







作为一个程序员或者说C++程序开发人员,想必对ELF目标文件从整体轮廓到某些局部的细节都非常熟知。该系列帖子主要为了解决一个疑惑:当我们有多个目标文件时,如何将它们连接起来形成一个可执行文件?这个过程发生了什么?其实,读到这里,可能就了解到,这其实就是链接的核心内容:静态链接。
1.应用到的两个源代码文件
<span style="font-size:18px;">/* a.c */ extern int shared; int main() { int a = 100; swap(&a, &shared); cout << a; cout << endl; cout << shared; }</span>首先使用GCC将“a.c”、“b.c”分别编译称目标文件“a.o”、“b.o”。从代码中,我们可以看到,“b.c”一共定义了两个全局符号:一个是变量“shared”,另一个是函数“swap”;“a.c”中定义了一个全局符号就是“main”。模块“a.c”中引用到了“b.c”中的swap和shared。我们要研究的工作就是“a.o”文件与“b.o”文件是怎么样链接成一个可执行文件 “ab”的?<span style="font-size:18px;">/* b.c */ int shared = 1; void swap(int* a, int* b) { *a ^= *b ^= *a ^= *b; }</span>
2.空间与地址分配
对于连接器而言,整个链接过程中,他就是将几个输出目标文件加工后合并成一个输出文件。根据我们已有的ELF文件格式知识,我们知道可执行文件中的代码段和数据段都是由输入的目标文件合并而来的。这里我们首先来探索第一个问题:对于多个输入目标文件,链接器如何将它们的各个段合并到输出文件?或者说,输出文件中的空间如何分配给输入文件?
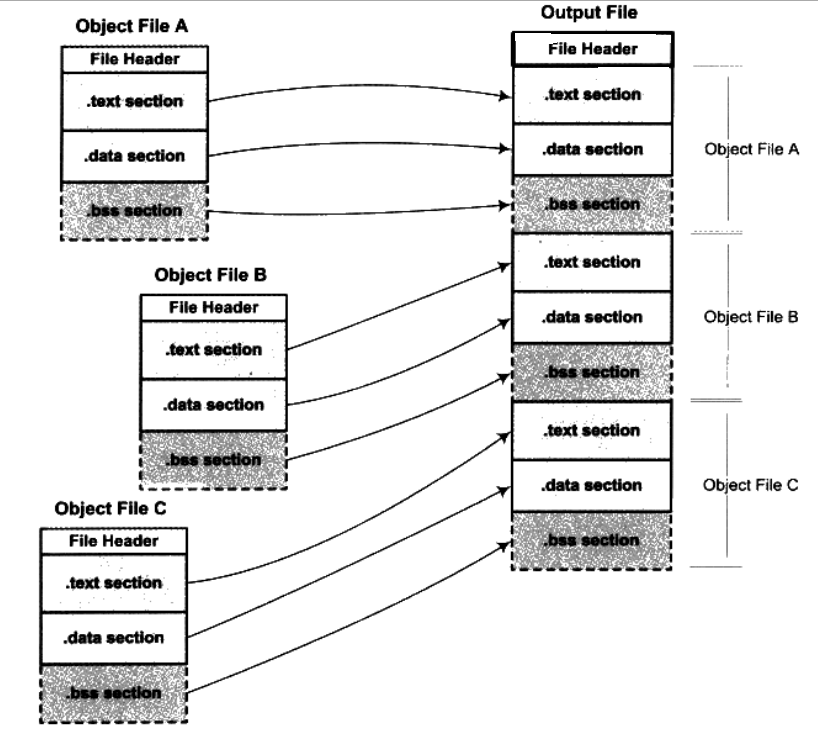
按序叠加:
按序叠加的思想非常简单粗暴,就是直接将各个目标文件一次合并,该思路可以用下面图示说明:
该种方法的确很简单,但是带来一个很直接的问题:在很多输入文件爱你的情况下,输出文件会有很多零散的段。比如说,一个规模稍大的应用程序可能会有数百个目标文件,如果每个目标文件都分别有.text段、.data段、.bss段,那最后的输出文件将会有成百上千个零散的段。这种做法非常消耗空间,造成内存空间中大量的内部碎片,并不是一个很好的方案。
相似段合并:
一个更实际的方法就是将相同性质的段合并到一起,其设计思想如下图所示:
正如我们了解到的,“.bss”段在目标文件和可执行文件中并不占用文件空间,但是在装载时需要占用地址空间。所以链接器在合并各个段的同时,也会将“.bss”段合并,并且分配虚拟空间。这里有一个问题,先前一直很迷惑,这里可以做一个小小的理解。所谓的“空间分配”到底是什么空间?
