










1. Xpath 解析
xpath -> xml -> html
安装 lxml 包: #可能会失败,需要先安装 Microsoft Visual C++ Build Tools
pip install lxml
或者
pip install wheel -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install lxml -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
使用:
from lxml import etree
或者
from lxml import html
etree = html.etree
Python 扩展包网址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
安装 lxml 失败参考:#这些方式治标不治本,而且都可能不成功,主要靠玄学
https://blog.csdn.net/weixin_39999536/article/details/110527819
https://www.cnblogs.com/huodaihao/p/8094144.html
https://www.cnblogs.com/jhli/p/6217123.html
安装 Microsoft Visual C++ Build Tools:
https://zhuanlan.zhihu.com/p/126669852 #参照方法 3-1
以上方法我都试过,都没成功,可能和我 pycharm 版本低有关系,最后升级到了 python 3.10.1,pycharm 2021.3.1 解决。
2. 准备一个 html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://www.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="feiji">飞机</a></li>
<li><a href="dapao">大炮</a></li>
<li><a href="huoche">火车</a></li>
</ol>
<div class="job">李嘉诚</div>
<div class="common">胡辣汤</div>
</body>
</html>
3. 写 py 文件
from lxml import etree
# from lxml import html
# etree = html.etree
# 需要加载准备解析的数据
f = open("test.html", mode="r", encoding='utf-8')
pageSource = f.read()
# 加载数据,返回element对象
et = etree.HTML(pageSource)
# xpath的语法
#result = et.xpath("/html") # /html 代表根节点
#result = et.xpath("/html/body") # /html 节点里面的 /body
#result = et.xpath("/html/body/span") # /body 里面的 span 标签
#result = et.xpath("/html/body/span/text()") # text() 表示提取标签中的文本信息
#result = et.xpath("/html/body/*/li/a/text()") # "*" 任意
#result = et.xpath("/html/body/*/li/a/@href") # @表示属性
#result = et.xpath("//a/@href") # // 表示任意位置
#result = et.xpath("//div[@class='job']/text()") # [@xx=xxxx] 属性的限定
# 带循环的
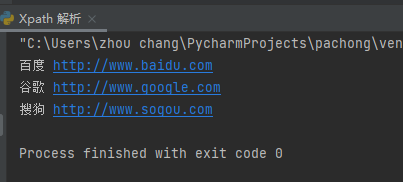
result = et.xpath("/html/body/ul/li")
for item in result:
href = item.xpath("./a/@href")[0] # ./ 表示当前这个元素
text = item.xpath("./a/text()")[0] # ./ 表示当前这个元素
print(text, href)















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









