./1.txt /test
-put:等同于 copyFromLocal,生产环境更习惯用 put
hadoop fs -put ./1.txt /test
-appendToFile:追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./1.txt /test/1.txt
4.3下载
-copyToLocal:从 HDFS 拷贝到本地
hadoop fs -copyToLocal /test/1.txt /output
-get:等同于 copyToLocal,生产环境更习惯用 get
hadoop fs -get /test/1.txt /output
4.4 HDFS直接操作
-
-ls:显示目录信息hadoop fs -ls /test -
-cat:显示文件内容hadoop fs -cat /test/1.txt -
-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限hadoop fs -chmod 666 /test/1.txt hadoop fs -chown hadoop:hadoop /test/1.txt -
-mkdir:创建路径hadoop fs -mkdir /test -
-cp:从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
hadoop fs -cp /test1/1.txt /test2
-mv:在 HDFS 目录中移动文件
hadoop fs -mv /test1/1.txt /test2
-tail:显示一个文件的末尾 1kb 的数据
hadoop fs -tail /test/1.txt
-rm:删除文件或文件夹
hadoop fs -rm /test/1.txt
-rm -r:递归删除目录及目录里面内容
hadoop fs -rm -r /test
-du:统计文件夹的大小信息
[hadoop@hadoop1 hadoop-3.3.1]$ hadoop fs -du -s -h /input/1.txt
37 111 /input/1.txt
[hadoop@hadoop1 hadoop-3.3.1]$ hadoop fs -du -h /input
37 111 /input/1.txt
5 15 /input/2.txt
# 37表示文件大小;111表示37*3个副本;/input表示查看的目录
-setrep:设置 HDFS 中文件的副本数量
hadoop fs -setrep 10 /input/1.txt
# 这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
5. HDFS的API操作
5.1 HDFS API介绍
涉及的主要类:
- Configuration: 该类的对象封转了客户端或者服务器的配置。
- FileSystem: 该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过 FileSystem 的静态方法 get 获得该对象。
FileSystem fs = FileSystem.get(conf);
get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类型的文件系统。如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath 下也没有给定相应的配置,conf 中的默认值就来自于 hadoop 的 jar 包中的 core-default.xml,默认值为:file:///,则获取的将不是一个 DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象。
Java API官方文档:https://hadoop.apache.org/docs/r3.3.1/api/index.html
5.2 环境配置
- 安装包解压在英文路径下

配置环境变量


IDEA 新建Maven项目,加入下面的 pom 依赖
<repositories>
<repository>
<id>cental</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!-- Google Options -->
<dependency>
<groupId>com.github.pcj</groupId>
<artifactId>google-options</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.itcast.sentiment_upload.Entrance</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
在resources下新建log4j.properties,加入下面内容
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
再按照[Hadoop3.x报错[main] DEBUG 该博客教程上传文件即可。
5.3 HDFS创建目录
@Test
public void testMkdirs() throws IOException, URISyntaxException, InterruptedException {
Configuration configuration = new Configuration();
// FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration,"hadoop");
// 创建目录
fs.mkdirs(new Path("/hdfsapi"));
// 关闭资源
fs.close();
}
5.4 HDFS文件上传
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 获取文件系统
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration, "hadoop");
// 上传文件
fs.copyFromLocalFile(new Path("D:/test.txt"), new Path("/input"));
// 关闭资源
fs.close();
}
5.5 HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration, "hadoop");
// 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/input/1.txt"), new Path("D:/1.txt"), true);
// 关闭资源
fs.close();
}
5.6 HDFS文件更名和移动
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{
// 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration, "hadoop");
// 修改文件名称
fs.rename(new Path("/input/test.txt"), new Path("/input/test1.txt"));
// 关闭资源
fs.close();
}
5.7 HDFS删除文件和目录
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration, "hadoop");
// 执行删除
fs.delete(new Path("/output"), true);
// 关闭资源
fs.close();
}
5.8 HDFS文件详情查看
查看文件名称、权限、长度、块信息。
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException {
// 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration, "hadoop");
// 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 关闭资源
fs.close();
}
5.9 HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 获取文件配置信息
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.68.101:8020"), configuration, "hadoop");
// 判断是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/input"));
for (FileStatus fileStatus : listStatus) {
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 关闭资源
fs.close();
}
HDFS REST HTTP API
见Hadoop生态圈(三)- HDFS REST HTTP API_hdfs rest api-CSDN博客
Hadoop3.3.1编译安装部署教程
见Hadoop 3.1.1 分布式搭建文档
HDFS数据存储与数据管理
1. Hadoop常用文件存储格式
1.1 传统系统常见文件存储格式
在 Windows 有很多种文件格式,例如:JPEG 文件用来存储图片、MP3 文件用来存储音乐、DOC 文件用来存储 WORD 文档。每一种文件存储某一类的数据,例如:我们不会用文本来存储音乐、不会用文本来存储图片。Windows 上支持的存储格式是非常的多。
1.1.1 文件系统块大小
- 在服务器/电脑上,有多种块设备(Block Device),例如:硬盘、CDROM、软盘等等。
- 每个文件系统都需要将一个分区拆分为多个块,用来存储文件。不同的文件系统块大小不同。

例如:我们看到该文件系统的块大小为:4096字节 = 4KB。如果我们需要在磁盘中存储 5 个字节的数据,也会占据 4096 字节的空间。
1.2 Hadoop中文件存储格式
Hadoop 上的文件存储格式,肯定不会像 Windows 这么丰富,因为目前我们用 Hadoop 来存储、处理数据。我们不会用 Hadoop 来听歌、看电影、或者打游戏。
- 文件格式是定义数据文件系统中存储的一种方式,可以在文件中存储各种数据结构,特别是 Row、Map,数组以及字符串,数字等。
- 在 Hadoop 中,没有默认的文件格式,格式的选择取决于其用途。而选择一种优秀、适合的数据存储格式是非常重要的。
- 后续我们要讲的,使用 HDFS 的应用程序(例如 MapReduce 或 Spark、Flink)性能中的最大问题、瓶颈是在特定位置查找数据的时间和写入到另一个位置的时间,而且管理大量数据的处理和存储也很复杂(例如:数据的格式会不断变化,原来一行有 12 列,后面要存储 20 列)。
- Hadoop 文件格式发展了好一段时间,这些文件存储格式可以解决大部分问题。我们在开发大数据中,选择合适的文件格式可能会带来一些明显的好处:
- 可以保证写入的速度
- 可以保证读取的速度
- 文件是可被切分的
- 对压缩支持友好
- 支持schema的更改
- 某些文件格式是为通用设计的(如 MapReduce 或 Spark、Flink),而其他文件则是针对更特定的场景,有些在设计时考虑了特定的数据特征。因此,确实有很多选择。
1.3 BigData File Viewer工具
1.3.1 介绍
- 一个跨平台(Windows,MAC,Linux)桌面应用程序,用于查看常见的大数据二进制格式,例如 Parquet,ORC,AVRO 等。支持本地文件系统,HDFS,AWS S3 等。
**GitHub地址:**https://github.com/Eugene-Mark/bigdata-file-viewer
1.3.2 功能
- 打开并查看本地目录中的Parquet,ORC和AVRO,HDFS,AWS S3等。
- 将二进制格式的数据转换为文本格式的数据,例如CSV
- 支持复杂的数据类型,例如数组,映射,结构等
- 支持Windows,MAC和Linux等多种平台
- 代码可扩展以涉及其他数据格式
1.4 Hadoop丰富的存储格式
1.4.1 Text File
1.4.1.1 简介
- 文本文件在非 Hadoop 领域很常见,在 Hadoop 领域也很常见。
- 数据一行一行到排列,每一行都是一条记录。以典型的 UNIX 方式以换行符
\n终止。 - 文本文件是可以被切分的,但如果对文本文件进行压缩,则必须使用支持切分文件的压缩编解码器,例如 BZIP2。因为这些文件只是文本文件,压缩时会对所有内容进行编码。
- 可以将每一行成为 JSON 文档,可以让数据带有结构。
1.4.1.2 应用场景
仅在需要从 Hadoop 中直接提取数据,或直接从文件中加载大量数据的情况下,才建议使用纯文本格式或 CSV。
1.4.1.3 优缺点
- 优点
- 简单易读、轻量级
- 缺点
- 读写速度慢。
- 不支持块压缩,在 Hadoop 中对文本文件进行压缩/解压缩会有较高的读取成本,因为需要将整个文件全部压缩或者解压缩。
- 无法切分压缩文件(会导致较大的 map task)。
1.4.2 Sequence File
1.4.2.1 简介
- Sequence 最初是为 MapReduce 设计的,因此和 MapReduce 集成很好。
- 在 Sequence File 中,每个数据都是以一个 key 和一个 value 进行序列化存储,仅此而已。
- Sequence File 中的数据是以二进制格式存储,这种格式所需的存储空间小于文本的格式。与文本文件一样,Sequence File 内部也不支持对键和值的结构指定格式编码。
1.4.2.2 应用场景
通常把 Sequence file 作为中间数据存储格式。例如:将大量小文件合并放入到一个 SequenceFIle 中

1.4.2.3 结构


1.4.2.4 优缺点
- 优点
- 与文本文件相比更紧凑,支持块级压缩。
- 压缩文件内容的同时,支持将文件切分。
- 序列文件在 Hadoop 和许多其他支持 HDFS 的项目支持很好,例如:Spark。
- 它是让我们摆脱文本文件迈出第一步。
- 它可以作为大量小文件的容器。
- 与文本文件相比更紧凑,支持块级压缩。
- 缺点
- 对于具有 SQL 类型的 Hive 支持不好,需要读取和解压缩所有字段。
- 不存储元数据,并且对 schema 扩展中的唯一方式是在末尾添加新字段。
1.4.3 Avro File
1.4.3.1 简介
- Apache Avro 是与语言无关的序列化系统,由 Hadoop 创始人 Doug Cutting开发
- Avro 是基于行的存储格式,它在每个文件中都包含 JSON 格式的 schema 定义,从而提高了互操作性并允许 schema 的变化(删除列、添加列)。 除了支持可切分以外,还此次块压缩。
- Avro 是一种自描述格式,它将数据的 schema 直接编码存储在文件中,可以用来存储复杂结构的数据。
- Avro 可以进行快速序列化,生成的序列化数据也比较小。
1.4.3.2 应用场景
- 适合于一次性需要将大量的列(数据比较宽)、写入频繁的场景
- 随着更多存储格式的发展,常用于 Kafka 和 Druid 中
1.4.3.3 结构
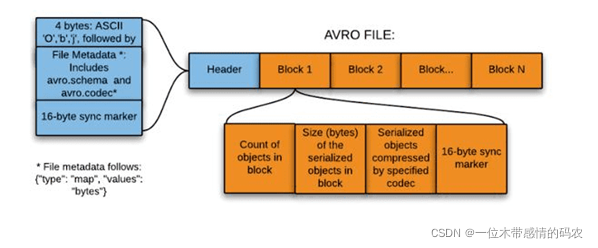
直接将一行数据序列化在一个block中
1.4.3.4 优缺点
- 优点
- Avro 是与语言无关的数据序列化系统。
- Avro 将 schema 存储在 header 中,数据是自描述的。
- 序列化和反序列化速度很快。
- Avro 文件是可切分的、可压缩的,非常适合在 Hadoop 生态系统中进行数据存储。
- 缺点
- 如果我们只需要对数据文件中的少数列进行操作,行式存储效率较低。例如:我们读取 15 列中的 2 列数据,基于行式存储就需要读取数百万行的 15 列。而列式存储就会比行式存储方式高效
- 列式存储因为是将同一列(类)的数据存储在一起,压缩率要比方式存储高
1.4.4 RCFile
1.4.4.1 简介
- RCFile 是为基于 MapReduce 的数据仓库系统设计的数据存储结构。它结合了行存储和列存储的优点,可以满足快速数据加载和查询,有效利用存储空间以及适应高负载的需求。
- RCFile 是由二进制键/值对组成的flat文件,它与 sequence file 有很多相似之处。
- 在数仓中执行分析时,这种面向列的存储非常有用。当我们使用面向列的存储类型时,执行分析很容易。
注: 无法将数据直接加载到 RCFile 中。首先需要将数据加载到另一个表中,然后将其覆盖写入到新创建的 RCFile 中。
1.4.4.2 应用场景
- 常用在Hive中
1.4.4.3 结构

- RCFile 可将数据分为几组行,并且在其中将数据存储在列中。
- RCFile 首先将行水平划分为行拆分(Row Group),然后以列方式垂直划分每个行拆分(Columns)。
- RCFile 将行拆分的元数据存储为 record 的 key,并将行拆分的所有数据存储 value。
- 作为行存储,RCFile 保证同一行中的数据位于同一节点中。
- 作为列存储,RCFile 可以利用列数据压缩,并跳过不必要的列读取。
1.4.4.4 优缺点
- 优点
- 基于列式的存储,更好的压缩比。
- 利用元数据存储来支持数据类型。
- 支持 Split。
- 缺点
- RC 不支持 schema 扩展,如果要添加新的列,则必须重写文件,这会降低操作效率。
1.4.5 ORC File
1.4.5.1 简介
- Apache ORC(Optimized Row Columnar,优化行列)是 Apache Hadoop 生态系统面向列的开源数据存储格式,它与 Hadoop 环境中的大多数计算框架兼容。
- ORC 代表“优化行列”,它以比 RC 更为优化的方式存储数据,提供了一种非常有效的方式来存储关系数据,然后存储 RC 文件。
- ORC 将原始数据的大小最多减少 75%,数据处理的速度也提高了。
1.4.5.2 应用场景
- 常用在 Hive 中
1.4.5.3 结构

1.4.5.4 优缺点
- 优点
- 比 TextFile,Sequence File 和 RC File 具备更好的的性能。
- 列数据单独存储。
- 带类型的数据存储格式,使用类型专用的编码器。
- 轻量级索引。
- 缺点
- 与 RC 文件一样,ORC 也是不支持列扩展的。
1.4.6 Parquet File
1.4.6.1 简介
- Parquet File 是另一种列式存储的结构,来自于 Hadoop 的创始人 Doug Cutting 的 Trevni 项目。
- 和 ORCFile 一样,Parquet 也是基于列的二进制存储格式,可以存储嵌套的数据结构。
- 当指定要使用列进行操作时,磁盘输入/输出操效率很高。
- Parquet 与 Cloudera Impala 兼容很好,并做了大量优化。
- 支持块压缩。
- 与 RC 和 ORC 文件不同,Parquet serdes 支持有限的 schema 扩展。在 Parquet 中,可以在结构的末尾添加新列。
关于 Hive 对 Parquet 文件的支持的一个注意事项: Parquet 列名必须小写,这一点非常重要。如果 Parquet 文件包含大小写混合的列名,则 Hive 将无法读取该列。
1.4.6.2 结构
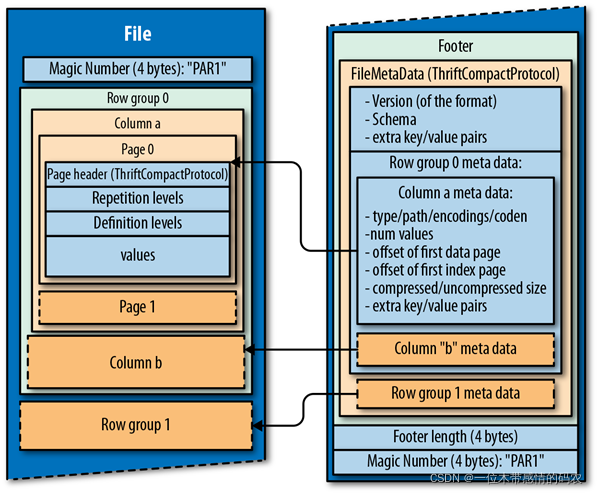
1.4.6.3 优缺点
- 优点
- 和 ORC 文件一样,它非常适合进行压缩,具有出色的查询性能,尤其是从特定列查询数据时,效率很高
- 缺点
- 与 RC 和 ORC 一样,Parquet 也具有压缩和查询性能方面的优点,与非列文件格式相比,写入速度通常较慢。
1.5 Parquet VS ORC

- ORC 文件格式压缩比 parquet 要高,parquet 文件的数据格式 schema 要比 ORC 复杂,占用的空间也就越高。
- ORC 文件格式的读取效率要比 parquet 文件格式高。
- 如果数据中有嵌套结构的数据,则 Parquet 会更好。
- Hive 对 ORC 的支持更好,对 parquet 支持不好,ORC 与 Hive 关联紧密。
- ORC 还可以支持 ACID、Update 操作等。
- Spark 对 parquet 支持较好,对 ORC 支持不好。
- 为了数据能够兼容更多的查询引擎,Parquet 也是一种较好的选择。
1.6 ProtoBuf和Thrift
由于 Protobuf 和 Thrift 是不可 split 的,因此它们在 HDFS 中并不流行。
1.7 扩展:Apache Arrow
1.7.1 Arrow简介
- Apache Arrow 是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。Apache Arrow 在 2016 年 2 月 17 日作为顶级 Apache 项目引入。
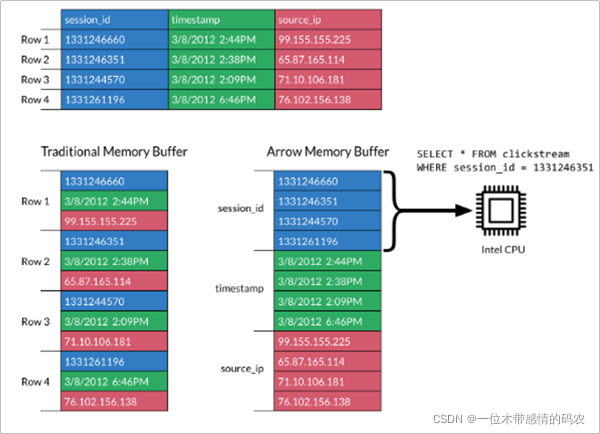
- Apache Arrow 发展非常迅速,并且在未来会有更好的发展空间。 它可以在系统之间进行高效且快速的数据交换,而无需进行序列化,而这些成本已与其他系统(例如 Thrift,Avro 和 Protocol Buffers)相关联。
- 每一个系统实现,它的方法(method)都有自己的内存存储格式,在开发中,70%-80%的时间浪费在了序列化和反序列化上。
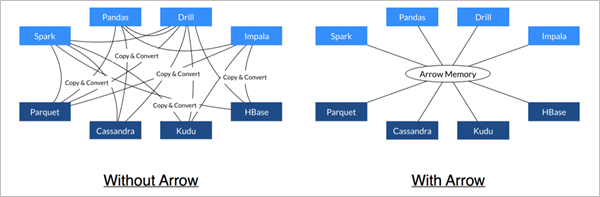
- Arrow 促进了许多组件之间的通信。 例如,使用Python(pandas)读取复杂的文件并将其转换为Spark DataFrame。

1.7.2 Arrow是如何提升数据移动性能的
- 利用 Arrow 作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。 例如,Spark 可以使用 Python 进程发送 Arrow 数据来执行用户定义的函数。
- 无需进行反序列化,可以直接从启用了 Arrow 的数据存储系统中接收 Arrow 数据。 例如,Kudu 可以将 Arrow 数据直接发送到 Impala 进行分析。
- Arrow 的设计针对嵌套结构化数据(例如在 Impala 或 Spark Data 框架中)的分析性能进行了优化。
2. 文件压缩格式
在 Hadoop 中,一般存储着非常大的文件,以及在存储 HDFS 块或运行 MapReduce 任务时,Hadoop 集群中节点之间的存在大量数据传输。 如果条件允许时,尽量减少文件大小,这将有助于减少存储需求以及减少网络上的数据传输。
2.1 Hadoop支持的压缩算法
Haodop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口,所有的实现类都在org.apache.hadoop.io.compress包下。

2.1.1 压缩算法比较
有不少的压缩算法可以应用到 Hadoop 中,但不同压缩算法有各自的特点。
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码/解码器 |
|---|---|---|---|---|---|
| DEFAULT | 无 | DEFAULT | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | gzip | DEFAULT | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | 是(索引) | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
存放数据到 HDFS 中,可以选择指定的压缩方式,在 MapReduce 程序读取时,会根据扩展名自动解压。例如:如果文件扩展名为.snappy,Hadoop 框架将自动使用 SnappyCodec 解压缩文件。

通过上图,我们可以看到哪些压缩算法压缩比更高。整体排序如下:
Snappy < LZ4 < LZO < GZIP < BZIP2,但压缩比越高,压缩的时间也会更长。以下是部分参考数据:
| 压缩算法 | 压缩后占比 | 压缩 | 解压缩 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
2.2 HDFS压缩如何抉择
既然压缩能够节省空间、而且可以提升 IO 效率,那么能否将所有数据都以压缩格式存储在 HDFS 中呢?例如:bzip2,而且文件是支持切分的。

如果选择 GZIP,就会出现以下情况:

- 如果文件是不可切分的,只有一个 CPU 在处理所有的文件,其他的 CPU 都是空闲的。如果 HDFS 中的 block 和文件大小差不多还好,一个文件、一个块、一个 CPU。如果是一个很大的文件就会出现问题了。
- bzip2 在压缩和解压缩数据方面实际上平均比 Gzip 差 3 倍,这对性能是有一定的影响的。如果我们需要频繁地查询数据,数据压缩一定会影响查询效率。
- 如果不关心查询性能(没有任何 SLA)并且很少选择此数据,则 bzip2 可能是不错的选择。最好是对自己的数据进行基准测试,然后再做决定。
3. HDFS存储类型和存储策略
3.1 介绍
- Archive 存储(档案存储)是一种将增长的存储容量与计算容量解耦的解决方案。
- 可以将一些需要存储、但计算需求很少的数据放在低成本的存储节点中,这些节点用于集群中冷数据的存储。
- 根据策略,热数据可以转移到冷节点存储。在冷区域中加入更多的节点可以使存储与集群中的计算容量无关。
- 异构存储和归档存储提供的框架将 HDFS 体系结构概括为包括其他类型的存储介质,包括:SSD 和内存。用户可以选择将数据存储在 SSD 或内存中以获得更好的性能。

3.2 存储类型和存储策略
3.2.1 多种多样的存储类型
大家考虑一个问题:我们可以将数据保存在什么样的存储类型中呢?
- 硬盘
- SSD
- SATA
- 内存
- NAS
3.2.2 速率对比
RAM 比 SSD 快几个数量级。普通的磁盘大致的速度为 30-150MB,比较快的 SSD 可以实现 500MB/秒 的实际写入速度。 RAM 的理论上最大速度可以达到 SSD 实际性能的 30 倍。
以下是一个实际对比图:

3.2.3 存储类型
之前在hdfs-site.xml中配置,是将数据保存在 Linux 中的本地磁盘。
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop-3.3.1/data/datanode</value>
</property>
以上配置跟下面的配置是一样的:
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]:/data/hadoop-3.3.1/data/datanode</value>
</property>
在 HDFS 中,可以给不同的存储介质分配不同的存储类型:
- DISK:默认的存储类型,磁盘存储。
- ARCHIVE:具有存储密度高(PB级),但计算能力小的特点,可用于支持档案存储。
- SSD:固态硬盘。
- RAM_DISK:DataNode 中的内存空间。
3.2.4 存储策略介绍
HDFS 中提供热、暖、冷、ALL_SSD、One_SSD、Lazy_Persistence 等存储策略。为了根据不同的存储策略将文件存储在不同的存储类型中,引入了一种新的存储策略概念。HDFS 支持以下存储策略:
- 热(hot)
- 用于大量存储和计算。
- 当数据经常被使用,将保留在此策略中。
- 当 block 是 hot 时,所有副本都存储在磁盘中。
- 冷(cold)
- 仅仅用于存储,只有非常有限的一部分数据用于计算。
- 不再使用的数据或需要存档的数据将从热存储转移到冷存储中。
- 当 block 是 cold 时,所有副本都存储在 Archive 中。
- 温(warm)
- 部分热,部分冷。
- 当一个块是 warm 时,它的一些副本存储在磁盘中,其余的副本存储在 Archive 中。
- 全SSD
- 将所有副本存储在 SSD 中。
- 单SSD
- 在 SSD 中存储一个副本,其余的副本存储在磁盘中。
- 懒持久
- 用于编写内存中只有一个副本的块。副本首先写在 RAM_Disk 中,然后惰性地保存在磁盘中。
3.2.5 HDFS中的存储策略
HDFS存储策略由以下字段组成:
- 策略 ID(Policy ID)
- 策略名称(Policy Name)
- 块放置的存储类型列表(Block Placement)
- 用于创建文件的后备存储类型列表(Fallback storages for creation)
- 用于副本的后备存储类型列表(Fallback storages for replication)
当有足够的空间时,块副本将根据 #3 中指定的存储类型列表存储。当列表 #3 中的某些存储类型耗尽时,将分别使用 #4 和 #5 中指定的后备存储类型列表来替换空间外存储类型,以便进行文件创建和副本。
以下是一个典型的存储策略表格:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | - | ARCHIVE |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | - | - |
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
注意事项:
- Lazy_Persistence 策略仅对单个副本块有用。对于具有多个副本的块,所有副本都将被写入磁盘,因为只将一个副本写入 RAM_Disk 并不能提高总体性能。
- 对于带条带的擦除编码文件,合适的存储策略是 ALL_SSD、HOST、CORD。因此,如果用户为 EC 文件设置除上述之外的策略,在创建或移动块时不会遵循该策略。
3.2.6 存储策略方案
- 创建文件或目录时,其存储策略为未指定状态。可以使用:
storagepolicies -setStoragePolicy命令指定 - 文件或目录的有效存储策略由以下规则解析:
- 如果使用存储策略指定了文件或目录,则返回该文件或目录。
- 对于未指定的文件或目录,如果是根目录,则返回默认存储策略。否则,返回其父级的有效存储策略
- 可以使用 storagepolicies –getStoragePolicy 命令获取有效的存储策略。
3.2.7 配置
-
dfs.storage.policy.enabled- 启用/禁用存储策略功能。默认值是 true
-
dfs.datanode.data.dir -
在每个数据节点上,应当用逗号分隔的存储位置标记它们的存储类型。这允许存储策略根据策略将块放置在不同的存储类型上。
注意:
- 磁盘上的 DataNode 存储位置
/grid/dn/disk0应该配置为[DISK]file:///grid/dn/disk0 - SSD 上的 DataNode 存储位置
/grid/dn/ssd0应该配置为[SSD]file:///grid/dn/ssd0 - 存档上的 DataNode 存储位置
/grid/dn/Archive0应该配置为[ARCHIVE]file:///grid/dn/archive0 - 将 RAM_磁盘上的 DataNode 存储位置
/grid/dn/ram0配置为[RAM_DISK]file:///grid/dn/ram0 - 如果 DataNode 存储位置没有显式标记存储类型,它的默认存储类型将是磁盘。
3.3 存储策略命令
3.3.1 列出存储策略
列出所有存储策略命令:
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
123456789
3.3.2 设置存储策略
为一个文件或目录设置存储策略:
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
1
| 参数名 | 说明 |
|---|---|
| -path | 引用目录或文件的路径 |
| -policy | 存储策略的名称 |
3.3.3 取消存储策略
取消文件或目录的存储策略。在执行 unset 命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略。
hdfs storagepolicies -unsetStoragePolicy -path <path>
| 参数名 | 说明 |
|---|---|
| -path | 引用目录或文件的路径 |
3.3.4 获取存储策略
获取文件或目录的存储策略:
hdfs storagepolicies -getStoragePolicy -path <path>
| 参数名 | 说明 |
|---|---|
| -path | 引用目录或文件的路径 |
3.4 冷热温三阶段数据存储
为了更加充分的利用存储资源,我们可以将数据分为冷、热、温三个阶段来存储。
| /data/hdfs-test/data_phase/hot | 热阶段数据 |
|---|---|
| /data/hdfs-test/data_phase/warm | 温阶段数据 |
| /data/hdfs-test/data_phase/cold | 冷阶段数据 |
3.4.1 配置DataNode存储目录
为了能够支撑不同类型的数据,我们需要在 hdfs-site.xml 中配置不同存储类型数据的位置。
- 进入到 Hadoop 配置目录,编辑
hdfs-site.xml
<!-- DataNode存储名称空间和事务日志的本地文件系统上的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///data/hadoop-3.3.1/data/datanode,[ARCHIVE]file:///data/hadoop-3.3.1/data/archive</value>
<description></description>
</property>
- 分发到另外两个节点
scp hdfs-site.xml 192.168.68.102:$PWD
scp hdfs-site.xml 192.168.68.103:$PWD
- 重启 HDFS 集群
配置好后,我们在 WebUI 的 Datanodes 页面中点击任意一个 DataNode 节点:

