








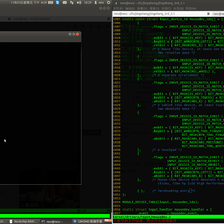
#! /usr/bin/env python3
# -*- coding:utf-8 -*-
# filename : qiushibaike2.py
# author : zoujiameng@aliyun.com.cn
from urllib.request import urlopen, Request, HTTPBasicAuthHandler, build_opener, ProxyHandler, install_opener
from urllib.parse import urlencode
from urllib.error import HTTPError, URLError
import socket, re
class HtmlUtils: # 如何实现单例?
#default_timeout = None
#the_page = None
def __init__(self, timeout=2):
self.default_timeout = timeout
self.the_page = None
socket.setdefaulttimeout(self.default_timeout)
def getHtml(self, url):
response = urlopen(url, timeout=self.default_timeout)
the_page = response.read()
self.the_page = the_page
return the_page
def getHtmlByRequest(self, url, user_agent=None):
if user_agent != None:
headers = { 'User-Agent' : user_agent }
request = Request(url, headers=headers)
else:
request = Request(url)
response = urlopen(request, timeout=self.default_timeout)
the_page = response.read()
self.the_page = the_page
return the_page
def __getHtmlBySendDataInternal__(self, url, data, headers=None):
values = urlencode(data)
if headers == None:
request = Request(url, values)
request.add_header('Referer', 'http://www.python.org/')
else:
request = Request(url, values, headers)
try:
response = urlopen(request, timeout=self.default_timeout)
except HTTPError as e:
print("Http Error Code:", e.code)
except URLError as e:
if hasattr(e, "code"):
print("URL Error Code:", e.code)
if hasattr(e, "reason"):
print("URL Error Reason", e.reason)
the_page = response.read()
self.the_page = the_page
return the_page.decode("utf-8")
def getHtmlBySendDataAndHeaders(self, url, data, user_agent):
#user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
return self.__getHtmlBySendDataInternal__(url, data, headers)
def getHtmlBySendData(self, url, data):
#user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
return self.__getHtmlBySendDataInternal__(url, data)
def savePageToFile(self, filename, dc="utf-8"):
with open(filename, "wb") as f:
#html = self.the_page#.decode(dc)
f.write(self.the_page)
def getHtmlByPwd(self, url, username, pwd, a_url):
import urllib.request
# create a password manager
password_mgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# Add the username and password.
password_mgr.add_password(None, url, username, pwd)
handler = HTTPBasicAuthHandler(password_mgr)
# create "opener" (OpenerDirector instance)
opener = build_opener(handler)
# use the opener to fetch a URL
self.the_page = opener.open(a_url).read()
# if we wanna install the opener. usage under:
#urllib.request.install_opener(opener)
#a = urllib.request.urlopen(a_url).read().decode('utf8')
def getHtmlIfSupportProxy(self, url, ip, port):
target = str(ip) + ':' + str(port)
proxy_support = ProxyHandler({'': target})
opener = build_opener(proxy_support)
install_opener(opener)
self.the_page = urllib.request.urlopen(url, timeout=self.default_timeout).read()
return self.the_page.decode("utf8")
# for test...
if __name__ == "__main__":
ht = HtmlUtils(3)
URLIndex = "https://www.qiushibaike.com/hot/page/"
user_agent = 'Mozilla/5.0 (compatible; MSIE 5.5; Ubuntu 14.04)'
for page in range(1, 10):
url = URLIndex + str(page)
ht.getHtmlByRequest(url, user_agent)
fn = "Myysite_" + str(page) + ".html"
ht.savePageToFile(fn)正常情况下,会生成9个html文件:

异常情况下,会有部分没有生成:

异常截图,HTTP Error:
















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









