







一. Kafka的分区数是不是越多越好?
1、 分区多的优点
Kafka使用分区将topic的消息打算到多个分区分布保存在不同的broker上,实现了producer和consumer消息处理的高吞吐量。
Kafka的producer和consumer都可以多线程地并行操作,而每个线程处理的是一个分区的数据。
因此分区实际上是调优Kafka并行度的最小单元。
对于producer而言,它实际上是用多个线程并发地向不同分区所在的broker发起socket连接,同时给这些分区发送消息。
对于consumer,同一个消费组内的所有consumer线程都被指定topic的某一个分区进行消费。
所以说,如果一个topic分区越多,理论上整个集群所能达到的吞吐量就约到
2、 分区不是越多越好
分区是否越多越好呢?显然也不是,因为每个分区都有自己的开销:
2.1、分区越多,客户端/服务器端需要使用的内存就越多
1)producer
Kafka0.8.2之后,在客户端producer有个参数batch.size,默认是16KB。它会为每个分区缓存消息(每个分区缓存默认16KB)。一旦满了就打包将消息批量发出。
如果分区越多,这部分缓存所需的内存占用也会更多。
假设你有10000个分区,按照默认设置,生产端这部分缓存需要占用约157MB的内存(16*10000/157)。
2)consumer
抛开获取数据所需的内存不说,只说线程的开销。
如果还是假设10000个分区,同时consumer线程数要匹配分区数(大部分情况下是最佳的消费吞吐量配置)的话,在consumer client就要创建10000个线程,也需要创建大约10000个socket去获取分区数据。
线程切换的开销本身已经不容小觑了。
3)服务器
服务器的开销也不小,如果阅读kafka源码的话可以发现,服务器端的很多组件都在内存中维护了分区级别的缓存。
比如controller,FetcherManager等,因此分区数越多,这种缓存的成本就越大。
2.2、分区越多,文件句柄的开销越多
每个分区在底层文件系统都有属于自己的一个目录。该目录下通常会有两个文件:base_offset.log和base_offset.index。
Kakfa的controller和ReplicaManager会为每个broker都保存这两个文件句柄(file handler)。
如果分区数越多,所需要保持打开状态的文件句柄数也就越多,最终可能会突破你的ulimit-n的限制。
2.3、分区越多,会降低高可用性
Kafka通过副本(replica)机制来保证高可用。
具体做法就是为每个分区保存若干个副本(replica_factor指定副本数)。
每个副本保存在不同的broker上,其中一个副本充当leader副本,负责处理producer和consumer请求,其他副本充当follower角色,由Kafka controller负责保证与leader的同步。
如果leader所在的broker挂掉了,controller会检测到然后在zookeeper的帮助下重新选出新的leader–这中间会有短暂的不可用时间窗口。
虽然大部分情况下可能只有几毫秒级别,但是如果你有10000个分区,10个broker,也就是平均每个broker上有1000个分区。此时broker挂掉了,那么zookeeper和controller需要立即对这1000个分区进行leader选举。
比起很少的分区leader选举而言,多个分区的选举要花更长的时间,并且通常不是线性累加的。
二. 如何确定分区个数?
创建一个只有1个分区的topic
测试这个topic的producer吞吐量和consumer吞吐量。
假设他们的值分别是Tp和Tc,单位可以是MB/s.
然后假设总的目标吞吐量是Tt,那么分区数=Tt/max(Tp,Tc)
如何测试Kafka的producer和consumer吞吐量,详见Kakfa吞吐量基准测试
三. 一条消息如何知道要背发送到哪个分区?
3.1、 按照key值分配
默认情况下,Kafka根据传递消息的key来进行分区的分配,即hash(key)% numParitions:
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这保证了相同key的消息一定会被分配到相同的分区。
3.2 key为null时,从缓存中获取分区id或者随机取一个
if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
不指定key时,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区好加入到缓存中以备直接使用–当然,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
四、 Consumer个数与分区数有什么关系?
