




一、神经网络(Neural network)架构torch.nn
1.1 神经网络架构
1.2 卷积神经网络
1.2.1 介绍
- 卷积神经网络(CNN)应用于计算机视觉领域,特征提取方法,任务:图像的分类和检索。
- GPU图像处理单元:GPU做卷积比CPU快得多
- 卷积网络与传统神经网络区别:数据二维->三维
- 整体架构:
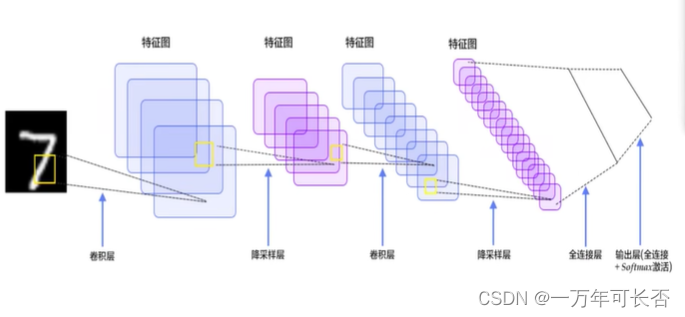
1.2.2 输入层
1.2.3 卷积层
-
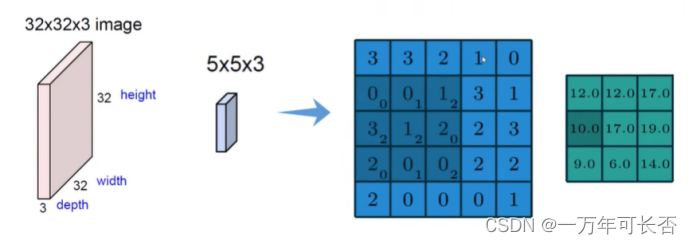
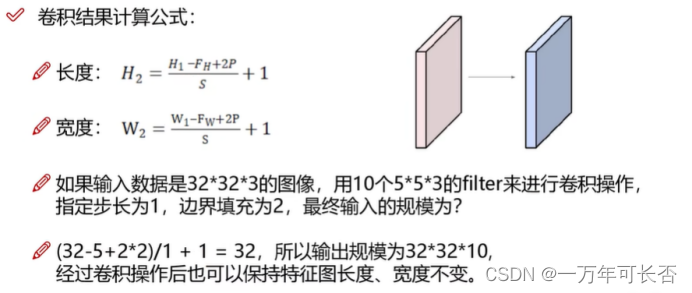
卷积的任务:图像分割成很多部分,对于不同区域提取出不同特征,经过卷积核计算,计算出每个区域的特征值,将5×5×5-> 3×3×3,卷积可做多次
-
图像颜色通道:3个颜色通道R G B做加法

-
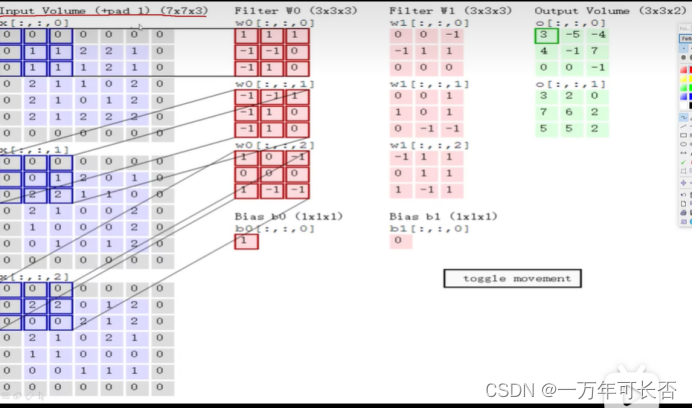
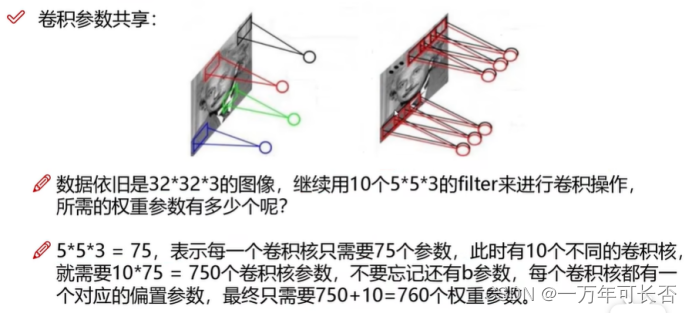
输入与不同的卷积核Filter Wi做内积得到的结果不同,一般做完卷积会加上一个偏置参数bias(下图对应:in_channel=3,out_channel=2,卷积核个数/大小为2/3×3,第一/二个bias为1/0)
-
卷积层一些参数:
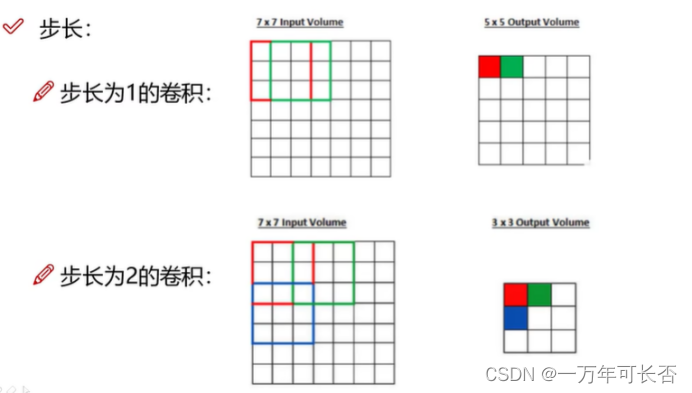
1)滑动窗口步长:不同步长得到的输出不同,一般来说步长越小精度越高,但效率会变慢,一般选择1
2)卷积核尺寸:Filter Wi的尺寸,一般选择3×3
3)边缘填充:往上数第二图的输入的图,边界的点被计算的次数少,显然不公平。于是在边界点外侧再填充一些点(灰色部分0)
4)卷积核个数(n):Filter Wi i=0,1…,n-1。要想得到多个特征图,需要设置不同的卷积核。
例:11×11 fileters at stride 4 pade 0表示卷积核尺寸11×11,步长2,填充0

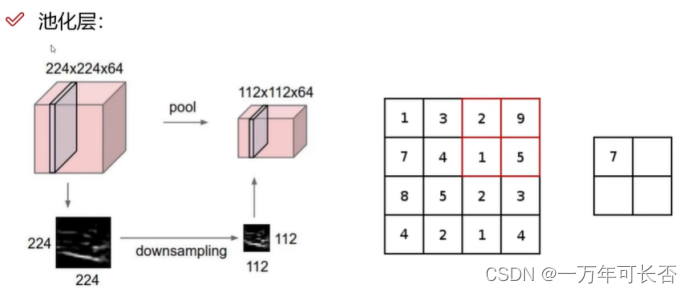
1.2.4 池化层:压缩 筛选
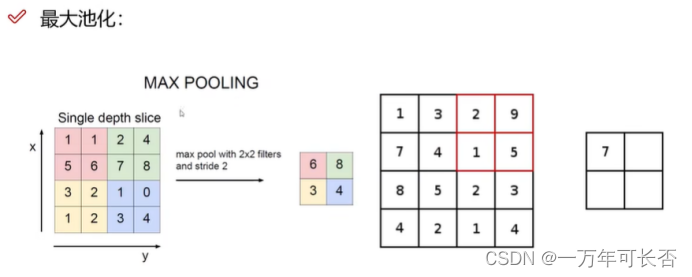
1.2.5 全连接层:卷积层和池化层只做特征提取,全连接层将一个图拉成特征向量
例如:
32×32×10->[10240,5]
