






本系统(程序+源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。
系统程序文件列表
开题报告内容
一、研究背景
随着互联网的迅速发展,豆瓣电影作为一个知名的电影评分和评论平台,积累了海量的电影相关数据,包括电影信息、评分、影评等。这些数据蕴含着丰富的信息,如观众的观影偏好、电影市场的发展趋势等。然而,由于数据量庞大且结构复杂,如何有效地挖掘和分析这些数据成为了一个挑战。在大数据技术不断发展的背景下,Spark作为一种快速、通用的大规模数据处理引擎,为处理和分析豆瓣电影数据提供了强大的技术支持。此外,人们对电影的需求不断增加,不仅是观影,还包括对电影相关信息的深入了解,这也促使了对豆瓣电影数据进行分析和可视化的研究 12 。
二、研究意义
- 对于观众而言,通过对豆瓣电影数据的分析和可视化,可以帮助他们更好地了解电影的整体质量、热门电影类型等信息,从而在众多电影中做出更符合自己喜好的选择。
- 对于电影制作方和发行方来说,分析豆瓣电影数据能够洞察观众的需求和喜好,为电影的制作、宣传和发行策略提供依据,提高电影的市场竞争力。
- 从学术角度看,该研究有助于探索大数据分析技术在电影领域的应用,为相关领域的数据分析研究提供参考范例,推动数据挖掘和可视化技术的发展 12 。
三、研究目的
- 深入挖掘豆瓣电影数据中的潜在信息,包括电影评分的分布情况、影评的时间分布、电影标题或描述中的高频词汇等。
- 通过可视化的方式将分析结果直观地展示出来,如以折线图展示电影上线走势,以直方图展示电影评分等级等,使用户能够更便捷地理解数据背后的意义。
- 构建一个基于Spark的豆瓣电影数据分析与可视化系统,为观众、电影制作方和研究者提供一个有效的数据查询、分析和展示平台 12 。
四、研究内容
- 电影数据采集
- 利用Python爬虫技术从豆瓣电影网站采集数据,确保采集到的数据全面且准确。采集的数据类型包括电影的基本信息(如名称、导演、主演、类型等)、评分信息、影评内容等。由于豆瓣电影数据量庞大,需要合理设计爬虫算法,提高数据采集效率,同时要遵守网站的相关规定,避免对网站造成不必要的负担。
- 对采集到的数据进行预处理,包括数据清洗(去除重复数据、错误数据等)、数据转换(将数据转换为适合分析的格式)等操作,为后续的数据分析奠定良好的基础。
- 基于Spark的数据分析
- 电影评分分析:分析电影评分的分布情况,如计算平均分、找出评分最高和最低的电影、分析不同类型电影的评分差异等。通过这些分析,可以了解电影的整体质量情况,以及观众对不同类型电影的评价倾向。
- 影评时间统计分析:统计影评的时间分布,确定影评的活跃时间段。这有助于了解观众在电影上映后的不同时间点的反应,也可以为电影的宣传和推广策略提供参考。例如,如果发现电影上映后的某一时间段内影评数量激增,那么电影制作方可以在这个时间段加大宣传力度。
- 电影高频词统计分析:统计电影标题或描述中的高频词汇,从而挖掘电影的主题热点。这些高频词可以反映出当前电影市场的流行趋势,如某些特定类型的角色、场景或者情节比较受关注。
- 历年电影上线走势分析:分析电影上线的时间分布,找出电影上线数量较高的年份或时间段,了解电影市场的活跃期。这对于电影制作方和发行方安排电影的上映计划具有重要意义。
- 可视化展示
- 根据数据分析的结果,选择合适的可视化工具(如Echart等)进行展示。例如,用折线图展示历年电影上线走势,用直方图展示电影评分等级,用词云图展示电影高频词等。通过可视化展示,将复杂的数据以直观的形式呈现给用户,提高数据的可读性和可理解性。
- 设计用户友好的可视化界面,方便用户进行数据查询、筛选和交互操作。例如,用户可以根据自己的需求选择不同的电影类型、时间段等进行数据查看,也可以对可视化图表进行放大、缩小、排序等操作。
五、拟解决的主要问题
- 数据采集与清洗问题
- 豆瓣电影网站的数据结构复杂且可能存在数据更新频繁、数据格式不统一等问题。需要解决如何高效采集数据并确保数据质量的问题,例如如何处理动态加载的数据、如何识别和纠正错误数据等。
- 由于数据量较大,在数据采集过程中可能会遇到网络限制、爬虫被封禁等问题。需要研究如何优化爬虫算法,提高数据采集的效率和稳定性,如采用分布式爬虫技术、设置合理的爬虫频率等。
- 数据分析算法优化问题
- 针对海量的电影数据,如何选择合适的数据分析算法以提高分析效率和准确性是一个关键问题。例如,在进行电影评分分析时,如何快速准确地计算大量电影的平均分和评分分布,在进行高频词统计时,如何处理中文分词等问题。
- 不同类型的数据之间可能存在关联,如何挖掘这些数据之间的深层次关系是需要解决的问题。例如,电影的评分与影评内容之间的关系,电影类型与上映时间之间的关系等。
- 可视化效果与用户体验问题
- 如何选择合适的可视化方式来展示不同类型的分析结果,使可视化效果既能准确传达数据信息,又具有良好的视觉效果。例如,对于电影评分等级的展示,如何选择合适的颜色、刻度等元素,使直方图更加直观。
