







 本文详细介绍了Java中的LinkedList类,它是一个双向链表,实现List、Deque接口并支持克隆和序列化。讨论了LinkedList的继承关系、与Collection的关系、遍历方式以及API的使用。在遍历方面,文章通过测试对比了不同方法的效率,建议避免使用随机访问get()。最后,简要概述了LinkedList的源码实现和应用示例。
本文详细介绍了Java中的LinkedList类,它是一个双向链表,实现List、Deque接口并支持克隆和序列化。讨论了LinkedList的继承关系、与Collection的关系、遍历方式以及API的使用。在遍历方面,文章通过测试对比了不同方法的效率,建议避免使用随机访问get()。最后,简要概述了LinkedList的源码实现和应用示例。
一.LinkList概述
- LinkedList是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
- LinkedList 实现 List 接口,能进行队列操作。
- LinkedList 实现Deque接口,即能将LinkedList当作双端队列使用。
- LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
-LinkedList 实现java.io.Serializable接口,这意味着LinkedList**支持序列化**,能通过序列化去传输。
LinkedList 是非同步的。 - ArrayList底层是由数组支持,而LinkedList是由双向链表实现的,其中的每个对象包含数据的同时还包含指向链表中前一个与后一个元素的引用。
二.LinkList的继承关系

public class LinkedList extends AbstractSequentialList
implements List, Deque, Cloneable, Serializable
三.LinkedList与Collection关系
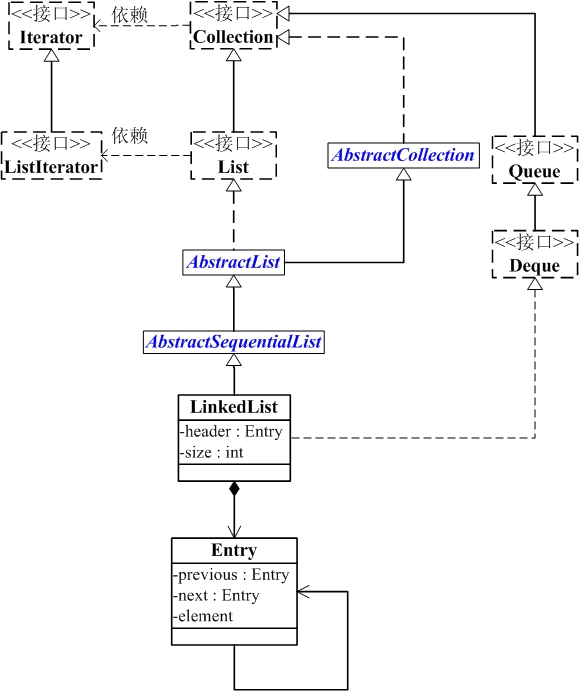
LinkedList的本质是双向链表。
LinkedList继承于AbstractSequentialList,并且实现了Dequeue接口。
LinkedList包含两个重要的成员:header 和 size。
header是双向链表的表头,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
size是双向链表中节点的个数。
四.LinkList遍历方式
- 迭代器遍历
“`
Iterator iterator = linkedList.iterator();
while(iterator.hasNext()){
iterator.next();
}
- for循环get()遍历
for(int i = 0; i < linkedList.size(); i++){
linkedList.get(i);
}
- Foreach循环遍历
for(Integer i : linkedList);
-通过pollFirst()或pollLast()遍历
while(linkedList.size() != 0){
linkedList.pollFirst();
}
-通过removeFirst()或removeLast()遍历
while(linkedList.size() != 0){
linkedList.removeFirst();
}
- 效率测试
测试以上几种遍历方式的效率,部分代码如下:
/**************** 遍历操作 **************/
System.out.println(“—————————————–”);
linkedList.clear();
for(int i = 0; i < 100000; i++){
linkedList.add(i);
}
// 迭代器遍历
long start = System.currentTimeMillis();
Iterator iterator = linkedList.iterator();
while(iterator.hasNext()){
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println(“Iterator:” + (end - start) +” ms”);
// 顺序遍历(随机遍历)
start = System.currentTimeMillis();
for(int i = 0; i < linkedList.size(); i++){
linkedList.get(i);
}
end = System.currentTimeMillis();
System.out.println(“for:” + (end - start) +” ms”);
// 另一种for循环遍历
start = System.currentTimeMillis();
for(Integer i : linkedList);
end = System.currentTimeMillis();
System.out.println(“for2:” + (end - start) +” ms”);
// 通过pollFirst()或pollLast()来遍历LinkedList
LinkedList temp1 = new LinkedList<>();
temp1.addAll(linkedList);
start = System.currentTimeMillis();
while(temp1.size() != 0){
temp1.pollFirst();
}
end = System.currentTimeMillis();
System.out.println(“pollFirst()或pollLast():” + (end - start) +” ms”);
// 通过removeFirst()或removeLast()来遍历LinkedList
LinkedList temp2 = new LinkedList<>();
temp2.addAll(linkedList);
start = System.currentTimeMillis();
while(temp2.size() != 0){
temp2.removeFirst();
}
end = System.currentTimeMillis();
System.out.println(“removeFirst()或removeLast():” + (end - start) +” ms”);
输出:
Iterator:17 ms
for:8419 ms
for2:12 ms
pollFirst()或pollLast():12 ms
removeFirst()或removeLast():10 ms
由测试结果可以看出,遍历LinkedList时,使用removeFirst()或removeLast()效率最高,而for循环get()效率最低,应避免使用这种方式进行。应当注意的是,使用pollFirst()或pollLast()或removeFirst()或removeLast()遍历时,会删除原始数据,若只单纯的读取,应当选用第一种或第三种方式。
五.LinkList之API
// Collection中定义的API