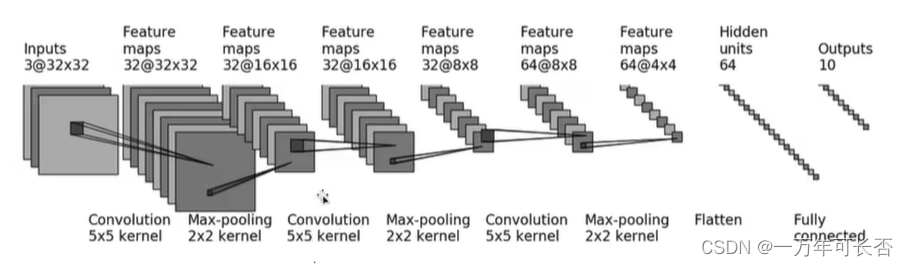
带参数计算的才算做一层,卷积(CONV计算) 激活(RELU无计算) 池化(POOL无计算) 全连接(FC计算),所以以下7层神经网络。
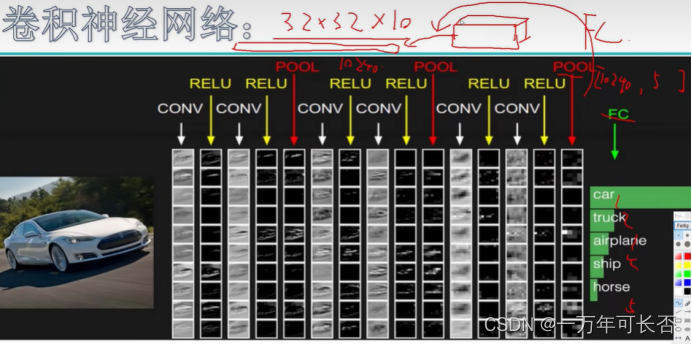
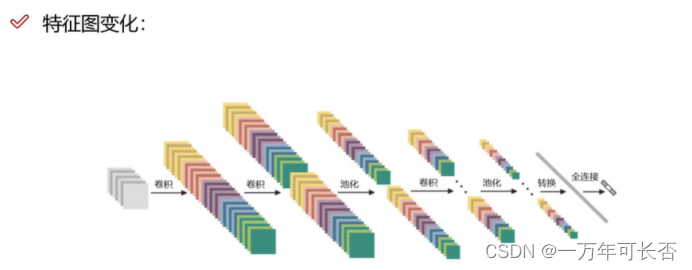
1.2.6 经典的架构:
-
12年Alexnet:8层

-
14年Vgg:16/19层,且卷积核3×3,经过maxpolling损失的信息在下一步弥补起来
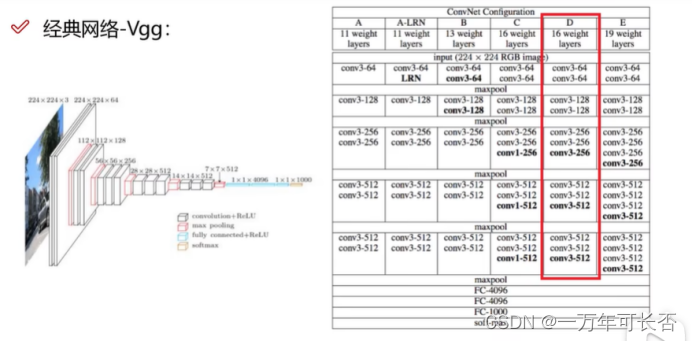
-
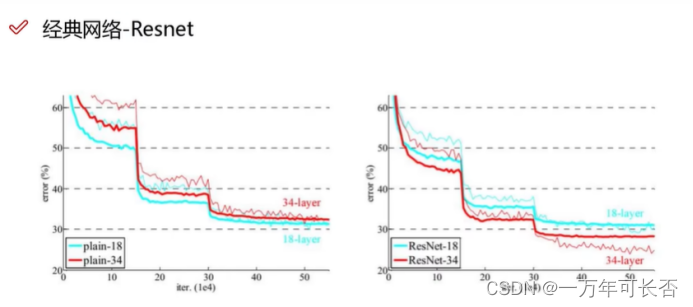
15年Resnet:按理说层数越高效果越好,但是实际并不是这样。于是,提出“同等映射”,在堆叠过程中得到F(x)如果表现不好将F(x)变为0,再在下一步加上原来的同等映射x,即F(x)+x

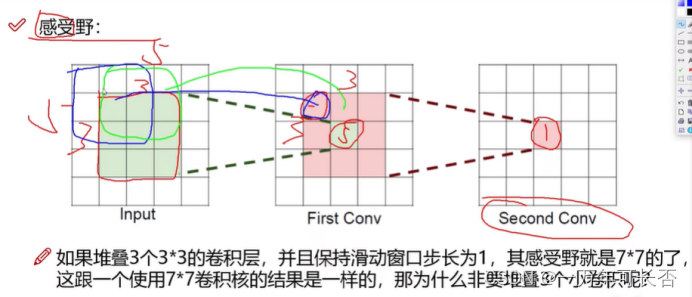
1.2.7 感受野:越大越好

二、各层的使用
2.1 容器Containers:nn.Module
import torch
from torch import nn
class Mywork(nn.Module):
# 可以使用alt+insert重写/实现方法
def __init__(self):
super().__init__()
# 前向传播
def forward(self, input):
output = input + 1
return output
mywork = Mywork()
x = torch.tensor(1.0)
output = mywork(x)
print(output)
输出:
tensor(2.)
2.2 卷积层Convolution Layers:nn.conv2d
- 代码演示
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 演示卷积层
# 进过卷积操作:64×3×32×32-》64×6×30×30
# 最后因为6通道无法输出,需要变成3通道:64×6×30×30-》128×3×30×30
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 一次取64张图片