- 设计一个用户友好的可视化界面,提高用户的交互体验。需要考虑用户的操作习惯和需求,提供便捷的数据查询、筛选和交互功能,如如何让用户快速找到自己感兴趣的数据,如何实现可视化图表的动态交互等。
六、研究方案
- 技术选型
- 选择Spark作为主要的数据处理框架,利用其强大的分布式计算能力处理海量的豆瓣电影数据。Spark具有内存计算、高效的数据处理速度等优点,适合处理大规模数据的分析任务。
- 使用Python作为爬虫开发语言,Python具有丰富的爬虫库(如Scrapy等)和数据处理库(如Pandas等),便于进行数据采集和预处理。
- 采用Echart等可视化工具进行数据可视化,Echart具有丰富的可视化图表类型和良好的交互性,可以满足不同类型数据的可视化需求。
- 数据采集与处理
- 开发Python爬虫程序,根据豆瓣电影网站的页面结构和数据接口,编写爬虫规则,实现数据的自动采集。在采集过程中,采用多线程或分布式爬虫技术提高采集效率,同时设置合理的爬虫频率,避免对网站造成过大压力。
- 对采集到的数据进行清洗和预处理,利用Python的数据处理库进行数据去重、错误数据修正、数据格式转换等操作。将处理后的数据存储到合适的数据存储系统(如Hadoop分布式文件系统等)中,以便后续的数据分析。
- 数据分析与可视化
- 在Spark框架下,使用Spark SQL、Spark MLlib等组件进行数据分析。例如,利用Spark SQL进行数据查询和聚合操作,利用Spark MLlib进行数据挖掘和机器学习算法的应用。根据不同的分析目标,编写相应的数据分析脚本,如电影评分分析脚本、影评时间统计分析脚本等。
- 根据数据分析的结果,使用Echart等可视化工具进行可视化展示。根据数据类型和分析目的选择合适的可视化图表类型,如折线图、直方图、词云图等。通过编写前端代码,将可视化图表集成到系统的用户界面中,实现数据的可视化展示和用户交互操作。
- 系统测试与优化
- 对构建的基于Spark的豆瓣电影数据分析与可视化系统进行测试,包括功能测试、性能测试等。功能测试主要检查系统的各项功能是否正常工作,如数据采集是否准确、数据分析是否正确、可视化展示是否符合预期等。性能测试主要检查系统在处理大规模数据时的性能表现,如数据处理速度、系统响应时间等。
- 根据测试结果,对系统进行优化。优化的内容包括算法优化、代码优化、系统架构优化等。例如,如果发现数据处理速度较慢,可以对数据分析算法进行优化;如果发现系统响应时间较长,可以对系统架构进行调整,如增加计算资源、优化数据存储结构等。
七、预期成果
- 构建一个完整的系统
- 成功构建一个基于Spark的豆瓣电影数据分析与可视化系统,该系统具有稳定的数据采集、处理、分析和可视化展示功能。系统能够高效地采集豆瓣电影数据,准确地进行数据分析,并以直观的可视化方式展示分析结果。
- 形成详细的研究报告
- 撰写一份详细的研究报告,阐述基于Spark的豆瓣电影数据分析与可视化系统的研究背景、意义、目的、研究内容、研究方案和研究成果等内容。报告中还应包括对研究过程中遇到的问题及解决方案的总结,以及对未来研究方向的展望。
- 提供可复用的技术方案
- 通过本研究,提供一套可复用的基于Spark的电影数据处理和分析的技术方案,包括数据采集、清洗、分析和可视化等方面的技术实现。该技术方案可以为其他类似的数据分析项目提供参考和借鉴,推动大数据技术在电影领域的应用和发展。
进度安排:
第 1 阶段:2022年6月底 完成选题及开题答辩
第 2 阶段:2022年7月可行性分析、需求分析、确定系统功能模块
第 3 阶段:2022年8月-12月系统设计及实现,根据完成情况着手论文撰写
第 4 阶段:2023年1月中旬中期检查
第 5 阶段:2023年2月中旬完成系统测试
第 6 阶段:2023年3月底完成论文及论文检测
第 7 阶段:2023年4月作品验收及准备论文答辩
第 8 阶段:2023年5月中旬 论文答辩
参考文献:
[1]孟维成. 对基于Java语言实现数据库的访问研究[J]. 软件, 2022, 43 (02): 169-171.
[2]刘学玉. JAVA编程语言在计算机软件开发中的应用[J]. 电子技术与软件工程, 2022, (01): 57-60.
[3]杨鑫. 《Java程序设计》的软件开发实践能力教学资源建设[J]. 中国新通信, 2021, 23 (24): 64-65.
[4]朱姝. Java程序设计语言在软件开发中的运用初探[J]. 电子测试, 2021, (21): 72-74.
[5]祝明慧. 祝明慧. 零基础学Java程序设计[M]. 电子工业出版社: 202111. 448.
[6]赵子昂, 黄钧露. JAVA编程在计算机应用软件中的应用特征与技术研究[J]. 电子测试, 2021, (18): 83-84.
以上是开题是根据本选题撰写,是项目程序开发之前开题报告内容,后期程序可能存在大改动。最终成品以下面运行环境+技术+界面为准,可以酌情参考使用开题的内容。要本源码参考请在文末进行获取!!