可以看到,现在配置的是两个目录,一个 StorageType 为 ARCHIVE、一个 StorageType 为 DISK。

3.4.2 配置策略
- 创建测试目录结构
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/cold
123
- 查看当前 HDFS 支持的存储策略
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
- 分别设置三个目录的存储策略
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/cold -policy COLD
- 查看三个目录的存储策略
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
The storage policy of /data/hdfs-test/data_phase/hot:
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
The storage policy of /data/hdfs-test/data_phase/warm:
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold
The storage policy of /data/hdfs-test/data_phase/cold:
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
3.4.3 上传测试
- 分别上传文件到三个目录中测试
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/cold
- 查看不同存储策略文件的 block 位置
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
Connecting to namenode via http://192.168.68.101:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fhot%2Fprofile
FSCK started by hadoop (auth:SIMPLE) from /192.168.68.101 for path /data/hdfs-test/data_phase/hot/profile at Thu Jan 13 14:50:08 CST 2022
/data/hdfs-test/data_phase/hot/profile 1942 bytes, replicated: replication=3, 1 block(s): OK
3. BP-1344315299-192.168.68.101-1641871518751:blk_1073741967_1143 len=1942 Live_repl=3 [DatanodeInfoWithStorage[192.168.68.103:9866,DS-ba9340ea-d242-4cea-b005-74b64e34ac39,DISK], DatanodeInfoWithStorage[192.168.68.101:9866,DS-e9f568d7-2eac-43b7-aed0-683514a8c41c,DISK], DatanodeInfoWithStorage[192.168.68.102:9866,DS-f23db2c4-f076-49e0-a721-c4c0aff89e8d,DISK]]
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs fsck /data/hdfs-test/data_phase/warm/profile -files -blocks -locations
Connecting to namenode via http://192.168.68.101:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fwarm%2Fprofile
FSCK started by hadoop (auth:SIMPLE) from /192.168.68.101 for path /data/hdfs-test/data_phase/warm/profile at Thu Jan 13 14:52:18 CST 2022
/data/hdfs-test/data_phase/warm/profile 1942 bytes, replicated: replication=3, 1 block(s): OK
0. BP-1344315299-192.168.68.101-1641871518751:blk_1073741968_1144 len=1942 Live_repl=3 [DatanodeInfoWithStorage[192.168.68.103:9866,DS-c54b6721-9962-4f13-a472-bca18c495dd0,ARCHIVE], DatanodeInfoWithStorage[192.168.68.102:9866,DS-1e50ee7c-eca0-49a4-b453-e9890759f328,ARCHIVE], DatanodeInfoWithStorage[192.168.68.101:9866,DS-e9f568d7-2eac-43b7-aed0-683514a8c41c,DISK]]
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs fsck /data/hdfs-test/data_phase/cold/profile -files -blocks -locations
Connecting to namenode via http://192.168.68.101:9870/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fcold%2Fprofile
FSCK started by hadoop (auth:SIMPLE) from /192.168.68.101 for path /data/hdfs-test/data_phase/cold/profile at Thu Jan 13 14:53:05 CST 2022
/data/hdfs-test/data_phase/cold/profile 1942 bytes, replicated: replication=3, 1 block(s): OK
0. BP-1344315299-192.168.68.101-1641871518751:blk_1073741969_1145 len=1942 Live_repl=3 [DatanodeInfoWithStorage[192.168.68.102:9866,DS-1e50ee7c-eca0-49a4-b453-e9890759f328,ARCHIVE], DatanodeInfoWithStorage[192.168.68.103:9866,DS-c54b6721-9962-4f13-a472-bca18c495dd0,ARCHIVE], DatanodeInfoWithStorage[192.168.68.101:9866,DS-0f356fed-83d9-4dc9-9f3e-ac52ce649236,ARCHIVE]]
可以看到:
- hot目录中的block,3个block都在DISK磁盘
- warm目录中的block,1个block在DISK磁盘,另外两个在archive磁盘
- cold目录中的block,3个block都在archive磁盘
3.5 HDFS中的内存存储支持
3.5.1 介绍
- HDFS 支持写入由 DataNode 管理的堆外内存
- DataNode 异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘 IO 操作,这种写入称之为懒持久写入。
- HDFS 为懒持久化写做了较大的持久性保证。在将副本保存到磁盘之前,如果节点重新启动,有非常小的几率会出现数据丢失。应用程序可以选择使用懒持久化写,以减少写入延迟。
该特性从 Apache Hadoop 2.6.0 开始支持。

- 比较适用于,当应用程序需要往 HDFS 中以低延迟的方式写入相对较低数据量(从几GB到十几GB,取决于可用内存)的数据时。
- 内存存储适用于在集群内运行,且运行的客户端与 HDFS DataNode 处于同一节点的应用程序。使用内存存储可以减少网络传输的开销。
- 如果内存不足或未配置,使用懒持久化写入的应用程序将继续工作,会继续使用磁盘存储。
3.5.2 配置内存存储支持
3.5.2.1 设置能够使用的内存空间
确定用于存储在内存中的副本内存量
- 在指定 DataNode 的 hdfs-site.xml 设置 dfs.datanode.max.locked.memory
- DataNode 将确保懒持久化的内存不超过 dfs.datanode.max.locked.memory
- 例如,为内存中的副本预留 32 GB
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>34359738368</value>
</property>
在设置此值时,请记住,还需要内存中的空间来处理其他事情,例如数据节点和应用程序 JVM 堆以及操作系统页缓存。如果在与数据节点相同的节点上运行 YARN 节点管理器进程,则还需要 YARN 容器的内存。
3.5.2.2 DataNode设置基于内存的存储
- 在每个 DataNode 节点上初始化一个 RAM 磁盘
- 通过选择 RAM 磁盘,可以在 DataNode 进程重新启动时保持更好的数据持久性
下面的设置可以在大多数 Linux 发行版上运行,目前不支持在其他平台上使用 RAM 磁盘。
3.5.3 选择tmpfs(VS ramfs)
- Linux 支持使用两种类型的 RAM 磁盘:tmpfs 和 ramfs
- tmpfs 的大小受 linux 内核的限制,而 ramfs 可以使用所有系统可用的内存
- tmpfs 可以在内存不足情况下交换到磁盘上。但是,许多对性能要求很高的应用运行时都禁用内存磁盘交换
- HDFS 当前支持 tmpfs 分区,而对 ramfs 的支持正在开发中
3.5.4 挂载RAM磁盘
- 使用 Linux 中的 mount 命令来挂载内存磁盘。例如:挂载32GB的tmpfs分区在 /mnt/dn-tmpfs
sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/ - 建议在
/etc/fstab创建一个入口,在 DataNode 节点重新启动时,将自动重新创建 RAM 磁盘 - 另一个可选项是使用
/dev/shm下面的子目录。这是 tmpfs 默认在大多数 Linux 发行版上都可以安装 - 确保挂载的大小大于或等于
dfs.datanode.max.locked.memory,或者写入到/etc /fstab - 不建议使用多个 tmpfs 对懒持久化写入的每个 DataNode 节点进行分区
3.5.5 设置RAM_DISK存储类型tmpfs标签
- 标记 tmpfs 目录中具有 RAM_磁盘存储类型的目录
- 在
hdfs-site.xml中配置dfs.datanode.data.dir。例如,在具有三个硬盘卷的 DataNode 上,/grid/0,/grid/1以及/grid/2和一个 tmpfs 挂载在/mnt/dn-tmpfs,dfs.datanode.data.dir必须设置如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>
- 这一步至关重要。如果没有 RAM_DISK 标记,HDFS 将把 tmpfs 卷作为非易失性存储,数据将不会保存到持久存储,重新启动节点时将丢失数据
3.5.6 确保启用存储策略
确保全局设置中的存储策略是已启用的。默认情况下,此设置是打开的。
3.5.7 使用懒持久化存储策略
- 指定 HDFS 使用 LAZY_PERSIST 策略,可以对文件使用懒持久化写入
可以通过以下三种方式之一进行设置:
3.5.7.1 在目录上执行hdfs storagepolicies命令
- 在目录上设置㽾策略,将使其对目录中的所有新文件生效
- 这个 HDFS 存储策略命令可以用于设置策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
3.5.7.2 在目录上执行setStoragePolicy方法
Apache Hadoop 2.8.0 后,应用程序可以通过编程方式将存储策略设置FileSystem.setStoragePolicy。
fs.setStoragePolicy(path, "LAZY_PERSIST");
3.5.7.3 创建文件的时候指定CreateFlag
当创建文件时,应用程序调用FileSystem.create方法,传递CreateFlag#LAZY_PERSIST实现。
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);
HDFS数据迁移解决方案
1. HDFS数据迁移解决方案
数据迁移指的是一种大规模量级的数据转移,转移的过程中往往会跨机房、跨集群 ,数据迁移规模的不同会导致整个数据迁移的周期也不尽相同 。
在 HDFS 中,同样有许多需要数据迁移的场景,比如冷热数据集群之间的数据转化, 或者 HDFS 数据的双机房备份等等 。因为涉及跨机房 、跨集群,所以数据迁移不会是一个简单的操作。
1.1 数据迁移使用场景
- 冷热集群数据同步、分类存储
- 集群数据整体搬迁
- 当公司的业务迅速的发展,导致当前的服务器数量资源出现临时紧张的时候,为了更高效的利用资源,会将原 A 机房数据整体迁移到 B 机房的,原因可能是 B 机房机器多,而且 B 机房本身开销较 A 机房成本低些等;
- 数据的准实时同步
- 数据准实时同步的目的在于数据的双备份可用,比如某天 A 集群突然宣告不允许再使用了,此时可以将线上使用集群直接切向 B 的同步集群,因为 B 集群实时同步 A 集群数据,拥有完全一致的真实数据和元数据信息,所以对于业务方使用而言是不会受到任何影响的。
1.2 数据迁移要素考量
- Bandwidth——带宽
- 带宽用的多了,会影响到线上业务的任务运行,带宽用的少了又会导致数据同步过慢的问题。
- Performance——性能
- 是采用简单的单机程序?还是多线程的性能更佳的分布式程序?
- Data-Increment——增量同步
- 当 TB,PB 级别的数据需要同步的时候,如果每次以全量的方式去同步数据,结果一定是非常糟糕。如果仅针对变化的增量数据进行同步将会是不错的选择。可以配合 HDFS 快照等技术实现增量数据同步。
- Syncable——数据迁移的同步性
- 数据迁移的过程中需要保证周期内数据是一定能够同步完的,不能差距太大。比如 A 集群 7 天内的增量数据,我只要花半天就可以完全同步到 B 集群,然后我又可以等到下周再次进行同步。最可怕的事情在于 A 集群的 7 天内的数据,我的程序花了 7 天还同步不完,然后下一个周期又来了,这样就无法做到准实时的一致性。其实 7 天还是一个比较大的时间,最好是能达到按天同步。
1.3 HDFS分布式拷贝工具:DistCp
1.3.1 DsitCp介绍
DistCp 是 Apache Hadoop 中的一种流行工具,在 hadoop-tools 工程下,作为独立子工程存在。其定位就是用于数据迁移的,定期在集群之间和集群内部备份数据。(在备份过程中,每次运行 DistCp 都称为一个备份周期)尽管性能相对较慢,但它的普及程度已经越来越高。

DistCp底层使用MapReduce在群集之间或并行在同一群集内复制文件。执行复制的MapReduce只有mapper阶段。 它涉及两个步骤:
- 构建要复制的文件列表(称为复制列表)
- 运行 MapReduce 作业以复制文件,并以复制列表为输入。
1.3.2 DsitCp特性
- 带宽限流
- DistCp 可以通过命令参数 bandwidth 来为程序进行带宽限流。
- 增量数据同步
- 在 DistCp 中可以通过 update 、append 和 diff 这 3 个参数实现增量同步。
- Update 解决了新增文件、目录的同步;Append 解决己存在文件的增量更新同步;Diff 解决删除或重命名类型文件的同步。
| Update | 只拷贝不存在的文件或者目录 |
|---|---|
| Append | 追加写目标路径下己存在的文件 |
| Diff | 通过快照的diff对比信息来同步源端路径与目标路径 |
- 高效的性能:分布式特性
- DistCp 底层使用 MapReduce 执行数据同步,MapReduce 本身是一类分布式程序。
1.3.3 DistCp命令
# hadoop distcp
usage: distcp OPTIONS [source_path...] <target_path>
-append //拷贝文件时支持对现有文件进行追加写操作
-async //异步执行distcp拷贝任务
-bandwidth <arg> //对每个Map任务的带宽限速
-delete //删除相对于源端,目标端多出来的文件
-diff <arg> //通过快照diff信息进行数据的同步
-overwrite //以覆盖的方式进行拷贝,如果目标端文件已经存在,则直接覆盖
-p <arg> //拷贝数据时,扩展属性信息的保留,包括权限信息、块大小信息等等
-skipcrccheck //拷贝数据时是否跳过cheacksum的校验
-update //拷贝数据时,只拷贝相对于源端 ,目标端不存在的文件数据
其中 source_path 、target_path 需要带上地址前缀以区分不同的集群,例如 :hadoop distcp hdfs://nn1:8020/foo/a hdfs://nn2:8020/bar/foo
上面的命令表示从nn1集群拷贝/foo/a路径下的数据到nn2集群的/bar/foo路径下。
HDFS NAMENODE 安全模式
1. HDFS NAMENODE 安全模式
1.1 场景:安全模式探究
HDFS 集群在停机状态下,使用hdfs –daemon命令逐个进程启动集群,观察现象。
首先启动 namenode:hdfs --daemon start namenode,然后依次执行浏览文件系统和创建文件夹操作,现象如下,发现集群可以查看目录结构但是无法新增目录。

打开 HDFS 集群 web 页面可以发现如下提示:

提示说:已经汇报的数据块的比例没有达到阈值。阈值为总数量块的 0.999。
接下来,启动第一台机器上的 Datanode 进程:hdfs --daemon start datanode,继续查看页面提示信息。


此时执行创建文件夹操作,发现可以创建成功了。

可以发现在安全模式下,我们可以浏览文件系统目录层次结构,但是却无法创建文件夹,安全模式下的文件系统似乎处于一种可读不可下的特殊状态。
1.2 安全模式概述
Hadoop 中的安全模式safe mode是NameNode的维护状态,在此状态下 NameNode 不允许对文件系统进行任何更改,可以接受读数据请求。
在 NameNode 启动过程中,首先会从 fsimage 和 edits 日志文件加载文件系统状态。然后,等待 DataNodes 汇报可用的 block 信息。在此期间,NameNode 保持在安全模式。随着 DataNode 的 block 汇报持续进行,当整个系统达到安全标准时,HDFS 自动离开安全模式。在 NameNode Web 主页上会显示安全模式是打开还是关闭。
如果 HDFS 处于安全模式下,不允许 HDFS 客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹,修改副本数等操作。
1.3 安全模式自动进入离开
1.3.1 自动进入时间
HDFS 集群启动时,当 NameNode 启动成功之后,此时集群就会自动进入安全模式。
1.3.2 自动离开条件
安全模式相关的配置属性参数都在hdfs-default.xml中定义,如果需要覆盖任何值,请在hdfs-site.xml文件中重新覆盖定义。
-
dfs.replication- hdfs block 的副本数据,默认 3
-
dfs.replication.max- 最大块副本数,默认 512
-
dfs.namenode.replication.min- 最小块副本数,默认 1
-
dfs.namenode.safemode.threshold-pct- 已汇报可用数据块数量占整体块数量的百分比阈值。默认 0.999f。
小于或等于 0,则表示退出安全模式之前,不要等待特定百分比的块。大于 1 的值将使安全模式永久生效。
- 已汇报可用数据块数量占整体块数量的百分比阈值。默认 0.999f。
-
dfs.namenode.safemode.min.datanodes- 指在退出安全模式之前必须存活的 DataNode 数量,默认 0
-
dfs.namenode.safemode.extension- 达到阈值条件后持续扩展的时间。倒计时结束如果依然满足阈值条件,自动离开安全模式。默认 30000 毫秒
1.4 安全模式手动进入离开
1.4.1 手动获取安全模式状态信息
hdfs dfsadmin -safemode get

1.4.2 手动进入命令
hdfs dfsadmin -safemode enter
手动进入安全模式对于集群维护或者升级的时候非常有用,因为这时候 HDFS 上的数据是只读的。


1.4.3 手动离开命令
hdfs dfsadmin -safemode leave

HDFS优化方案
1. HDFS优化方案
1.1 短路本地读取:Short Circuit Local Reads
1.1.1 背景
在 HDFS 中,不管是 Local Reads(DFSClient 和 Datanode 在同一个节点)还是 Remote Reads(DFSClient 和 Datanode不在同一个节点),底层处理方式都是一样的,都是先由Datanode读取数据,然后再通过RPC(基于TCP)把数据传给DFSClient。这样处理是比较简单的,但是性能会受到一些影响,因为需要 Datanode 在中间做一次中转。
尤其 Local Reads 的时候,既然 DFSClient 和数据是在一个机器上面,那么很自然的想法,就是让 DFSClient 绕开 Datanode 自己去读取数据。

所谓的“短路”读取绕过了 DataNode,从而允许客户端直接读取文件。显然,这仅在客户端与数据位于同一机器的情况下才可行。短路读取为许多应用提供了显着的性能提升。
1.1.2 短路本地读取
在 HDFS-2246 这个 JIRA 中,工程师们的想法是既然读取数据 DFSClient 和数据在同一台机器上,那么 Datanode 就把数据在文件系统中的路径,从什么地方开始读(offset)和需要读取多少(length)等信息告诉 DFSClient,然后 DFSClient 去打开文件自己读取。想法很好,问题在于配置复杂以及安全问题。

首先是配置问题,因为是让DFSClient自己打开文件读取数据,那么就需要配置一个白名单,定义哪些用户拥有访问 Datanode 的数据目录权限。如果有新用户加入,那么就得修改白名单。需要注意的是,这里是允许客户端访问 Datanode 的数据目录,也就意味着,任何用户拥有了这个权限,就可以访问目录下其他数据,从而导致了安全漏洞。因此,这个实现已经不建议使用了。

1.1.3 短路本地读取安全性改进
在 HDFS-347 中,提出了一种新的解决方案,让短路本地读取数据更加安全。

在 Linux 中,有个技术叫做Unix Domain Socket。Unix Domain Socket 是一种进程间的通讯方式,它使得同一个机器上的两个进程能以Socket的方式通讯。它带来的另一大好处是,利用它两个进程除了可以传递普通数据外,还可以在进程间传递文件描述符。
假设机器上的两个用户 A 和 B,A 拥有访问某个文件的权限而 B 没有,而 B 又需要访问这个文件。借助 Unix Domain Socket,可以让 A 打开文件得到一个文件描述符,然后把文件描述符传递给 B,B 就能读取文件里面的内容了即使它没有相应的权限。在 HDFS 的场景里面,A 就是 Datanode,B 就是 DFSClient,需要读取的文件就是 Datanode 数据目录中的某个文件。

这个方案在安全上就比上一个方案上好一些,至少它只允许 DFSClient 读取它需要的文件。
1.1.4 短路本地读取配置
1.1.4.1 libhadoop.so
因为 Java 不能直接操作 Unix Domain Socket,所以需要安装 Hadoop 的 native 包 libhadoop.so。在编译 Hadoop 源码的时候可以通过编译 native 模块获取。可以用如下命令来检查 native 包是否安装好。
hadoop checknative

1.1.4.2 hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>
dfs.client.read.shortcircuit是打开短路本地读取功能的开关。dfs.domain.socket.path是 DataNode 和DFSClient 之间沟通的 Socket 的本地路径。
注:/var/lib/hadoop-hdfs/dn_socket需要提前创建,但是只需要创建到/var/lib/hadoop-hdfs,后面的/dn_socket由 hadoop 自己创建,如果提前创建到这一步,DataNode 会启动失败。
1.2 makeHDFS Block负载平衡器:Balancer
1.2.1 背景
HDFS 数据可能并不总是在 DataNode 之间均匀分布。一个常见的原因是向现有群集中添加了新的 DataNode。HDFS 提供了一个 Balancer 程序,分析 block 放置信息并且在整个 DataNode 节点之间平衡数据,直到被视为平衡为止。
所谓的平衡指的是每个DataNode的利用率(节点上已用空间与节点总容量之比)与集群的利用率(集群上已用空间与集群总容量的比)相差不超过给定阈值百分比。 平衡器无法在单个 DataNode 上的各个卷之间进行平衡。

1.2.2 命令行配置和运行

-threshold 10 //集群平衡的条件,datanode间磁盘使用率相差阈值,区间选择:0~100
-policy datanode //平衡策略,默认为datanode, 如果datanode平衡,则集群已平衡。
-exclude -f /tmp/ip1.txt //默认为空,指定该部分ip不参与balance, -f:指定输入为文件
-include -f /tmp/ip2.txt //默认为空,只允许该部分ip参与balance,-f:指定输入为文件
-idleiterations 5 //迭代 5
1.2.2.1 设置平衡数据传输宽带
命令:hdfs dfsadmin -setBalancerBandwidth newbandwidth
其中newbandwidth是每个 DataNode 在平衡操作期间可以使用的最大网络带宽量,以每秒字节数为单位。
比如:hdfs dfsadmin -setBalancerBandwidth 104857600
1.2.2.2 默认运行balancer
命令:hdfs balancer
此时将会以默认参数进行数据块的平衡操作。
1.2.2.3 修改阈值运行balancer
命令:hdfs balancer -threshold 5
Balancer 将以阈值 5% 运行(默认值 10%),这意味着程序将确保每个 DataNode 上的磁盘使用量与群集中的总体使用量相差不超过 5%。例如,如果集群中所有 DataNode 的总体使用率是集群磁盘总存储容量的 40%,则程序将确保每个 DataNode 的磁盘使用率在该 DataNode 磁盘存储容量的 35% 至 45% 之间。
1.3 磁盘均衡器:HDFS Disk Balancer
1.3.1 背景
相比较于个人 PC,服务器一般可以通过挂载多块磁盘来扩大单机的存储能力。
在 Hadoop HDFS 中,DataNode 负责最终数据 block 的存储,在所在机器上的磁盘之间分配数据块。当写入新 block 时,DataNodes 将根据选择策略(循环策略或可用空间策略)来选择 block 的磁盘(卷)。
循环策略:它将新 block 均匀分布在可用磁盘上。默认此策略。
可用空间策略:此策略将数据写入具有更多可用空间(按百分比)的磁盘。