其实“连接器为目标文件分配地址和空间”这句话中的“地址和空间”有两个含义:第一个是指在输出的可执行文件中的空间;第二个是在装载后的虚拟地址中的虚拟地址空间。对于有实际数据的段,比如".text"和“.data”来说,他们在文件中和虚拟地址中都要分配空间,因为他们在这两个里面都存在!然而,对于“.bss”这样的段来说,分配空间的意义只限于虚拟地址空间,因为他在文件中并没有内容。事实上,我们在这里谈到的空间分配只关注与虚拟地址空间的分配。
当代操作器多采用后一种空间分配策略。整个链接过程可以分为两步:
1.空间与地址分配。扫描所有输入的目标文件,并且获得他们的各个段的长度、属性和位置,并且将输入目标文件中的符号表综所有的符号定义和符号引用收集起来,统一放到一个全局符号表中。这一步,链接器将能够获得所有目标文件的段长度,并且将它们合并。而且通过计算出输出文件中各个段合并后的长度和位置,建立映射关系。2.符号解析与重定位。在上面收集到信息的基础上,读取输入文件中段的数据、重定位信息,并且进行符号解析和重定位、调整代码中的地址。这一步才是链接过程的核心,特别是重定位过程。
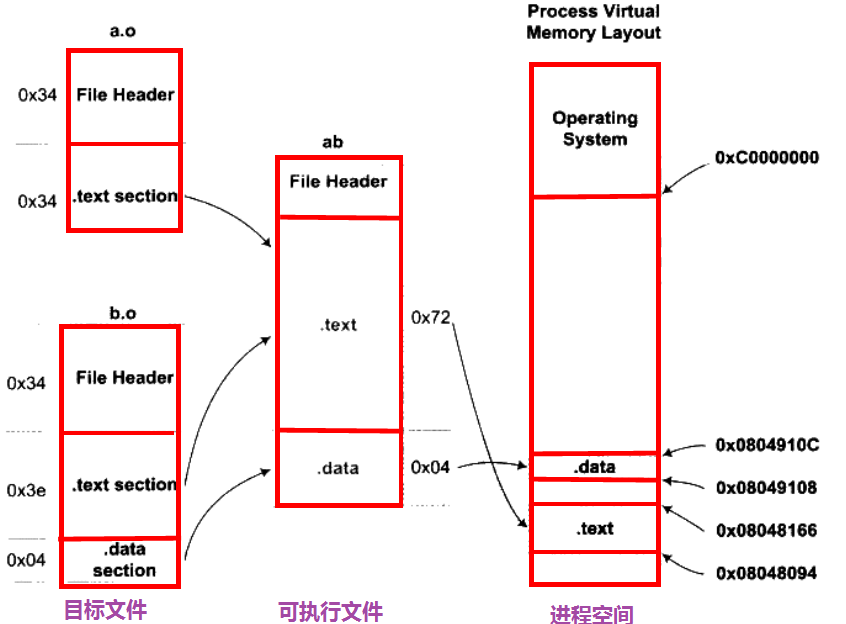
连接前后各个段的属性分析:
注:VMV(Virtual Memory Address,虚拟地址);LMA(Load Memory Address,加载地址)。正常情况下两者一样。
这个连接前后,目标文件各段的分配、程序虚拟地址等可以用下图表示:
符号地址的确定:
在第一步完成之后,连接器开始计算各个符号的虚拟地址。因为各个符号在段内的相对位置是固定的,所以这个时候“main”、"shared"、"swap"等地址也就确定了,只不过链接器需要给每个符号加上一个偏移量,使他们能够调整到正确的虚拟地址。




3.符号解析与重定位
重定位:
在完成空间和地址的分配步骤以后,链接器就进入符号解析与重定位的步骤,这也是静态链接的核心内容。在分析符号解析与重定位之前,首先看看“a.o”里面是怎么样使用那两个东东的("shared"、"swap")【也就是说,我们在a.c源文件中使用了“shared”变量和“swap”函数,那么编译器再将“a.c”编译成指令时,是如何访问该变量?以及如何调用该函数的呢?】
