









1.简介
本文提出了一种新颖的多模态图像融合方法,旨在通过融合红外和可见光图像来提升场景理解的质量。传统方法在融合过程中往往难以同时兼顾视觉质量和对下游任务的适应性,而本文提出的SAGE方法通过引入Segment Anything Model(SAM)的语义先验信息,有效地解决了这一问题。SAGE的核心在于设计了一个Semantic Persistent Attention(SPA)模块,该模块能够高效地整合SAM提供的高级语义信息和源图像的细节特征,从而生成高质量的融合图像。此外,为了确保模型在实际应用中的高效性,本文还提出了一种双层优化驱动的知识蒸馏机制,通过三元组损失函数将主网络的知识迁移到轻量级的子网络中,从而在去除SAM依赖的同时,保持了融合图像的高质量和对下游任务的适应性。
通过在多个标准数据集上的广泛实验,SAGE方法不仅在视觉效果上表现出色,还在语义分割等下游任务中展现了卓越的性能,同时保持了高效的推理速度,为多模态图像融合领域提供了一种具有实际应用价值的新思路。
github地址:https://github.com/RollingPlain/SAGE_IVIF?tab=readme-ov-file
-
-
2.论文详解
简介
近期,大规模视觉模型的发展显著提升了多种视觉分析任务的性能。其中,Segment Anything Model(SAM)因其卓越且稳健的提供丰富语义信息的能力而脱颖而出,非常适合用于IVIF,如图2所示。此外,其分割能力与IVIF领域的下游任务需求天然契合。然而,目前将SAM整合用于低级任务的方法通常需要在推理时使用完整的SAM,这在实际应用中显得过于不切实际。
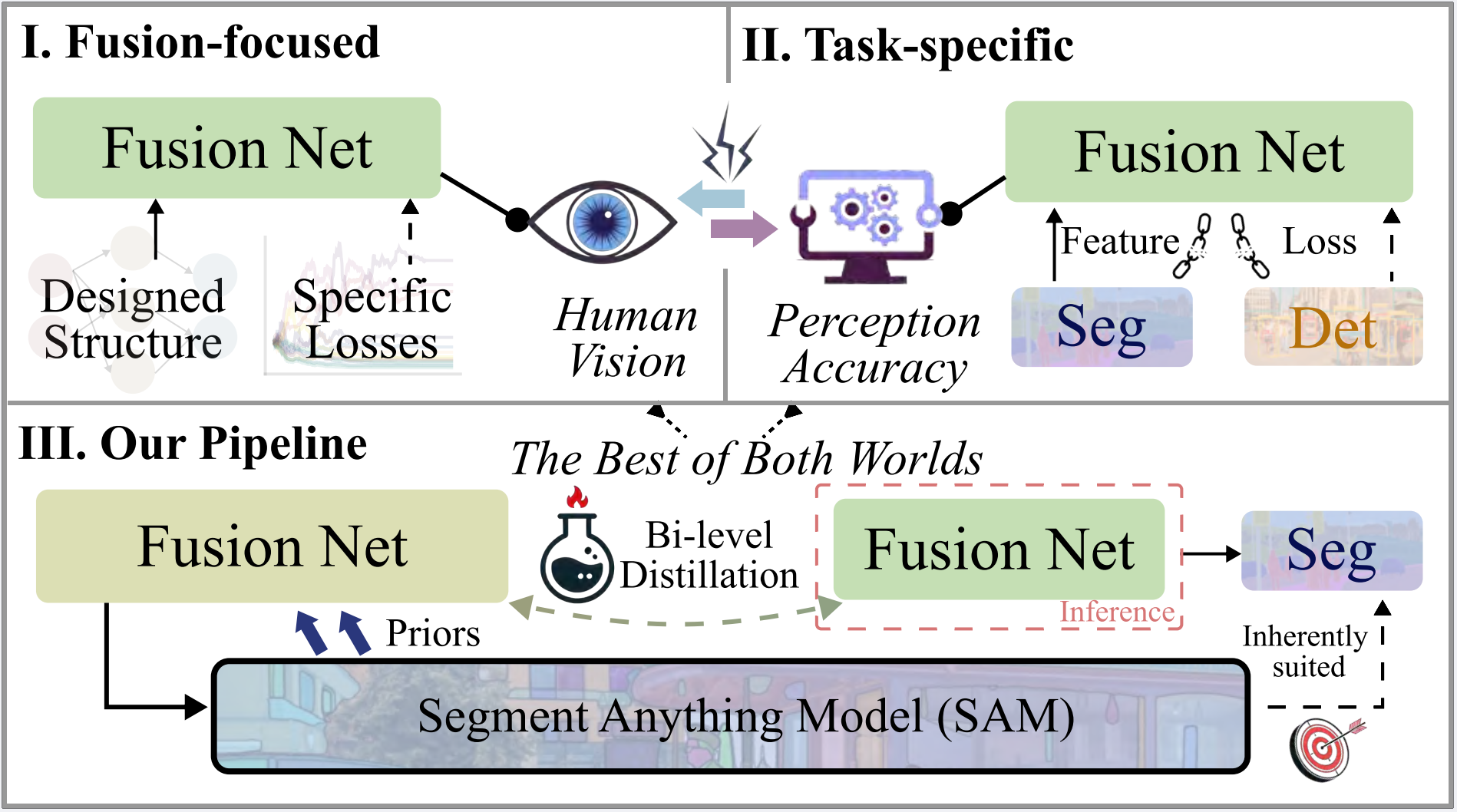
为了解决这些问题,作者提出了融合方法SAGE,该方法完全整合并提炼了来自SAM的语义先验。如图(III)所示,作者的目标之一是充分利用SAM的语义先验优势,同时减轻计算负担。所提出的方法包含两个关键组件:语义持久注意力模块和双级蒸馏方案。前者专注于在整个过程中使用持久存储库以保留源图像信息,同时启发式地使网络能够整合SAM预测的语义块。此外,蒸馏方案旨在高效地将SAM从推理过程中排除,从而降低计算复杂度。通过在不同方面增强蒸馏信息,方案中的三元组损失显著提升了融合模型的性能。因此,仅使用蒸馏后的模型即可实现高效的融合,提供高质量的视觉结果和精确的任务性能,而无需直接涉及SAM。
如图所示,作者所提出方法与现有主流比较方法的差异如下:
- (I)传统和早期基于深度学习的方法侧重于融合视觉效果。
