










协程--轻量级的用户态线程
协程(Coroutine)是一种轻量级的用户态线程。简单来说,进程(Process), 线程(Thread)的调度是由操作系统负责,线程的睡眠、等待、唤醒的时机是由操作系统控制,开发者无法精确的控制它们。使用协程,开发者可以自行控制程序切换的时机,可以在一个函数执行到一半的时候中断执行,让出CPU,在需要的时候再回到中断点继续执行。因为切换的时机是由开发者来决定的,就可以结合业务的需求来实现一些高级的特性。
先来抽象的理解一下进程和线程
术语简介
上下文: 指的是程序在执行中的一个状态。通常我们会用调用栈来表示这个状态——栈记载了每个调用层级执行到哪里,还有执行时的环境情况等所有有关的信息。
调度: 指的是决定哪个上下文可以获得接下去的CPU时间的方法。
进程: 是一种古老而典型的上下文系统,每个进程有独立的地址空间,资源句柄,他们互相之间不发生干扰。
线程: 是一种轻量进程,实际上在linux内核中,两者几乎没有差别,除了线程并不产生新的地址空间和资源描述符表,而是复用父进程的。 但是无论如何,线程的调度和进程一样,必须陷入内核态。详细的知识介绍请参考《深入理解计算机操作系统》一书,这里只是简单的说一些概念;
早期时候,CPU都是单核的,由于单核 CPU 无法被平行使用(多个程序同时运行在一个CPU上)。为了创造共享CPU的假象,设计人员就搞出了一个叫做时间片的概念,将时间分割成为连续的时间片段,让多个程序在这些连续的时间片中交叉获得CPU使用权限,这样看起来就好像多个程序在同时运行一样。后来,给任务分配时间片并进行调度的调度器成为了操作系统的核心组件;
时间被分割为连续的时间片段后,在调度不同程序运行的时候,如果不对内存进行管理(上下文切换),那么切换时间片的时候会造成程序上下文的互相污染(A程序在运行时,突然发现自己内存中多了好多变量,一脸萌比。其实这些变量全是B程序产生的,如果两个程序存在同名变量,那更是两脸萌比了)。但是手工管理物理地址难度巨大,因此设计大牛们又引入了虚拟地址的概念,共包含三个部分:
- CPU 增加了内存管理单元模块,来进行虚拟地址和物理地址的转换;
- 操作系统加入了内存管理模块,负责管理物理内存和虚拟内存;
- 发明了一个概念叫做进程。进程的虚拟地址一样,经过操作系统和 MMU 映射到不同的物理地址上。
经过前面两部的演变,进程就产生了。进程是由一大堆元素组成的一个实体,其中最基本的两个元素就是代码和能够被代码控制的资源(包括内存、I/O、文件等);一个进程从产生到消亡,可以被操作系统调度。掌控资源和能够被调度是进程的两大基本特点。但是进程作为一个基本的调度单位有点不人性:假如我想一边循环输出 hello world,一边接收用户输入计算加减法,就得起俩进程,那随便写个代码都像 chrome 一样变成内存杀手了。这个时候,设计大牛们又想着能不能有一种轻量级的进程呢,这种‘轻量级的进程’不需要自己的独立的内存,IO等资源,而是共享已有的资源,紧接着诞生了线程的概念,线程在进程内部,处理并发的逻辑,拥有独立的栈,却共享线程的资源。使用线程作为 CPU 的基本调度单位显得更加有效率,但也引发各种抢占资源的问题,活生生变成了一把双刃剑.