但是,在长期运行的群集中采用循环策略时,DataNode 有时会不均匀地填充其存储目录(磁盘/卷),从而导致某些磁盘已满而其他磁盘却很少使用的情况。发生这种情况的原因可能是由于大量的写入和删除操作,也可能是由于更换了磁盘。
另外,如果我们使用基于可用空间的选择策略,则每个新写入将进入新添加的空磁盘,从而使该期间的其他磁盘处于空闲状态。这将在新磁盘上创建瓶颈。
因此,需要一种Intra DataNode Balancing(DataNode内数据块的均匀分布)来解决 Intra-DataNode 偏斜(磁盘上块的不均匀分布),这种偏斜是由于磁盘更换或随机写入和删除而发生的。
因此,Hadoop 3.0 中引入了一个名为 Disk Balancer 的工具,该工具专注于在 DataNode 内分发数据。
1.3.2 HDFS Disk Balancer简介
HDFS disk balancer是 Hadoop 3 中引入的命令行工具,用于平衡 DataNode 中的数据在磁盘之间分布不均匀问题。 这里要特别注意,HDFS disk balancer 与 HDFS Balancer 是不同的:
HDFS disk balancer 针对给定的 DataNode 进行操作,并将块从一个磁盘移动到另一个磁盘,是 DataNode 内部数据在不同磁盘间平衡;
HDFS Balancer 平衡了 DataNode 节点之间的分布。
1.3.3 HDFS Disk Balancer功能
HDFS Disk balancer支持两个主要功能,即报告和平衡。
1.3.3.1 数据传播报告
为了定义一种方法来衡量集群中哪些计算机遭受数据分布不均的影响,HDFS 磁盘平衡器定义了 HDFS Volume Data Density metric(卷/磁盘数据密度度量标准)和 Node Data Density metric(节点数据密度度量标准)。
HDFS 卷数据密度度量标准能够比较数据在给定节点的不同卷上的分布情况。
节点数据密度度量允许在节点之间进行比较。
- Volume data density metric计算过程
假设有一台具有四个卷/磁盘的计算机:Disk1,Disk2,Disk3,Disk4,各个磁盘使用情况:
| Disk1 | Disk2 | Disk3 | Disk4 | |
|---|---|---|---|---|
| capacity | 200 GB | 300 GB | 350 GB | 500 GB |
| dfsUsed | 100 GB | 76 GB | 300 GB | 475 GB |
| dfsUsedRatio | 0.5 | 0.25 | 0.85 | 0.95 |
| volumeDataDensity | 0.20 | 0.45 | -0.15 | -0.24 |
Total capacity= 200 + 300 + 350 + 500 = 1350 GB
Total Used= 100 + 76 + 300 + 475 = 951 GB
因此,每个卷/磁盘上的理想存储为:
Ideal storage = total Used ÷ total capacity= 951÷1350 = 0.70
也就是每个磁盘应该保持在 70% 理想存储容量。
VolumeDataDensity = idealStorage – dfs Used Ratio
比如 Disk1 的卷数据密度= 0.70-0.50 = 0.20。其他 Disk 以此类推。
volumeDataDensity的正值表示磁盘未充分利用,而负值表示磁盘相对于当前理想存储目标的利用率过高。
- Node Data Density计算过程
Node Data Density(节点数据密度)= 该节点上所有卷/磁盘volume data density 绝对值的总和。
上述例子中的节点数据密度=|0.20|+|0.45|+|-0.15|+|-0.24| = 1.04
较低的 node Data Density 值表示该机器节点具有较好的扩展性,而较高的值表示节点具有更倾斜的数据分布。
一旦有了 volumeDataDensity 和 nodeDataDensity,就可以找到集群中数据分布倾斜的节点,或者可以获取给定节点的 volumeDataDensity。
1.3.3.2 磁盘平衡
当指定某个 DataNode 节点进行 disk 数据平衡,就可以先计算或读取当前的 volumeDataDensity(磁盘数据密度)。有了这些信息,我们可以轻松地确定哪些卷已超量配置,哪些卷已不足。为了将数据从一个卷移动到 DataNode 中的另一个卷,Hadoop 开发实现了基于 RPC 协议的 Disk Balancer。
1.3.4 HDFS Disk Balancer开启
HDFS Disk Balancer 通过创建计划进行操作,该计划是一组语句,描述应在两个磁盘之间移动多少数据,然后在 DataNode 上执行该组语句。计划包含多个移动步骤。计划中的每个移动步骤都具有目标磁盘,源磁盘的地址。移动步骤还具有要移动的字节数。该计划是针对可操作的 DataNode 执行的。
默认情况下,Hadoop 集群上已经启用了 Disk Balancer 功能。通过在hdfs-site.xml中调整dfs.disk.balancer.enabled参数值,选择在 Hadoop 中是否启用磁盘平衡器。
1.3.5 HDFS Disk Balancer相关命令
1.3.5.1 Plan计划
命令:hdfs diskbalancer -plan <datanode>
-out //控制计划文件的输出位置
-bandwidth //设置用于运行Disk Balancer的最大带宽。默认带宽10 MB/s。
–thresholdPercentage //定义磁盘开始参与数据重新分配或平衡操作的值。默认的thresholdPercentage值为10%,这意味着仅当磁盘包含的数据比理想存储值多10%或更少时,磁盘才用于平衡操作。
-maxerror //它允许用户在中止移动步骤之前为两个磁盘之间的移动操作指定要忽略的错误数。
-v //详细模式,指定此选项将强制plan命令在stdout上显示计划的摘要。
-fs //此选项指定要使用的NameNode。如果未指定,则Disk Balancer将使用配置中的默认NameNode。

1.3.5.2 Execute执行
命令:hdfs diskbalancer -execute <JSON file path>
execute 命令针对为其生成计划的 DataNode 执行计划。
1.3.5.3 Query查询
命令:hdfs diskbalancer -query <datanode>
query 命令从运行计划的 DataNode 获取 HDFS 磁盘平衡器的当前状态。
1.3.5.4 Cancel取消
命令:hdfs diskbalancer -cancel <JSON file path>
hdfs diskbalancer -cancel planID node <nodename>
cancel 命令取消运行计划。
1.3.5.5 Report执行
命令:hdfs diskbalancer -fs https://namenode.uri -report <file://>
1.4 纠删码技术:Erasure Coding
1.4.1 背景:3副本策略弊端
为了提供容错能力,HDFS 会根据 replication factor(复制因子)在不同的 DataNode 上复制文件块。默认复制因子为 3(注意这里的 3 指的是 1+2=3,不是额外 3 个),则原始块除外,还将有额外两个副本。每个副本使用 100% 的存储开销,因此导致 200% 的存储开销。这些副本也消耗其他资源,例如网络带宽。

在复制因子为N时,存在N-1个容错能力,但存储效率仅为1/N。
这种复制增加了存储开销,并且似乎很昂贵。因此,HDFS 使用 Erasure Coding(纠删码)代替复制,以提供相同级别的容错能力,并且存储开销不超过 50%。
Erasure Coding 文件的复制因子始终为 1,用户无法对其进行更改。
1.4.2 Erasure Coding(EC)简介
纠删码技术(Erasure coding) 简称 EC,是一种编码容错技术。最早用于通信行业,数据传输中的数据恢复。它通过对数据进行分块,然后计算出校验数据,使得各个部分的数据产生关联性。当一部分数据块丢失时,可以通过剩余的数据块和校验块计算出丢失的数据块。
Hadoop 3.0 之后引入了纠删码技术(Erasure Coding),它可以提高 50% 以上的存储利用率,并且保证数据的可靠性。
存储系统 RAID 使用纠删码。RAID通过striping(条带化) 实现纠删码,也就是说,将逻辑上连续的数据(例如文件)划分为较小的单位(bit,byte,or block),并将连续的单位存储在不同的磁盘上。
对于原始数据集的每个条带,都会根据纠删码算法来计算并存储一定数量的奇偶校验单元,该过程称为编码。
任何条带化单元中的错误都可以根据剩余数据和奇偶校验单元从计算中恢复,此过程称为解码。

1.4.3 Reed-Solomon(RS)码
1.4.3.1 RS码介绍
Reed-Solomon(RS)码是存储系统较为常用的一种纠删码,它有两个参数 k 和 m,记为 RS(k,m)。如下图所示,k 个数据块组成一个向量被乘上一个生成矩阵(Generator Matrix)GT 从而得到一个码字(codeword)向量,该向量由 k 个数据块和 m 个校验块构成。如果一个数据块丢失,可以用 (GT)-1 乘以码字向量来恢复出丢失的数据块。RS(k,m)最多可容忍 m 个块(包括数据块和校验块)丢失。

1.4.3.2 RS码通俗解释
比如有 7、8、9 三个原始数据,通过矩阵乘法,计算出来两个校验数据 50、122。这时原始数据加上校验数据,一共五个数据:7、8、9、50、122,可以任意丢两个,然后通过算法进行恢复。

1.4.4 Hadoop EC架构
为了支持纠删码,HDFS 体系结构进行了一些更改调整。
- Namenode扩展
- 条带化的 HDFS 文件在逻辑上由
block group(块组)组成,每个块组包含一定数量的内部块。这允许在块组级别而不是块级别进行文件管理。
- 条带化的 HDFS 文件在逻辑上由
- 客户端扩展
- 客户端的读写路径得到了增强,可以并行处理块组中的多个内部块。
- Datanode扩展
- DataNode 运行一个附加的 ErasureCodingWorker(ECWorker)任务,以对失败的纠删编码块进行后台恢复。 NameNode 检测到失败的 EC 块,然后 NameNode 选择一个 DataNode 进行恢复工作。
- 纠删编码策略
- 为了适应异构的工作负载,允许 HDFS 集群中的文件和目录具有不同的复制和纠删码策略。纠删码策略封装了如何对文件进行编码/解码。默认情况下启用
RS-6-3-1024k策略, RS 表示编码器算法 Reed-Solomon,6 、3 中表示数据块和奇偶校验块的数量,1024k 表示条带化单元的大小。 目录上还支持默认的REPLICATION方案。它只能在目录上设置,以强制目录采用 3 倍复制方案,而不继承其祖先的纠删码策略。此策略可以使 3x 复制方案目录与纠删码目录交错。REPLICATION 始终处于启用状态。- 此外也支持用户通过 XML 文件定义自己的 EC 策略,Hadoop conf 目录中有一个名为
user_ec_policies.xml.template的示例 EC 策略 XML 文件,用户可以参考该文件。
- 为了适应异构的工作负载,允许 HDFS 集群中的文件和目录具有不同的复制和纠删码策略。纠删码策略封装了如何对文件进行编码/解码。默认情况下启用
- Intel ISA-L
- 英特尔 ISA-L 代表英特尔智能存储加速库。 ISA-L 是针对存储应用程序而优化的低级功能的开源集合。它包括针对 Intel AVX 和 AVX2 指令集优化的快速块 Reed-Solomon 类型擦除代码。
HDFS纠删码可以利用ISA-L加速编码和解码计算。
- 英特尔 ISA-L 代表英特尔智能存储加速库。 ISA-L 是针对存储应用程序而优化的低级功能的开源集合。它包括针对 Intel AVX 和 AVX2 指令集优化的快速块 Reed-Solomon 类型擦除代码。
1.4.5 Erasure Coding部署方式
1.4.5.1 集群和硬件配置
编码和解码工作会消耗 HDFS 客户端和 DataNode 上的额外CPU。
纠删码文件也分布在整个机架上,以实现机架容错。这意味着在读写条带化文件时,大多数操作都是在机架上进行的。因此,网络带宽也非常重要。
对于机架容错,拥有足够数量的机架也很重要,每个机架所容纳的块数不超过 EC 奇偶校验块的数。
机架数量=(数据块+奇偶校验块)/奇偶校验块后取整。比如对于 EC 策略 RS(6,3),这意味着最少 3 个机架(由(6 + 3)/ 3 = 3 计算),理想情况下为 9 个或更多,以处理计划内和计划外的停机。对于机架数少于奇偶校验单元数的群集,HDFS 无法维持机架容错能力,但仍将尝试在多个节点之间分布条带化文件以保留节点级容错能力。因此,建议设置具有类似数量的 DataNode 的机架。
1.4.5.2 纠删码策略设置
纠删码策略由参数dfs.namenode.ec.system.default.policy指定,默认是 RS-6-3-1024k,其他策略默认是禁用的。可以通过hdfs ec [-enablePolicy -policy <policyName>]命令启用策略集。
1.4.5.3 启用英特尔ISA-L
默认 RS 编解码器的 HDFS 本机实现利用 Intel ISA-L 库来改善编码和解码计算。要启用和使用 Intel ISA-L,需要执行三个步骤。
建立 ISA-L 库;
使用 ISA-L 支持构建 Hadoop;
使用 -Dbundle.isal 将 isal.lib 目录的内容复制到最终的 tar 文件中。使用 tar 文件部署 Hadoop。确保 ISA-L 在 HDFS 客户端和 DataNode 上可用。
1.4.6 EC命令
HDFS 提供了一个 ec 子命令来执行与纠删码有关的管理命令。

-
-setPolicy -path <path> [-policy <policy>] [-replicate]- 在指定路径的目录上设置擦除编码策略。
path:HDFS 中的目录。这是必填参数。设置策略仅影响新创建的文件,而不影响现有文件。policy:用于此目录下文件的擦除编码策略。默认 RS-6-3-1024k 策略。-replicate在目录上应用默认的 REPLICATION 方案,强制目录采用 3x 复制方案。-replicate和-policy <policy>是可选参数。不能同时指定它们。
-
-getPolicy -path <path>- 获取指定路径下文件或目录的擦除编码策略的详细信息。
-
-unsetPolicy -path <path>- 取消设置先前对目录上的 setPolicy 的调用所设置的擦除编码策略。如果该目录从祖先目录继承了擦除编码策略,则 unsetPolicy 是 no-op。在没有显式策略集的目录上取消策略将不会返回错误。
-
-listPolicies- 列出在 HDFS 中注册的所有(启用,禁用和删除)擦除编码策略。只有启用的策略才适合与 setPolicy 命令一起使用。
-
-addPolicies -policyFile <文件>- 添加用户定义的擦除编码策略列表。
-
-listCodecs- 获取系统中支持的擦除编码编解码器和编码器的列表。
-
-removePolicy -policy <policyName>- 删除用户定义的擦除编码策略。
-
-enablePolicy -policy <policyName>- 启用擦除编码策略。
-
-disablePolicy -policy <policyName>- 禁用擦除编码策略。
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
见ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain-CSDN博客
HDFS动态节点管理
见Hadoop生态圈(八)- HDFS动态节点管理_hadoop集群刷新节点-CSDN博客
HDFS High Availability(HA)高可用集群
见Hadoop生态圈(九)- HDFS High Availability(HA)高可用集群_hadoop客户端无法识别高可用(ha)集群的逻辑名称访问-CSDN博客
HDFS Federation联邦机制
见Hadoop生态圈(十)- HDFS Federation联邦机制_ha ns2 联邦-CSDN博客
HDFS集群滚动升级
见Hadoop生态圈(十一)- HDFS集群滚动升级_hadoop rolling upgrade-CSDN博客
HDFS架构深入学习
1. HDFS架构剖析
1.1 HDFS整体概述
HDFS是 Hadoop Distribute File System 的简称,意为:Hadoop分布式文件系统。是 Hadoop 核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。HDFS解决的问题就是大数据如何存储,它是横跨在多台计算机上的文件存储系统并且具有高度的容错能力。
HDFS集群遵循主从架构。每个群集包括一个主节点和多个从节点。在内部,文件分为一个或多个块,每个块根据复制因子存储在不同的从节点计算机上。主节点存储和管理文件系统名称空间,即有关文件块的信息,例如块位置,权限等。从节点存储文件的数据块。主从各司其职,互相配合,共同对外提供分布式文件存储服务。当然内部细节对于用户来说是透明的。

1.2 角色介绍
1.2.1 概述
HDFS 遵循主从架构。每个群集包括一个主节点和多个从节点。其中:
NameNode是主节点,负责存储和管理文件系统元数据信息,包括 namespace 目录结构、文件块位置信息等;DataNode是从节点,负责存储文件具体的数据块。
两种角色各司其职,共同协调完成分布式的文件存储服务。
SecondaryNameNode是主角色的辅助角色,帮助主角色进行元数据的合并。

1.2.2 NameNode
NameNode是 Hadoop 分布式文件系统的核心,架构中的主角色。它维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。基于此,NameNode成为了访问HDFS的唯一入口。
内部通过内存和磁盘两种方式管理元数据。其中磁盘上的元数据文件包括 Fsimage 内存元数据镜像文件和 edits log(Journal)编辑日志。
在 Hadoop2 之前,NameNode 是单点故障。Hadoop 2 中引入的高可用性。Hadoop 集群体系结构允许在集群中以热备配置运行两个或多个 NameNode。

1.2.3 Datanode
DataNode是 Hadoop HDFS 中的从角色,负责具体的数据块存储。DataNode 的数量决定了 HDFS 集群的整体数据存储能力。通过和 NameNode 配合维护着数据块。

1.2.4 Secondarynamenode
除了 DataNode 和 NameNode 之外,还有另一个守护进程,它称为secondary NameNode。充当NameNode的辅助节点,但不能替代 NameNode。
当 NameNode 启动时,NameNode 合并 Fsimage 和 edits log 文件以还原当前文件系统名称空间。如果 edits log 过大不利于加载,Secondary NameNode 就辅助 NameNode 从 NameNode 下载Fsimage文件和edits log文件进行合并。
1.3 HDFS重要特性
1.3.1 主从架构
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。

1.3.2 分块机制
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于 hdfs-default.xml 中:dfs.blocksize。默认大小在 Hadoop2.x/3.x 是128M(134217728),1.x 版本中是 64M。

1.3.3 副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认dfs.replication的值是3,也就是会额外再复制 2 份,连同本身总共 3 份副本。

1.3.4 Namespace
HDFS 支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的 namespace 名称空间,任何对文件系统名称空间或属性的修改都将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
1.3.5 元数据管理
在 HDFS 中,Namenode 管理的元数据具有两种类型:
-
文件自身属性信息- 文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
-
文件块位置映射信息- 记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上。
1.3.6 数据块存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以在多个 DataNode 上存储。

2. HDFS Web Interfaces
2.1 Web Interfaces介绍
除了命令行界面之外,Hadoop 还为 HDFS 提供了 Web 用户界面。用户可以通过 Web 界面操作文件系统并且获取和 HDFS 相关的状态属性信息。
HDFS Web 地址是 http://nn_host:port/,默认端口号9870。

2.2 模块功能解读
2.2.1 Overview
Overview 是总揽模块,默认的主页面。展示了 HDFS 一些最核心的信息。

2.2.1.1 Summary

2.2.1.2 NameNode Journal Status

2.2.1.3 NameNode Storage

2.2.1.4 DFS Storage Types

2.2.2 Datanodes
Datanodes 模块主要记录了 HDFS 集群中各个 DataNode 的相关状态信息。

2.2.3 Datanode Volume Failures
此模块记录了 DataNode 卷故障信息。

2.2.4 Snapshot
Snapshot模块记录 HDFS 文件系统的快照相关信息,包括哪些文件夹创建了快照和总共有哪些快照。

2.2.5 Satartup progress

2.2.6 Utilities
Utilities模块算是用户使用最多的模块了,里面包括了文件浏览、日志查看、配置信息查看等核心功能。

2.2.6.1 Browse the file system
该模块可以说是我们在开发使用 HDFS 过程中使用最多的模块了,提供了一种Web页面浏览操作文件系统的能力,在某些场合下,比使用命令操作更加直观方便。

2.2.6.2 Logs、Log Level


2.2.6.3 Configruation
该模块可以列出当前集群成功加载的所谓配置文件属性,可以从这里来进行判断用户所设置的参数属性是否成功加载生效,如果此处没有,需要检查配置文件或者重启集群加载。

3. HDFS读写流程
因为 namenode 维护管理了文件系统的元数据信息,这就造成了不管是读还是写数据都是基于 NameNode 开始的,也就是说NameNode成为了HDFS访问的唯一入口。入口地址是:http://nn_host:8020。
3.1 写数据流程

3.1.1 Pipeline管道、ACK应答响应
Pipeline,中文翻译为管道。这是 HDFS 在上传文件写数据过程中采用的一种数据传输方式。客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。通俗描述 pipeline 的过程就是:Client→ \rightarrow→A→ \rightarrow→B→ \rightarrow→C。
为什么 datanode 之间采用 pipeline线性传输,而不是一次给三个 datanode 拓扑式传输呢?因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。在 pipeline 管道传输数据的过程中,传输的反方向会进行 ACK 校验,确保数据传输安全。

3.1.2 具体流程
- HDFS 客户端通过对 DistributedFileSystem 对象调用
create()请求创建文件。 - DistributedFileSystem 对 namenode进行
RPC调用,请求上传文件。namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode 就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个 IOException。 - DistributedFileSystem 为客户端返回 FSDataOutputStream 输出流对象。由此客户端可以开始写入数据。FSDataOutputStream 是一个包装类,所
包装的是DFSOutputStream。 - 在客户端写入数据时,DFSOutputStream 将它分成一个个数据包(
packet默认 64kb),并写入一个称之为数据队列(data queue)的内部队列。DFSOutputStream 有一个内部类做 DataStreamer,用于请求 NameNode 挑选出适合存储数据副本的一组 DataNode。这一组 DataNode 采用pipeline机制做数据的发送。默认是 3 副本存储。 - DataStreamer 将数据包流式传输到 pipeline 的第一个 datanode,该 DataNode 存储数据包并将它发送到 pipeline 的第二个 DataNode。同样,第二个 DataNode 存储数据包并且发送给第三个(也是最后一个)DataNode。
- DFSOutputStream 也维护着一个内部数据包队列来等待 DataNode 的收到确认回执,称之为
确认队列(ack queue),收到 pipeline 中所有 DataNode 确认信息后,该数据包才会从确认队列删除。 - 客户端完成数据写入后,将在流上调用 close() 方法关闭。该操作将剩余的所有数据包写入 DataNode pipeline,并在联系到 NameNode 告知其文件写入完成之前,等待确认。
- 因为 namenode 已经知道文件由哪些块组成(DataStream 请求分配数据块),因此它仅需等待最小复制块即可成功返回。
- 数据块最小复制是由参数
dfs.namenode.replication.min指定,默认是1。
3.1.3 默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定。策略如下:

3.1.4 网络拓扑——节点距离计算
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。

例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为 /d1/r1/n1。利用这种标记,这里给出四种距离描述。
3.2 读数据流程

3.2.1 具体流程
- 客户端通过调用 DistributedFileSystem 对象上的 open() 来打开希望读取的文件。
- DistributedFileSystem 使用
RPC调用namenode 来确定文件中前几个块的块位置。对于每个块,namenode 返回具有该块副本的 datanode 的地址,并且 datanode 根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个 DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。 - DistributedFileSystem 将
FSDataInputStream(支持文件seek定位读的输入流)返回到客户端以供其读取数据。FSDataInputStream 类转而封装为 DFSInputStream 类,DFSInputStream 管理着 datanode 和 namenode 之间的 IO。 - 客户端在流上调用 read() 方法。然后,已存储着文件前几个块 DataNode 地址的 DFSInputStream 随即连接到文件中第一个块的最近的 DataNode 节点。通过对数据流反复调用 read() 方法,可以将数据从 DataNode 传输到客户端。
- 当该块快要读取结束时,DFSInputStream 将关闭与该 DataNode 的连接,然后寻找下一个块的最佳 datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
- 客户端从流中读取数据时,块是按照打开 DFSInputStream 与 DataNode 新建连接的顺序读取的。它也会根据需要询问 NameNode 来检索下一批数据块的 DataNode 位置信息。一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法。
- 如果 DFSInputStream 与 DataNode 通信时遇到错误,它将尝试该块的下一个最接近的 DataNode 读取数据。并将记住发生故障的 DataNode,保证以后不会反复读取该 DataNode 后续的块。此外,DFSInputStream 也会通过校验和(checksum)确认从 DataNode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream 会尝试从其他 DataNode 读取该块的副本,也会将被损坏的块报告给 namenode 。
3.3 角色职责概述
3.3.1 Namenode职责
- NameNode 是 HDFS 的核心,集群的主角色,被称为 Master。
- NameNode 仅存储管理 HDFS 的元数据:文件系统 namespace 操作维护目录树,文件和块的位置信息。
- NameNode 不存储实际数据或数据集。数据本身实际存储在 DataNodes 中。
- NameNode 知道 HDFS 中任何给定文件的块列表及其位置。使用此信息 NameNode 知道如何从块中构建文件。
- NameNode 并不持久化存储每个文件中各个块所在的 DataNode 的位置信息,这些信息会在系统启动时从 DataNode 汇报中重建。
- NameNode 对于 HDFS 至关重要,当 NameNode 关闭时,HDFS / Hadoop 集群无法访问。
- NameNode 是 Hadoop 集群中的单点故障。
- NameNode 所在机器通常会配置有大量内存(RAM)。
3.3.2 Datanode职责
- DataNode 负责将实际数据存储在 HDFS 中。是集群的从角色,被称为 Slave。
- DataNode 启动时,它将自己发布到 NameNode 并汇报自己负责持有的块列表。
- 根据 NameNode 的指令,执行块的创建、复制、删除操作。
- DataNode 会定期(
dfs.heartbeat.interval配置项配置,默认是 3 秒)向 NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效。 - DataNode 会定期向 NameNode 进行自己持有的数据块信息汇报,汇报时间间隔取参数
dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时。 - DataNode 所在机器通常配置有大量的硬盘空间。因为实际数据存储在 DataNode 中。
Namenode元数据管理及各组件工作机制
1. Namenode元数据管理
1.1 元数据是什么
元数据(Metadata),又称中介数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
在 HDFS 中,元数据主要指的是文件相关的元数据,由 NameNode 管理维护。从广义的角度来说,因为 NameNode 还需要管理众多 DataNode 节点,因此 DataNode 的位置和健康状态信息也属于元数据。
1.2 元数据管理概述
在 HDFS 中,文件相关元数据具有两种类型:
- 文件自身属性信息
- 文件名称、权限,修改时间,文件大小,复制因子,数据块大小。

- 文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
- 文件块位置映射信息
- 记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上。
- 按存储形式分为内存元数据和元数据文件两种,分别存在内存和磁盘上。

1.2.1 内存元数据
为了保证用户操作元数据交互高效,延迟低,NameNode 把所有的元数据都存储在内存中,我们叫做内存元数据。内存中的元数据是最完整的,包括文件自身属性信息、文件块位置映射信息。
但是内存的致命问题是,断点数据丢失,数据不会持久化。因此 NameNode 又辅佐了元数据文件来保证元数据的安全完整。
1.2.2 磁盘元数据
1.2.2.1 fsimage内存镜像文件
fsimage 是内存元数据的一个持久化的检查点。但是fsimage中仅包含Hadoop文件系统中文件自身属性相关的元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是由 datanode 启动加入集群的时候,向 namenode 进行数据块的汇报得到的,并且后续间断指定时间进行数据块报告。
持久化的动作是一种数据从内存到磁盘的 IO 过程。会对 namenode 正常服务造成一定的影响,不能频繁的进行持久化。
1.2.2.2 Edits log编辑日志
为了避免两次持久化之间数据丢失的问题,又设计了 Edits log 编辑日志文件。文件中记录的是HDFS所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到 edits 文件中。
1.2.3 加载元数据顺序
fsimage 和 edits 文件都是经过序列化的,在NameNode启动的时候,它会将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
当客户端对 HDFS 中的文件进行新增或者修改操作,操作记录首先被记入 edits 日志文件中,当客户端操作成功后,相应的元数据会更新到内存元数据中。因为 fsimage 文件一般都很大(GB 级别的很常见),如果所有的更新操作都往 fsimage 文件中添加,这样会导致系统运行的十分缓慢。
HDFS 这种设计实现着手于:一是内存中数据更新、查询快,极大缩短了操作响应时间;二是内存中元数据丢失风险颇高(断电等),因此辅佐元数据镜像文件(fsimage)+ 编辑日志文件(edits)的备份机制进行确保元数据的安全。
NameNode 维护整个文件系统元数据。因此,元数据的准确管理,影响着 HDFS 提供文件存储服务的能力。
1.3 元数据管理相关目录文件
1.3.1 元数据存储目录
在 Hadoop 的 HDFS 首次部署好配置文件之后,并不能马上启动使用,而是先要对文件系统进行格式化操作:hdfs namenode -format
在这里要注意两个概念,一个是 format 之前,HDFS 在物理上还不存在;二就是此处的 format 并不是指传统意义上的本地磁盘格式化,而是一些清除与准备工作。其中就会创建元数据本地存储目录和一些初始化的元数据相关文件。
namenode 元数据存储目录由参数:dfs.namenode.name.dir指定,格式化完成之后,将会在$dfs.namenode.name.dir/current目录下创建如下的文件:

其中的dfs.namenode.name.dir是在hdfs-site.xml文件中配置的,默认值如下:

dfs.namenode.name.dir属性可以配置多个目录,各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到 hadoop 的元数据,特别是当其中一个目录是 NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
1.3.2 元数据相关文件
1.3.2.1 VERSION

- namespaceID/clusterID/blockpoolID
- 这些都是 HDFS 集群的唯一标识符。标识符被用来防止 DataNodes 意外注册到另一个集群中的 namenode 上。这些标识在联邦(federation)部署中特别重要。联邦模式下,会有多个 NameNode 独立工作。每个的 NameNode 提供唯一的命名空间(namespaceID),并管理一组唯一的文件块池(blockpoolID)。clusterID 将整个集群结合在一起作为单个逻辑单元,在集群中的所有节点上都是一样的。
- storageType
- 说明这个文件存储的是什么进程的数据结构信息
- 如果是 DataNode,storageType=DATA_NODE。
- cTime
- NameNode 存储系统创建时间,首次格式化文件系统这个属性是 0,当文件系统升级之后,该值会更新到升级之后的时间戳;
- layoutVersion
- HDFS 元数据格式的版本。添加需要更改元数据格式的新功能时,请更改此数字。当前的 HDFS 软件使用比当前版本更新的布局版本时,需要进行 HDFS 升级。
1.3.2.2 seen_txid

包含最后一个 checkpoint 的最后一个事务 ID。这不是 NameNode 接受的最后一个事务 ID。该文件不会在每个事务上更新,而只会在 checkpoint 或编辑日志记录上更新。该文件的目的是尝试识别 edits 启动期间是否丢失的文件。如果 edits 目录被意外删除,然后自上一个 checkpoint 以来的所有事务都将消失,NameNode 仅从最近的一次 fsimage 加载启动。为了防止这种情况,NameNode 启动还检查 seen_txid 以确认它至少可以加载该数目的事务。如果无法验证装入事务,它将中止启动。
1.3.2.3 fsimage相关

元数据镜像文件。每个 fsimage 文件还有一个对应的 .md5 文件,可以用来做 MD5 校验,HDFS使用该文件来防止磁盘损坏文件异常。
1.3.2.4 Edits log相关

已完成且不可修改的编辑日志。这些文件中的每个文件都包含文件名定义的范围内的所有编辑日志事务。在 HA 高可用性部署中,主备 namenode 之间可以通过 edits log 进行数据同步。
1.3.3 Fsimage、editslog查看
1.3.3.1 Fsimage
fsimage文件是 Hadoop 文件系统元数据的一个永久性的检查点,包含Hadoop文件系统中的所有目录和文件idnode的序列化信息;对于文件来说,包含的信息有修改时间、访问时间、块大小和组成一个文件块信息等;而对于目录来说,包含的信息主要有修改时间、访问控制权限等信息。
oiv是offline image viewer的缩写,用于将 fsimage 文件的内容转储到指定文件中以便于阅读,该工具还提供了只读的 WebHDFS API 以允许离线分析和检查 hadoop 集群的命名空间。
oiv 在处理非常大的 fsimage 文件时是相当快的,如果该工具不能够处理 fsimage,它会直接退出。该工具不具备向后兼容性,比如使用 hadoop-2.4 版本的 oiv 不能处理 hadoop-2.3 版本的 fsimage,只能使用 hadoop-2.3 版本的 oiv。就像它的名称所提示的(offline),oiv 不需要 hadoop 集群处于运行状态。
命令:hdfs oiv -i fsimage_0000000000000000050 -p XML -o fsimage.xml

1.3.3.2 editslog
edits log文件存放的是Hadoop文件系统的所有更新操作记录日志,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
NameNode 起来之后,HDFS 中的更新操作会重新写到 edits 文件中,因为 fsimage 文件一般都很大(GB 级别的很常见),如果所有的更新操作都往 fsimage 文件中添加,这样会导致系统运行的十分缓慢,但是如果往 edits 文件里面写就不会这样,每次执行写操作之后,且在向客户端发送成功代码之前,edits 文件都需要同步更新。如果一个文件比较大,使得写操作需要向多台机器进行操作,只有当所有的写操作都执行完成之后,写操作才会返回成功,这样的好处是任何的操作都不会因为机器的故障而导致元数据的不同步。
oev是offline edits viewer(离线 edits 查看器)的缩写,该工具不需要 hadoop 集群处于运行状态。
命令:hdfs oev -i edits_0000000000000000011-0000000000000000025 -o edits.xml
在输出文件中,每个RECORD记录了一次操作,示例如下:

1.4 SecondaryNamenode
1.4.1 SNN职责概述

NameNode 职责是管理元数据信息,DataNode 的职责是负责数据具体存储,那么 SecondaryNameNode 的作用是什么?对很多初学者来说是非常迷惑的。它为什么会出现在 HDFS 中。从它的名字上看,它给人的感觉就像是 NameNode 的备份。但它实际上却不是。
当 HDFS 集群运行一段事件后,就会出现下面一些问题:
- edits logs 会变的很大,fsimage 将会变得很旧;
- namenode 重启会花费很长时间,因为有很多改动要合并到 fsimage 文件上;
- 如果频繁进行 fsimage 持久化,又会影响 NameNode 正常服务,毕竟 IO 操作是一种内存到磁盘的耗精力操作
因此为了克服这个问题,需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在 NameNode 上的压力。
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
1.4.2 SNN checkpoint机制
1.4.2.1 概述
Checkpoint核心是把 fsimage 与 edits log 合并以生成新的 fsimage 的过程。此过程有两个好处:fsimage 版本不断更新不会太旧、edits log 文件不会太大。
1.4.2.2 流程

- 当触发 checkpoint 操作条件时,SNN 发生请求给 NN 滚动 edits log。然后 NN 会生成一个新的编辑日志文件:edits new,便于记录后续操作记录。
- 同时 SNN 会将 edits 文件和 fsimage 复制到本地(使用 HTTP GET 方式)。
- SNN 首先将
fsimage载入到内存,然后一条一条地执行edits文件中的操作,使得内存中的 fsimage 不断更新,这个过程就是 edits 和 fsimage 文件合并。合并结束,SNN 将内存中的数据dump生成一个新的 fsimage 文件。 - SNN 将新生成的 Fsimage new 文件复制到 NN 节点。
- 至此刚好是一个轮回,等待下一次 checkpoint 触发 SecondaryNameNode 进行工作,一直这样循环操作。
1.4.2.3 触发机制
Checkpoint 触发条件受两个参数控制,可以通过 core-site.xml 进行配置:
dfs.namenode.checkpoint.period=3600 //两次连续的checkpoint之间的时间间隔。默认1小时
dfs.namenode.checkpoint.txns=1000000 //最大没有执行checkpoint事务的数量,满足将强制执行紧急checkpoint,即使尚未达到检查点周期。默认100万事务数量。
12
从上面的描述我们可以看出,SecondaryNamenode根本就不是Namenode的一个热备,只是将fsimage和edits合并。
1.5 Namenode元数据恢复
1.5.1 Namenode存储多目录
namenode 元数据存储目录由参数:dfs.namenode.name.dir指定。
dfs.namenode.name.dir属性可以配置多个目录,各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到 hadoop 的元数据,特别是当其中一个目录是 NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
1.5.2 从SecondaryNameNode恢复
SecondaryNameNode 在 checkpoint 的时候会将 fsimage 和 edits log 下载到自己的本机上本地存储目录下。并且在 checkpoint 之后也不会进行删除。
如果 NameNode 中的 fsimage 真的出问题了,还是可以用 SecondaryNamenode 中的 fsimage 替换一下 NameNode 上的 fsimage,虽然已经不是最新的 fsimage,但是我们可以将损失减小到最少。

2. NN、2NN及DN工作机制
2.1 namenode和SecondaryNamenode工作机制

- 第一阶段:NameNode启动
- 第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- 客户端对元数据进行增删改的请求。
- NameNode 记录操作日志,更新滚动日志。
- NameNode 在内存中对元数据进行增删改。
- 第二阶段:Secondary NameNode工作
- Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode 是否检查结果。
- Secondary NameNode 请求执行 CheckPoint。
- NameNode 滚动正在写的 Edits 日志。
- 将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
- Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件 fsimage.chkpoint。
- 拷贝 fsimage.chkpoint 到 NameNode。
- NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
2.2 DataNode工作机制

- 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验以及时间戳。
- DataNode 启动后向 NameNode 注册,通过后,周期性(6小时)的向 NameNode 上报所有的块信息。
DataNode 向 NameNode 汇报当前解读信息的时间间隔,默认 6 小时:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
12345
DataNode 扫描自己节点块信息列表的时间,默认 6 小时:
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value>
</property>
1234
- 心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
2.3 DataNode数据完整性
思考:如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号(1)和绿灯信号(0),但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理 DataNode 节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是 DataNode 节点保证数据完整性的方法。
- 当 DataNode 读取 Block 的时候,它会计算 CheckSum。
- 如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
- Client 读取其他 DataNode 上的 Block。
- 常见的校验算法 crc(32),md5(128),sha1(160)
- DataNode 在其文件创建后周期验证 CheckSum。

2.4 DataNode掉线时限参数设置

需要注意的是 hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
123456789
HDFS小文件解决方案
1. Hadoop Archive归档
HDFS 并不擅长存储小文件,因为每个文件最少一个 block,每个 block 的元数据都会在 NameNode 占用内存,如果存在大量的小文件,它们会吃掉 NameNode 节点的大量内存。如下所示,模拟小文件场景:
[hadoop@hadoop1 input]$ hadoop fs -mkdir /smallfile
[hadoop@hadoop1 input]$ echo 1 > 1.txt
[hadoop@hadoop1 input]$ echo 2 > 2.txt
[hadoop@hadoop1 input]$ echo 3 > 3.txt
[hadoop@hadoop1 input]$ hadoop fs -put 1.txt 2.txt 3.txt /smallfile
12345

Hadoop Archives可以有效的处理以上问题,它可以把多个文件归档成为一个文件,归档成一个文件后还可以透明的访问每一个文件。
1.1 创建Archive
Usage: hadoop archive -archiveName name -p <parent> <src>* <dest>
其中-archiveName是指要创建的存档的名称。比如test.har,archive 的名字的扩展名应该是*.har。 -p参数指定文件存档文件(src)的相对路径。
举个例子:-p /foo/bar a/b/c e/f/g,这里的/foo/bar是a/b/c与e/f/g的父路径,所以完整路径为/foo/bar/a/b/c与/foo/bar/e/f/g。
例如:如果你只想存档一个目录/smallfile下的所有文件:
hadoop archive -archiveName test.har -p /smallfile /outputdir
这样就会在/outputdir目录下创建一个名为test.har的存档文件。
**注意:**Archive 归档是通过 MapReduce 程序完成的,需要启动 YARN 集群。

1.2 查看Archive
1.2.1 查看归档之后的样子
首先我们来看下创建好的 har 文件。使用如下的命令:
hadoop fs -ls /outputdir/test.har

这里可以看到 har 文件包括:两个索引文件,多个 part 文件(本例只有一个)以及一个标识成功与否的文件。part文件是多个原文件的集合, 通过 index 文件可以去找到原文件。
例如上述的三个小文件 1.txt 2.txt 3.txt 内容分别为 1,2,3。进行 archive 操作之后,三个小文件就归档到 test.har 里的 part-0 一个文件里。

1.2.2 查看归档之前的样子
在查看 har 文件的时候,如果没有指定访问协议,默认使用的就是 hdfs://,此时所能看到的就是归档之后的样子。
此外,Archive 还提供了自己的 har uri 访问协议。如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
Hadoop Archives 的 URI 是:
har://scheme-hostname:port/archivepath/fileinarchive
scheme-hostname 格式为hdfs-域名:端口

hadoop fs -ls har://hdfs-node1:8020/outputdir/test.har/
hadoop fs -ls har:///outputdir/test.har
hadoop fs -cat har:///outputdir/test.har/1.txt
123
1.3 提取Archive
按顺序解压存档(串行):
hadoop fs -cp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
hadoop fs -mkdir /smallfile1
hadoop fs -cp har:///outputdir/test.har/* /smallfile1
hadoop fs -ls /smallfile1
123

要并行解压存档,请使用 DistCp,对应大的归档文件可以提高效率:
hadoop distcp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
hadoop distcp har:///outputdir/test.har/* /smallfile2
1
1.4 Archive使用注意事项
- Hadoop archives 是特殊的档案格式。一个 Hadoop archive 对应一个文件系统目录。Hadoop archive 的扩展名是
*.har; - 创建 archives 本质是运行一个 Map/Reduce 任务,所以应该在 Hadoop 集群上运行创建档案的命令;
- 创建 archive 文件要消耗和原文件一样多的硬盘空间;
- archive 文件不支持压缩,尽管 archive 文件看起来像已经被压缩过;
- archive 文件一旦创建就无法改变,要修改的话,需要创建新的 archive 文件。事实上,一般不会再对存档后的文件进行修改,因为它们是
定期存档的,比如每周或每日; - 当创建 archive 时,源文件不会被更改或删除;
2. Sequence File
2.1 Sequence File介绍
Sequence File是 Hadoop API 提供的一种二进制文件支持。这种二进制文件直接将<key, value>键值对序列化到文件中。

2.2 Sequence File优缺点
- 优点
- 二级制格式存储,比文本文件更紧凑。
- 支持不同级别压缩(基于 Record 或 Block 压缩)。
- 文件可以拆分和并行处理,适用于 MapReduce。
- 缺点
- 二进制格式文件不方便查看。
- 特定于 hadoop,只有 Java API 可用于与之件进行交互。尚未提供多语言支持。
2.3 Sequence File格式
Hadoop Sequence File 是一个由二进制键/值对组成的。根据压缩类型,有 3 种不同的 Sequence File 格式:未压缩格式、record压缩格式、block压缩格式。
Sequence File 由一个header和一个或多个record组成。以上三种格式均使用相同的 header 结构,如下所示:

前 3 个字节为 SEQ,表示该文件是序列文件,后跟一个字节表示实际版本号(例如 SEQ4 或 SEQ6)。Header 中其他也包括 key、value class 名字、 压缩细节、metadata、Sync marker。Sync Marker 同步标记,用于可以读取任意位置的数据。
2.3.1 未压缩格式

未压缩的 Sequence File 文件由 header、record、sync 三个部分组成。其中 record 包含了 4 个部分:record length(记录长度)、key length(键长)、key、value。
每隔几个 record(100字节左右)就有一个同步标记。
2.3.2 基于record压缩格式

基于 record 压缩的 Sequence File 文件由 header、record、sync 三个部分组成。其中 record 包含了4个部分:record length(记录长度)、key length(键长)、key、compressed value(被压缩的值)。
每隔几个 record(100字节左右)就有一个同步标记。
2.3.3 基于block压缩格式

基于 block 压缩的 Sequence File 文件由 header、block、sync 三个部分组成。
block指的是record block,可以理解为多个record记录组成的块。注意,这个 block 和 HDFS 中分块存储的 block(128M)是不同的概念。
Block 中包括:record 条数、压缩的 key 长度、压缩的 keys、压缩的 value 长度、压缩的 values。每隔一个 block 就有一个同步标记。
block 压缩比 record 压缩提供更好的压缩率。使用 Sequence File 时,通常首选块压缩。
2.4 Sequence File文件读写
2.4.1 开发环境构建
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
1234567891011121314151617
2.4.2 SequenceFileWrite
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
public class SequenceFileWrite {
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws Exception {
//设置客户端运行身份 以root去操作访问HDFS
System.setProperty("HADOOP_USER_NAME","hadoop");
//Configuration 用于指定相关参数属性
Configuration conf = new Configuration();
//sequence file key、value
IntWritable key = new IntWritable();
Text value = new Text();
//构造Writer参数属性
SequenceFile.Writer writer = null;
CompressionCodec Codec = new GzipCodec();
SequenceFile.Writer.Option optPath = SequenceFile.Writer.file(new Path("hdfs://192.168.68.101:8020/seq.out"));
SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(key.getClass());
SequenceFile.Writer.Option optVal = SequenceFile.Writer.valueClass(value.getClass());
SequenceFile.Writer.Option optCom = SequenceFile.Writer.compression(SequenceFile.CompressionType.RECORD,Codec);
try {
writer = SequenceFile.createWriter( conf, optPath, optKey, optVal, optCom);
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253
运行结果:

最终输出的文件如下:

2.4.3 SequenceFileRead
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;
public class SequenceFileRead {
public static void main(String[] args) throws IOException {
//设置客户端运行身份 以root去操作访问HDFS
System.setProperty("HADOOP_USER_NAME","hadoop");
//Configuration 用于指定相关参数属性
Configuration conf = new Configuration();
SequenceFile.Reader.Option option1 = SequenceFile.Reader.file(new Path("hdfs://192.168.68.101:8020/seq.out"));
SequenceFile.Reader.Option option2 = SequenceFile.Reader.length(174);//这个参数表示读取的长度
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(conf,option1,option2);
Writable key = (Writable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";//是否返回了Sync Mark同步标记
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
123456789101112131415161718192021222324252627282930313233343536
运行结果:

2.5 案例:使用Sequence File合并小文件
2.5.1 理论依据
可以使用 Sequence File 对小文件合并,即将文件名作为key,文件内容作为value序列化到大文件中。例如,假设有 10,000 个 100KB 文件,那么我们可以编写一个程序将它们放入单个 Sequence File 中,如下所示,可以在其中使用 filename 作为键,并使用 content 作为值。
2.5.2 具体值
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.SequenceFile.Reader;
import org.apache.hadoop.io.SequenceFile.Writer;
import org.apache.hadoop.io.Text;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MergeSmallFilesToSequenceFile {
private Configuration configuration = new Configuration();
private List<String> smallFilePaths = new ArrayList<String>();
//定义方法用来添加小文件的路径
public void addInputPath(String inputPath) throws Exception{
File file = new File(inputPath);
//给定路径是文件夹,则遍历文件夹,将子文件夹中的文件都放入smallFilePaths
//给定路径是文件,则把文件的路径放入smallFilePaths
if(file.isDirectory()){
File[] files = FileUtil.listFiles(file);
for(File sFile:files){
smallFilePaths.add(sFile.getPath());
System.out.println("添加小文件路径:" + sFile.getPath());
}
}else{
smallFilePaths.add(file.getPath());
System.out.println("添加小文件路径:" + file.getPath());
}
}
//把smallFilePaths的小文件遍历读取,然后放入合并的sequencefile容器中
public void mergeFile() throws Exception{
Writer.Option bigFile = Writer.file(new Path("D:\\datasets\\bigfile"));
Writer.Option keyClass = Writer.keyClass(Text.class);
Writer.Option valueClass = Writer.valueClass(BytesWritable.class);
//构造writer
Writer writer = SequenceFile.createWriter(configuration, bigFile, keyClass, valueClass);
//遍历读取小文件,逐个写入sequencefile
Text key = new Text();
for(String path:smallFilePaths){
File file = new File(path);
long fileSize = file.length();//获取文件的字节数大小
byte[] fileContent = new byte[(int)fileSize];
FileInputStream inputStream = new FileInputStream(file);
inputStream.read(fileContent, 0, (int)fileSize);//把文件的二进制流加载到fileContent字节数组中去
String md5Str = DigestUtils.md5Hex(fileContent);
System.out.println("merge小文件:"+path+",md5:"+md5Str);
key.set(path);
//把文件路径作为key,文件内容做为value,放入到sequencefile中
writer.append(key, new BytesWritable(fileContent));
}
writer.hflush();
writer.close();
}
//读取大文件中的小文件
public void readMergedFile() throws Exception{
Reader.Option file = Reader.file(new Path("D:\\bigfile.seq"));
Reader reader = new Reader(configuration, file);
Text key = new Text();
BytesWritable value = new BytesWritable();
while(reader.next(key, value)){
byte[] bytes = value.copyBytes();
String md5 = DigestUtils.md5Hex(bytes);
String content = new String(bytes, Charset.forName("GBK"));
System.out.println("读取到文件:"+key+",md5:"+md5+",content:"+content);
}
}
public static void main(String[] args) throws Exception {
MergeSmallFilesToSequenceFile msf = new MergeSmallFilesToSequenceFile();
//合并小文件
msf.addInputPath("D:\\datasets\\smallfile");
msf.mergeFile();
//读取大文件
// msf.readMergedFile();
}
}
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788

HDFS Trash垃圾回收详解
1. Trash垃圾回收
1.1 背景
回收站(垃圾桶)是微软 Windows 操作系统里的一个系统文件夹,主要用来存放用户临时删除的文档资料,存放在回收站的文件可以恢复。
回收站的功能给了我们一剂 “后悔药”。回收站保存了删除的文件、文件夹、图片、快捷方式等。这些项目将一直保留在回收站中,直到您清空回收站。我们许多误删除的文件就是从它里面找到的。
HDFS 本身也是一个文件系统,那么就会涉及到文件数据的删除操作。默认情况下,HDFS中是没有回收站垃圾桶概念的,删除操作的数据将会被直接删除,没有后悔药。
1.2 功能概述
Trash机制,叫做回收站或者垃圾桶。Trash 就像 Windows 操作系统中的回收站一样。它的目的是防止你无意中删除某些东西。默认情况下是不开启的。
启用 Trash 功能后,从 HDFS 中删除某些内容时,文件或目录不会立即被清除,它们将被移动到回收站Current目录中(/user/${username}/.Trash/current)。
.Trash中的文件在用户可配置的时间延迟后被永久删除。也可以简单地将回收站里的文件移动到.Trash目录之外的位置来恢复回收站中的文件和目录。
1.2.1 Trash Checkpoint
检查点仅仅是用户回收站下的一个目录,用于存储在创建检查点之前删除的所有文件或目录。如果你想查看回收站目录,可以在/user/${username}/.Trash/{timestamp_of_checkpoint_creation}处看到:
最近删除的文件被移动到回收站 Current 目录,并且在可配置的时间间隔内,HDFS 会为在 Current 回收站目录下的文件创建检查点/user/${username}/.Trash/<日期>,并在过期时删除旧的检查点。

1.3 功能开启
1.3.1 关闭HDFS集群
在 hadoop1 节点上,执行一键关闭 HDFS 集群命令:stop-dfs.sh。

1.3.2 修改core-site.xml文件
在 hadoop1 节点上修改core-site.xml文件,添加下面两个属性:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
12345678
fs.trash.interval:分钟数,当超过这个分钟数后检查点会被删除。如果为零,Trash 回收站功能将被禁用。
fs.trash.checkpoint.interval:检查点创建的时间间隔(单位为分钟)。其值应该小于或等于fs.trash.interval。如果为零,则将该值设置为fs.trash.interval的值。每次运行检查点时,它都会从当前版本中创建一个新的检查点,并删除在数分钟之前创建的检查点。
1.3.3 同步集群配置文件
scp /data/hadoop-3.3.1/etc/hadoop/core-site.xml hadoop@192.168.68.102:/data/hadoop-3.3.1/etc/hadoop/
scp /data/hadoop-3.3.1/etc/hadoop/core-site.xml hadoop@192.168.68.103:/data/hadoop-3.3.1/etc/hadoop/
12
1.3.4 启动HDFS集群
在 hadoop1 节点上,执行一键启动 HDFS 集群命令:start-dfs.sh。
1.4 功能使用
1.4.1 删除文件到Trash
开启 Trash 功能后,正常执行删除操作,文件实际并不会被直接删除,而是被移动到了垃圾回收站。


1.4.2 删除文件跳过Trash
有的时候,我们希望直接把文件删除,不需要再经过 Trash 回收站了,可以在执行删除操作的时候添加一个参数:-skipTrash
hadoop fs -rm -skipTrash /input/2.txt

1.4.3 从Trash中恢复文件
回收站里面的文件,在到期被自动删除之前,都可以通过命令恢复出来。使用 mv、cp 命令把数据文件从 Trash 目录下复制移动出来就可以了。
hadoop fs -mv /user/hadoop/.Trash/Current/input/* /input/

1.4.4 清空Trash
除了fs.trash.interval参数控制到期自动删除之外,用户还可以通过命令手动清空回收站,释放 HDFS 磁盘存储空间。
首先想到的是删除整个回收站目录,将会清空回收站,这是一个选择。此外。HDFS 提供了一个命令行工具来完成这个工作:
hadoop fs -expunge
该命令立即从文件系统中删除过期的检查点。

HDFS Snapshot快照详解
1. Snapshot快照
1.1 快照介绍和作用
HDFS snapshot是HDFS整个文件系统,或者某个目录在某个时刻的镜像。该镜像并不会随着源目录的改变而进行动态的更新。可以将快照理解为拍照片时的那一瞬间的投影,过了那个时间之后,又会有新的一个投影。
HDFS 快照的核心功能包括:数据恢复、数据备份、数据测试。
1.1.1 数据恢复
可以通过滚动的方式来对重要的目录进行创建 snapshot 的操作,这样在系统中就存在针对某个目录的多个快照版本。当用户误删除掉某个文件时,可以通过最新的 snapshot 来进行相关的恢复操作。
1.1.2 数据备份
可以使用 snapshot 来进行整个集群,或者某些目录、文件的备份。管理员以某个时刻的 snapshot 作为备份的起始结点,然后通过比较不同备份之间差异性,来进行增量备份。
1.1.3 数据测试
在某些重要数据上进行测试或者实验,可能会直接将原始的数据破坏掉。可以临时的为用户针对要操作的数据来创建一个 snapshot,然后让用户在对应的 snapshot 上进行相关的实验和测试,从而避免对原始数据的破坏。
1.2 HDFS快照的实现
在了解 HDFS 快照功能如何实现之前,首先有一个根本的原则需要记住:快照不是数据的简单拷贝,快照只做差异的记录。这一原则在其他很多系统的快照概念中都是适用的,比如磁盘快照,也是不保存真实数据的。因为不保存实际的数据,所以快照的生成往往非常迅速。
在 HDFS 中,如果在其中一个目录比如/A下创建一个快照,则快照文件中将会存在与/A目录下完全一致的子目录文件结构以及相应的属性信息,通过命令也能看到快照里面具体的文件内容。但是这并不意味着快照已经对此数据进行完全的拷贝 。这里遵循一个原则:对于大多不变的数据,你所看到的数据其实是当前物理路径所指的内容,而发生变更的inode数据才会被快照额外拷贝,也就是所说的差异拷贝。
inode 译成中文就是索引节点,它用来存放文件及目录的基本信息,包含时间、名称、拥有者、所在组等信息。
HDFS 快照不会复制 datanode 中的块,只记录了块列表和文件大小。
HDFS 快照不会对常规 HDFS 操作产生不利影响,修改记录按逆时针顺序进行,因此可以直接访问当前数据。通过从当前数据中减去修改来计算快照数据。
1.3 快照的命令
1.3.1 快照功能启停命令
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs dfsadmin
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.
[-report [-live] [-dead] [-decommissioning] [-enteringmaintenance] [-inmaintenance]]
[-safemode <enter | leave | get | wait | forceExit>]
[-saveNamespace [-beforeShutdown]]
[-rollEdits]
[-restoreFailedStorage true|false|check]
[-refreshNodes]
[-setQuota <quota> <dirname>...<dirname>]
[-clrQuota <dirname>...<dirname>]
[-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>]
[-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
[-finalizeUpgrade]
[-rollingUpgrade [<query|prepare|finalize>]]
[-upgrade <query | finalize>]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue]
[-refresh <host:ipc_port> <key> [arg1..argn]
[-reconfig <namenode|datanode> <host:ipc_port> <start|status|properties>]
[-printTopology]
[-refreshNamenodes datanode_host:ipc_port]
[-getVolumeReport datanode_host:ipc_port]
[-deleteBlockPool datanode_host:ipc_port blockpoolId [force]]
[-setBalancerBandwidth <bandwidth in bytes per second>]
[-getBalancerBandwidth <datanode_host:ipc_port>]
[-fetchImage <local directory>]
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
[-shutdownDatanode <datanode_host:ipc_port> [upgrade]]
[-evictWriters <datanode_host:ipc_port>]
[-getDatanodeInfo <datanode_host:ipc_port>]
[-metasave filename]
[-triggerBlockReport [-incremental] <datanode_host:ipc_port> [-namenode <namenode_host:ipc_port>]]
[-listOpenFiles [-blockingDecommission] [-path <path>]]
[-help [cmd]]
1234567891011121314151617181920212223242526272829303132333435363738
HDFS 中可以针对整个文件系统或者文件系统中某个目录创建快照,但是创建快照的前提是相应的目录开启快照的功能。
如果针对没有启动快照功能的目录创建快照则会报错:

启用快照功能:
hdfs dfsadmin -allowSnapshot /input
禁用快照功能:
hdfs dfsadmin -disallowSnapshot /input
1.3.2 快照操作相关命令
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate] [-fs <path>]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP (yyyyMMdd:HHmmss) ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs lsSnapshottableDir
[hadoop@hadoop1 hadoop-3.3.1]$ hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
快照相关的操作命令有:createSnapshot创建快照、deleteSnapshot删除快照、renameSnapshot重命名快照、lsSnapshottableDir列出可以快照目录列表、snapshotDiff获取快照差异报告。
1.4 案例:快照的使用
-
开启指定目录的快照
hdfs dfsadmin -allowSnapshot /input

-
对指定目录创建快照
hdfs dfs -createSnapshot /input,系统自动生成快照名称
hdfs dfs -createSnapshot /input mysnap1,指定名称创建快照

通过web浏览器访问快照:

-
重命名快照
hdfs dfs -renameSnapshot /input mysnap1 mysnap2

-
列出当前用户所有可以快照的目录
hdfs lsSnapshottableDir

-
比较两个快照不同之处
[hadoop@hadoop1 input]$ echo 222 > 2.txt [hadoop@hadoop1 input]$ hadoop fs -appendToFile 2.txt /input/1.txt [hadoop@hadoop1 input]$ hadoop fs -cat /input/1.txt hello hadoop stream data flink spark 222 [hadoop@hadoop1 input]$ hdfs dfs -createSnapshot /input mysnap3 Created snapshot /input/.snapshot/mysnap3 [hadoop@hadoop1 input]$ hadoop fs -put 2.txt /input [hadoop@hadoop1 input]$ hdfs dfs -createSnapshot /input mysnap4 Created snapshot /input/.snapshot/mysnap4 123456789101112+The file/directory has been
created.
-The file/directory has been
deleted.
MThe file/directory has been
modified.
RThe file/directory has been
renamed.
-
删除快照
hdfs dfs -deleteSnapshot /input mysnap4

-
删除有快照的目录
hadoop fs -rm -r /input

拥有快照的目录不允许被删除,某种程度上也保护了文件安全。
HDFS权限管理
1. 总览概述
作为分布式文件系统,HDFS 也集成了一套兼容 POSIX 的权限管理系统。客户端在进行每次文件操时,系统会从用户身份认证和数据访问授权两个环节进行验证: 客户端的操作请求会首先通过本地的用户身份验证机制来获得 “凭证”(类似于身份证书),然后系统根据此 “凭证” 分辨出合法的用户名,再据此查看该用户所访问的数据是否已经授权。一旦这个流程中的某个环节出现异常,客户端的操作请求便会失败。

2. UGO权限管理
2.1 介绍
HDFS 的文件权限与 Linux/Unix 系统的 UGO 模型类型类似,可以简单描述为:每个文件和目录都与一个所有者和一个组相关联。该文件或目录对作为所有者(USER)的用户,作为该组成员的其他用户(GROUP)以及对所有其他用户(OTHER)具有单独的权限。

在 HDFS 中,对于文件,需要r权限才能读取文件,而w权限才能写入或追加到文件。没有x可执行文件的概念。
对于目录,需要r权限才能列出目录的内容,需要w权限才能创建或删除文件或目录,并且需要x权限才能访问目录的子级。
2.2 umask权限掩码
Linux 中umask可用来设定权限掩码。权限掩码是由 3 个八进制的数字所组成,将现有的存取权限减掉权限掩码后,即可产生建立文件时预设的权限。
与 Linux/Unix 系统类似,HDFS 也提供了 umask 掩码,用于设置在 HDFS 中默认新建的文件和目录权限位。默认 umask 值有属性fs.permissions.umask-mode指定,默认值 022。
创建文件和目录时使用的 umask,默认的权限就是:777-022=755。也就是drwxr-xr-x。
2.3 UGO权限相关命令
hadoop fs -chmod 750 /user/itcast/foo,变更目录或文件的权限位
hadoop fs -chown :portal /user/itcast/foo,变更目录或文件的属主或用户组
hadoop fs -chgrp itcast _group1 /user/itcast/foo,变更用户组
需要注意的是,使用这个命令的用户必须是超级用户,或者是该文件的属主,同时也是该用户组的成员。
2.4 Web页面修改UGO权限
Hadoop3.0 之后,支持在 HDFS Web 页面上使用鼠标修改。

粘滞位(Sticky bit)用法在目录上设置,如此以来,只有目录内文件的所有者或者root才可以删除或移动该文件。如果不为目录设置粘滞位,任何具有该目录写和执行权限的用户都可以删除和移动其中的文件。实际应用中,粘滞位一般用于/tmp目录,以防止普通用户删除或移动其他用户的文件。

3. 用户身份认证
用户身份认证独立于 HDFS 之外,也就说 HDFS 并不负责用户身份合法性检查,但 HDFS 会通过相关接口来获取相关的用户身份,然后用于后续的权限管理。用户是否合法,完全取决于集群使用认证体系。目前社区支持两种身份认证,即简单认证(Simple)和Kerberos。模式由hadoop.security.authentication属性指定,默认simple。
3.1 Simple认证
基于客户端所在的Linux/Unix系统的登录用户名来进行认证。只要用户能正常登录就认证成功。客户端与 NameNode 交互时,会将用户的登录账号(通过类似 whoami 的命令来获取)作为合法用户名传递至 Namenode。 这意味着使用不同的账号登录到同一个客户端,会产生不同的用户名,故在多租户条件这种认证会导致权限混淆;同时恶意用户也可以伪造其他人的用户名非法获得相应的权限,对数据安全造成极大的隐患。线上生产环境一般不会使用。simple 认证时,HDFS 想法是:防止好人误做坏事,不防止坏人做坏事。

3.2 Kerberos认证
在神话里,Kerberos 是 Cerberus 的希腊语,是一只守护地狱入口的三头巨犬,它确保没有人能在进入地狱后离开。
从技术角度来说,Kerberos 是麻省理工学院(MIT)开发的一种网络身份认证协议。它旨在通过使用密钥加密技术为客户端/服务器应用程序提供强身份验证。



4. Group Mapping组映射
在用户身份验证成功之后,接下来会检查该用户所拥有的权限。HDFS 的文件权限也是采用 UGO 模型,分成用户、组和其他权限。但与 Linux/Unix 系统不同,HDFS 的用户和组都是使用字符串存储的,在 Linux/Unix 上通用的 UID 和 GID 是无法在 HDFS 使用的。
此外,HDFS的组需要通过外部的用户组关联(Group Mapping)服务来获取。用户到组的映射可以使用系统自带的方案(使用 NameNode 服务器上的用户组系统),也可以通过其他实现类似功能的插件(LDAP、Ranger等)方式来代替。在拿到用户名后,NameNode 会通过用户组关联服务获取该用户所对应的用户组列表,并用于后期的用户组权限校验。下面是两种主要的实现方式 。
4.1 基于Linux/Unix系统的用户和用户组
Linux/Unix 系统上的用户和用户组信息存储在/etc/passwd和/etc/group文件中。默认情况下,HDFS 会通过调用外部的 Shell 命令来获取用户的所有用户组列表。 此方案的优点在于组映射服务十分稳定,不易受外部服务的影响。但是用户和用户组管理涉及到root权限等,同时会在服务器上生成大量的用户组,后续管理,特别是自动化运维方面会有较大影响。

4.2 基于使用LDAP协议的数据库
OpenLDAP 是一个开源 LDAP 的数据库,通过 phpLDAPadmin 等管理工具或相关接口可以方便地添加用户和修改用户组。HDFS 可以使用 LdapGroupsMappings 来使用 LDAP 服务。通过配置 LDAP 的相关属性,可以通过接口来直接获取到某个用户所有的用户组列表(memberOf)。 使用 LDAP 的不足在于需要保障 LDAP 服务的可用性和性能,关于 LDAP 的管理和使用将会后续再作介绍。 不同的 LDAP 有不同的实现,需要使用不同类型的 LDAP Schema 来构建,譬如示例中使用的是 Person 和 GroupOfNames 类型而不是 PosixAccount 和 PosixGroup 类型 以下是开启 LDAP 关联的配置文件:
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.LdapGroupsMapping</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.user</name>
<value>cn=Manager,dc=hadoop,dc=apache,dc=org</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.password</name>
<value>hadoop</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.url</name>
<value>ldap://localhost:389/dc=hadoop,dc=apache,dc=org</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.url</name>
<value>ldap://localhost:389/dc=hadoop,dc=apache,dc=org</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.base</name>
<value></value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.user</name>
<value>(&(|(objectclass=person)(objectclass=applicationProcess))(cn={0}))</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.group</name>
<value>(objectclass=groupOfNames)</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.member</name>
<value>member</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.group.name</name>
<value>cn</value>
</property>
12345678910111213141516171819202122232425262728293031323334353637383940
5. ACL权限管理
5.1 背景和介绍
在 UGO 权限中,用户对文件只有三种身份,就是属主(user)、属组(group)和其他人(other):每种用户身份拥有读(read)、写(write)和执行(execute)三种权限。但是在实际工作中,使用 UGO 来控制权限可以满足大部分场景下的数据安全性要求,但是对于一些复杂的权限需求则无能为力。

文件系统根目录中有一个/project目录,这是班级的项目目录。班级中的每个学员都可以访问和修改这个目录,老师也需要对这个目录拥有访问和修改权限,其他班级的学员当然不能访问这个目录。需要怎么规划这个目录的权限呢?应该这样:老师使用 root 用户,作为这个目录的属主,权限为 rwx;班级所有的学员都加入 tgroup 组,使 tgroup 组作为/project目录的属组,权限是 rwx;其他人的权限设定为 0。这样这个目录的权限就可以符合我们的项目开发要求了。
有一天,班里来了一位试听的学员 st,她必须能够访问/project 目录,所以必须对这个目录拥有 r 和 x 权限;但是她又没有学习过以前的课程,所以不能赋予她 w 权限,怕她改错了目录中的内容,所以学员 st 的权限就是 r-x。可是如何分配她的身份呢?变为属主?当然不行,要不 root 该放哪里?加入 tgroup 组?也不行,因为 tgroup 组的权限是 rwx,而我们要求学员 st 的权限是 r-x。如果把其他人的权限改为 r-x 呢?这样一来,其他班级的所有学员都可以访问/project目录了。
当出现这种情况时,普通权限中的三种身份就不够用了。ACL 权限就是为了解决这个问题的。在使用 ACL 权限给用户 st 陚予权限时,st 既不是/project目录的属主,也不是属组,仅仅赋予用户 st 针对此目录的 r-x 权限。
ACL是Access Control List(访问控制列表)的缩写,ACL提供了一种方法,可以为特定的用户或组设置不同的权限,而不仅仅是文件的所有者和文件的组。
5.2 ACL Shell命令
hadoop fs -getfacl [-R] <path>
显示文件和目录的访问控制列表(ACL)。如果目录具有默认 ACL,则 getfacl 还将显示默认 ACL。
hadoop fs [generic options] -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]
设置文件和目录的访问控制列表(ACL)。
hadoop fs -ls <args>
ls 的输出将在带有 ACL 的任何文件或目录的权限字符串后附加一个 ‘+’ 字符。
5.3 ACL操作实战
hadoop 用户创建文件夹:hadoop fs -mkdir /itheima
此时使用普通用户 test 去操作/itheima,发现没有w权限
[test@hadoop1 ~]$ echo 1 >> 1.txt
[test@hadoop1 ~]$ hadoop fs -put 1.txt /itheima
put: Permission denied: user=test, access=WRITE, inode="/itheima":hadoop:supergroup:drwxr-xr-x
123
接下来使用 ACL 给 test 用户单独添加rwx权限
[test@hadoop1 ~]$ hadoop fs -setfacl -m user:test:rwx /itheima
setfacl: Permission denied. user=test is not the owner of inode=/itheima
12
发现报错 原因是ACL功能默认是关闭的。
在hdfs-site.xml中设置dfs.namenode.acls.enabled=true开启 ACL,并重启 HDFS 集群
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
1234
再次设置 ACL 权限
hadoop fs -setfacl -m user:test:rwx /itheima
1
设置成功之后查看 ACL 权限
[hadoop@hadoop1 test]$ hadoop fs -getfacl /itheima
# file: /itheima
# owner: hadoop
# group: supergroup
user::rwx
user:test:rwx #发现test权限配置成功
group::r-x
mask::rwx
other::r-x
123456789
再使用普通用户 test 去操作,发现可以成功了
如果切换其他普通用户 发现还是无法操作
[test1@hadoop1 ~]$ echo 2 >> 2.txt
[test1@hadoop1 ~]$ hadoop fs -put 2.txt /itheima
put: Permission denied: user=test1, access=WRITE, inode="/itheima":hadoop:supergroup:drwxrwxr-x
123
ACL其他操作命令:
- 带有 ACL 的任何文件或目录的权限字符串后附加一个 ‘+’ 字符
[hadoop@hadoop1 hadoop-3.3.1]$ hadoop fs -ls /
Found 13 items
drwxr-xr-x - hadoop supergroup 0 2022-01-11 15:25 /benchmarks
drwxr-xr-x - hadoop supergroup 0 2022-01-13 14:45 /data
drwxr-xr-x - hadoop supergroup 0 2022-01-12 13:09 /hdfsapi
drwxr-xr-x - hadoop supergroup 0 2022-01-24 16:52 /input
drwxrwxr-x+ - hadoop supergroup 0 2022-01-25 10:10 /itheima
drwxr-xr-x - hadoop supergroup 0 2022-01-24 11:31 /outputdir
-rw-r--r-- 3 hadoop supergroup 5945 2022-01-24 15:02 /seq.out
drwxr-xr-x - hadoop supergroup 0 2022-01-24 11:24 /smallfile
drwxr-xr-x - hadoop supergroup 0 2022-01-24 14:29 /smallfile1
drwxr-xr-x - hadoop supergroup 0 2022-01-12 17:07 /test
drwxr-xr-x - hadoop supergroup 0 2022-01-13 19:53 /test1
drwx------ - hadoop supergroup 0 2022-01-11 13:34 /tmp
drwxr-xr-x - hadoop supergroup 0 2022-01-11 12:15 /user
123456789101112131415
- 删除指定的 ACL 条目
hadoop fs -setfacl -x user:test /itheima
1
- 删除基本 ACL 条目以外的所有条目。保留用户,组和其他条目以与权限位兼容。
hadoop fs -setfacl -b /itheima
1
- 设置默认的 ACL 权限,以后在该目录中新建文件或者子目录时,新建的文件/目录的 ACL 权限都是之前设置的 default ACLs
[hadoop@hadoop1 hadoop-3.3.1]$ hadoop fs -setfacl -m default:user:test:rwx /itheima
[hadoop@hadoop1 hadoop-3.3.1]$ hadoop fs -getfacl /itheima
# file: /itheima
# owner: hadoop
# group: supergroup
user::rwx
group::r-x
mask::r-x
other::r-x
default:user::rwx
default:user:test:rwx
default:group::r-x
default:mask::rwx
default:other::r-x
1234567891011121314
- 删除默认 ACL 权限
hadoop fs -setfacl -k /itheima
1
--set: 完全替换 ACL,丢弃所有现有条目。 acl_spec 必须包含用户,组和其他条目,以便与权限位兼容。
hadoop fs -setfacl --set user::rw-,user:hadoop:rw-,group::r--,other::r-- /file
1
HDFS Transparent Encryption透明加密
见Hadoop生态圈(十八)- HDFS Transparent Encryption透明加密_hdfs encryption 怎么做-CSDN博客
HDFS核心源码详解
1. HDFS源码结构分析
1.1 IDEA导入HDFS源码工程
解压Hadoop源码在Windows某个目录下(该目录最好没有中文没有空格)。

打开 IDEA,选择Open or Import

选择 HDFS 工程打开

初次导入 IDEA 会自动根据 POM 依赖下载插件和依赖,此时静静等待即可。确保下载完成。
1.2 HDFS工程结构
hadoop-hdfs-project工程目录结构如下:

1.2.1 hadoop-hdfs
在hadoop-hdfs模块中,主要实现了网络、传输协议、JN、安全、server服务等相关功能。是 hdfs 的核心模块。并且提供了 hdfs web UI 页面功能的支撑。


1.2.2 hadoop-hdfs-client
在hadoop-hdfs-client模块中,主要定义实现了和 hdfs 客户端相关的功能逻辑。

1.2.3 hadoop-hdfs-httpfs
hadoop-hdfs-httpfs模块主要实现了通过HTTP协议操作访问hdfs文件系统的相关功能。HttpFS 是一种服务器,它提供到 HDFS 的 REST HTTP 网关,具有完整的文件系统读写功能。
HttpFS 可用于在运行不同Hadoop版本的群集之间传输数据(克服 RPC 版本问题),例如使用 Hadoop DistCP。

1.2.4 hadoop-hdfs-native-client
hadoop-hdfs-native-client模块定义了hdfs访问本地库的相关功能和逻辑。该模块主要是使用 C 语言进行编写,用于和本地库进行交互操作。

1.2.5 hadoop-hdfs-nfs
hadoop-hdfs-nfs模块是Hadoop HDFS的NFS实现。

1.2.6 hadoop-hdfs-rbf
hadoop-hdfs-rbf模块是 hadoop3.0 之后的一个新的模块。主要实现了 RBF 功能。RBF 是 Router-based Federation 简称,翻译中文叫做:基于路由的 Federation 方案。
简单来说就是:HDFS 将路由信息放在了服务端来处理,而不是在客户端。以此完全做到对于客户端的透明。

2. HDFS核心源码解析
2.1 HDFS客户端核心类
2.1.1 Configuration
源码注释中对于Configuration类是这么描述的:

Configuration提供对配置参数的访问,通常称之为配置文件类。主要用于加载或者设定程序运行时相关的参数属性。
2.1.1.1 Configuration加载默认配置
在程序中打上断点,看一下新建Configuration对象的时候加载了什么:

按下F7进入方法内部,再一次次按下F8,执行过程中可以发现,首先加载了静态方法和静态代码块,其中在静态代码块中显示默认加载了两个配置文件:
core-default.xml以及core-site.xml

2.1.1.2 Configuration加载用户设置
按下shift+F8,跳出Configuration类的创建,按F8执行下一步,当到达FileSystem.get(conf)这一行代码的时候,可以发现用户通过conf.set设置的属性也会被加载。


2.1.2 FileSystem
源码注释中对于FileSystem类是这么描述的:

简单翻译下:FileSystem类是一个通用的文件系统的抽象基类。具体来说它可以实现为一个分布式的文件系统,也可以实现为一个本地文件系统。所有的可能会使用到 HDFS 的用户代码在进行编写时都应该使用 FileSystem 对象。
代表本地文件系统的实现是 LocalFileSystem,代表分布式文件系统的实现是DistributedFileSystem。当然针对其他 hadoop 支持的文件系统也有不同的具体实现。
因此 HDFS 客户端在进行读写操作之前,需要创建 FileSystem 对象的实例。
2.1.2.1 获取FileSystem实例
将断点达到如下的位置,debug 运行程序:

经过方法的层层调用,最终找到了FileSystem对象是通过调用getInternal方法得到的。

首先在getInternal方法中调用了createFileSystem方法,进去该方法:
原来,FileSystem实例是通过反射的方式获得的,具体实现是通过调用反射工具类ReflectionUtils的newInstance方法并将 class 对象以及Configuration对象作为参数传入最终得到了FileSystem实例。

2.2 HDFS通信协议
2.2.1 概述
HDFS 作为一个分布式文件系统,它的某些流程是非常复杂的(例如读、写文件等典型流程),常常涉及数据节点、名字节点和客户端三者之间的配合、相互调用才能实现。为了降低节点间代码的耦合性,提高单个节点代码的内聚性, HDFS 将这些节点间的调用抽象成不同的接口。
HDFS 节点间的接口主要有两种类型:
Hadoop RPC接口:基于 Hadoop RPC 框架实现的接口;
流式接口:基于TCP或者HTTP实现的接口;
2.2.2 Hadoop RPC接口
2.2.2.1 RPC介绍
RPC全称Remote Procedure Call——远程过程调用。就是为了解决远程调用服务的一种技术,使得调用者像调用本地服务一样方便透明。

通信模块:传输 RPC 请求和响应的网络通信模块,可以基于 TCP 协议,也可以基于 UDP 协议,可以是同步,也可以是异步的。
客户端 Stub 程序:服务器和客户端都包括 Stub 程序。在客户端,Stub 程序表现的就像本地程序一样,但底层却会将调用请求和参数序列化并通过通信模块发送给服务器。之后 Stub 程序等待服务器的响应信息,将响应信息反序列化并返回给请求程序。
服务器端 Stub 程序:在服务器端,Stub 程序会将远程客户端发送的调用请求和参数反序列化,根据调用信息触发对应的服务程序,然后将服务程序返回的响应信息序列化并发回客户端。
请求程序:请求程序会像调用本地方法一样调用客户端 Stub 程序,然后接收 Stub 程序返回的响应信息。
服务程序:服务器会接收来自 Stub 程序的调用请求,执行对应的逻辑并返回执行结果。
Hadoop RPC调用使得HDFS进程能够像本地调用一样调用另一个进程中的方法,并且可以传递Java基本类型或者自定义类作为参数,同时接收返回值。如果远程进程在调用过程中出现异常,本地进程也会收到对应的异常。目前Hadoop RPC调用是基于Protobuf实现的。
Hadoop RPC 接口主要定义在org.apache.hadoop.hdfs.protocol包和org.apache.hadoop.hdfs.server.protocol包中,核心的接口有:
ClientProtocol、ClientDatanodeProtocol、DatanodeProtocol。
2.2.2.2 ClientProrocol
ClientProtocol定义了客户端与名字节点间的接口,这个接口定义的方法非常多,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与 Namenode 协商之后,再进行数据块的读出和写入操作。
ClientProtocol 定义了所有由客户端发起的、由 Namenode 响应的操作。这个接口非常大,有 80 多个方法,核心的是:HDFS文件读相关的操作、HDFS文件写以及追加写的相关操作。
- 读数据相关的方法
ClientProtocol 中与客户端读取文件相关的方法主要有两个: getBlockLocations()和reportBadBlocks()。
客户端会调用ClientProtocol.getBlockLocations()方法获取 HDFS 文件指定范围内所有数据块的位置信息。这个方法的参数是 HDFS 文件的文件名以及读取范围,返回值是文件指定范围内所有数据块的文件名以及它们的位置信息,使用LocatedBlocks对象封装。每个数据块的位置信息指的是存储这个数据块副本的所有 Datanode 的信息,这些 Datanode 会以与当前客户端的距离远近排序。客户端读取数据时,会首先调用getBlockLocations()方法获取 HDFS 文件的所有数据块的位置信息,然后客户端会根据这些位置信息从数据节点读取数据块。

客户端会调用ClientProtocol.reportBadBlocks()方法向 Namenode 汇报错误的数据块。当客户端从数据节点读取数据块且发现数据块的校验和并不正确时,就会调用这个方法向 Namenode 汇报这个错误的数据块信息。

- 写、追加数据相关方法
在 HDFS 客户端操作中最重要的一部分就是写入一个新的 HDFS 文件,或者打开一个已有的 HDFS 文件并执行追加写操作。ClientProtocol 中定义了 8 个方法支持 HDFS 文件的写操作: create()、 append()、 addBlock()、 complete(), abandonBlock(),getAddtionnalDatanodes()、updateBlockForPipeline()和updatePipeline()。
create()方法用于在 HDFS 的文件系统目录树中创建一个新的空文件,创建的路径由 src 参数指定。这个空文件创建后对于其他的客户端是 “可读” 的,但是这些客户端不能删除、重命名或者移动这个文件,直到这个文件被关闭或者租约过期。客户端写一个新的文件时,会首先调用create方法在文件系统目录树中创建一个空文件,然后调用addBlock方法获取存储文件数据的数据块的位置信息,最后客户端就可以根据位置信息建立数据流管道,向数据节点写入数据了。

当客户端完成了整个文件的写入操作后,会调用complete()方法通知 Namenode。这个操作会提交新写入 HDFS 文件的所有数据块,当这些数据块的副本数量满足系统配置的最小副本系数(默认值为 1),也就是该文件的所有数据块至少有一个有效副本时, complete()方法会返回true,这时 Namenode 中文件的状态也会从构建中状态转换为正常状态;否则, complete会返回false,客户端就需要重复调用complete操作,直至该方法返回true 。