运行环境
开发工具:idea/eclipse/myeclipse
数据库:mysql5.7或8.0
操作系统:win7以上,最好是win10
数据库管理工具:Navicat10以上版本
环境配置软件: JDK1.8+Maven3.3.9
服务器:Tomcat7.0
技术栈
- 前端技术:
- 使用Vue.js框架构建用户界面,这是一个现代的前端JavaScript框架,能够帮助创建动态的、单页的应用程序。
- 后端技术:
- SSM框架:这是Spring、SpringMVC和MyBatis三个框架的整合,其中:
- Spring负责业务对象的管理和业务逻辑的实现。
- SpringMVC处理Web层的请求分发,将用户的请求指派给后端的控制器处理。
- MyBatis作为数据持久层框架,负责与MySQL数据库的交互。
- SSM框架:这是Spring、SpringMVC和MyBatis三个框架的整合,其中:
- 数据库技术:
- 使用MySQL作为关系型数据库管理系统,存储应用数据。
- Navicat作为数据库可视化工具,方便进行数据库的管理、维护和设计。
- 开发环境和工具:
- JDK 1.8:Java开发工具包,用于编译和运行Java应用程序。
- Apache Tomcat 7.0:作为Web应用服务器,用于部署和运行Web应用程序。
- Maven 3.3.9:用于项目管理和构建自动化,它可以帮助您管理项目的构建、报告和文档。
- 开发流程:
- 使用Maven进行项目依赖管理和构建。
- 开发时,前后端可以分离开发,前端通过Vue.js构建用户界面,并通过Ajax与后端进行数据交互。
- 后端使用SSM框架进行业务逻辑处理和数据持久化操作。
- 开发完成后,将前端静态文件部署到Tomcat服务器,后端代码也部署在Tomcat上,实现整个Web应用的运行。
