







一、数据定义
- 数据地址:内存中每个字节空间的唯一编号值,标示数据起始存放位置
- 数据长度:数据地址之后的空间长度
- 数据结构:数据空间内各数据的实际意义(相当于数据类型)
由于由于计算机内存是一个频繁访问的部件,一次读写一个字节的方式就显得笨拙,因而设计出一次读写多字节的方式(片段访问方式)。比如Intel X86架构,CPU正常情况下可一次读写4个字节(将4个字节数据空间的首地址写入地址总线,控制读写4个字节长度的空间数据)。

二、数据结构
一个有意义的数据至少需要一个以上的内存片段来存储。
例:

一个学生的信息由学号、姓名、年龄、性别、年级、课目、成绩等组成,将这些数值分离来看,没有实际含义。只有将它们联系起来,才具有实际意义;
例:
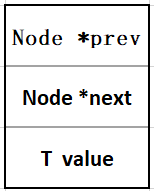
一个std::list双向链表,由若干个节点组成,每个节点就是一个内存片段。节点内部存储上一个节点的地址、下一个节点的地址及节点的数据。链表本身只存储两个地址,分别是首地址、尾地址、链表长度等信息。
三、数据对齐
CPU高速运行加之内存速度慢,按照单周期访问多字节(2字节、4字节、8字节等)的方式可以有效加快数据的存取。非对齐的地址访问需要CPU多次访问并合并数据,才能实现存取。数据的起始地址对齐一般按照2的幂值来对齐。
例:
在X86架构的32位操作系统中,对齐值通常如下:
| 类型 | 对齐 |
| char | 1 |
| short | 2 |
| int | 4 |
| double | 8 |
编译器在确定数据的地址和大小时均会应用对齐原则
对齐公式:
| aligned_address = (address + alignment - 1) & (~(alignment - 1)) | 将address值按照 alignment值对齐 |
地址计算:
data_address_aligned = (pre_data_address + sizeof(pre_data) + alignof(data) - 1) &
(~(alignof(data) - 1))
跟据data的前一个数据地址和大小,计算data的对齐地址值
四、数据序列
小端对齐(Little Endian) 将低序字节存储在起始地址
大端对齐(Big Endian) 将高序字节存储在起始地址
例:一个2字节大小的数值0x01020304的存储方式:
地址 4000 4001 4002 4003
小端 04 03 02 01
大端 01 02 03 04
X86架构数据是小端对齐,网络传输数据是大端对齐
测试自己主机字节序就是运用上述原理:
union tst_endian {
uint32 data;
struct {
uint8 u1;
uint8 u2;
uint8 u3;
uint8 u4;
};
};
tst_endian test_endian_data;
test_endian_data.data = 0x01020304;
if( test_endian_data.u1 == 0x04 ) {
//小端
}
else {
//大端
}五、数据声明
C++通过声明语法来声明一个数据。数据的声明只是把数据内部的结构信息进行了定义(编译器知道这个数据具有什么样的类型、大小、结构、名称、作用域等,便于读写这个数据)
- 内置的类型声明:char/short/int/long/long long/float/double number;
- 自定义类型声明:
struct Student {
int _number;
string _name;
...
} LeiJun;
enum/union/class Teacher;
指针:类型1 *指针名;类型2 **指针名;…
数组:类型 数组名[常量];
引用:类型 &引用名;
- 常见的数据修饰符:const、static、signed、unsigned、mutable、register
- signed 有符号
- unsigned 无符号
- static 分配于静态存储区的数据
- const 初始化后就不能改变的数据
- register 寄存器变量(因编译器智能化而极少用)
- mutable 数据随时可能改变,多线程、中断等场合使用较多
一切皆数据:
程序运行时,所有代码和数据均有序存放于内存中。把代码存放的起始地址看做一种特殊的数据,这个数据是CPU指令的调入点。
- 函数指针是一个存储函数入口地址值的变量
- lambda函数从本质来看,就是一个局部代码块
函数指针:
R(*func_name)(P1 p,...);
func_names是一个参数为P1类型、返回值是R类型的函数指针
lambda:
auto lambda = [ =/& 变量名…] (T t1,...) -> R {
语句;
…
};
[...] 表示变量捕获列表 T 参数类型 R 返回值类型
& 引用方式捕获 = 值传递方式捕获
六、空间分配
声明并初始化的数据会立即分配内存空间,读写未经过初始化的数据会出现未知的错误:
全局变量:
- main函数外声明并初始化的变量(main函数执行前分配空间、初始化顺序未知)
- 类内部声明的静态变量(main函数执行前分配空间、初始化顺序未知)
- 函数内声明的static静态变量(第一次调用时初始化,然后多次调用共享)
自定义类型:
- 只有在对象生成时才会分配空间(常量在初始化时分配空间)
七、变量的判读
(一)指针数组和数组指针的不同:
指针数组:指向数组的指针 例: T (*ptrArray)[10]
数组指针:存储指针的数组 例: T* array[10]
注意:变量名按照数组右结合,其余左结合的方式来判读
ptrArray是一个指针,这个指针指向一个含有10个T类型元素的数组
array是一个含有10个元素的数组,每个元素是T*类型的指针
(二)const远近的不同(就近原则):
//pInt1是一个指针,这个指针指向的const int类型
const int *pInt1;
//pInt2是一个常量,这个常量是一个指针,指向int类型
int * const pInt2;
//pInt3是一个常量,这个常量是一个指针,指向cosnt int类型
const int * const pInt3;
八、多维指针的实践意义
- 一维指针定义:T *name;//name存储一个T类型数据的地址
- 二维指针定义:T **name;//name存储一个T类型指针的地址
- 通用指针定义:T [*]name;//声明name为一个指针变量,*的个数是维度
一个指针变量包含2个属性:
- 指针的值:变量内存储的地址值(指向数据的开始存放地址)
- 指向的值:通过地址值访问的数据空间
对指针变量的操作包含2个维度:
- 读写指针的值(指针变量存储的地址值)
- 读写地址值对应空间的值(指针变量指向的值)
例:身份证->人员信息的对应关系
通过身份证定位人员信息并获取详细信息,指针雷同于身份证,修改指针的值(不同的身份证),修改指向的值(人员信息)
二维指针存储的是一个一维指针变量的地址值;
三维指针存储的是一个二维指针变量的地址值;
九、引用的实践意义
只有实际存在的数据才能建立引用(被引用的数据一定存在且有效,这是与指针的不同 )
对任意已存在的数据均可以建立引用(引用不存在有效和无效的问题)
十、案例分析
| 参数类设计: 一个任意类型的函数参数(变量)有哪些特性? 例: int data; Student leijun; 可以看出一个参数或变量有如下3个特性:
实际上,知道一个起始地址和类型就可以唯一确定数据了,变量名只是方便人阅读代码的工具。 QGenericArgument: 类型地址:_name 数据地址:_data
| class QGenericArgument {
#define Q_ARG(type, data) QArgument<type >(#type, data) 思 考: QArgument类实现了一个数据 -> QArguemnt的正确转换,那么反向转换(QArguemnt类型字符串 -> 带类型的数据指针)如何实现?
例: "QString” -> QString* cast() { return static_cast<QString *> (aData); } 以上类的设计与实现来自于QT库,实现了任意参数 -> QArgument的转换,达到了函数参数仅有一个类型(实际可以代表无数种类型)的效果,反向转换是作者设计(没有研究过QT是如何实现) |















 3307
3307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