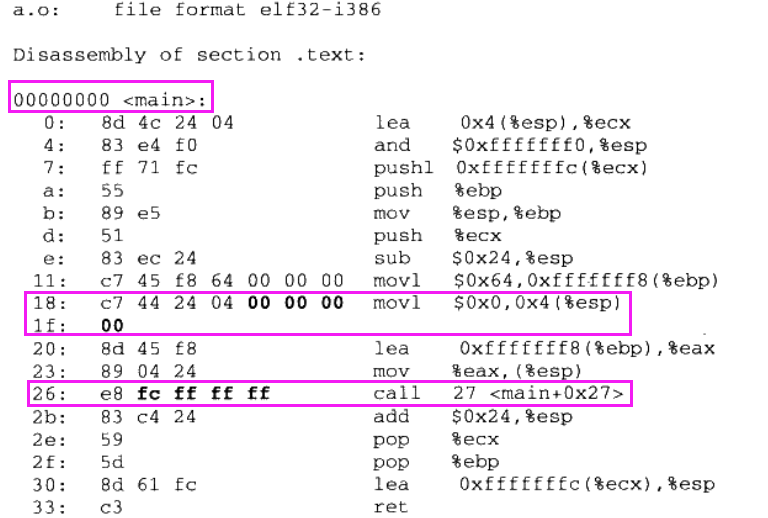
对a.o文件进行反汇编得到下面代码清单:
注:在程序的代码里面使用的都是虚拟地址,从上图中我们可以看到“main”函数的起始地址是0x0000000,这是因为在未进行空间分配之前,目标文件代码段中的起始地址都应该以0x0000000开始,等待空间分配完成以后,各个函数才会确定自己在虚拟地址空间中的位置。
通过反汇编结果,我们能够清楚的看到,”a.o“共定义了一个main函数,共占用0x33个字节,共17条指令;对于变量”shared“的引用是一条”move“指令,它的作用是将”shared“的地址赋值到ESP寄存器+4的偏移地址中去。对于函数”swap“的引用是一条”call“指令。
重定位表:
那么链接器是怎样知道哪些指令是要被调整的呢?这些指令有哪些部分需要部分调整呢?又怎么进行调整?这些工作其实就是依赖重定位表完成的!该结构专门用来保存这些与重定位有关的信息。
符号解析:
其实在我们普通的观念中,之所以要进行链接是因为我们的目标文件中用到的符号被定义在其他的目标文件中了,所以我们要把他们整合起来。比如,如果我们直接用ld命令来链接”a.o“文件,而不输入”b.o“文件,那么链接器就会报错,提示我们没有发现shared和swap两个符号的定义,链接就会失败,实验效果如下图所示:
其实,这也是我们平时在编写程序的时候最常见到的问题:链接是符号没有定义!导致这个问题的原因有很多,最常见的一般都是链接时缺少了某个库,或者输入目标文件路径不正确或符号的生命与定义不一样!!!

4.小结
通过前面的介绍,我们可以更加深层次地理解为什么缺少符号的定义会导致连接错误!其实重定位过程也伴随符号的解析过程,每个目标文件都可能定义一些符号,也可能引用到定义在其他目标文件中的符号。重定位的过程中,每个重定位的入口都是对一个符号的引用,那么当链接器需要对某个符号的引用进行重定位时,就必须明白该富豪的目标地址。这时候,链接器就会去查找由所有目标文件的符号所组成的全局符号表,找到相应的符号后就可以开展重定位工作。















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