通过上面的介绍,我们现在在来说一下协程产生的背景。上面的介绍中,我们知道进程掌握着独立资源,线程享受着基本调度。一个进程里可以跑多个线程处理并发。但纯粹的内核态线程有一个问题就是性能消耗:线程切换的时候,进程需要为了管理而切换到内核态,状态转换的消耗有点严重。为此又产生了一个概念,唤做用户态线程(协程)。用户态线程就是程序自己控制状态切换,进程不用陷入内核态,开发者可以按照程序的特性来选择更适合的调度算法,协程属于语言级别的调度算法实现。
协程、子例程与生成器的区别
协程的概念产生的非常早,Melvin Conway 早在 1963 年就针对编译器的设计提出一种将”语法分析”和”词法分析”分离的方案,把 token 作为货物,将其转换为经典的生产者-消费者问题。编译器的控制流在词法和语法解析之间来回切换:当词法模块读入足够多的 token 时,控制流交给语法分析;当语法分析消化完所有 token 后,控制流交给词法分析。(有兴趣的童鞋可以去看看编译原理,推荐龙书)从这一概念提出的环境我们可以看出,协程的核心思想在于:
控制流的主动让出和恢复。这一点和文章开始提到的用户态线程有几分相似,但是用户态线程多在语言层面实现,对于使用者还是不够开放,无法提供显示的调度方式。但是协程做到了这一点,用户可以在编码阶段通过类似 yieldto 原语对控制流进行调度。
子例程和协程的区别。
子例程和协程产生,需要我们先明确命令式编程与函数式编程这两种不同的编程范式对逻辑控制方式的差异。刚开始产生程序编码这一行业时,使用的是命令式编程,命令式编程围绕着自顶向下的开发理念,将子例程调用作为唯一的控制结构。而函数式编程则产生在命令式编程之后,属于前人痛定思痛的一种产物(具体的细节感兴趣的话可以WIKI一下)。介于篇幅问题,这里直接抛出概念。实际上,子例程就是没用使用 yield 的协程, 程序设计大师 Donald E. Knuth 也曾经将子例程定义为:
子例程是协程的一种特例。但不进行让步和恢复的协程(子例程),终究失掉了协程的灵魂内核,不能称之为协程。直到后来出现了一个叫做迭代器(Iterator)的神奇的东西。迭代器的出现主要还是因为数据结构日趋复杂,以前用 for 循环就可以遍历的结构需要抽象出一个独立的迭代器来支持遍历,用 js 为例。迭代器的遍历会搞成下面这个样子:
for (let key of Object.keys(obj)) {
console.log(`${key} : ${obj[key]}`);
}实际上,要实现这种迭代器的语法糖,就必须引入协程的思想:主执行栈在进入循环后先让步给迭代器,迭代器取出下一个迭代元素之后再恢复主执行栈的控制流。这种迭代器的实现就是因为内置了生成器(generator)。生成器也是一种特殊的协程,它拥有 yield 原语,但是却不能指定让步的协程,只能让步给生成器的调用者或恢复者。由于不能多个协程跳来跳去,生成器相对主执行线程来说只是一个可暂停的玩具,它甚至都不需要另开新的执行栈,只需要在让步的时候保存一下上下文就好。因此我们认为生成器与主控制流的关系是不对等的,也称之为非对称协程(semi-coroutine)。
由此我们也知道了,为啥 es6 一下引起了这么一大坨特性啊,因为引入迭代器,就必须引入生成器,这俩就是这种不可分割的基友关系。
协程的专题简介
协程的语义:
一般的协程实现都会提供两个重要的操作 Yield 和 Resume 。其中:
- Yield:是让出cpu的意思,它会中断当前的执行,回到上一次Resume的地方
- Resume:继续协程的运行。执行Resume后,回到上一次协程Yield的地方。(ES中对应的是next操作)
协程与线程的关系
首先我们可以明确,协程不能调度其他进程中的上下文。每个协程要获得CPU,都必须在线程中执行。因此,协程所能利用的CPU数量,和用于处理协程的线程数量直接相关。作为推论,在单个线程中执行的协程,可以视为单线程应用。这些协程,在未执行到特定位置(基本就是阻塞操作)前,是不会被抢占,也不会和其他CPU上的上下文发生同步问题的。因此,一段协程代码,中间没有可能导致阻塞的调用,执行在单个线程中。那么这段内容可以被视为同步的。(记住这一点方便理解后面的内容,毕竟JS是单(进)线程模型)
协程的优点:
简化了编码形式,提升代码可读性。
协程可以将异步的逻辑代码用同步的方式进行编写,将多个异步操作集中到一个函数中完成,不需要维护过多的session数据或状态机,同时兼备异步的高效。如果一个业务逻辑中涉及到多个异步请求,使用传统的异步回调方式,会使代码变得很凌乱,逻辑被不同的函数分割的支离破碎,非常不便于代码阅读,调试(很容易就造成回调地狱)。如果使用协程,可以将一个完整的业务逻辑集中在一个函数中完成,一眼了然。编程简单。单线程模式,没有线程中普遍存在的资源竞争问题,不需要加锁操作,降低编码难度,分离关注点。