- (II)特定任务的方法(例如TarDAL和SegMiF)引入了任务损失和特征,导致优化目标不一致,从而在视觉效果和任务准确性之间产生了冲突。
- (III)作者的流程首先在大型网络中利用SAM的语义先验,然后将知识提炼到较小的子网络中,实现了实用的推理可行性,同时通过SAM对这些任务的固有适应性,确保了“两全其美”。
-
方法
整体框架
作者方法的整体工作流程如图所示。
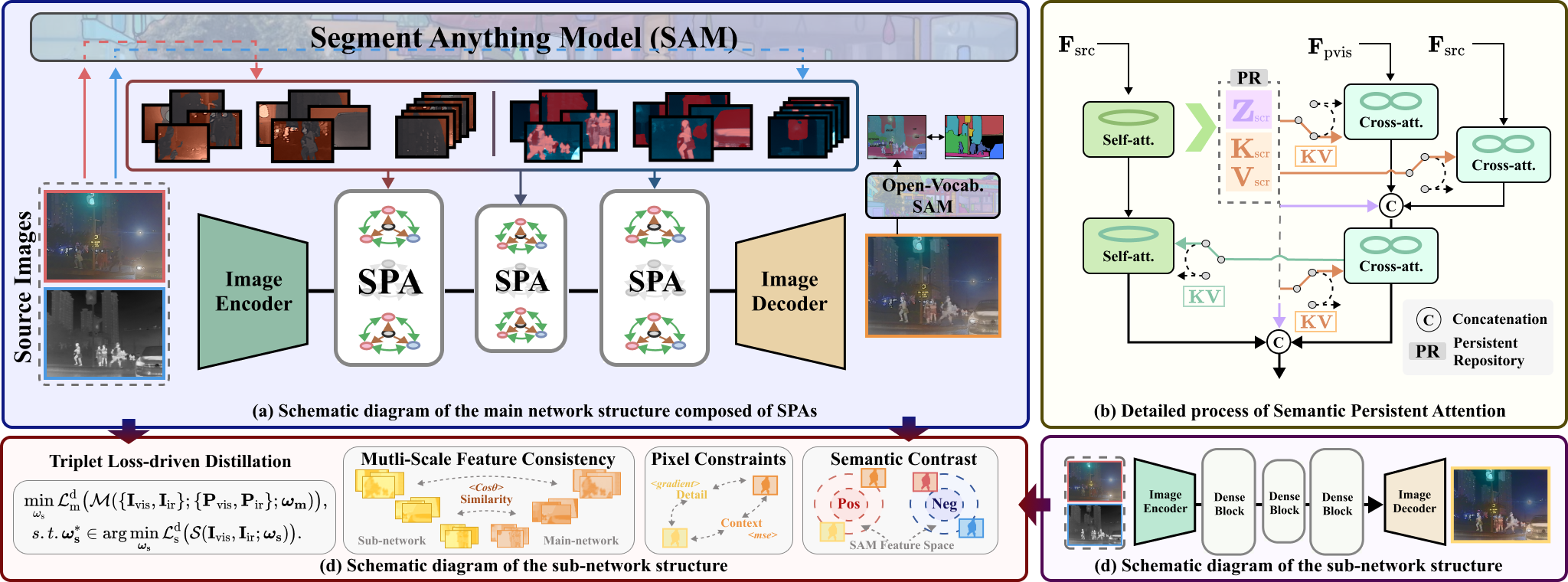
作者的目标是在推理阶段充分利用SAM的语义先验,以提升跨模态融合的质量。然而,直接部署大规模的SAM模型往往会带来过高的计算负担。为了解决这一问题,作者采用了知识蒸馏策略,将由SAM驱动的主网络所编码的信息转移到一个轻量级子网络中,从而显著降低推理成本,同时保持高质量的融合效果。不过,SAM增强的主网络与紧凑子网络之间巨大的容量差异,常常导致语义传递不完整或结构不一致,从而阻碍了理想的跨模态融合性能。为了解决这一问题,作者提出了一种双级优化框架,将两个网络作为一个统一系统进行联合优化,旨在弥合蒸馏差距,并在SAM的语义先验指导下保持一致的融合效果。
设表示源可见光和红外输入图像,即
。在 SAM 的指导下生成的相应语义先验块表示为
。用 M 表示主网络,其参数为
,用 S 表示子网络,其参数为
。作者定义了优化过程:
,其中:
-
是蒸馏损失,确保主网络中具有有意义的语义线索的高质量融合,
-
是蒸馏损失,引导子网络有效地模仿主网络的行为。
- 融合参考图像由
给出,
- 子网络产生融合图像
。
值得注意的是,两个蒸馏目标都依赖于对方网络的输出,建立了双向依赖关系,这是作者蒸馏公式的一个关键特征。在整体框架中,主网络将来自SAM的语义先验整合到融合过程中,而子网络则在双级公式下优化,以与其输出对齐。
-
语义持续注意模块(Semantic Persistent Attention Module)
为了充分利用SAM提供的语义信息,作者提出了语义持续注意(SPA)模块,如图中的流程图所示。
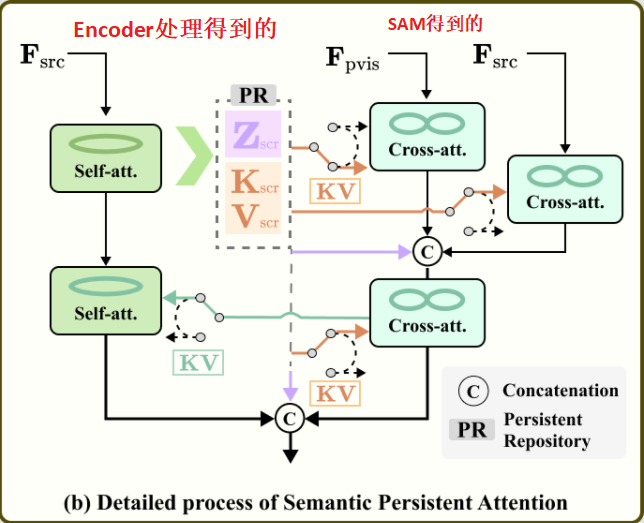
SPA模块的核心是一个持久存储库(Persistent Repository,简称PR),它作为一个静态存储器,用于存储和维护融合过程中的关键上下文信息。具体来说,PR存储了源特征的潜在表示(Z)以及相应的键值对(
,
),这些在交叉注意力操作期间提供了一致的上下文支持。作者设计的这一背后的核心思想是,PR作为一个稳定、特定模态的信息源,引导交叉注意力机制将语义块与原始源的丰富上下文细节融合。
从SAM中提取的可见光和红外语义块( 和