dataloader = DataLoader(dataset, batch_size=64)
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
# 卷积设置:输入通道为3,输出通道为6,卷积核大小3×3,步数为1,不填充
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
mydata = Mydata()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs, targets = data
output = mydata(imgs)
# torch.Size([64, 3, 32, 32])
# torch.Size([64, 6, 30, 30])
# 可知输入64×3×32×32-》64×6×32×32 (数量,通道,图长,图宽)
print(imgs.shape)
print(output.shape)
writer.add_images("inputImage", imgs, step)
# 这里64×6×30×30无法直接输出,需要变成 yyy×3×30×30
# 下面参数-1表示未知,经过计算可得出为128
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("outputImage", output, step)
step = step + 1
writer.close()
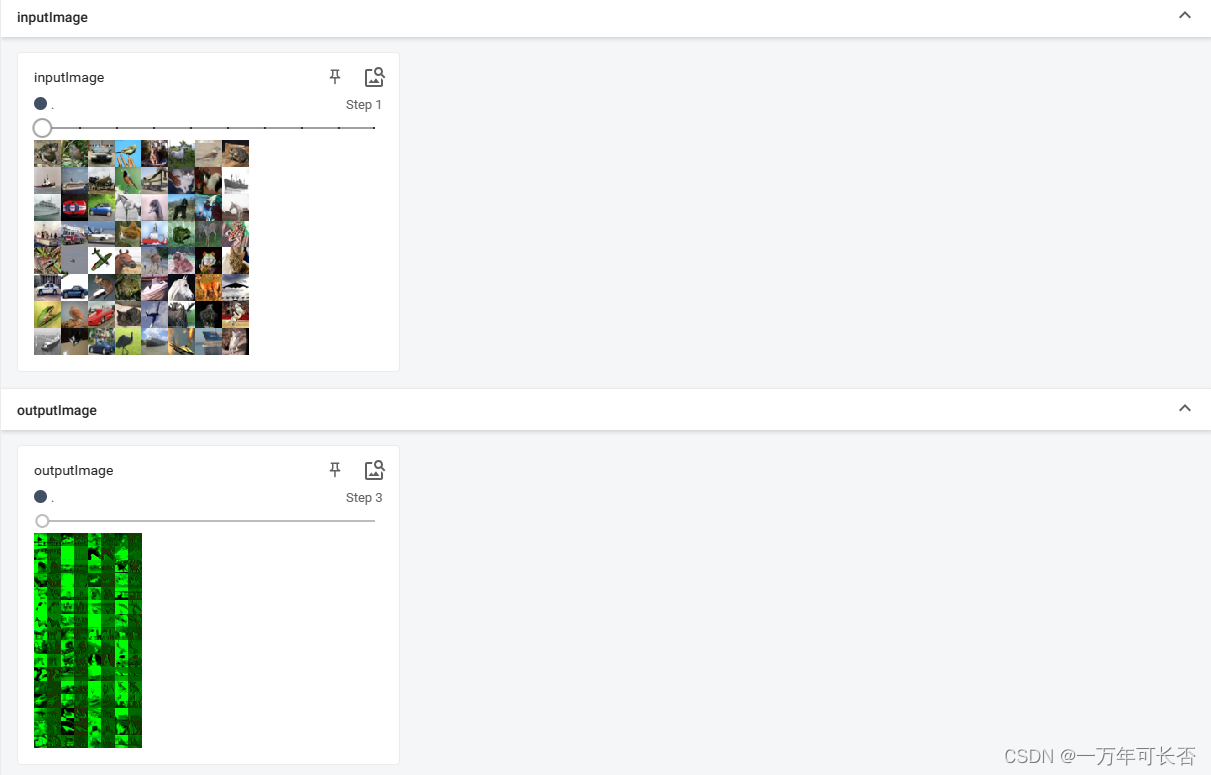
- 结果展示:可以看出经过卷积操作图片的变化
2.3 填充层Padding Layers
2.4 池化层Pooling Layers
- 代码演示
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 一次取64张图片
dataloader = DataLoader(dataset, batch_size=64)
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
# ceil_mode表示池化核移动超出边界是否保留
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, x):
x = self.maxpool1(x)