2.2.2.3 ClientDatanodeProtocol
客户端与数据节点间的接口。ClientDatanodeProtocol中定义的方法主要是用于客户端获取数据节点信息时调用,而真正的数据读写交互则是通过流式接口进行的。
ClientDatanodeProtocol中定义的接口可以分为两部分:一部分是支持 HDFS 文件读取操作的,例如getReplicaVisibleLength()以及getBlockLocalPathInf();另一部分是支持DFSAdmin中与数据节点管理相关的命令。我们重点关注第一部分。
- getReplicaVisibleLength
- 客户端会调用
getReplicaVisibleLength()方法从数据节点获取某个数据块副本真实的数据长度。当客户端读取一个 HDFS 文件时,需要获取这个文件对应的所有数据块的长度,用于建立数据块的输入流,然后读取数据。但是 Namenode 元数据中文件的最后一个数据块长度与 Datanode 实际存储的可能不一致,所以客户端在创建输入流时就需要调用getReplicaVisibleLength()方法从 Datanode 获取这个数据块的真实长度。

- 客户端会调用
- getBlockLocalPathInfo
- HDFS 对于本地读取,也就是 Client 和保存该数据块的 Datanode 在同一台物理机器上时,是有很多优化的。Client 会调用
ClientProtocol.getBlockLocalPathInf()方法获取指定数据块文件以及数据块校验文件在当前节点上的本地路径,然后利用这个本地路径执行本地读取操作,而不是通过流式接口执行远程读取,这样也就大大优化了读取的性能。
- HDFS 对于本地读取,也就是 Client 和保存该数据块的 Datanode 在同一台物理机器上时,是有很多优化的。Client 会调用
2.2.2.4 DatanodeProtocol
数据节点通过这个接口与名字节点通信,同时名字节点会通过这个接口中方法的返回值向数据节点下发指令。注意,这是名字节点与数据节点通信的唯一方式。这个接口非常重要,数据节点会通过这个接口向名字节点注册、汇报数据块的全量以及增量的存储情况。同时,名字节点也会通过这个接口中方法的返回值,将名字节点指令带回该数据块,根据这些指令,数据节点会执行数据块的复制、删除以及恢复操作。
可以将DatanodeProtocol定义的方法分为三种类型: Datanode启动相关、心跳相关以及数据块读写相关。
2.2.3 基于TCP/HTTP流式接口
HDFS 除了定义 RPC 调用接口外,还定义了流式接口,流式接口是 HDFS 中基于 TCP 或者 HTTP 实现的接口。在 HDFS 中,流式接口包括了基于 TCP 的DataTransferProtocol接口,以及 HA 架构中 Active Namenode 和 Standby Namenode 之间的 HTTP 接口。
2.2.3.1 DataTransferProtocol
DataTransferProtocol是用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS 客户端与数据节点以及数据节点与数据节点之间的数据块传输就是基于 DataTransferProtocol 接口实现的。HDFS 没有采用 Hadoop RPC 来实现 HDFS 文件的读写功能,是因为 Hadoop RPC 框架的效率目前还不足以支撑超大文件的读写,而使用基于 TCP 的流式接口有利于批量处理数据,同时提高了数据的吞吐量。
DataTransferProtocol 中最重要的方法就是 readBlock()和writeBlock()。
- readBlock:从当前 Datanode 读取指定的数据块。
- writeBlock:将指定数据块写入数据流管道(pipeLine)中。
DataTransferProtocol 接口调用并没有使用 Hadoop RPC 框架提供的功能,而是定义了用于发送 DataTransferProtocol 请求的 Sender 类,以及用于响应 DataTransferProtocol 请求的 Receiver 类。
Sender 类和 Receiver 类都实现了 DataTransferProtocol 接口。。我们假设 DFSClient 发起了一个 DataTransferProtocol.readBlock() 操作,那么 DFSClient 会调用 Sender 将这个请求序列化,并传输给远端的 Receiver。远端的 Receiver 接收到这个请求后,会反序列化请求,然后调用代码执行读取操作。

2.3 数据写入流程分析
2.3.1 写入流程图

2.3.2 写入数据代码
public class HDFSWriteDemo {
public static void main(String[] args) throws Exception{
//设置客户端用户身份:hadoop具备在hdfs读写权限
System.setProperty("HADOOP_USER_NAME","hadoop");
//创建Conf对象
Configuration conf = new Configuration();
//设置操作的文件系统是HDFS 默认是file:///
conf.set("fs.defaultFS","hdfs://192.168.68.101:8020");
//创建FileSystem对象 其是一个通用的文件系统的抽象基类
FileSystem fs = FileSystem.get(conf);
//设置文件输出的路径
Path path = new Path("/helloworld.txt");
//调用create方法创建文件
FSDataOutputStream out = fs.create(path);
//创建本地文件输入流
FileInputStream in = new FileInputStream("D:\\datasets\\hdfs\\helloworld.txt");
//IO工具类实现流对拷贝
IOUtils.copy(in,out);
//关闭连接
fs.close();
}
}
12345678910111213141516171819202122
2.3.3 写入数据流程梳理
2.3.3.1 客户端请求NameNode创建
HDFS 客户端通过对DistributedFileSystem对象调用create()请求创建文件。DistributedFileSystem为客户端返回FSDataOutputStream输出流对象。通过源码注释可以发现FSDataOutputStream是一个包装类,所包装的是DFSOutputStream。
可以通过create()方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是DFSOutputStream。

点击进入代码DFSOutputStream dfsos = dfs.create可以发现,DFSOutputStream这个类是从DFSClient类的create方法中返回过来的。

在DFSOutputStream dfsos = dfs.create打上断点,dubug。进来之后点进去发现,DFSClient类中的DFSOutputStream实例对象是通过调用DFSOutputStream类的newStreamForCreate方法产生的。

点击进入这个方法,找到了客户端请求 NameNode 新建元数据的关键代码。

2.3.3.2 NameNode执行请求检查
DistributedFileSystem对 namenode 进行RPC调用,请求上传文件。namenode 执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode 就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个IOException。
2.3.3.3 DataStreamer类
在之前的newStreamForCreate方法中,我们发现了最终返回的是out对象,并且在返回之前,调用了out对象的start方法。

点进start方法,发现调用的是DataStreamer对象的start方法。


DataStreamer类是DFSOutputSteam的一个内部类,在这个类中,有一个方法叫做run方法,数据写入的关键代码就在这个run方法中实现。

2.3.3.4 DataStreamer写数据
在客户端写入数据时,DFSOutputStream将它分成一个个数据包(packet 默认 64kb),并写入一个称之为数据队列(data queue)的内部队列。DataStreamer请求 NameNode 挑选出适合存储数据副本的一组 DataNode。这一组 DataNode 采用pipeline机制做数据的发送。默认是 3 副本存储。


DataStreamer将数据包流式传输到pipeline的第一个 datanode,该 DataNode 存储数据包并将它发送到pipeline的第二个 DataNode。同样,第二个 DataNode 存储数据包并且发送给第三个(也是最后一个) DataNode。

DFSOutputStream也维护着一个内部数据包队列来等待 DataNode 的收到确认回执,称之为确认队列(ack queue),收到pipeline中所有 DataNode 确认信息后,该数据包才会从确认队列删除。

客户端完成数据写入后,将在流上调用close()方法关闭。该操作将剩余的所有数据包写入 DataNode pipeline,并在联系到 NameNode 告知其文件写入完成之前,等待确认。
因为 namenode 已经知道文件由哪些块组成(DataStream 请求分配数据块),因此它仅需等待最小复制块即可成功返回。数据块最小复制是由参数dfs.namenode.replication.min指定,默认是 1。
2.4 数据读取流程分析
2.4.1 读取流程图

2.4.2 读取数据代码
public class HDFSReadDemo {
public static void main(String[] args) throws Exception{
//设置客户端用户身份:hadoop具备在hdfs读写权限
System.setProperty("HADOOP_USER_NAME","hadoop");
//创建Conf对象
Configuration conf = new Configuration();
//设置操作的文件系统是HDFS 默认是file:///
conf.set("fs.defaultFS","hdfs://192.168.68.101:8020");
//创建FileSystem对象 其是一个通用的文件系统的抽象基类
FileSystem fs = FileSystem.get(conf);
//调用open方法读取文件
FSDataInputStream in = fs.open(new Path("/helloworld.txt"));
//创建本地文件输出流
FileOutputStream out = new FileOutputStream("D:\\helloworld.txt");
//IO工具类实现流对拷贝
IOUtils.copy(in,out);
//关闭连接
fs.close();
}
}
1234567891011121314151617181920
2.4.3 读取数据流程梳理
2.4.3.1 客户端请求NameNode打开open
客户端通过调用DistributedFileSystem对象上的open()来打开希望读取的文件。DistributedFileSystem为客户端返回FSDataInputStream输入流对象。通过源码注释可以发现FSDataInputStream是一个包装类,所包装的是DFSInputStream。
可以通过open方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是DFSInputStream。

点击进入代码DFSInputStream dfsis = dfs.open()可以发现,DFSInputStream这个类是从DFSClient类的open方法中返回过来的。该输入流从 namenode 获取 block 的位置信息。

2.4.3.2 getLocatedBlocks
在上述open方法中,有一个核心方法调用叫做getLocatedBlocks,见名知意,该方法是用于获取块位置信息的。

点击方法进去之后发现,最终调用的是callGetBlockLocations:

继续点下去,发现最终调用的是getBlockLocations方法。

通过源码可以发现,getBlockLocations方法是位于ClientProtocol这个接口中。在ClientProtocol的注释上可以得出信息,这是客户端和 namenode 进行通信的。

2.4.3.3 NameNode返回块信息
DistributedFileSystem使用RPC调用 namenode 来确定文件中前几个块的块位置。对于每个块,namenode 返回具有该块副本的 datanode 的地址,并且 datanode 根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个 DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。
之前的getBlockLocations方法在源码注释上也描述了这段逻辑。

大致意思如下:获取指定范围内指定文件的块位置。 每个块的 DataNode 位置按与客户端的接近程度进行排序。返回LocatedBlocks,其中包含文件长度,块及其位置。 每个块的 DataNode 位置按到客户端地址的距离排序。然后,客户端将必须联系指示的 DataNode 之一以获得实际数据。
2.4.3.4 客户端读数据
DFSClient在获取到 block 的位置信息之后,继续调用openInternal方法。

点击进入该方法可以发现,分了两种不同的输入流。这取决于文件的存储策略是否采用 EC 纠删码。如果未使用EC编码策略存储,那么直接创建DFSInputStream。

最终将 block 位置信息保存到DFSInputStream输入流对象中的成员变量中返回给客户端。
客户端在DFSInputStream流上调用read()方法。然后DFSInputStream连接到文件中第一个块的最近的 DataNode 节点。通过对数据流反复调用read()方法,将数据从 DataNode 传输到客户端。当该块快要读取结束时,DFSInputStream将关闭与该 DataNode 的连接,然后寻找下一个块的最佳 datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问 NameNode 来检索下一批数据块的 DataNode 位置信息。一旦客户端完成读取,就对FSDataInputStream调用close()方法。
如果DFSInputStream与 DataNode 通信时遇到错误,它将尝试该块的下一个最接近的 DataNode 读取数据。并将记住发生故障的 DataNode,保证以后不会反复读取该 DataNode 后续的块。此外,DFSInputStream也会通过校验和(checksum)确认从 DataNode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream会尝试从其他 DataNode 读取该块的副本,也会将被损坏的块报告给 namenode 。
MapReduce入门与基础理论
1. 初识MapReduce
1.1 理解MapReduce思想
MapReduce 思想在生活中处处可见,每个人或多或少都曾接触过这种思想。MapReduce 的思想核心是 “先分再合,分而治之”, 所谓 “分而治之” 就是把一个复杂的问题,按照一定的 “分解” 方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果。
这种思想来源于日常生活与工作时的经验,同样也完全适用于大量复杂的任务处理场景(大规模数据处理场景)。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
Map 负责 “分”,即把复杂的任务分解为若干个 “简单的任务” 来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce 负责 “合”,即对 map 阶段的结果进行全局汇总。
这两个阶段合起来正是 MapReduce 思想的体现。
一个比较形象的语言解释MapReduce:
我们要数停车场中的所有的车数量。你数第一列,我数第二列。这就是 “Map”。我们人越多,能够同时数车的人就越多,速度就越快。
数完之后,我们聚到一起,把所有人的统计数加在一起。这就是 “Reduce”。
1.2 场景:如何模拟实现分布式计算
1.2.1 什么是分布式计算
分布式计算是一种计算方法,和集中式计算是相对的。
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。
分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。

1.2.2 大数据场景下模拟实现

1.3 Hadoop MapReduce设计构思
MapReduce 是 Hadoop 的一个模块,是一个分布式运算程序的编程框架。
对许多开发者来说,自己完完全全实现一个并行计算程序难度太大,而 MapReduce 就是一种简化并行计算的编程模型,降低了开发并行应用的入门门槛。
Hadoop MapReduce 构思体现在如下的三个方面。
1.3.1 如何对付大数据处理
对相互间不具有计算依赖关系的大数据计算任务,实现并行最自然的办法就是采取MapReduce分而治之的策略。
也就是 Map 阶段分的阶段,把大数据拆分成若干份小数据,多个程序同时并行计算产生中间结果;然后是 Reduce 聚合阶段,通过程序对并行的结果进行最终的汇总计算,得出最终的结果。
并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!

1.3.2 构建抽象模型
MapReduce 借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
Map:对一组数据元素进行某种重复式的处理;

Reduce:对 Map 的中间结果进行某种进一步的结果整理。

MapReduce 中定义了如下的 Map 和 Reduce 两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map 和 Reduce 为程序员提供了一个清晰的操作接口抽象描述。通过以上两个编程接口,大家可以看出 MapReduce 处理的数据类型是<key,value>键值对。
1.3.3 统一架构、隐藏底层细节
如何提供统一的计算框架,如果没有统一封装底层细节,那么程序员则需要考虑诸如数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce 设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
MapReduce 最大的亮点在于通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架。
程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
2. Hadoop MapReduce简介
2.1 MapReduce介绍
Hadoop MapReduce是一个分布式运算程序的编程框架,用于轻松编写应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多 TB 数据集)。
MapReduce 是一种面向海量数据处理的一种指导思想,也是一种用于对大规模数据进行分布式计算的编程模型。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
MapReduce 最早由 Google 于 2004 年在一篇名为《MapReduce:Simplified Data Processingon Large Clusters》的论文中提出,把分布式数据处理的过程拆分为 Map 和 Reduce 两个操作函数(受到 Lisp 以及其他函数式编程语言的启发),随后被 Apache Hadoop 参考并作为开源版本提供支持。它的出现解决了人们在最初面临海量数据束手无策的问题,同时,它还是易于使用和高度可扩展的,使得开发者无需关系分布式系统底层的复杂性即可很容易的编写分布式数据处理程序,并在成千上万台普通的商用服务器中运行。

2.2 MapReduce特点
- 易于编程
- Mapreduce 框架提供了用于二次开发得接口;简单地实现一些接口,就可以完成一个分布式程序。任务计算交给计算框架去处理,将分布式程序部署到 hadoop 集群上运行,集群节点可以扩展到成百上千个等。
- 良好的扩展性
- 当计算机资源不能得到满足的时候,可以通过增加机器来扩展它的计算能力。基于 MapReduce 的分布式计算得特点可以随节点数目增长保持近似于线性的增长,这个特点是 MapReduce 处理海量数据的关键,通过将计算节点增至几百或者几千可以很容易地处理数百 TB 甚至 PB 级别的离线数据。
- 高容错性
- Hadoop 集群是分布式搭建和部署得,任何单一机器节点宕机了,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业任务得完成,过程完全是由 Hadoop 内部完成的。
- 适合海量数据的离线处理
- 可以处理 GB、TB 和 PB 级别得数据量
2.3 MapReduce局限性
MapReduce 虽然有很多的优势,也有相对得局限性,不代表不能做,而是在有些场景下实现的效果比较差,并不适合用 MapReduce 来处理,主要表现在以下结果方面:
- 实时计算性能差
- MapReduce 主要应用于离线作业,无法作到秒级或者是亚秒级得数据响应。
- 不能进行流式计算
- 流式计算特点是数据是源源不断得计算,并且数据是动态的;而 MapReduce 作为一个离线计算框架,主要是针对静态数据集得,数据是不能动态变化得。
- 不擅长DAG(有向无环图)计算
- 多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后,每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
3. Hadoop MapReduce编程
3.1 MapReduce架构体系
一个完整的 mapreduce 程序在分布式运行时有三类实例进程:
MRAppMaster:负责整个程序的过程调度及状态协调。MapTask:负责 Map 阶段的整个数据处理流程。ReduceTask:负责 Reduce 阶段的整个数据处理流程。

3.2 MapReduce编程规范
MapReduce 分布式的运算程序需要分成 2 个阶段,分别是 Map 阶段和 Reduce 阶段。Map 阶段对应的是 MapTask 并发实例,完全并行运行,互不相干。Reduce 阶段对应的是 ReduceTask 并发实例,数据依赖于上一个阶段所有 MapTask 并发实例的数据输出结果。
MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行 mr 程序的客户端驱动)。
用户自定义的 Mapper 和 Reducer 都要继承各自的父类。Mapper 中的业务逻辑写在map()方法中,Reducer 的业务逻辑写在reduce()方法中。整个程序需要一个 Driver 来进行提交,提交的是一个描述了各种必要信息的job对象。
最需要注意的是:整个MapReduce程序中,数据都是以kv键值对的形式流转的。因此在实际编程解决各种业务问题中,需要考虑每个阶段的输入输出 kv 分别是什么。并且在 MapReduce 中数据会因为某些默认的机制进行排序进行分组。所以说 kv 的类型数据确定及其重要。
3.3 Map Reduce工作执行流程
整个 MapReduce 工作流程可以分为 3 个阶段:map、shuffle、reduce。

- map阶段:
- 负责把从数据源读取来到数据进行处理,默认情况下读取数据返回的是 kv 键值对类型,经过自定义 map 方法处理之后,输出的也应该是 kv 键值对类型。
- shuffle阶段:
- map 输出的数据会经过分区、排序、分组等自带动作进行重组,相当于洗牌的逆过程。这是 MapReduce 的核心所在,也是难点所在。也是值得我们深入探究的所在。
- 默认分区规则:key 相同的分在同一个分区,同一个分区被同一个 reduce 处理。
- 默认排序规则:根据 key 字典序排序
- 默认分组规则:key 相同的分为一组,一组调用 reduce 处理一次。
- reduce阶段:
- 负责针对 shuffle 好的数据进行聚合处理。输出的结果也应该是 kv 键值对。
4. Hadoop序列化机制
4.1 什么是序列化
序列化(Serialization)是将结构化对象转换成字节流以便于进行网络传输或写入持久存储的过程。
反序列化(Deserialization)是将字节流转换为一系列结构化对象的过程,重新创建该对象。
序列化的用途:
- 作为一种持久化格式。
- 作为一种通信的数据格式。
- 作为一种数据拷贝、克隆机制。

简单概况:
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
4.2 Java的序列化机制
Java 中,一切都是对象,在分布式环境中经常需要将 Object 从这一端网络或设备传递到另一端。这就需要有一种可以在两端传输数据的协议。Java 序列化机制就是为了解决这个问题而产生。
Java 对象序列化的机制,把对象表示成一个二进制的字节数组,里面包含了对象的数据,对象的类型信息,对象内部的数据的类型信息等等。通过保存或则转移这些二进制数组达到持久化、传递的目的。
要实现序列化,需要实现java.io.Serializable接口。反序列化是和序列化相反的过程,就是把二进制数组转化为对象的过程。
4.3 Hadoop的序列化机制
Hadoop 的序列化没有采用 java 的序列化机制,而是实现了自己的序列化机制。
原因在于 java 的序列化机制比较臃肿,重量级,是不断的创建对象的机制,并且会额外附带很多信息(校验、继承关系系统等)。但在 Hadoop 的序列化机制中,用户可以复用对象,这样就减少了 java 对象的分配和回收,提高了应用效率。
Hadoop 通过Writable接口实现的序列化机制,不过没有提供比较功能,所以和 java 中的 Comparable 接口合并,提供一个接口 WritableComparable(自定义比较)。
Writable 接口提供两个方法(write和readFields)。
package org.apache.hadoop.io;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
12345
4.4 Hadoop中的数据类型
Hadoop 提供了如下内容的数据类型,这些数据类型都实现了WritableComparable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储,以及进行大小比较。
| Hadoop 数据类型 | Java数据类型 | 备注 |
|---|---|---|
| BooleanWritable | boolean | 标准布尔型数值 |
| ByteWritable | byte | 单字节数值 |
| IntWritable | int | 整型数 |
| FloatWritable | float | 浮点数 |
| LongWritable | long | 长整型数 |
| DoubleWritable | double | 双字节数值 |
| Text | String | 使用UTF8格式存储的文本 |
| MapWritable | map | 映射 |
| ArrayWritable | array | 数组 |
| NullWritable | null | 当<key,value>中的key或value为空时使用 |
注意:如果需要将自定义的类放在 key 中传输,则还需要实现 Comparable 接口,因为 MapReduce 框中的 Shuffle 过程要求对 key 必须能排序。
5. MapReduce经典入门案例
5.1 WordCount业务需求
WordCount 中文叫做单词统计、词频统计,指的是使用程序统计某文本文件中,每个单词出现的总次数。这个是大数据计算领域经典的入门案例,虽然业务及其简单,但是希望能够通过案例感受背后 MapReduce 的执行流程和默认的行为机制,这才是关键。
# 输入数据 1.txt
hello hadoop hello hello
hadoop allen hadoop
------------------------------------------
# 输出结果
hello 3
hadoop 3
allen 1
12345678
5.2 MapReduce编程思路

map阶段核心:把输入的数据经过切割,全部标记 1。因此输出就是 <单词,1>。
shuffle阶段核心:经过默认的排序分区分组,key 相同的单词会作为一组数据构成新的 kv 对。
reduce阶段核心:处理 shuffle 完的一组数据,该组数据就是该单词所有的键值对。对所有的 1 进行累加求和,就是该单词的总次数。最终输出 <单词,总次数>。
5.3 WordCount编程实现
5.3.1 编程环境搭建
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>HdfsDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>cental</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!-- Google Options -->
<dependency>
<groupId>com.github.pcj</groupId>
<artifactId>google-options</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.itcast.sentiment_upload.Entrance</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123
5.3.2 Mapper类编写
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
//Mapper输出kv键值对 <单词,1>
private Text keyOut = new Text();
private final static LongWritable valueOut = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将读取的一行内容根据分隔符进行切割
String[] words = value.toString().split("\\s+");
//遍历单词数组
for (String word : words) {
keyOut.set(word);
//输出单词,并标记1
context.write(new Text(word),valueOut);
}
}
}
1234567891011121314151617
5.3.3 Reducer类编写
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//统计变量
long count = 0;
//遍历一组数据,取出该组所有的value
for (LongWritable value : values) {
//所有的value累加 就是该单词的总次数
count +=value.get();
}
result.set(count);
//输出最终结果<单词,总次数>
context.write(key,result);
}
}
123456789101112131415161718
5.3.4 客户端驱动类编写
5.3.4.1 方式1:直接构建作业启动
public class WordCountDriver_v1 {
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, WordCountDriver_v1.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WordCountDriver_v1.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
1234567891011121314151617181920212223242526272829303132
5.3.4.2 方式2:Tool工具类创建启动
public class WordCountDriver_v2 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 创建作业实例
Job job = Job.getInstance(getConf(), WordCountDriver_v2.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WordCountDriver_v2.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(getConf());
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
//使用工具类ToolRunner提交程序
int status = ToolRunner.run(conf, new WordCountDriver_v2(), args);
//退出客户端程序 客户端退出状态码和MapReduce程序执行结果绑定
System.exit(status);
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445
6. MapReduce程序运行
所谓的运行模式讲的是:mr 程序是单机运行还是分布式运行?mr 程序需要的运算资源是 yarn 分配还是单机系统分配?
运行在何种模式取决于下述这个参数:
mapreduce.framework.name=yarn,集群模式
mapreduce.framework.name=local,本地模式
默认是 local 模式 在mapred-default.xml中有定义。如果代码中、运行的环境中有配置,会默认覆盖 default 配置。
6.1 本地模式运行
mapreduce 程序是被提交给 LocalJobRunner 在本地以单进程的形式运行。而处理的数据及输出结果可以在本地文件系统,也可以在 hdfs 上。
本质是程序的 conf 中是否有mapreduce.framework.name=local。
本地模式非常便于进行业务逻辑的 debug。
右键直接运行main方法所在的主类即可。
6.2 集群模式运行
将 mapreduce 程序提交给 yarn 集群,分发到很多的节点上并发执行。处理的数据和输出结果应该位于 hdfs 文件系统。
将程序打成jar包,然后在集群的任意一个节点上用下面命令启动:
hadoop jar wordcount.jar com.mapreduce.WordCountDriver args
yarn jar wordcount.jar com.mapreduce.WordCountDriver args
12
7. MapReduce输入输出梳理
MapReduce 框架运转在<key,value>键值对上,也就是说,框架把作业的输入看成是一组 <key,value> 键值对,同样也产生一组 <key,value> 键值对作为作业的输出,这两组键值对可能是不同的。


7.1 输入特点
默认读取数据的组件叫做TextInputFormat。
关于输入路径:
- 如果指向的是一个文件,就处理该文件
- 如果指向的是一个文件夹(目录),就处理该目录所有的文件,当成整体来处理。
7.2 输出特点
默认输出数据的组件叫做TextOutputFormat。
输出路径不能提前存在,否则执行报错,对输出路径进行检测判断。
8. MapReduce流程简单梳理
8.1 执行流程图

8.2 Map阶段执行过程
- 第一阶段是把输入目录下文件按照一定的标准逐个进行
逻辑切片,形成切片规划。默认情况下,Split size=Block size。每一个切片由一个 MapTask 处理(getSplits)。 - 第二阶段是对切片中的数据按照一定的规则
解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key 是每一行的起始位置(单位是字节),value 是本行的文本内容(TextInputFormat)。 - 第三阶段是调用 Mapper 类中的 map 方法。上阶段中
每解析出来的一个<k,v>,调用一次map方法。每次调用 map 方法会输出零个或多个键值对。 - 第四阶段是按照一定的规则对第三阶段输出的
键值对进行分区。默认是只有一个区。分区的数量就是 Reducer 任务运行的数量。默认只有一个 Reducer 任务。 - 第五阶段是对每个
分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对 <2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是 <1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。 - 第六阶段是对数据进行
局部聚合处理,也就是 combiner 处理。键相等的键值对会调用一次 reduce 方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
8.3 Redue阶段执行过程
- 第一阶段是 Reducer 任务会主动从 Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此 Reducer 会复制多个 Mapper 的输出。
- 第二阶段是把复制到 Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用 reduce 方法。键相等的键值对调用一次 reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到 HDFS 文件中。
在整个MapReduce程序的开发过程中,我们最大的工作量是覆盖map函数和覆盖reduce函数。
MapReduce编程基础
1. MapReduce Partition、Combiner
1.1 MapReduce Partition分区
1.1.1 默认情况下MR输出文件个数
在默认情况下,不管 map 阶段有多少个并发执行 task,到 reduce 阶段,所有的结果都将有一个 reduce 来处理,并且最终结果输出到一个文件中。
此时,MapReduce 的执行流程如下所示:

1.1.2 修改reducetask个数
在 MapReduce 程序的驱动类中,通过 job 提供的方法,可以修改 reducetask 的个数。

默认情况下不设置,reducetask 个数为 1,结果输出到一个文件中。
使用 api 修改 reducetask 个数之后,输出结果文件的个数和reducetask个数对应。比如设置为 6 个,此时的输出结果如下所示:

此时,MapReduce 的执行流程如下所示:

1.1.3 数据分区概念
当 MapReduce 中有多个reducetask执行的时候,此时maptask的输出就会面临一个问题:究竟将自己的输出数据交给哪一个reducetask来处理,这就是所谓的数据分区(partition)问题。

1.1.4 默认分区规则
MapReduce 默认分区规则是HashPartitioner。跟 map 输出的数据 key 有关。

当然用户也可以自己自定义分区规则。
1.1.5 Partition注意事项
reducetask个数的改变导致了数据分区的产生,而不是有数据分区导致了 reducetask 个数改变。- 数据分区的核心是分区规则。即如何分配数据给各个 reducetask。
- 默认的规则可以保证只要
map阶段输出的key一样,数据就一定可以分区到同一个reducetask,但是不能保证数据平均分区。 - reducetask 个数的改变还会导致输出结果文件不再是一个整体,而是输出到多个文件中。
1.2 MapReduce Combiner规约
1.2.1 数据规约的含义
数据规约是指在尽可能保持数据原貌的前提下,最大限度地精简数据量。
1.2.2 MapReduce弊端
- MapReduce 是一种具有两个执行阶段的分布式计算程序,Map 阶段和 Reduce 阶段之间会涉及到
跨网络数据传递。 - 每一个 MapTask 都可能会产生大量的本地输出,这就导致跨网络传输数据量变大,网络 IO 性能低。
比如 WordCount 单词统计案例,假如文件中有 1000 个单词,其中 999 个为 hello,这将产生 999 个 <hello,1>的键值对在网络中传递,性能及其低下。
1.2.3 Combiner组件概念
Combiner中文叫做数据规约,是 MapReduce 的一种优化手段。- Combiner 的作用就是
对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量。
1.2.4 Combiner组件使用
-
combiner 是 MapReduce 程序中 Mapper 和 Reducer 之外的一种组件,
默认情况下不启用。 -
combiner本质就是Reducer,combiner 和 reducer的区别在于运行的位置:
- combiner 是在每一个 maptask 所在的节点运行,是局部聚合;
- Reducer是对所有 maptask 的输出结果计算,是全局聚合;
-
具体实现步骤:
- 自定义一个 CustomCombiner 继承 Reducer,重写 reduce 方法;
- 在 job 中设置:
job.setCombinerClass(CustomCombiner.class);
1.2.5 Combiner使用注意事项
- Combiner 能够应用的前提是不能影响最终的业务逻辑,而且,Combiner 的输出 kv 应该跟 reducer 的输入 kv 类型要对应起来。
- 下述场景禁止使用Combiner,不仅优化了数据量,还改变了最终的结果:
- 业务和数据个数相关的;
- 业务和整体排序相关的;
- Combiner 组件不是禁用,而是慎用。
用的好提升程序性能,用不好,改变程序结果且不易发现。
2. MapReduce编程指南
2.1 编程技巧
MapReduce执行流程了然于心,能够知道数据在 MapReduce 中的流转过程。业务需求解读准确,即需要明白做什么。牢牢把握住key的选择,因为 MapReduce 很多行为跟key相关, 比如:排序、分区、分组。- 学会
自定义组件修改默认行为,当默认的行为不满足业务需求,可以尝试自定义规则。 - 通过
画图梳理业务执行流程,确定每个阶段的数据类型。
2.2 MapReduce执行流程图
2.2.1 执行流程图
2.2.2 Map阶段执行过程
- 第一阶段是把输入目录下文件按照一定的标准逐个进行
逻辑切片,形成切片规划。默认情况下,Split size=Block size。每一个切片由一个 MapTask 处理(getSplits)。 - 第二阶段是对切片中的数据按照一定的规则
解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key 是每一行的起始位置(单位是字节),value 是本行的文本内容(TextInputFormat)。 - 第三阶段是调用 Mapper 类中的 map 方法。上阶段中
每解析出来的一个<k,v>,调用一次map方法。每次调用 map 方法会输出零个或多个键值对。 - 第四阶段是按照一定的规则对第三阶段输出的
键值对进行分区。默认是只有一个区。分区的数量就是 Reducer 任务运行的数量。默认只有一个 Reducer 任务。 - 第五阶段是对每个
分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对 <2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是 <1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。 - 第六阶段是对数据进行
局部聚合处理,也就是 combiner 处理。键相等的键值对会调用一次 reduce 方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
2.2.3 Redue阶段执行过程
- 第一阶段是 Reducer 任务会主动从 Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此 Reducer 会复制多个 Mapper 的输出。
- 第二阶段是把复制到 Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用 reduce 方法。键相等的键值对调用一次 reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到 HDFS 文件中。
2.3 key的重要性体现
- 在 MapReduce 编程中,核心是
牢牢把握住每个阶段的输入输出key是什么。 - 因为 MapReduce 中很多默认行为都跟 key 相关。
排序:key 的字典序a-z 正序分区:key.hashcode % reducetask 个数分组:key 相同的分为一组
- 最重要的是,如果觉得默认的行为不满足业务需求,MapReduce 还支持自定义排序、分区、分组的规则,这将使得编程更加灵活和方便。
3. 案例:美国新冠疫情COVID-19统计
现有美国 2021-1-28 号,各个县 county 的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示:
2021-01-28,Juneau City and Borough,Alaska,02110,1108,3
2021-01-28,Kenai Peninsula Borough,Alaska,02122,3866,18
2021-01-28,Ketchikan Gateway Borough,Alaska,02130,272,1
2021-01-28,Kodiak Island Borough,Alaska,02150,1021,5
2021-01-28,Kusilvak Census Area,Alaska,02158,1099,3
2021-01-28,Lake and Peninsula Borough,Alaska,02164,5,0
2021-01-28,Matanuska-Susitna Borough,Alaska,02170,7406,27
2021-01-28,Nome Census Area,Alaska,02180,307,0
2021-01-28,North Slope Borough,Alaska,02185,973,3
2021-01-28,Northwest Arctic Borough,Alaska,02188,567,1
2021-01-28,Petersburg Borough,Alaska,02195,43,0
1234567891011
字段含义如下:date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)。
完整数据集链接:https://pan.baidu.com/s/1AdWWprwEdeyfELOY7YP6ug,提取码:6666
3.1 MapReduce自定义对象序列化
3.1.1 需求
统计美国 2021-1-28,每个州 state 累积确诊案例数、累计死亡案例数。
3.1.2 分析
自定义对象CovidCountBean,用于封装每个县的确诊病例数和死亡病例数。- 注意需要
实现Hadoop的序列化机制。 以州state作为map阶段输出的key,以 CovidCountBean 作为 value,这样经过 MapReduce 的默认排序分组规则,属于同一个州的数据就会变成一组进行 reduce 处理,进行累加即可得出每个州累计确诊病例。
3.1.3 代码实现
3.1.3.1 自定义JavaBean
public class CovidCountBean implements Writable{
private long cases;//确诊病例数
private long deaths;//死亡病例数
public CovidCountBean() {
}
public CovidCountBean(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public void set(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public long getCases() {
return cases;
}
public void setCases(long cases) {
this.cases = cases;
}
public long getDeaths() {
return deaths;
}
public void setDeaths(long deaths) {
this.deaths = deaths;
}
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(cases);
out.writeLong(deaths);
}
/**
* 反序列化方法 注意顺序
*/
@Override
public void readFields(DataInput in) throws IOException {
this.cases = in.readLong();
this.deaths =in.readLong();
}
@Override
public String toString() {
return cases +"\t"+ deaths;
}
}
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455
3.1.3.2 Mapper类
public class CovidSumMapper extends Mapper<LongWritable, Text, Text, CovidCountBean> {
Text outKey = new Text();
CovidCountBean outValue = new CovidCountBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
//州
outKey.set(fields[2]);
//Covid数据 确诊病例 死亡病例
outValue.set(Long.parseLong(fields[fields.length-2]),Long.parseLong(fields[fields.length-1]));
//map输出结果
context.write(outKey,outValue);
}
}
12345678910111213141516
3.1.3.3 Reducer类
public class CovidSumReducer extends Reducer<Text, CovidCountBean,Text,CovidCountBean> {
CovidCountBean outValue = new CovidCountBean();
@Override
protected void reduce(Text key, Iterable<CovidCountBean> values, Context context) throws IOException, InterruptedException {
long totalCases = 0;
long totalDeaths =0;
//累加统计
for (CovidCountBean value : values) {
totalCases += value.getCases();
totalDeaths +=value.getDeaths();
}
outValue.set(totalCases,totalDeaths);
context.write(key,outValue);
}
}
123456789101112131415161718
3.1.3.4 程序驱动类
public class CovidSumDriver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidSumDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidSumDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidSumMapper.class);
job.setReducerClass(CovidSumReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CovidCountBean.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CovidCountBean.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
1234567891011121314151617181920212223242526272829303132333435
3.1.4 代码执行结果

3.2 MapReduce自定义排序
3.2.1 需求
统计美国 2021-01-28,每个州state的累积确证案例数、累积死亡案例数。
将美国 2021-01-28,每个州state的确证案例数进行倒序排序。
3.2.2 分析
如果你的需求中需要根据某个属性进行排序 ,不妨把这个属性作为 key。因为 MapReduce 中key有默认排序行为的。但是需要进行如下考虑:
- 如果你的需求是正序,并且数据类型是 Hadoop 封装好的基本类型。这种情况下不需要任何修改,直接使用基本类型作为 key 即可。因为 Hadoop 封装好的类型已经实现了排序规则。
- 比如,LongWritable 类型:

- 比如,LongWritable 类型:
- 如果你的需求是倒序,或者数据类型是自定义对象。需要重写排序规则。需要对象
实现Comparable接口,重写ComparTo方法。

3.2.3 代码实现
3.2.3.1 自定义JavaBean
public class CovidCountBean implements WritableComparable<CovidCountBean> {
private long cases;//确诊病例数
private long deaths;//死亡病例数
public CovidCountBean() {
}
public CovidCountBean(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public void set(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public long getCases() {
return cases;
}
public void setCases(long cases) {
this.cases = cases;
}
public long getDeaths() {
return deaths;
}
public void setDeaths(long deaths) {
this.deaths = deaths;
}
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(cases);
out.writeLong(deaths);
}
/**
* 反序列化方法 注意顺序
*/
@Override
public void readFields(DataInput in) throws IOException {
this.cases = in.readLong();
this.deaths =in.readLong();
}
@Override
public String toString() {
return cases +"\t"+ deaths;
}
/**
* 排序比较器 本业务中根据确诊案例数倒序排序
*/
@Override
public int compareTo(CovidCountBean o) {
return this.cases - o.getCases()> 0 ? -1:(this.cases - o.getCases() < 0 ? 1 : 0);
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960
3.2.3.2 Mapper类
public class CovidSortSumMapper extends Mapper<LongWritable, Text, CovidCountBean,Text> {
CovidCountBean outKey = new CovidCountBean();
Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
outKey.set(Long.parseLong(fields[1]),Long.parseLong(fields[2]));
outValue.set(fields[0]);
context.write(outKey,outValue);
}
}
12345678910111213
3.2.3.3 Reducer类
public class CovidSortSumReducer extends Reducer<CovidCountBean, Text,Text,CovidCountBean> {
@Override
protected void reduce(CovidCountBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Text outKey = values.iterator().next();
context.write(outKey,key);
}
}
1234567
3.2.3.4 驱动程序类
public class CovidSortSumDriver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidSortSumDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidSortSumDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidSortSumMapper.class);
job.setReducerClass(CovidSortSumReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(CovidCountBean.class);
job.setMapOutputValueClass(Text.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CovidCountBean.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
1234567891011121314151617181920212223242526272829303132333435
3.2.4 代码执行结果

3.3 MapReduce自定义分区
3.3.1 需求
将美国每个州的疫情数据输出到各自不同的文件中,即一个州的数据在一个结果文件中。
3.3.2 分析
输出到不同文件中表示 reducetask 有多个,而 reducetask 默认只有1个,可以通过job.setNumReduceTasks(N)设置。当有多个 reducetask 意味着数据分区,默认分区规则是hashPartitioner,默认分区规则符合业务需求的话,就直接使用;不符合,再自定义分区。
3.3.3 代码实现
3.3.3.1 自定义JavaBean
public class CovidCountBean implements WritableComparable<CovidCountBean> {
private long cases;//确诊病例数
private long deaths;//死亡病例数
public CovidCountBean() {
}
public CovidCountBean(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public void set(long cases, long deaths) {
this.cases = cases;
this.deaths = deaths;
}
public long getCases() {
return cases;
}
public void setCases(long cases) {
this.cases = cases;
}
public long getDeaths() {
return deaths;
}
public void setDeaths(long deaths) {
this.deaths = deaths;
}
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(cases);
out.writeLong(deaths);
}
/**
* 反序列化方法 注意顺序
*/
@Override
public void readFields(DataInput in) throws IOException {
this.cases = in.readLong();
this.deaths =in.readLong();
}
@Override
public String toString() {
return cases +"\t"+ deaths;
}
/**
* 排序比较器 本业务中根据确诊案例数倒序排序
*/
@Override
public int compareTo(CovidCountBean o) {
return this.cases - o.getCases()> 0 ? -1:(this.cases - o.getCases() < 0 ? 1 : 0);
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960
3.3.3.2 自定义分区器
public class StatePartitioner extends Partitioner<Text, Text> {
//模拟美国各州数据字典 实际中可以从redis中快速查询 如果数据不大也可以使用数据集合保存
public static HashMap<String, Integer> stateMap = new HashMap<String, Integer>();
static{
stateMap.put("Alabama", 0);
stateMap.put("Arkansas", 1);
stateMap.put("California", 2);
stateMap.put("Florida", 3);
stateMap.put("Indiana", 4);
}
@Override
public int getPartition(Text key, Text value, int numPartitions) {
Integer code = stateMap.get(key.toString());
if (code != null) {
return code;
}
return 5;
}
}
123456789101112131415161718192021222324
3.3.3.3 Mapper类
public class CovidPartitionMapper extends Mapper<LongWritable, Text,Text, Text> {
Text outKey = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] splits = value.toString().split(",");
//以州作为输出的key
outKey.set(splits[2]);
context.write(outKey,value);
}
}
123456789101112
3.3.3.4 Reducer类
public class CovidPartitionReducer extends Reducer<Text,Text,Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value,NullWritable.get());
}
}
}
12345678
3.3.3.5 驱动程序类
public class CovidPartitionDriver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidPartitionDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidPartitionDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidPartitionMapper.class);
job.setReducerClass(CovidPartitionReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//todo 设置reducetask个数 和自定义分区器
job.setNumReduceTasks(6);
job.setPartitionerClass(StatePartitioner.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
12345678910111213141516171819202122232425262728293031323334353637383940
3.3.4 代码执行结果


3.3.5 分区个数和reducetask个数的关系
正常情况下:分区的个数 = reducetask个数
- 分区的个数 > reducetask个数
- 程序执行报错
- 分区的个数 < reducetask个数
- 有空文件产生
3.4 MapReduce自定义分组
3.4.1 分组概念和默认分组规则
- 分组在发生在 reduce 阶段,决定了
同一个reduce中哪些数据将组成一组去调用reduce方法处理。 - 默认分组规则是:
key相同的就会分为一组(前后两个 key 直接比较是否相等)。 - 需要注意的是,在 reduce 阶段进行分组之前,因为进行数据排序行为,因此
排序+分组将会使得key一样的数据一定被分到同一组,一组去调用reduce方法处理。
3.4.2 自定义分组规则
- 写类继承WritableComparator,重写Compare方法。
- 只要
Compare方法返回为 0,MapReduce框架在分组的时候就会认为前后两个相等,分为一组。 - 在 job 对象中进行设置才能让自己的重写分组类生效:
job.setGroupingComparatorClass(xxxx.class);
3.4.3 需求
找出美国 2021-01-28,每个州 state 的确诊案例数最多的县 county 是哪一个。该问题也是俗称的 TopN 问题。
3.4.4 分析
- 在 ma p阶段将 “州state和累计确诊病例数cases” 作为 key 输出;
- 重写对象的排序规则,
首先根据州的正序排序,如果州相等,按照确诊病例数cases倒序排序,发送到 reduce; - 在 reduce 端利用自定义分组规则,将
州state相同的分为一组,然后取第一个即是最大值;
3.4.5 代码实现
3.4.5.1 自定义对象
public class CovidBean implements WritableComparable<CovidBean> {
private String state;//州
private String county;//县
private long cases;//确诊病例
public CovidBean() {
}
public CovidBean(String state, String county, long cases) {
this.state = state;
this.county = county;
this.cases = cases;
}
public void set (String state, String county, long cases) {
this.state = state;
this.county = county;
this.cases = cases;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getCounty() {
return county;
}
public void setCounty(String county) {
this.county = county;
}
public long getCases() {
return cases;
}
public void setCases(long cases) {
this.cases = cases;
}
@Override
public String toString() {
return "CovidBean{" +
"state='" + state + '\'' +
", county='" + county + '\'' +
", cases=" + cases +
'}';
}
//todo 排序规则 根据州state正序进行排序 如果州相同 则根据确诊数量cases倒序排序
@Override
public int compareTo(CovidBean o) {
int result ;
int i = state.compareTo(o.getState());
if ( i > 0) {
result =1;
} else if (i <0 ) {
result = -1;
} else {
// 确诊病例数倒序排序
result = cases > o.getCases() ? -1 : 1;
}
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(state);
out.writeUTF(county);
out.writeLong(cases);
}
@Override
public void readFields(DataInput in) throws IOException {
this.state =in.readUTF();
this.county =in.readUTF();
this.cases =in.readLong();
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687
3.4.5.2 Mapper类
public class CovidTop1Mapper extends Mapper<LongWritable, Text, CovidBean, NullWritable> {
CovidBean outKey = new CovidBean();
NullWritable outValue = NullWritable.get();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
//封装数据: 州 县 确诊病例
outKey.set(fields[2],fields[1],Long.parseLong(fields[4]));
context.write(outKey,outValue);
}
}
12345678910111213
3.4.5.3 Reducer类
public class CovidTop1Reducer extends Reducer<CovidBean, NullWritable,CovidBean,NullWritable> {
@Override
protected void reduce(CovidBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//不遍历迭代器,此时key就是分组中的第一个key 也就是该州确诊病例数最多的县对应的数据
context.write(key,NullWritable.get());
}
}
1234567
3.4.5.4 自定义分组
public class CovidGroupingComparator extends WritableComparator {
protected CovidGroupingComparator(){
super(CovidBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
CovidBean aBean = (CovidBean) a;
CovidBean bBean = (CovidBean) b;
return aBean.getState().compareTo(bBean.getState());
}
}
1234567891011121314
3.4.5.5 驱动程序类
public class CovidTop1Driver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidTop1Driver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidTop1Driver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidTop1Mapper.class);
job.setReducerClass(CovidTop1Reducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(CovidBean.class);
job.setMapOutputValueClass(NullWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(CovidBean.class);
job.setOutputValueClass(NullWritable.class);
//todo 设置自定义分组
job.setGroupingComparatorClass(CovidGroupingComparator.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
1234567891011121314151617181920212223242526272829303132333435363738
3.4.6 代码执行结果

3.5 自定义分组扩展:topN问题
3.5.1 需求
找出美国 2021-01-28,每个州 state 的确诊案例数最多的县 county 前 3 个。(Top3 问题)
3.5.2 分析
- 在 map 阶段将 “州state和累计确诊病例数cases” 作为 key 输出;
- 重写对象的排序规则,
首先根据州的正序排序,如果州相等,按照确诊病例数cases倒序排序,发送到 reduce; - 在 reduce 端利用自定义分组规则,将
州state相同的分为一组,然后遍历取值,取出每组中的前 3 个即可。
为了验证验证结果方便,可以在输出的时候以 cases 作为 value,实际上为空即可,value 并无实际意义。
3.5.3 代码实现
3.5.3.1 自定义对象、自定义分组类
这两个和上述的 Top1 一样,此处就不再重复编写。可以直接使用。
3.5.3.2 Mapper类
public class CovidTopNMapper extends Mapper<LongWritable, Text, CovidBean,LongWritable> {
CovidBean outKey = new CovidBean();
LongWritable outValue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
//封装数据: 州 县 确诊病例
outKey.set(fields[2],fields[1],Long.parseLong(fields[4]));
outValue.set(Long.parseLong(fields[4]));
context.write(outKey,outValue);
}
}
1234567891011121314
3.5.3.3 Reducer类
public class CovidTopNReducer extends Reducer<CovidBean, LongWritable,CovidBean,LongWritable> {
@Override
protected void reduce(CovidBean key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int num =0;
for (LongWritable value : values) {
if(num < 3 ){ //输出每个州最多的前3个
context.write(key,value);
num++;
}else{
return;
}
}
}
}
1234567891011121314
3.5.3.4 程序驱动类
public class CovidTopNDriver {
public static void main(String[] args) throws Exception{
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidTopNDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidTopNDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidTopNMapper.class);
job.setReducerClass(CovidTopNReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(CovidBean.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(CovidBean.class);
job.setOutputValueClass(LongWritable.class);
//todo 设置自定义分组
job.setGroupingComparatorClass(CovidGroupingComparator.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
123456789101112131415161718192021222324252627282930313233343536373839
3.5.4 代码执行结果

MapReduce并行度机制
1. MapTask并行度机制
1.1 概念
MapTask 的并行度指的是map阶段有多少个并行的task共同处理任务。map 阶段的任务处理并行度,势必影响到整个 Job 的处理速度。
- 一个 Job 的 Map 阶段并行度由客户端在提交 Job 时的切片数决定;
- **数据块:**Block 是 HDFS 物理上把数据分成一块一块。数据块是 HDFS 存储数据单位;
- **数据切片:**数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个 MapTask;
1.2 逻辑规划
- MapTask 并行度的决定机制叫做
逻辑规划; 客户端提交Job之前会对待处理数据进行逻辑切片,形成逻辑规划文件;- 逻辑切片机制由 FileInputFormat 实现类的
getSplits()方法完成; - 逻辑规划结果写入规划文件(job.split),在客户端提交 Job 之前,把规划文件提交到任务准备区,供后续使用;
- 每个逻辑切片最终对应启动一个 MapTask;
1.3 逻辑规划规则
- FileInputFormat中默认的切片机制:
- 简单地按照文件的内容长度进行切片;
- 切片大小,默认等于 block 大小,而 block 大小默认为 128M;
- 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片;
# 比如待处理数据有两个文件
file1.txt 320M
file2.txt 10M
# 经过FileInputFormat的切片机制运算后,形成切片信息如下:
file1.txt.split1 0M~128M
file1.txt.split2 128M~256M
file1.txt.split3 256M~320M
file2.txt.split1 0M~10M
12345678
1.4 逻辑切片相关参数
在 FileInputFormat 中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定:
-
minsize(切片最小值)
,默认值:1
- 配置参数:
mapreduce.input.fileinputformat.split.minsize=1; - 参数调的比 blockSize 大,则可以让切片变得比 blockSize 还大;
- 配置参数:
-
maxsize
,默认值:Long.MAXValue
- 配置参数:
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue; - 参数如果调的比 blockSize 小,则会让切片变小,而且就等于配置的这个参数的值;
- 配置参数:
因此,默认情况下,split size=block size,在 hadoop 2.x 中为 128M。
但是,不论怎么调参数,都不能让多个小文件 “划入” 一个 split。
另外,当bytesRemaining/splitSize > 1.1不满足的话,那么最后所有剩余的会作为一个切片。从而不会形成例如 129M 文件规划成两个切片的局面。
2. ReduceTask并行度机制
- Reducetask 并行度同样影响整个 job 的执行并发度和执行效率,与 maptask 的并发数由切片数决定不同,Reducetask 数量的决定是可以直接
手动设置:job.setNumReduceTasks(4); - 注意 Reducetask 数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有 1个 Reducetask;
- 如果数据分布不均匀,就有可能在 reduce 阶段产生数据倾斜;
3. CombineTextInputFormat
3.1 TextInputFormat
在运行 MapReduce 程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。针对不同的数据类型,FileInputFormat 有不同的接口实现类:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
TextInputFormat 是默认的 FileInputFormat 实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型。
以下是一个示例,比如,一个分片包含了如下 4 条文本记录。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
1234
每条记录表示为以下键/值对:
(0,Rich learning form)
(20,Intelligent learning engine)
(49,Learning more convenient)
(74,From the real demand for more close to the enterprise)
1234
3.2 CombineTextInputFormat切片机制
框架默认的 TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个 MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
- 应用场景:
- CombineTextInputFormat 用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 MapTask 处理;
- 虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);(4M)- 注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值;
- 切片机制
- 生成切片过程包括:虚拟存储过程和切片过程二部分。

- 虚拟存储过程:
- 将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;
当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片); - 例如 setMaxInputSplitSize 值为 4M,输入文件大小为 8.02M,则先逻辑上分成一个 4M。剩余的大小为 4.02M,如果按照 4M 逻辑划分,就会出现 0.02M 的小的虚拟存储文件,所以将剩余的 4.02M 文件切分成(2.01M和2.01M)两个文件;
- 将输入目录下所有文件大小,依次和设置的 setMaxInputSplitSize 值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;
- 切片过程:
- 判断虚拟存储的文件大小是否大于 setMaxInputSplitSize 值,大于等于则单独形成一个切片;
- 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
- 测试举例:
- 有 4 个小文件大小分别为 1.7M、5.1M、3.4M 以及 6.8M 这四个小文件,则虚拟存储之后形成 6 个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M 以及(3.4M、3.4M) - 最终会形成 3 个切片,大小分别为:
(1.7+2.55) M,(2.55+3.4) M,(3.4+3.4) M
- 有 4 个小文件大小分别为 1.7M、5.1M、3.4M 以及 6.8M 这四个小文件,则虚拟存储之后形成 6 个文件块,大小分别为:
MapReduce工作流程详解
1. MapReduce工作流程详解