)被编码成特征(
和
)。这些编码后的语义特征代表了场景的有限部分,并通过交叉注意力机制进行处理。通过利用存储在PR中的键值对(
,
),交叉注意力机制用源图像的完整场景上下文丰富了语义查询(
和
),从而解决了块中固有的场景覆盖不完整的问题。PR确保融合过程始终基于稳定、一致的上下文,使块能够有效地用特定模态的信息丰富。这种稳定性在保持语义一致性的同时,通过注意力机制允许灵活的特征细化。
总之,SPA模块使用PR来引导交叉注意力机制,确保来自SAM的语义块被一致且详细的特定模态信息所丰富。这种方法通过结合来自SAM的高级语义理解和来自源特征的详细信息,实现了红外和可见光图像模态的融合。最终输出代表了一组语义丰富、结构一致的特征集,富含SAM的语义先验,并准备好进行进一步处理。
主网络大量利用SPA模块,旨在充分利用SAM提供的复杂语义先验,专注于捕捉和保留详细的语义知识,从而促进一个强大的表示,该表示可以稍后被蒸馏到一个更高效的子网络中。
-
蒸馏过程中的三重损失
在本节中,作者介绍了一种基于三元组损失的蒸馏方案,该方案在双级优化框架下促进了从主网络(M)到子网络(S)的语义知识转移。具体来说,作者采用了DARTS风格的训练协议,其中主网络(教师)和子网络(学生)以小的交替步骤进行更新,近似双级优化的内外结构。这允许梯度以双向方式流动:子网络从主网络提供的蒸馏信号中学习,同时主网络也根据子网络的性能和分割目标调整其参数。因此,两个网络达到了相互妥协的一致性转移。
双层优化(Bi-level Optimization)是一种优化框架,用于解决包含两个相互依赖的优化问题的复杂任务。它通常用于机器学习中的元学习、超参数优化、知识蒸馏等场景。双层优化的核心思想是将优化问题分为两个层次:上层优化问题(Outer Optimization)和下层优化问题(Inner Optimization),并通过交替更新的方式求解。
上层优化:优化教师网络的参数。
下层优化:优化学生网络的参数,使其尽可能接近教师网络的性能。
双层优化被用于知识蒸馏,其中主网络(教师网络)和子网络(学生网络)通过交替更新的方式进行优化。主网络利用语义先验信息生成高质量的融合结果,而子网络则通过模仿主网络的行为来实现高效的推理。

作者的蒸馏方案由三种不同的损失驱动,每种损失都侧重于融合图像的不同方面。设 为主网络生成的融合参考图像,
为子网络的融合输出。
- 首先,作者引入了一个特征对齐项:
,其中
和
是相同尺度m上密集块和SPA块的特征图,
是
-范数。
- 第二个损失组件在上下文级别上运行,它由两部分组成:一部分是保留结构一致性的梯度部分,另一部分是用于强度一致性的均方误差(MSE)损失。它们定义为:其中∇表示Sobel算子,