return x
mydata = Mydata()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs, targets = data
output = mydata(imgs)
writer.add_images("polling_inputImage", imgs, step)
writer.add_images("polling_outputImage", output, step)
step = step + 1
writer.close()
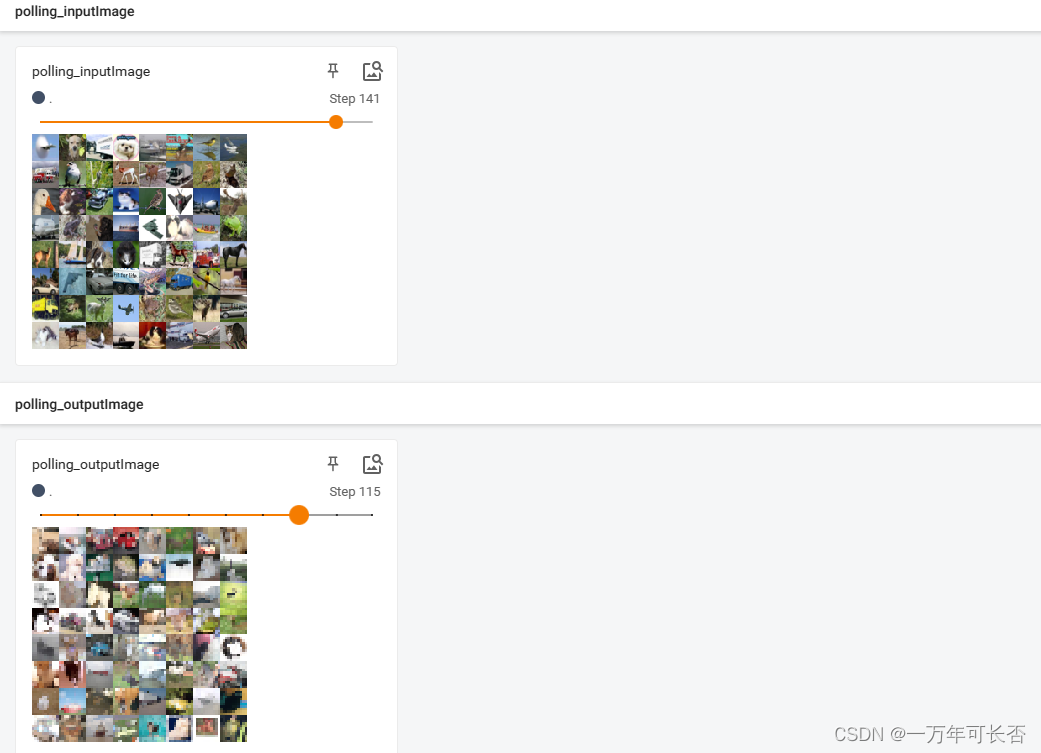
- 结果展示
2.5 非线性激活Non-linear Activations
- 代码展示
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 一次取64张图片
dataloader = DataLoader(dataset, batch_size=64)
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, x):
x = self.sigmoid1(x)
return x
mydata = Mydata()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs, targets = data
output = mydata(imgs)
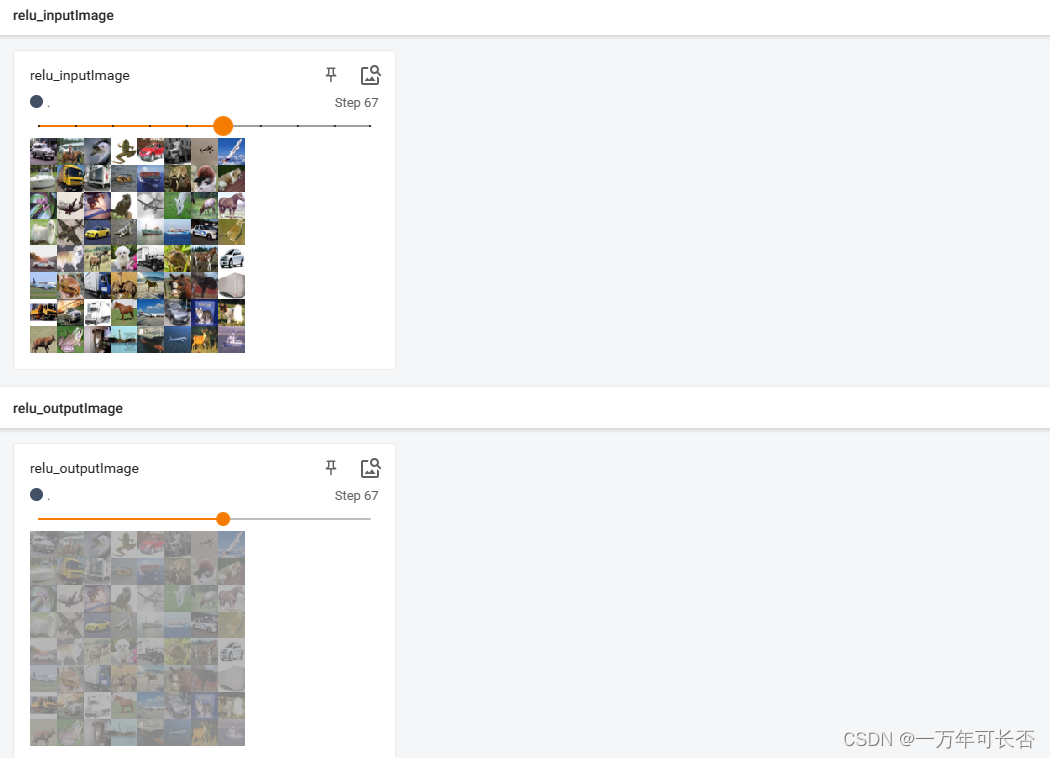
writer.add_images("relu_inputImage", imgs, step)
writer.add_images("relu_outputImage", output, step)
step = step + 1
writer.close()
- 结果展示
2.6 线性层linear Layers
通过线性层,给定输入x1…xn得到g1…gL

- 代码演示
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 一次取64张图片
dataloader = DataLoader(dataset, batch_size=64)
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, x):