boolean add(E object)//添加一个数组对象
boolean addAll(Collection<? extends E> collection)//添加一个包含Collection的对象
void clear()//清空
boolean contains(Object object)//包含
boolean containsAll(Collection<?> collection)
boolean equals(Object object)//判等
int hashCode()
boolean isEmpty()//判空
Iterator<E> iterator()
boolean remove(Object object)//删除
boolean removeAll(Collection<?> collection)
boolean retainAll(Collection<?> collection)
int size()
<T> T[] toArray(T[] array)
Object[] toArray()
// AbstractCollection中定义的API
void add(int location, E object)
boolean addAll(int location, Collection<? extends E> collection)
E get(int location)//获取某个元素值
int indexOf(Object object)
int lastIndexOf(Object object)
ListIterator<E> listIterator(int location)
ListIterator<E> listIterator()
E remove(int location)
E set(int location, E object)
List<E> subList(int start, int end)
// ArrayList新增的API
Object clone()//
void ensureCapacity(int minimumCapacity)//保证容量不小于元素个数
void trimToSize()
void removeRange(int fromIndex, int toIndex)
六.LinkList源码解析
为了更了解LinkedList的原理,下面对LinkedList源码代码作出分析。
在阅读源码之前,我们先对LinkedList的整体实现进行大致说明:
LinkedList实际上是通过双向链表去实现的。既然是双向链表,那么它的顺序访问会非常高效,而随机访问效率比较低。
既然LinkedList是通过双向链表的,但是它也实现了List接口{也就是说,它实现了get(int location)、remove(int location)等“根据索引值来获取、删除节点的函数”}。LinkedList是如何实现List的这些接口的,如何将“双向链表和索引值联系起来的”?
实际原理非常简单,它就是通过一个计数索引值来实现的。例如,当我们调用get(int location)时,首先会比较“location”和“双向链表长度的1/2”;若前者大,则从链表头开始往后查找,直到location位置;否则,从链表末尾开始先前查找,直到location位置。
这就是“双线链表和索引值联系起来”的方法。
好了,接下来开始阅读源码(只要理解双向链表,那么LinkedList的源码很容易理解的)。
package java.util;
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 链表的表头,表头不包含任何数据。Entry是个链表类数据结构。
private transient Entry<E> header = new Entry<E>(null, null, null);
// LinkedList中元素个数
private transient int size = 0;
// 默认构造函数:创建一个空的链表
public LinkedList() {
header.next = header.previous = header;
}
// 包含“集合”的构造函数:创建一个包含“集合”的LinkedList
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
// 获取LinkedList的第一个元素
public E getFirst() {
if (size==0)
throw new NoSuchElementException();
// 链表的表头header中不包含数据。
// 这里返回header所指下一个节点所包含的数据。
return header.next.element;
}
// 获取LinkedList的最后一个元素
public E getLast() {
if (size==0)
throw new NoSuchElementException();
// 由于LinkedList是双向链表;而表头header不包含数据。
// 因而,这里返回表头header的前一个节点所包含的数据。
return header.previous.element;
}
// 删除LinkedList的第一个元素
public E removeFirst() {
return remove(header.next);
}
// 删除LinkedList的最后一个元素
public E removeLast() {
return remove(header.previous);
}
// 将元素添加到LinkedList的起始位置
public void addFirst(E e) {
addBefore(e, header.next);
}
// 将元素添加到LinkedList的结束位置
public void addLast(E e) {
addBefore(e, header);
}
// 判断LinkedList是否包含元素(o)
public boolean contains(Object o) {
return indexOf(o) != -1;
}
// 返回LinkedList的大小
public int size() {
return size;
}
// 将元素(E)添加到LinkedList中
public boolean add(E e) {
// 将节点(节点数据是e)添加到表头(header)之前。
// 即,将节点添加到双向链表的末端。
addBefore(e, header);
return true;
}
// 从LinkedList中删除元素(o)
// 从链表开始查找,如存在元素(o)则删除该元素并返回true;
// 否则,返回false。
public boolean remove(Object o) {
if (o==null) {
// 若o为null的删除情况
for (Entry<E> e = header.next; e != header; e = e.next) {
if (e.element==null) {
remove(e);
return true;
}
}
} else {
// 若o不为null的删除情况
for (Entry<E> e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