是
-范数。因此,上下文损失可以计算为
。在实践中,作者不仅在
和
之间应用这些项,还在每个融合输出和原始源图像之间应用,以确保重建保真度。这防止了两个网络在蒸馏过程中偏离源图像。
- 第三个损失组件,对比语义损失,旨在确保融合图像的特征空间保持与参考图像接近,同时与单独的可见光和红外图像有所区别,以实现有效的蒸馏。作者利用由SAM编码器(定义为
)的语义特征空间,通过来自
和
的二进制掩码(
和
)的逐元素乘法来构建正负对。每个模态上的对比语义损失定义为:
其中l是索引。因此,总的
也可以在两个网络之间的双级优化方案中双向计算,确保
的特征空间容易对齐。
- 对于主网络,作者还加入了一个额外的分割交叉熵损失
。这个损失是在由开放词汇模型
生成的分割预测和真实分割标签之间计算的。这个损失旨在防止潜在的优化冲突,而不是影响子网络。分割损失
。其中
表示标签分割图,
是预测的分割图,c是类别索引。
子网络的总蒸馏损失,如公式(1)中所表示的 ,是特征损失、上下文损失和对比语义损失的总和:
而主网络的总蒸馏损失可以计算为:。
-
实验
作者使用了五个代表性的数据集,即TNO,RoadScene,MFNet,FMB和M3FD,用于训练和评估。对于分割任务,作者采用了SegFormer(B3变体)作为主干,并且模型训练了100个周期。训练和测试的划分严格按照官方数据集指南进行。作者采用Adam进行训练,主网络和子网络的初始学习率分别为 和
。余弦退火衰减将两者都降低到
。在蒸馏之前,模型经历了一个预训练阶段,随后进行了5个周期的蒸馏。批量大小设置为4,并且在训练期间图像被随机裁剪和调整大小到192×256。整个框架是在PyTorch中实现的,并在两个NVIDIA GeForce RTX 4090 GPU上执行。
作者通过可视化和定量分析展示了自己的融合质量,并与近年来的其他9种最先进的方法进行了比较,包括DDFM,U2Fusion,TarDAL,SegMiF,FILM,SHIP,MRFS,EMMA和TIMFusion。
图4展示了各种方法的视觉对比。总体而言,作者提出的方法有两个主要优势。
- 首先,它有效地保留了原始图像的多模态信息。在TNO监控场景中,可见图像中的植被细节和红外图像中的烟囱烟雾都得到了很好的保留(左上角的图像集)。在RoadScene中,作者的方法也实现了最佳的树叶恢复。
- 另一方面,作者的方法表现出强大的抗干扰能力,因为它能够准确重建夜晚浓雾中地面上的反光人行横道线和远处建筑物的轮廓(第二行中的绿色框)。SAM的整合增强了作者的方法,使其能够超越其他方法并取得更优越的结果。