x = self.linear1(x)
return x
# [64, 3, 32, 32]->[1, 1, 1, 196608]通过线性层将196608->10
mydata = Mydata()
for data in dataloader:
imgs, targets = data
print(imgs.shape) # [64, 3, 32, 32]
output = torch.reshape(imgs, (1, 1, 1, -1))
# output = torch.flatten(imgs)
print(output.shape) # [1, 1, 1, 196608]
output = mydata(output)
print(output.shape) # [1, 1, 1, 10]
- 结果展示
torch.Size([64, 3, 32, 32])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
2.7 Sequential层:实现序列化模块
Sequential层的作用:将以上各层封装起来,简化操作
以下实现CIFAR10网络模型
- 代码演示
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64), # 64*4*4=1024
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
mydata = Mydata()
print(mydata)
input = torch.ones((64, 3, 32, 32))
output = mydata(input)
print(output.shape)
- 结果
Mydata(
(model1): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
2.8 Loss Funcion
计算实际输出与目标输出的差距,为我们更新输出提供一定依据(反向传播),然后反向传播会计算梯度,最后利用优化器更新参数;持续上述,每次开始时梯度要清零。
- 代码演示
import torch
import torchvision
from torch import nn
from torch.nn import L1Loss, MSELoss, Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# Loss函数L1Loss