同一时间,topic下的一个分区只能被同一个consumer group下的一个consumer线程来消费。
但反之并不成立,即一个consumer线程可以消费多个分区的数据,比如Kafka提供的ConsoleConsumer,默认就只是一个线程来消费所有分区的数据。
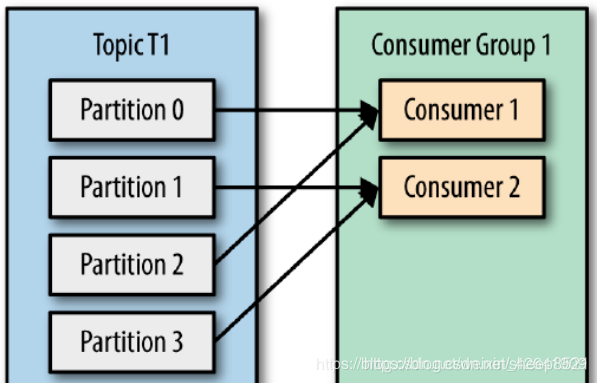
所以,如果你的分区数是N,那么最好线程数也保持为N,这样通常能够达到最大的吞吐量。超过N的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。
五. Consumer消费Parition的分配策略
Kafka提供的两种分配策略: range和roundrobin,由参数partition.assignment.strategy指定,默认是range策略。
当以下事件发生时,Kafka 将会进行一次分区分配:
- 同一个 Consumer Group 内新增消费者
- 消费者离开当前所属的Consumer Group,包括shuts down 或
crashes - 订阅的主题新增分区
将分区的所有权从一个消费者移到另一个消费者称为重新平衡(rebalance),如何rebalance就涉及到本文提到的分区分配策略。
下面我们将详细介绍 Kafka 内置的两种分区分配策略。本文假设我们有个名为 T1 的主题,其包含了10个分区,然后我们有两个消费者(C1,C2)
来消费这10个分区里面的数据,而且 C1 的 num.streams = 1,C2 的 num.streams = 2。
5.1. Range strategy
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。在我们的例子里面,排完序的分区将会是0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是C1-0, C2-0, C2-1。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程, 10 / 3 = 3,而且除不尽,那么消费者线程 C1-0 将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C2-1 将消费 7, 8, 9 分区
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6, 7 分区
C2-1 将消费 8, 9, 10 分区
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3分区
C2-0 将消费 T1主题的 4, 5, 6 分区以及 T2主题的 4, 5, 6分区
C2-1 将消费 T1主题的 7, 8, 9 分区以及 T2主题的 7, 8, 9分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了2个分区,这就是Range strategy的一个很明显的弊端。
5.2、 RoundRobin strategy
使用RoundRobin策略有两个前提条件必须满足:
同一个Consumer Group里面的所有消费者的num.streams必须相等;
每个消费者订阅的主题必须相同。
所以这里假设前面提到的2个消费者的num.streams = 2。RoundRobin策略的工作原理:将所有主题的分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按照 hashCode 进行排序,看下面的代码应该会明白:
val allTopicPartitions = ctx.partitionsForTopic.flatMap { case(topic, partitions) =>
info("Consumer %s rebalancing the following partitions for topic %s: %s"
.format(ctx.consumerId, topic, partitions))
partitions.map(partition => {
TopicAndPartition(topic, partition)
})
}.toSeq.sortWith((topicPartition1, topicPartition2) => {
/*
* Randomize the order by taking the hashcode to reduce the likelihood of all partitions of a given topic ending
* up on one consumer (if it has a high enough stream count).
*/
topicPartition1.toString.hashCode < topicPartition2.toString.hashCode
})
最后按照round-robin风格将分区分别分配给不同的消费者线程。
最后按照round-robin风格将分区分别分配给不同的消费者线程。
在这个的例子里面,假如按照 hashCode 排序完的topic-partitions组依次为T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9,我们的消费者线程排序为C1-0, C1-1, C2-0, C2-1,最后分区分配的结果为:
C1-0 将消费 T1-5, T1-2, T1-6 分区;
C1-1 将消费 T1-3, T1-1, T1-9 分区;
C2-0 将消费 T1-0, T1-4 分区;
C2-1 将消费 T1-8, T1-7 分区;
多个主题的分区分配和单个主题类似。遗憾的是,目前我们还不能自定义分区分配策略,只能通过partition.assignment.strategy参数选择 range 或 roundrobin。















 7579
7579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