1.1 MapTask工作机制详解
1.1.1 流程图

1.1.2 执行步骤
整个 Map 阶段流程大体如上图所示。
简单概述:input File 通过 split 被逻辑切分为多个 split 文件,通过 Record 按行读取内容给 map(用户自己实现的)进行处理,数据被 map 处理结束之后交给 OutputCollector 收集器,对其结果 key 进行分区(默认使用 hash 分区),然后写入 buffer,每个 map task 都有一个内存缓冲区,存储着 map 的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个 map task 结束后再对磁盘中这个 map task 产生的所有临时文件做合并,生成最终的正式输出文件,然后等待 reduce task 来拉数据。
详细步骤:
- 首先,读取数据组件 InputFormat(默认 TextInputFormat)会通过 getSplits 方法对输入目录中文件进行
逻辑切片规划得到 splits,有多少个 split 就对应启动多少个 MapTask。split 与 block 的对应关系默认是一对一。 - 将输入文件切分为 splits 之后,由
RecordReader对象(默认 LineRecordReader)进行读取,以\n作为分隔符,读取一行数据,返回<key,value>。Key 表示每行首字符偏移值,value 表示这一行文本内容。 - 读取 split 返回 <key,value>,进入用户自己继承的 Mapper 类中,执行
用户重写的map函数。RecordReader 读取一行这里调用一次。 - map 逻辑完之后,将 map 的每条结果通过
context.write进行collect数据收集。在 collect 中,会先对其进行分区处理,默认使用HashPartitioner。
MapReduce 提供 Partitioner 接口,它的作用就是根据 key 或 value 及 reduce 的数量来决定当前的这对输出数据最终应该交由哪个 reduce task 处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均 reduce 的处理能力,如果用户自己对 Partitioner 有需求,可以订制并设置到 job 上。 - 接下来,会将数据写入内存,内存中这片区域叫做
环形缓冲区,缓冲区的作用是批量收集 map 结果,减少磁盘 IO 的影响。我们的 key/value 对以及 Partition 的结果都会被写入缓冲区。当然写入之前,key 与 value 值都会被序列化成字节数组。
环形缓冲区其实是一个数组,数组中存放着 key、value 的序列化数据和 key、value 的元数据信息,包括 partition、key 的起始位置、value 的起始位置以及 value 的长度。环形结构是一个抽象概念。
缓冲区是有大小限制,默认是100MB。当 map task 的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写 map 结果的线程。溢写线程启动时不应该阻止 map 的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 =80MB),溢写线程启动,锁定这 80MB 的内存,执行溢写过程。Map task 的输出结果还可以往剩下的 20MB 内存中写,互不影响。 - 当溢写线程启动后,需要对这 80MB 空间内的 key 做
排序(Sort)。排序是 MapReduce 模型默认的行为,这里的排序也是对序列化的字节做的排序。
如果 job 设置过Combiner,那么现在就是使用 Combiner 的时候了。将有相同 key 的 key/value 对的 value 加起来,减少溢写到磁盘的数据量。Combiner 会优化 MapReduce 的中间结果,所以它在整个模型中会多次使用。
那哪些场景才能使用 Combiner 呢?从这里分析,Combiner 的输出是 Reducer 的输入,Combiner 绝不能改变最终的计算结果。Combiner 只应该用于那种 Reduce 的输入 key/value 与输出 key/value 类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner 的使用一定得慎重,如果用好,它对 job 执行效率有帮助,反之会影响 reduce 的最终结果。 - 每次溢写会在磁盘上生成一个
临时文件(写之前判断是否有 combiner),如果 map 的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个 reduce 对应数据的偏移量。
至此map整个阶段结束。
1.2 ReduceTask工作机制详解
1.2.1 流程图

1.2.2 执行步骤
Reduce 大致分为copy、sort、reduce三个阶段,重点在前两个阶段。copy 阶段包含一个 eventFetcher 来获取已完成的 map 列表,由 Fetcher 线程去 copy 数据,在此过程中会启动两个 merge 线程,分别为 inMemoryMerger 和 onDiskMerger,分别将内存中的数据 merge 到磁盘和将磁盘中的数据进行 merge。待数据 copy 完成之后,copy 阶段就完成了,开始进行 sort 阶段,sort 阶段主要是执行 finalMerge 操作,纯粹的 sort 阶段,完成之后就是 reduce 阶段,调用用户定义的 reduce 函数进行处理。
详细步骤:
Copy阶段,简单地拉取数据。Reduce 进程启动一些数据 copy 线程(Fetcher),通过 HTTP 方式请求 maptask 获取属于自己的文件。Merge阶段。这里的 merge 如 map 端的 merge 动作,只是数组中存放的是不同 map 端 copy 来的数值。Copy 过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活。merge 有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的 merge。与 map 端类似,这也是溢写的过程,这个过程中如果你设置有 Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种 merge 方式一直在运行,直到没有 map 端的数据时才结束,然后启动第三种磁盘到磁盘的 merge 方式生成最终的文件。- 把分散的数据合并成一个大的数据后,还会再对合并后的
数据排序。 - 对排序后的键值对
调用reduce方法,键相等的键值对调用一次 reduce 方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到 HDFS 文件中。
1.3 MapReduce Shuffle机制
Shuffle 的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
而在 MapReduce 中,Shuffle 更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
shuffle 是 Mapreduce的核心,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。

Partition阶段:将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存之前会对 key 进行分区的计算,默认 Hash 分区等。Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了 combiner,还会将有相同分区号和 key 的数据进行排序。Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask 最终只产生一个中间数据文件。Copy阶段: ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。Merge阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。Sort阶段:在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。
注意:
- Shuffle 中的缓冲区大小会影响到 MapReduce 程序的执行效率,原则上说,缓冲区越大,磁盘 IO 的次数越少,执行速度就越快。
- 缓冲区的大小可以通过参数调整,参数:
mapreduce.task.io.sort.mb,默认100M。
1.3.1 Shuffle的弊端
shuffle 阶段过程繁琐、琐碎,涉及了多个阶段的任务交接。
shuffle 中频繁进行数据内存到磁盘、磁盘到内存、内存再到磁盘的过程,效率极低。
shuffle 阶段,大量的数据从 map 阶段输出,发送到 reduce 阶段,这一过程中,可能会涉及到大量的网络 IO。
MapReduce Counter计数器
1. 计数器概述
在执行 MapReduce 程序的时候,控制台输出信息中通常有下面所示片段内容:

可以发现,输出信息中的核心词是counters,中文叫做计数器。在进行 MapReduce 运算过程中,许多时候,用户希望了解程序的运行情况。Hadoop内置的计数器功能收集作业的主要统计信息,可以帮助用户理解程序的运行情况,辅助用户诊断故障。
这些记录了该程序运行过程的的一些信息的计数,如Map input records=2,表示 Map 有 2 条记录。可以看出来这些内置计数器可以被分为若干个组,即对于大多数的计数器来说,Hadoop 使用的组件分为若干类。
2. MapReduce内置计数器
Hadoop 为每个 MapReduce 作业维护一些内置的计数器,这些计数器报告各种指标,例如和 MapReduce 程序执行中每个阶段输入输出的数据量相关的计数器,可以帮助用户进行判断程序逻辑是否生效、正确。
Hadoop 内置计数器根据功能进行分组。每个组包括若干个不同的计数器,分别是:MapReduce 任务计数器(Map-Reduce Framework)、文件系统计数器(File System Counters)、作业计数器(Job Counters)、输入文件任务计数器(File Input Format Counters)、输出文件计数器(File Output Format Counters)。
需要注意的是,内置的计数器都是 MapReduce 程序中全局的计数器,跟 MapReduce 分布式运算没有关系,不是所谓的每个局部的统计信息。
2.1 Map-Reduce Framework Counters
| 计数器名称 | 说明 |
|---|---|
| MAP_INPUT_RECORDS | 所有mapper已处理的输入记录数 |
| MAP_OUTPUT_RECORDS | 所有mapper产生的输出记录数 |
| MAP_OUTPUT_BYTES | 所有mapper产生的未经压缩的输出数据的字节数 |
| MAP_OUTPUT_MATERIALIZED_BYTES | mapper输出后确实写到磁盘上字节数 |
| COMBINE_INPUT_RECORDS | 所有combiner(如果有)已处理的输入记录数 |
| COMBINE_OUTPUT_RECORDS | 所有combiner(如果有)已产生的输出记录数 |
| REDUCE_INPUT_GROUPS | 所有reducer已处理分组的个数 |
| REDUCE_INPUT_RECORDS | 所有reducer已经处理的输入记录的个数。每当某个reducer的迭代器读一个值时,该计数器的值增加 |
| REDUCE_OUTPUT_RECORDS | 所有reducer输出记录数 |
| REDUCE_SHUFFLE_BYTES | Shuffle时复制到reducer的字节数 |
| SPILLED_RECORDS | 所有map和reduce任务溢出到磁盘的记录数 |
| CPU_MILLISECONDS | 一个任务的总CPU时间,以毫秒为单位,可由/proc/cpuinfo获取 |
| PHYSICAL_MEMORY_BYTES | 一个任务所用的物理内存,以字节数为单位,可由/proc/meminfo获取 |
| VIRTUAL_MEMORY_BYTES | 一个任务所用虚拟内存的字节数,由/proc/meminfo获取 |
2.2 File System Counters Counters
文件系统的计数器会针对不同的文件系统使用情况进行统计,比如 HDFS、本地文件系统:

| 计数器名称 | 说明 |
|---|---|
| BYTES_READ | 程序从文件系统中读取的字节数 |
| BYTES_WRITTEN | 程序往文件系统中写入的字节数 |
| READ_OPS | 文件系统中进行的读操作的数量(例如,open操作,filestatus操作) |
| LARGE_READ_OPS | 文件系统中进行的大规模读操作的数量 |
| WRITE_OPS | 文件系统中进行的写操作的数量(例如,create操作,append操作) |
2.3 Job Counters

| 计数器名称 | 说明 |
|---|---|
| Launched map tasks | 启动的map任务数,包括以“推测执行”方式启动的任务 |
| Launched reduce tasks | 启动的reduce任务数,包括以“推测执行”方式启动的任务 |
| Data-local map tasks | 与输人数据在同一节点上的map任务数 |
| Total time spent by all maps in occupied slots (ms) | 所有map任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all reduces in occupied slots (ms) | 所有reduce任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all map tasks (ms) | 所有map task花费的时间 |
| Total time spent by all reduce tasks (ms) | 所有reduce task花费的时间 |
2.4 File Input | Output Format Counters

| 计数器名称 | 说明 |
|---|---|
| 读取的字节数(BYTES_READ) | 由map任务通过FilelnputFormat读取的字节数 |
| 写的字节数(BYTES_WRITTEN) | 由map任务(针对仅含map的作业)或者reduce任务通过FileOutputFormat写的字节数 |
3. MapReduce自定义计数器
虽然 Hadoop 内置的计数器比较全面,给作业运行过程的监控带了方便,但是对于一些业务中的特定要求(统计过程中对某种情况发生进行计数统计)MapReduce 还是提供了用户编写自定义计数器的方法。最重要的是,计数器是全局的统计,避免了用户自己维护全局变量的不利性。
自定义计数器的使用分为两步:
首先通过context.getCounter方法获取一个全局计数器,创建的时候需要指定计数器所属的组名和计数器的名字:

然后在程序中需要使用计数器的地方,调用 counter 提供的方法即可,比如 +1 操作:

这样在执行程序的时候,在控制台输出的信息上就有自定义计数器组和计数器统计信息。
4. 案例:MapReduce自定义计数器
4.1 需求
针对一批文件进行词频统计,不知何种原因,在任意文件的任意地方都有可能插入单词 “apple”,现要求使用计数器统计出数据中 apple 出现的次数,便于用户执行程序时判断。

4.2 代码实现
4.2.1 Mapper类
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//从程序上下文对象获取一个全局计数器:用于统计apple出现的个数
//需要指定计数器组 和计数器的名字
Counter counter = context.getCounter("itcast_counters", "apple Counter");
String[] words = value.toString().split("\\s+");
for (String word : words) {
//判断读取内容是否为apple 如果是 计数器加1
if("apple".equals(word)){
counter.increment(1);
}
context.write(new Text(word),new LongWritable(1));
}
}
}
1234567891011121314151617
4.2.2 Reduce类
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count +=value.get();
}
context.write(key,new LongWritable(count));
}
}
12345678910
4.2.3 运行主类
public class WordCountDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 创建作业实例
Job job = Job.getInstance(getConf(), WordCountDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(this.getClass());
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
//使用工具类ToolRunner提交程序
int status = ToolRunner.run(conf, new WordCountDriver(), args);
//退出客户端程序 客户端退出状态码和MapReduce程序执行结果绑定
System.exit(status);
}
}
12345678910111213141516171819202122232425262728293031323334353637383940
4.2.4 执行结果

MapReduce Join操作
1. 背景
在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时我们就可以使用 SQL 语句中的连接(JOIN),在两个或多个数据表中查询数据。
在使用 MapReduce 框架进行数据处理的过程中,也会涉及到从多个数据集读取数据,进行join关联的操作,只不过此时需要使用 java 代码并且根据 MapReduce 的编程规范进行业务的实现。
但是由于 MapReduce 的分布式设计理念的特殊性,因此对于 MapReduce 实现 join 操作具备了一定的特殊性。特殊主要体现在:究竟在MapReduce中的什么阶段进行数据集的关联操作,是mapper阶段还是reducer阶段,之间的区别又是什么?
整个 MapReduce 的 join 分为两类:map side join、reduce side join。
2. reduce side join
2.1 概述
reduce side join,顾名思义,在reduce阶段执行join关联操作。这也是最容易想到和实现的 join 方式。因为通过shuffle过程就可以将相关的数据分到相同的分组中,这将为后面的 join 操作提供了便捷。

基本上,reduce side join大致步骤如下:
- mapper 分别读取不同的数据集;
- mapper 的输出中,通常以 join 的字段作为输出的 key;
- 不同数据集的数据经过 shuffle,key 一样的会被分到同一分组处理;
- 在 reduce 中根据业务需求把数据进行关联整合汇总,最终输出。
2.2 弊端
reduce 端 join 最大的问题是整个 join 的工作是在 reduce 阶段完成的,但是通常情况下 MapReduce 中 reduce 的并行度是极小的(默认是 1 个),这就使得所有的数据都挤压到reduce阶段处理,压力颇大。虽然可以设置 reduce 的并行度,但是又会导致最终结果被分散到多个不同文件中。
并且在数据从 mapper 到 reducer 的过程中,shuffle阶段十分繁琐,数据集大时成本极高。
3. MapReduce分布式缓存
DistributedCache 是 hadoop 框架提供的一种机制,可以将job指定的文件,在job执行前,先行分发到task执行的机器上,并有相关机制对cache文件进行管理。
DistributedCache 能够缓存应用程序所需的文件 (包括文本,档案文件,jar 文件等)。
Map-Redcue 框架在作业所有任务执行之前会把必要的文件拷贝到 slave 节点上。 它运行高效是因为每个作业的文件只拷贝一次并且为那些没有文档的 slave 节点缓存文档。
3.1 使用方式
3.1.1 添加缓存文件
可以使用 MapReduce 的 API 添加需要缓存的文件。
// 添加归档文件到分布式缓存中
job.addCacheArchive(URI uri);
// 添加普通文件到分布式缓存中
job.addCacheFile(URI uri);
1234
注意:需要分发的文件,必须提前放到hdfs上,默认的路径前缀是hdfs://。
3.1.2 程序中读取缓存文件
在 Mapper 类或者 Reducer 类的 setup 方法中,用输入流获取分布式缓存中的文件。
protected void setup(Context context) throw IOException,InterruptedException{
FileReader reader = new FileReader("myfile");
BufferReader br = new BufferedReader(reader);
......
}
12345
4. map side join
4.1 概述
map side join,其精髓就是在map阶段执行join关联操作,并且程序也没有了reduce阶段,避免了 shuffle 时候的繁琐。实现的关键是使用MapReduce的分布式缓存。

尤其是涉及到一大一小数据集的处理场景时,map 端的 join 将会发挥出得天独厚的优势。
map side join 的大致思路如下:
- 首先分析 join 处理的数据集,使用分布式缓存技术将小的数据集进行分布式缓存;
- MapReduce 框架在执行的时候会自动将缓存的数据分发到各个 maptask 运行的机器上;
- 程序只运行 mapper,在 mapper 初始化的时候从分布式缓存中读取小数据集数据,然后和自己读取的大数据集进行 join 关联,输出最终的结果;
- 整个 join 的过程没有 shuffle,没有 reducer;
4.2 优势
map 端 join 最大的优势减少 shuffle 时候的数据传输成本。并且 mapper 的并行度可以根据输入数据量自动调整,充分发挥分布式计算的优势。
5. MapReduce join案例:订单商品处理
5.1 需求
有两份结构化的数据文件:itheima_goods(商品信息表)、itheima_order_goods(订单信息表),具体字段内容如下。
要求使用MapReduce统计出每笔订单中对应的具体的商品名称信息。比如107860商品对应着:AMAZFIT黑色硅胶腕带。
数据文件链接:https://pan.baidu.com/s/1W7lk7jA66bHC6-ShkxNeJQ ,提取码:6666
5.1.1 itheima_goods

5.1.1 itheima_order_goods

5.2 Reduce Side实现
5.2.1 分析
使用 mapper 处理订单数据和商品数据,输出的时候以 goodsId 商品编号作为 key。相同 goodsId 的商品和订单会到同一个 reduce 的同一个分组,在分组中进行订单和商品信息的关联合并。在 MapReduce 程序中可以通过 context 获取到当前处理的切片所属的文件名称。根据文件名来判断当前处理的是订单数据还是商品数据,以此来进行不同逻辑的输出。
join 处理完之后,最后可以再通过 MapReduce 程序排序功能,将属于同一笔订单的所有商品信息汇聚在一起。
5.2.2 代码实现
5.2.2.1 mapper类
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
Text outKey = new Text();
Text outValue = new Text();
StringBuilder sb = new StringBuilder();
String filename =null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取当前处理的切片所属的文件名字
FileSplit inputSplit = (FileSplit) context.getInputSplit();
filename = inputSplit.getPath().getName();
System.out.println("当前正在处理的文件是:"+filename);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//设置字符串长度,此处用于清空数据
sb.setLength(0);
//切割处理输入数据
String[] fields = value.toString().split("\\|");
//判断处理的是哪个文件
if(filename.contains("itheima_goods.txt")){//处理的是商品数据
// 100101|155083444927602|四川果冻橙6个约180g (商品id、商品编号、商品名称)
outKey.set(fields[0]);
StringBuilder append = sb.append(fields[1]).append("\t").append(fields[2]);
outValue.set(sb.insert(0, "goods#").toString());
System.out.println(outKey+"---->"+outValue);
context.write(outKey,outValue);
}else{//处理的是订单数据
// 2|113561|11192 (订单编号、商品id、实际支付价格)
outKey.set(fields[1]);
StringBuilder append = sb.append(fields[0]).append("\t").append(fields[2]);
outValue.set(sb.insert(0, "order#").toString());
System.out.println(outKey+"---->"+outValue);
context.write(outKey,outValue);
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041
5.2.2.2 reducer类
public class ReduceJoinReducer extends Reducer<Text,Text,Text,Text> {
//用来存放 商品编号、商品名称
List<String> goodsList = new ArrayList<>();
//用来存放 订单编号、实际支付价格
List<String> orderList = new ArrayList<>();
Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//遍历values
for (Text value : values) {
//将结果添加到对应的list中
if(value.toString().startsWith("goods#")){
String s = value.toString().split("#")[1];
goodsList.add(s);
}
if(value.toString().startsWith("order#")){
String s = value.toString().split("#")[1];
orderList.add(s);
}
}
//获取2个集合的长度
int goodsSize = goodsList.size();
int orderSize = orderList.size();
for (int i = 0; i < orderSize; i++) {
for (int j = 0; j < goodsSize; j++) {
outValue.set(orderList.get(i)+"\t"+goodsList.get(j));
//最终输出:商品id、订单编号、实际支付价格、商品编号、商品名称
context.write(key,outValue);
}
}
join,顾名思义,`在reduce阶段执行join关联操作`。这也是最容易想到和实现的 join 方式。因为通过`shuffle过程就可以将相关的数据分到相同的分组中`,这将为后面的 join 操作提供了便捷。

基本上,reduce side join大致步骤如下:
1. mapper 分别读取不同的数据集;
2. mapper 的输出中,通常以 join 的字段作为输出的 key;
3. 不同数据集的数据经过 shuffle,key 一样的会被分到同一分组处理;
4. 在 reduce 中根据业务需求把数据进行关联整合汇总,最终输出。
### 2.2 弊端
reduce 端 join 最大的问题是整个 join 的工作是在 reduce 阶段完成的,但是通常情况下 MapReduce 中 reduce 的并行度是极小的(默认是 1 个),这就使得`所有的数据都挤压到reduce阶段处理,压力颇大`。虽然可以设置 reduce 的并行度,但是又会导致最终结果被分散到多个不同文件中。
并且在数据从 mapper 到 reducer 的过程中,`shuffle阶段十分繁琐`,数据集大时成本极高。
## 3. MapReduce[分布式缓存](https://so.csdn.net/so/search?q=分布式缓存&spm=1001.2101.3001.7020)
DistributedCache 是 hadoop 框架提供的一种机制,可以`将job指定的文件,在job执行前,先行分发到task执行的机器上,并有相关机制对cache文件进行管理`。
DistributedCache 能够缓存应用程序所需的文件 (包括文本,档案文件,jar 文件等)。
Map-Redcue 框架在作业所有任务执行之前会把必要的文件拷贝到 slave 节点上。 它运行高效是因为每个作业的文件只拷贝一次并且为那些没有文档的 slave 节点缓存文档。
### 3.1 使用方式
#### 3.1.1 添加缓存文件
可以使用 MapReduce 的 API 添加需要缓存的文件。
```java
// 添加归档文件到分布式缓存中
job.addCacheArchive(URI uri);
// 添加普通文件到分布式缓存中
job.addCacheFile(URI uri);
1234
注意:需要分发的文件,必须提前放到hdfs上,默认的路径前缀是hdfs://。
3.1.2 程序中读取缓存文件
在 Mapper 类或者 Reducer 类的 setup 方法中,用输入流获取分布式缓存中的文件。
protected void setup(Context context) throw IOException,InterruptedException{
FileReader reader = new FileReader("myfile");
BufferReader br = new BufferedReader(reader);
......
}
12345
4. map side join
4.1 概述
map side join,其精髓就是在map阶段执行join关联操作,并且程序也没有了reduce阶段,避免了 shuffle 时候的繁琐。实现的关键是使用MapReduce的分布式缓存。
尤其是涉及到一大一小数据集的处理场景时,map 端的 join 将会发挥出得天独厚的优势。
map side join 的大致思路如下:
- 首先分析 join 处理的数据集,使用分布式缓存技术将小的数据集进行分布式缓存;
- MapReduce 框架在执行的时候会自动将缓存的数据分发到各个 maptask 运行的机器上;
- 程序只运行 mapper,在 mapper 初始化的时候从分布式缓存中读取小数据集数据,然后和自己读取的大数据集进行 join 关联,输出最终的结果;
- 整个 join 的过程没有 shuffle,没有 reducer;
4.2 优势
map 端 join 最大的优势减少 shuffle 时候的数据传输成本。并且 mapper 的并行度可以根据输入数据量自动调整,充分发挥分布式计算的优势。
5. MapReduce join案例:订单商品处理
5.1 需求
有两份结构化的数据文件:itheima_goods(商品信息表)、itheima_order_goods(订单信息表),具体字段内容如下。
要求使用MapReduce统计出每笔订单中对应的具体的商品名称信息。比如107860商品对应着:AMAZFIT黑色硅胶腕带。
数据文件链接:https://pan.baidu.com/s/1W7lk7jA66bHC6-ShkxNeJQ ,提取码:6666
5.1.1 itheima_goods
5.1.1 itheima_order_goods
5.2 Reduce Side实现
5.2.1 分析
使用 mapper 处理订单数据和商品数据,输出的时候以 goodsId 商品编号作为 key。相同 goodsId 的商品和订单会到同一个 reduce 的同一个分组,在分组中进行订单和商品信息的关联合并。在 MapReduce 程序中可以通过 context 获取到当前处理的切片所属的文件名称。根据文件名来判断当前处理的是订单数据还是商品数据,以此来进行不同逻辑的输出。
join 处理完之后,最后可以再通过 MapReduce 程序排序功能,将属于同一笔订单的所有商品信息汇聚在一起。
5.2.2 代码实现
5.2.2.1 mapper类
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
Text outKey = new Text();
Text outValue = new Text();
StringBuilder sb = new StringBuilder();
String filename =null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取当前处理的切片所属的文件名字
FileSplit inputSplit = (FileSplit) context.getInputSplit();
filename = inputSplit.getPath().getName();
System.out.println("当前正在处理的文件是:"+filename);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//设置字符串长度,此处用于清空数据
sb.setLength(0);
//切割处理输入数据
String[] fields = value.toString().split("\\|");
//判断处理的是哪个文件
if(filename.contains("itheima_goods.txt")){//处理的是商品数据
// 100101|155083444927602|四川果冻橙6个约180g (商品id、商品编号、商品名称)
outKey.set(fields[0]);
StringBuilder append = sb.append(fields[1]).append("\t").append(fields[2]);
outValue.set(sb.insert(0, "goods#").toString());
System.out.println(outKey+"---->"+outValue);
context.write(outKey,outValue);
}else{//处理的是订单数据
// 2|113561|11192 (订单编号、商品id、实际支付价格)
outKey.set(fields[1]);
StringBuilder append = sb.append(fields[0]).append("\t").append(fields[2]);
outValue.set(sb.insert(0, "order#").toString());
System.out.println(outKey+"---->"+outValue);
context.write(outKey,outValue);
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041
5.2.2.2 reducer类
public class ReduceJoinReducer extends Reducer<Text,Text,Text,Text> {
//用来存放 商品编号、商品名称
List<String> goodsList = new ArrayList<>();
//用来存放 订单编号、实际支付价格
List<String> orderList = new ArrayList<>();
Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//遍历values
for (Text value : values) {
//将结果添加到对应的list中
if(value.toString().startsWith("goods#")){
String s = value.toString().split("#")[1];
goodsList.add(s);

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