loss1 = L1Loss()
result1 = loss1(inputs, targets)
print(result1)
# Loss函数MSELoss
loss2 = MSELoss()
result2 = loss2(inputs, targets)
print(result2)
# Loss函数CrossEntropyLoss
x = torch.tensor([0.1, 0.2, 0.3]) # x表示各个类的概率
y = torch.tensor([1])
x = torch.reshape(x, [1, 3]) # 这个3表示3个类
loss3 = nn.CrossEntropyLoss()
result3 = loss3(x, y)
print(result3)
# 演示
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 一次取64张图片
dataloader = DataLoader(dataset, batch_size=1)
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64), # 64*4*4=1024
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
mydata = Mydata()
for data in dataloader:
imgs, targets = data
output = mydata(imgs)
# 计算loss
result_loss = loss(output, targets)
print(result_loss)
# 为反向传播提供依据
result_loss.backward()
- 结果
tensor(0.6667)
tensor(1.3333)
tensor(1.1019)
Files already downloaded and verified
tensor(2.2537, grad_fn=<NllLossBackward0>)
...省略
2.9 优化器optim
每次开始时梯度要清零,然后计算loss,然后反向传播会计算梯度,最后利用优化器更新参数。
- 代码演示
import torch
import torchvision
from torch import nn
from torch.nn import L1Loss, MSELoss, Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False,
transform=torchvision.transforms.ToTensor(), download=True)
# 一次取64张图片
dataloader = DataLoader(dataset, batch_size=1)
class Mydata(nn.Module):
def __init__(self):
super(Mydata, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64), # 64*4*4=1024
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
mydata = Mydata()
# 使用CrossEntropyLoss损失函数
loss = nn.CrossEntropyLoss()
# 使用SGD优化器 lr表示学习速率
optim = torch.optim.SGD(mydata.parameters(), lr=0.01)
for epoch in range(20): # 进行20轮
running_loss = 0.0
for data in dataloader:
imgs, targets = data
output = mydata(imgs)
# 计算loss
result_loss = loss(output, targets)
# 参数的梯度清零
optim.zero_grad()
# 反向传播计算参数的梯度grad
result_loss.backward()
# 利用梯度优化参数
optim.step()
running_loss = running_loss + result_loss
print("每一轮的全部数据的误差:")
print(running_loss)
- 结果
Files already downloaded and verified
每一轮的全部数据的误差:
tensor(18657.6328, grad_fn=<AddBackward0>)
...省略

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