- 降低资源开销。协程是用户态线程,切换时不需要考虑线程,进程切换时存在的时间和资源开销。
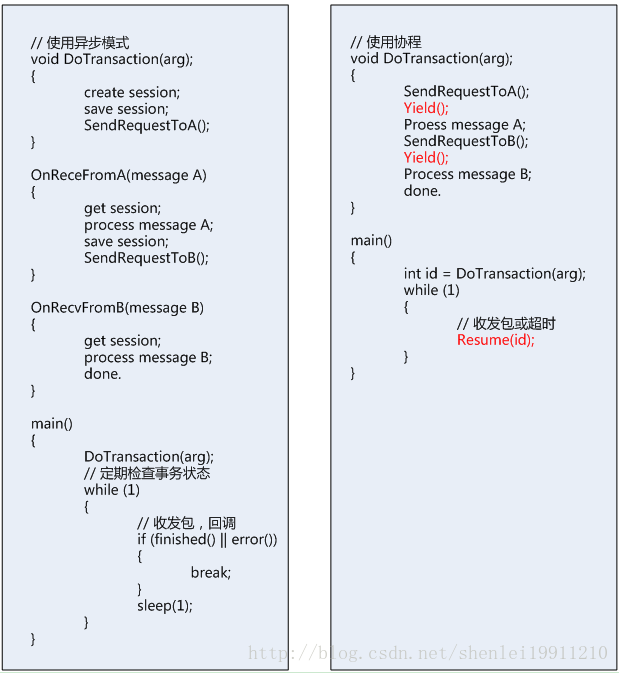
举例:
一个事务需要AB两个步骤,每一步需要请求不同的服务器:
可以看到:如果使用协程的话,可以在一个函数中看到参数,每个步骤的请求和应答内容,就不需要用户再去维护一个session和状态机。并且,看起来就像同步一样的代码逻辑。
协程的缺点:
- 在协程执行中不能有阻塞操作,否则整个线程被阻塞(协程是语言级别的,线程,进程属于操作系统级别)
- 需要特别关注全局变量、对象引用的使用
NodeJS中部分现有的协程实现窥探
自 es6 尝试引入生成器以来,大量的协程实现尝试开始兴起,协程一时间成为风靡前端界的新名词。但这些实现中有的仅仅是实现了一个看上去很像协程的语法糖,有的却 hack 了底层代码,实现了真正的协程。这里以 TJ 大神的 co 和 node-fibers 为例,浅析这两种协程实现方式上的差异。
CO
co 实际上是一个语法糖,它可以包裹一个生成器,然后生成器里可以使用同步的方式来编写异步代码,效果如下:
var fs = require('fs');
var readFile = function (fileName){
return new Promise(function (resolve, reject){
fs.readFile(fileName, function(error, data){
if (error) reject(error);
resolve(data);
});
});
};
co(function* (){
let f1 = yield readFile('/etc/fstab');
let f2 = yield readFile('/etc/shells');
let sum = f1.toString().length + f2.toString().length;
console.log(sum);
});在 es7 中的 async/await 更甜的语法糖,实现效果如下:
async function (){
let f1 = await readFile('/etc/fstab');
let f2 = await readFile('/etc/shells');
let sum = f1.toString().length + f2.toString().length;
console.log(sum);
};这段代码仿佛是在说明:我们把 readFile 丢到另一个协程里去了!等他搞定之后就又回到主线程上!代码可读性一下子就提升了!但事实真的是这样的么?我们来看一下 co 的不考虑异常处理的精简版本实现:
function co(gen){
let def = Promise.defer();
let iter = gen();
function resolve(data) {
// 恢复迭代器并带入promise的终值
step(iter.next(data));
}
function step(it) {
it.done ?
// 迭代结束则解决co返回的promise
def.resolve(it.value) :
// 否则继续用解决程序解决下一个让步出来的promise
it.value.then(resolve);
}
resolve();
return def.promise;
}从 co 的代码实现可以看出,实际上 co 只是进行了对生成器让步、恢复的控制,把让步出来的 promise 对象求取终值,之后恢复给生成器——这都没有多个执行栈,并没有什么协程么!但是有观众会指出:这不是用了生成器么,生成器就是非对称协程,所以它就是协程!好的,我们再来捋一捋:
协程在诞生之时,只有一个 Ghost,叫做主动让步和恢复控制流,协程因之而生;
后来在实现上,发现可以采用可控用户态线程的方式来实现,因此这种线程成为了协程的一个 shell。
后来又发现,生成器也可以实现一部分主动让步和恢复的功能,但是弱了一点,我们也称生成器为协程的一个弱弱的 shell。
所以我们说起协程,实际上说的是它的 Ghost,只要能主动让步和恢复,就可以叫做协程;但协程的实现方式有多种,有的有独立栈,有的没有独立栈,他们都只是协程的壳,不要在意这些细节,嗯。
好吧,实际上并没有什么改变。因为 promise 本身的实现机制还是回调,所以在 then 的时候就把回调扔给 webAPI 了,等到合适的时机又扔回给事件队列。事件队列中的代码需要等到主栈清空的时候再运行,这时候执行了 iter.next 来恢复生成器——而生成器是没有独立栈的,只有一份保存的上下文;因此只是把生产器的上下文再次加载到栈顶,然后沿着恢复的点继续执行而已。引入生成器之后,事件循环的一切都木有改变!
