








 超级会员免费看
超级会员免费看

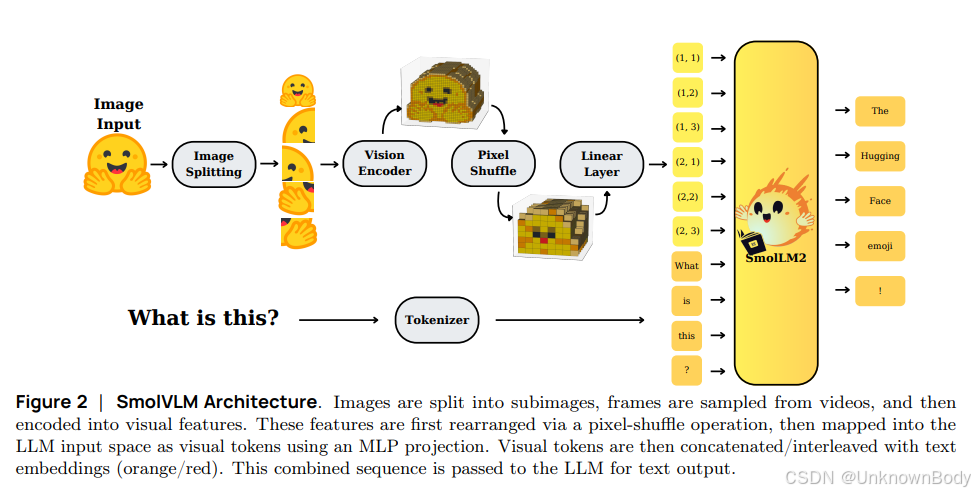
主要内容
- 背景与挑战:视觉语言模型(VLMs)能力提升但资源需求大,小模型常借鉴大模型设计导致内存使用低效。
- 模型设计
- 架构探索:分析视觉编码器和语言模型间的计算分配,发现平衡的参数分配更优;扩展上下文长度、采用像素混洗等策略提高模型性能。
- 指令微调:研究视觉和文本标记化、数据组合等对模型性能的影响,如学习位置标记优于字符串标记,谨慎使用大语言模型微调文本数据等。
- 实验结果
- 构建模型变体:构建SmolVLM - 256M、SmolVLM - 500M和SmolVLM - 2.2B三种模型,适用于不同计算环境。
- 训练数据:分视觉和视频阶段训练,使用多种数据集并合理分配数据比例。
- 性能评估:在多个视觉语言和视频基准测试中表现出色,内存使用效率高;在边缘设备上

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