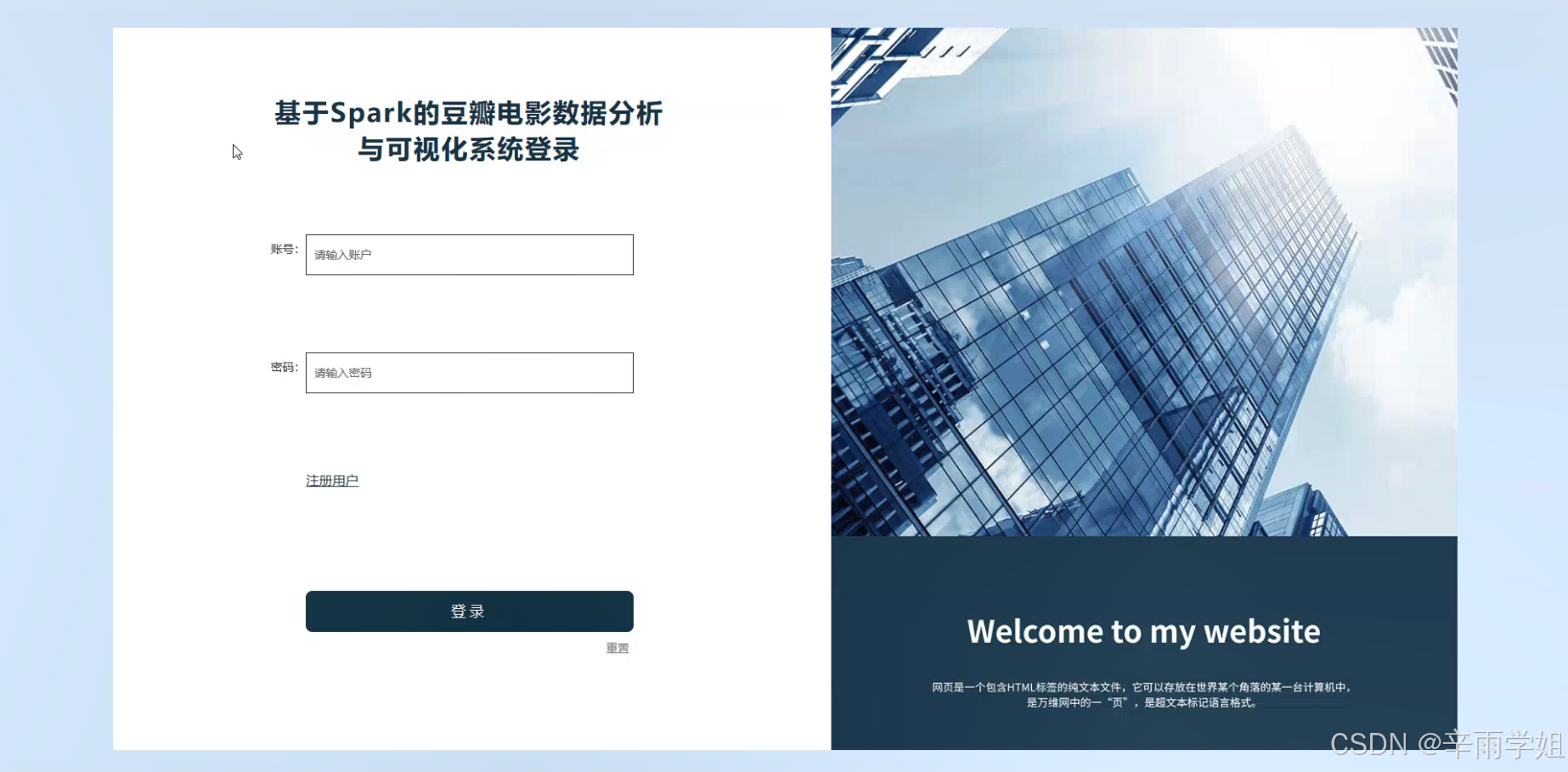
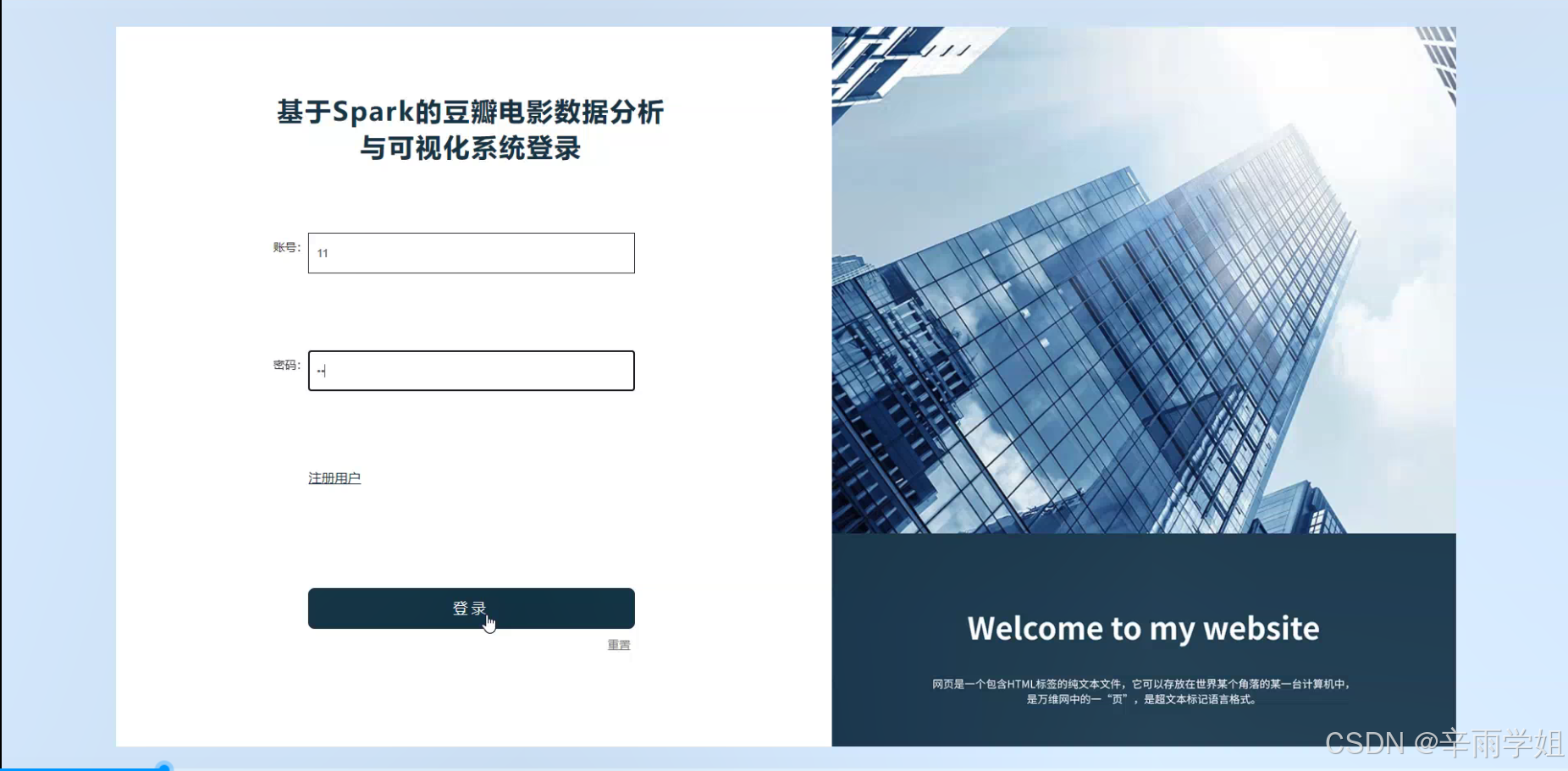
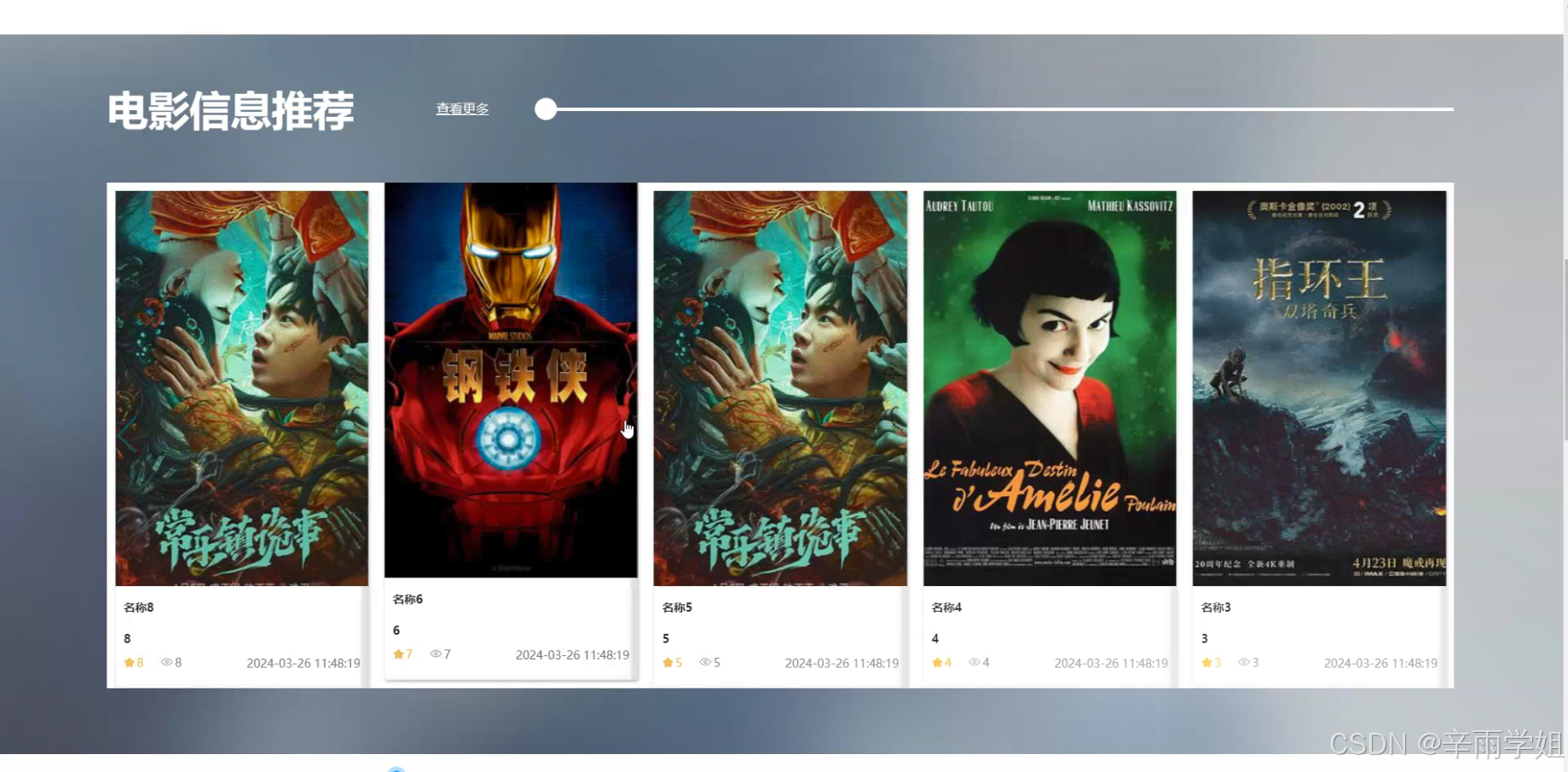
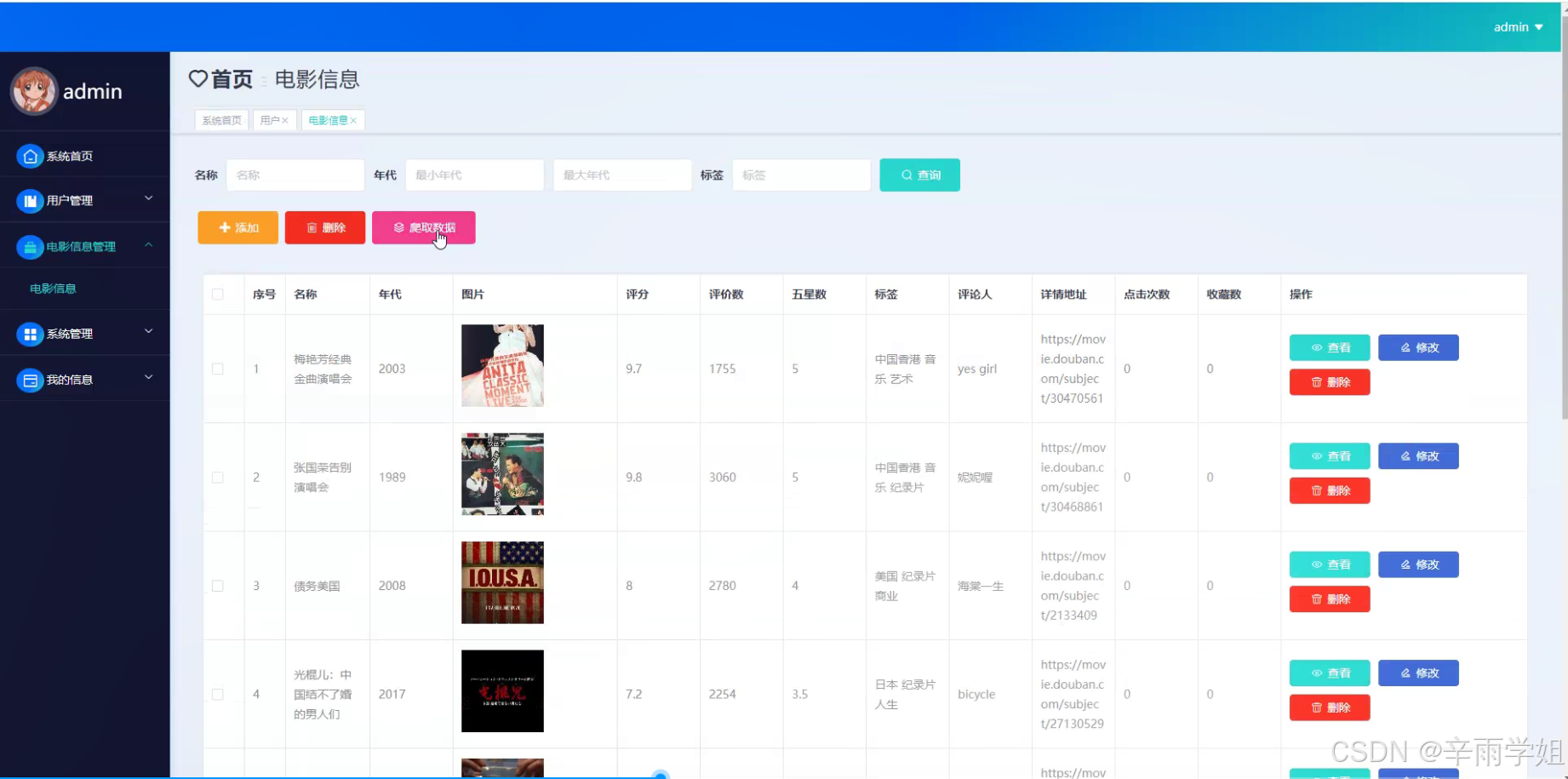
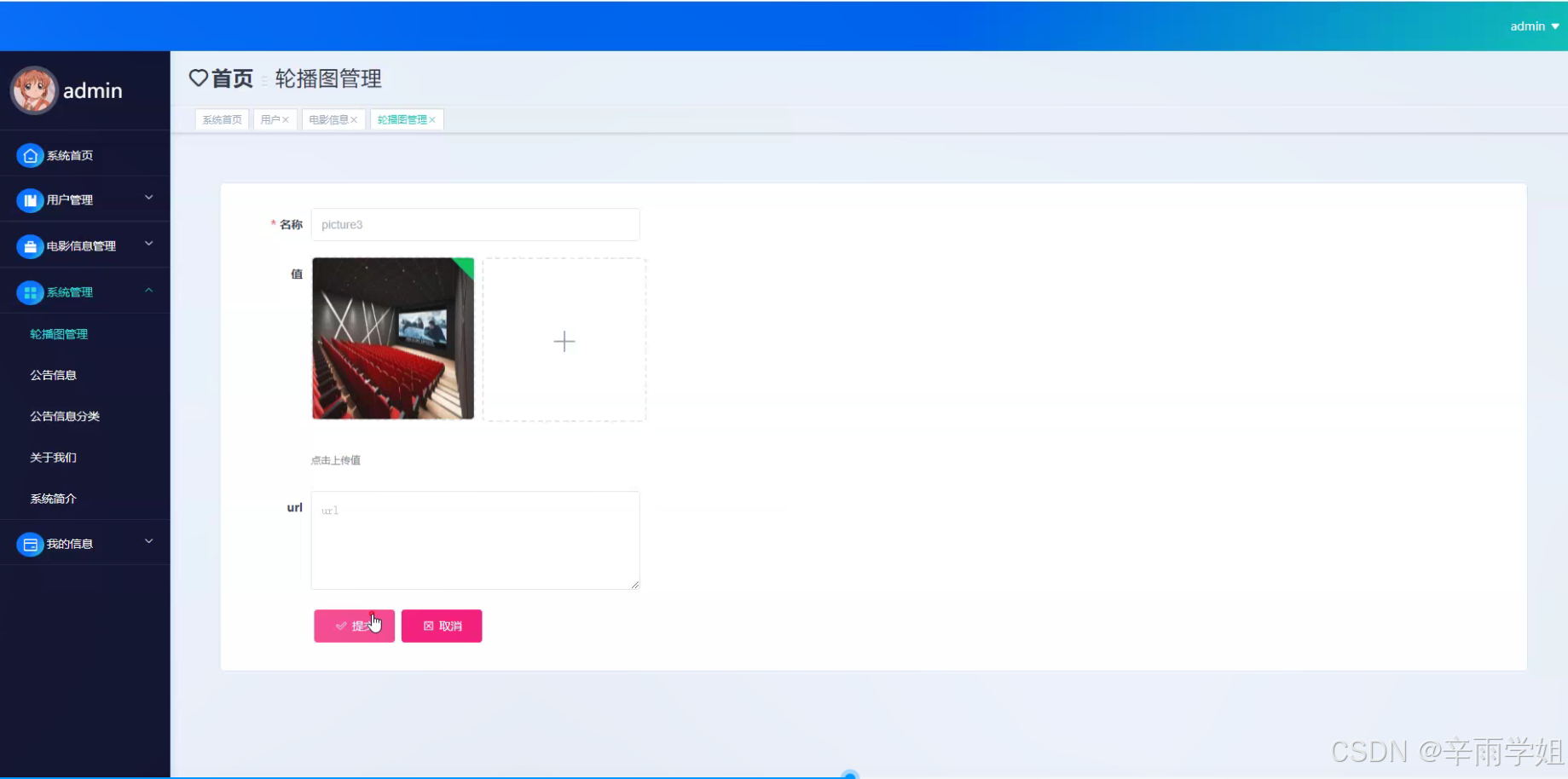