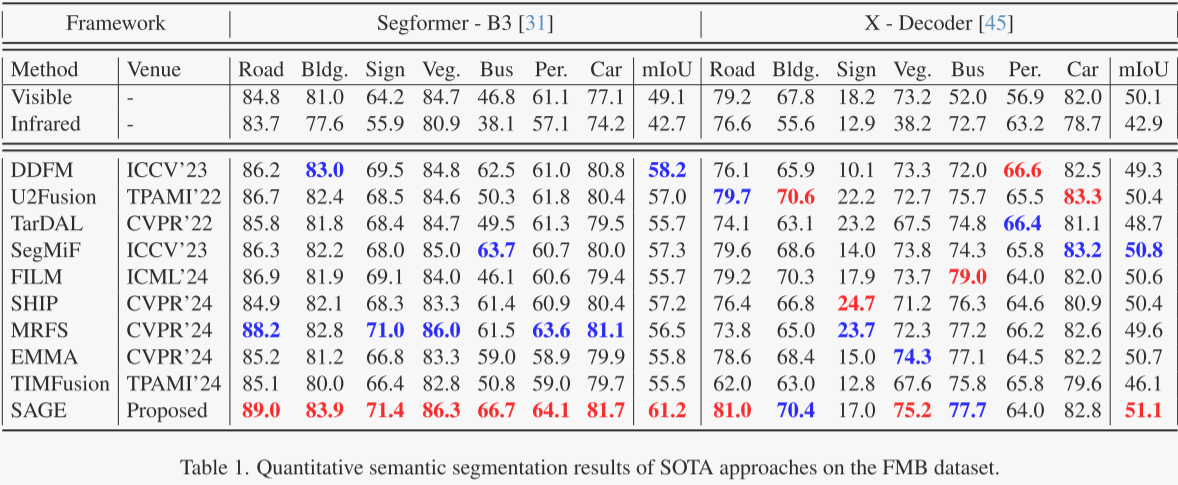
表1展示了在FMB数据集上两个分割框架的IoU结果的定性比较。第一个框架涉及重新训练由各种融合方法生成的图像,而第二个框架使用带有提示词的开放词汇分割网络的输出,无需重新训练。在传统比较中,作者的方法比第二好的方法提高了3.0 mIoU,展示了其在各类别中的竞争优势。此外,在不需要训练的分割网络中,作者的方法也表现良好,这得益于SAM提供的语义信息的适应性。表2进一步展示了在分辨率较低、标签较少的MFNet数据集上的定性结果。尽管作者的方法在背景类别上显示出一些差距,但在关键感知类别和平均性能方面总体上表现出优越性。作者的方法将SAM与融合网络整合,实现了高效分割性能的突破。
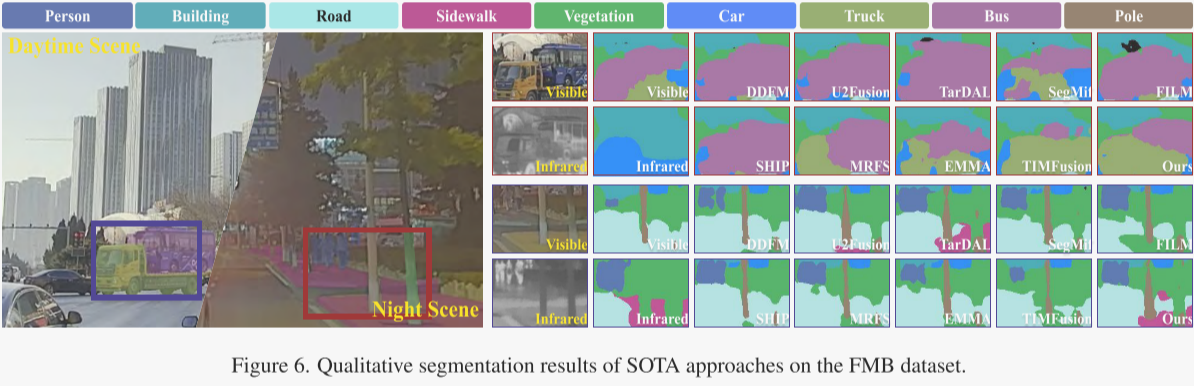
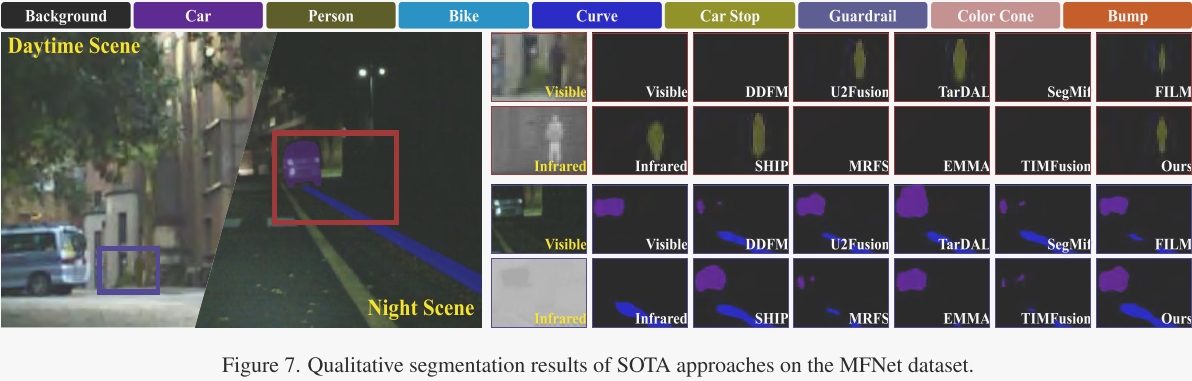
作者在图6中展示了在具有挑战性的新FMB数据集上的分割可视化结果。在白天的交叉路口场景中,得益于SAM提供的强大的语义先验,作者的方法是唯一一个能够完全区分卡车和公共汽车的方法。在夜间道路场景中,作者成功地分割了人行道,实现了最佳性能。此外,作者还在图7中展示了在MFNet数据集上的分割结果。利用SAM学习的高级语义信息,作者的方法成功地分割了白天远处的小行人目标以及夜间几乎不可见的车道曲线。
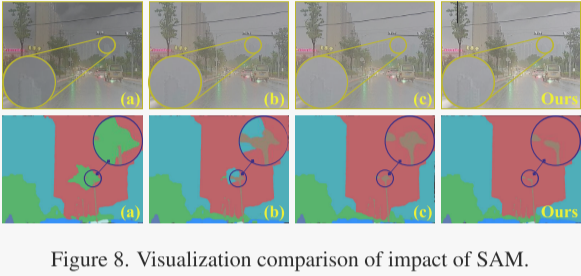
SAM的影响。Segment Anything模块是作者方法中的关键基石。为了探索它的影响,作者通过将SAM从核心框架中分离出来,推导出三个变体。具体来说,在变体(a)中,作者用随机裁剪的源图像块替换语义块,从而将SAM从主网络M中移除。在变体(b)中,作者用分割标签辅助语义块的生成。此外,作者用传统的分割网络替换SO。变体(a)增强了源图像信息,导致最优的相似性指标SCD和MS-SSIM,如表3所示。作者的方法充分利用了SAM提供的语义先验,从而获得了最佳的雾中建筑轮廓,如图8第一行所示。
对SPA模块的研究。作者提出的语义持久注意力(Semantic Persistent Attention,简称SPA)模块在整合来自SAM的语义先验方面发挥着关键作用,有效地指导了固有模态特征的保留和增强。为了研究它的影响,作者设置了三个变体:(a)没有潜在表示Z,(b)持久存储库中没有键值对,以及(c)没有PR。由于这些修改导致的通道损失已经得到纠正。这些消融变体的视觉比较如图9所示。显然,SPA模块中的PR在维持关键信息方面发挥着重要作用。移除任何组件都会导致显著的信息丢失。例如,在(b)中,虽然突出了感兴趣的区域,但缺少源图像信息导致了模糊。同样,SPA模块中缺少PR完全阻止了有益语义信息的捕获,导致网络失去对关键区域的关注,并导致(c)中的低对比度融合结果。