Node-fibers
看完了生成器的实现,我们再来看下真·协程的效果。这里以 hack 了 node.js 线程的 node-fibers 为例,看一下真·协程与生产器的区别在何处。
首先,node-fibers 本身仅仅是实现了创造协程的功能以及一些原语,本身并没有类似 co 的异步转同步的语法糖,我们采用相似的方式来包裹一个,为了区别,就叫它 ceo 吧(什么鬼):
let Fiber = require('fibers');
function ceo(cb){
let def = Promise.defer();
// 注意这里传入的是回调函数
let fiber = new Fiber(cb);
function resolve(data) {
// 恢复迭代器并带入promise的终值
step(fiber.run(data));
}
function step(it) {
!fiber.started ?
// 迭代结束则解决co返回的promise
def.resolve(it.value) :
// 否则继续用解决程序解决下一个让步出来的promise
it.then(resolve);
}
resolve();
return def.promise;
}
ceo(() => {
let f1 = Fiber.yield(readFile('/etc/fstab'));
let f2 = Fiber.yield(readFile('/etc/shells'));
let sum = f1.toString().length + f2.toString().length;
console.log(sum);
});上面的代码看起来和前面的好像最大的区别就是生成器变成了回调函数,只是少了一个 * 嘛。但是注意啦,关键点就在这里:没有了生成器,我们可以在任意一层函数里进行让步,这里使用 ceo 包裹的这个回调,是一个真正独立的执行栈。在真·协程里,我们可以搞出这样的代码:
ceo(() => {
let foo1 = a => {
console.log('read from file1');
let ret = Fiber.yield(a);
return ret;
};
let foo2 = b => {
console.log('read from file2');
let ret = Fiber.yield(b);
return ret;
};
let getSum = () => {
let f1 = foo1(readFile('/etc/fstab'));
let f2 = foo2(readFile('/etc/shells'));
return f1.toString().length + f2.toString().length;
};
let sum = getSum();
console.log(sum);
});通过这个代码可以发现,在第一次让步被恢复的时候,恢复的是一系列的执行栈!从栈顶到栈底依次为:foo1 => getSum => ceo 里的匿名函数;而使用生成器,我们就无法写出这样的程序,因为 yield 原语只能在生产器内部使用——无论什么时候被恢复,都是简单的恢复在生成器内部,所以说生成器是不用开新栈滴。
那么问题就来了,使用了真·协程之后,原先的事件循环模型是否会发生改变呢?是不是主执行栈调用协程的时候,协程就会在自己的栈里跑,而主栈就排空了可以执行异步代码呢?我们来看下面这个例子:
"use strict";
var Fiber = require('fibers');
let syncTask = () => {
var now = +new Date;
while (new Date - now < 1000) {}
console.log('SyncTask Loaded!');
};
let asyncTask = () => {
setTimeout(() => {
console.log('AsyncTask Loaded!');
});
};
var fiber = Fiber(() => {
syncTask();
Fiber.yield();
});
function mainThread() {
asyncTask();
fiber.run();
}
mainThread();
// 输出:
// SyncTask Loaded!
// AsyncTask Loaded!我们在主线程执行的时候抛出了一个异步方法,之后在协程里用冗长的同步代码阻塞它,这里我们可以清楚的看到:阻塞任何一个执行中的协程都会阻塞掉主线程!也就是说,即使加入了协程,js 还是可以被认为是单线程的,因为同一时刻势必只有一个协程在运行,在协程运行和恢复期间,js 会将当前栈保存,然后用对应协程的栈来填充主的执行栈。只有所有协程都被挂起或运行结束,才能继续运行异步代码。
因此,真·协程的引入对事件循环还是造成了一定的影响,可怜的异步代码要等的更久了。
简单的总结一下
协程的使用:
考虑服务端协程的使用(可以延伸到客户端中具体使用方式),服务端程序中协程创建和启动的时机非常重要。一般来说,会在收到一个请求包时认为是一个事务的开始,此时创建并启动协程,协程执行完即认为事务结束。期间,如果遇到异步请求事件,当发送完请求后,在协程内主动Yield,当收到应答后再Resume回来。其过程可以用下图表示:

-- 关于Node部分的代码参考了网络博文,具体引用地址由于时间问题已经不可找回,如能提供不胜感激















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