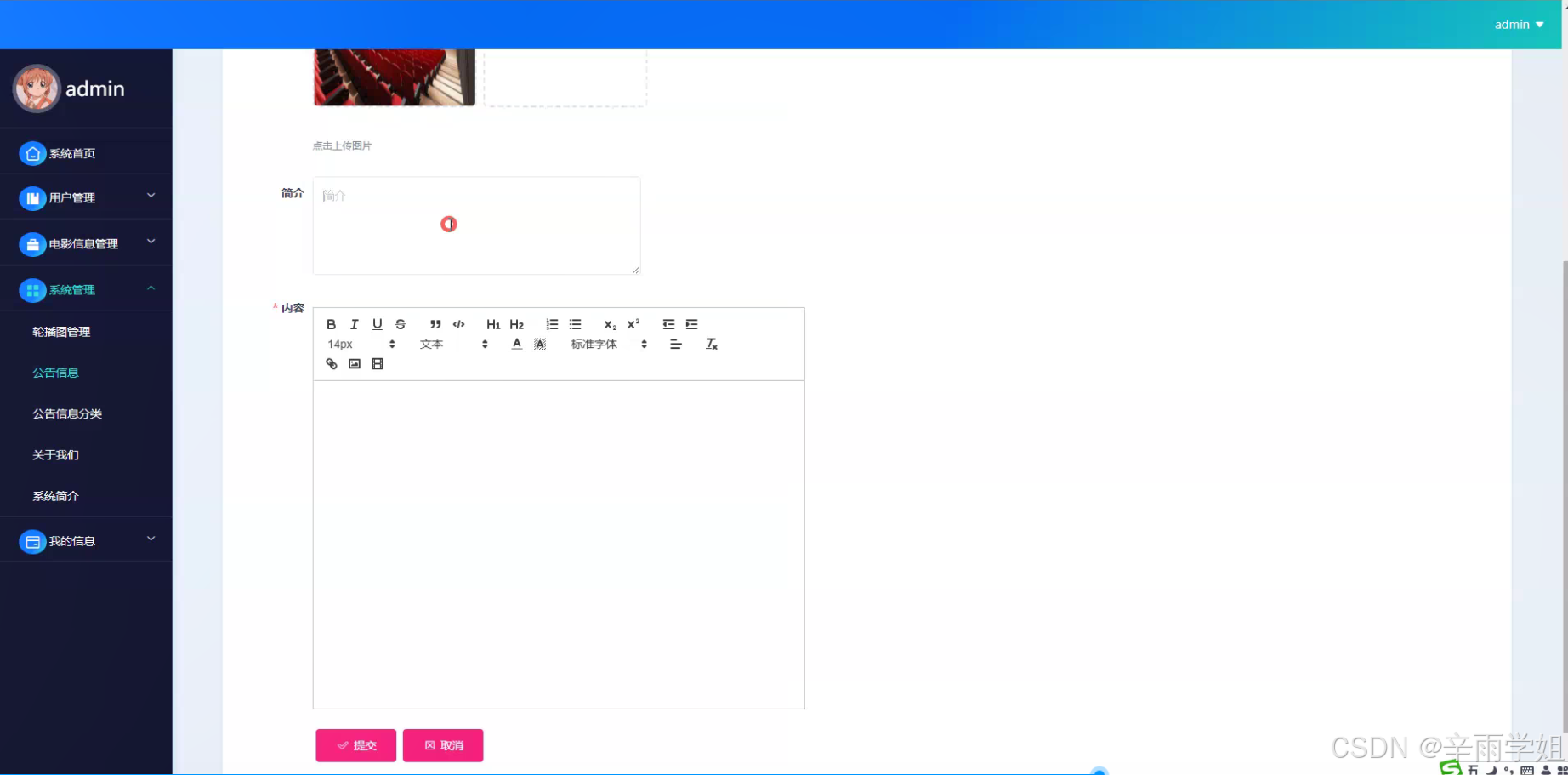
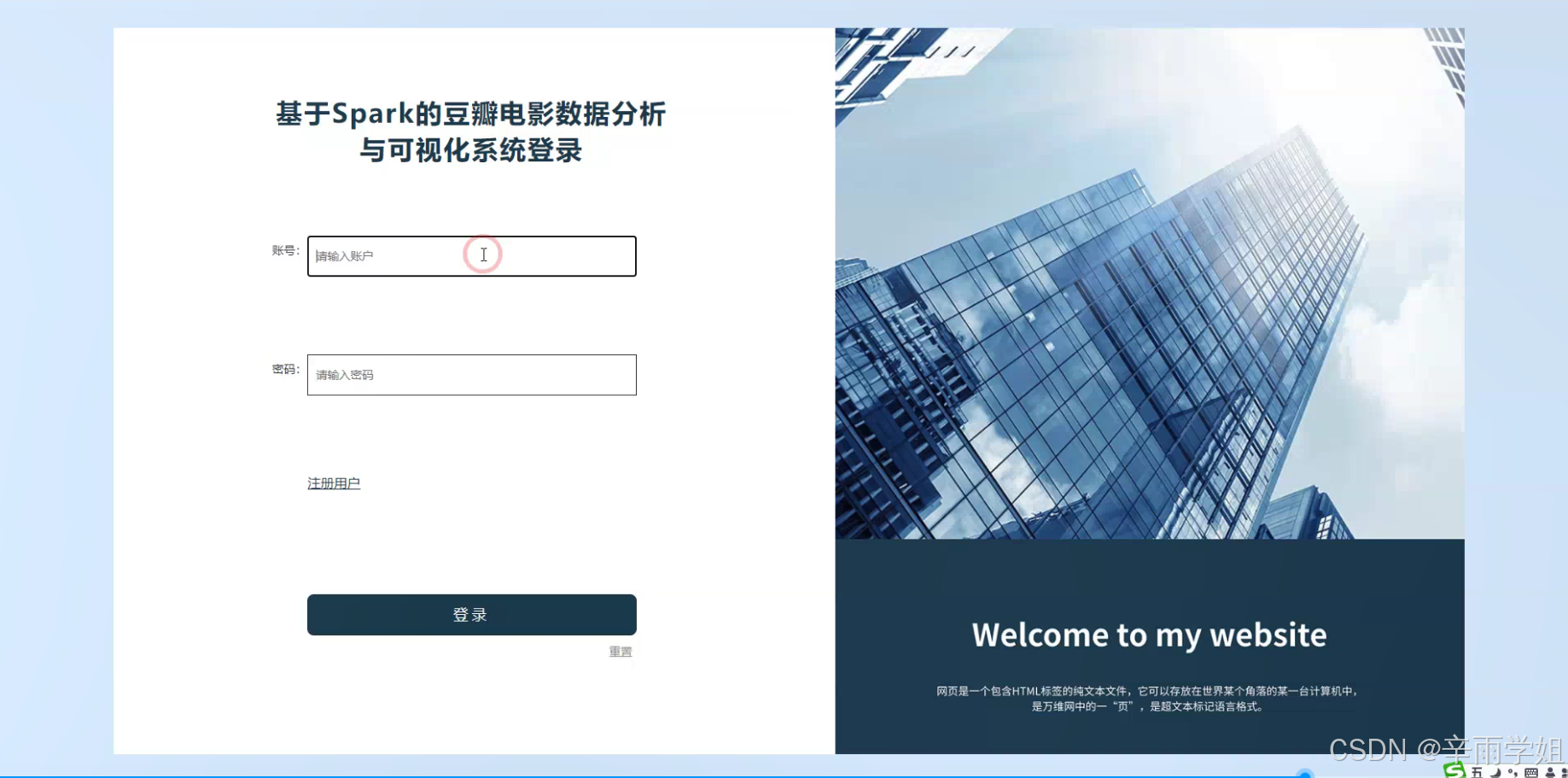
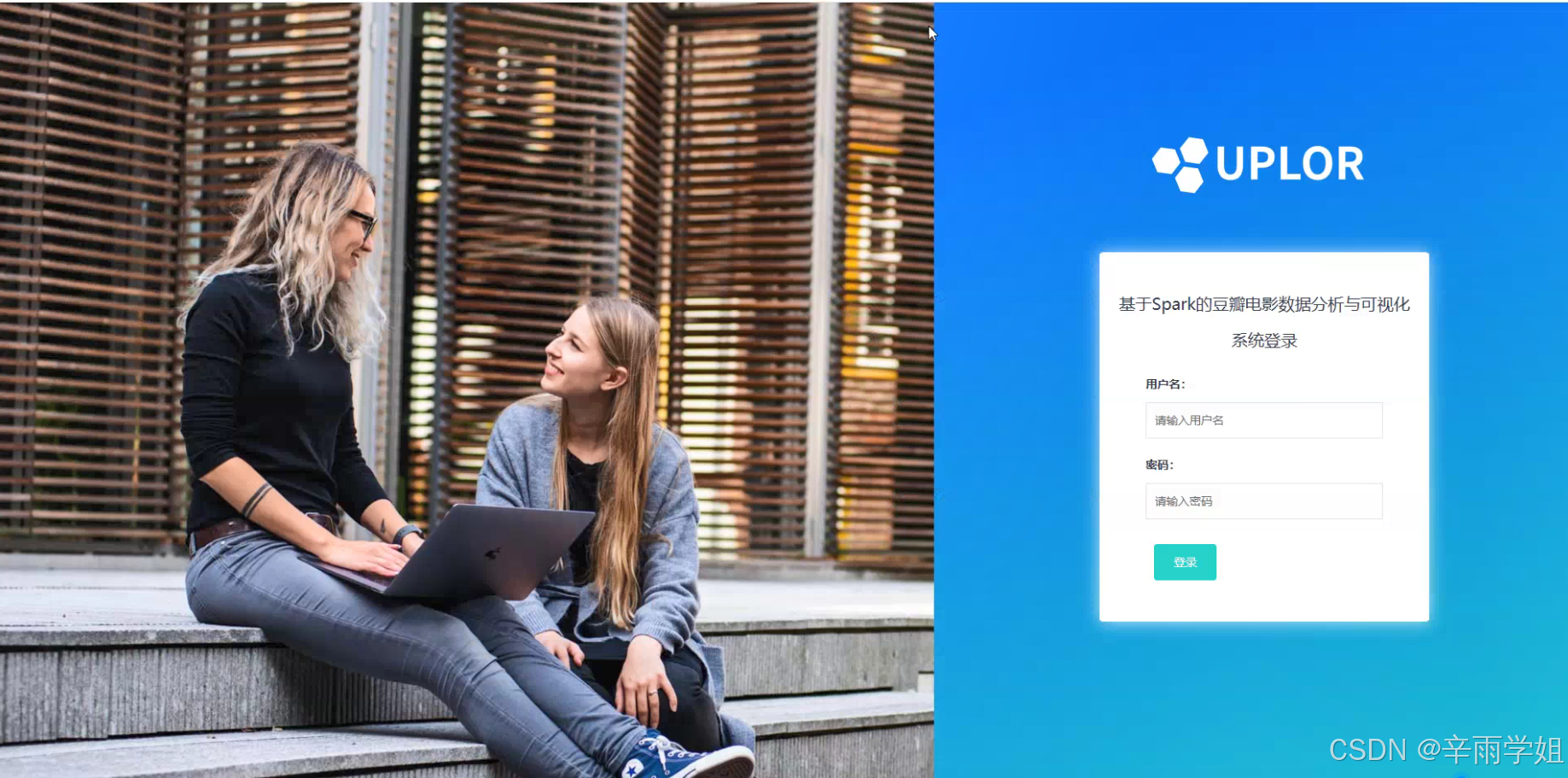
程序界面:

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