关于蒸馏方案的讨论。此外,作者讨论了蒸馏方案。首先,作者对三元组损失函数的每个组件进行了消融研究,得到了如表3 III所示的变体(a)-(c)。此外,作者用离线蒸馏方法替换了双级优化蒸馏方法,形成了变体(d)。这些变体的视觉比较如图10所示。值得注意的是,传统在线蒸馏的结果在视觉质量和变体(b)生成的梯度图方面都明显不如作者的方法。这证实了在整合语义信息时所提出的蒸馏方法的有效性。

在M3FD基准测试中,作者将自己的方法与另外9种最先进的方法在时间、FLOPS和参数方面进行了比较。如表4所示,作者的方法在所有方面都显示出显著的优势,特别是在时间和FLOPs方面。具体来说,由于作者的蒸馏方案,子网络能够灵活调整同时保持高效率,从而减少了FLOPs。与其他方法相比,作者的方法实现了10.47毫秒的处理时间和52.06G的FLOPs,超越了大多数现有方法,参数数量仅为0.136M,展示了计算效率。
作者的方法有效地减轻了推理过程中SAM的计算负担,显著降低了计算开销,同时保留了语义信息。这种设计使网络能够在处理速度和计算资源之间取得平衡,从而在实际应用中实现更高的效率。
3.代码详解
环境安装
下载代码:
- 源代码:https://github.com/RollingPlain/SAGE_IVIF?tab=readme-ov-file
- detectron2(下载后放到xformer文件夹下):https://github.com/facebookresearch/detectron2
-
使用Python3.10的环境,然后使用requirement安装库
pip install -r requirements.txt下载数据(官方代码库有提供6张图片做测试,仅测试可以不下数据):
数据文件夹格式如下:
SAGE ROOT
├── data
| ├── test
| | ├── Ir # infrared images
| | └── Vis # visible images
| ├── train
| | ├── Ir # infrared images
| | ├── Vis # visible images
| | ├── Label # segmentation ground truth masks
| | └── Mask_cache # cached segmentation masks generated by SAM下载权重:
- Sam:https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth
- focal:https://huggingface.co/xdecoder/X-Decoder/blob/main/xdecoder_focall_last.pt
然后更改dataset/dataset_teacher_FMB.py的_initialize_sam_and_generate_masks()下大约73行处的代码,更改为你的权重位置:
sam = sam_model_registry["vit_b"](checkpoint=-
test.py
运行test.py可直接测试
python test.py测试代码的核心如下,用于在测试数据集上运行预训练的模型,并将生成的结果保存为图像文件。
model.eval()
with torch.no_grad(): # 禁用梯度计算
for data in tqdm(test_loader, ascii='>='):
names = data['name'] # 文件名
exts = data['ext'] # 文件后缀
label, ir, y, cb, cr = data['label'], data['ir'], data['y'], data['cb'], data['cr'] # 标签(初始为空)、ir(红外)、y、cb、cr(可见光) 尺寸均为[b,c,h,w]=[1,1,h,w]
ir, y, cb, cr = utils.togpu_4(device, ir, y, cb, cr) # 转移到GPU
output, _ = model(y, ir) # [b,c,h,w]=[1,1,h,w]
output_colored = utils.YCrCb2RGB(torch.cat((output, cb, cr), dim=1)) # 将输出从YCrCb颜色空间转换为RGB
# 保存
if not os.path.exists(args.save_path):
os.makedirs(args.save_path)
if args.checkpoint != '':
for i, (name, ext) in enumerate(zip(names, exts)):
save_path = os.path.join(args.save_path, f'{name}{ext}')
torchvision.utils.save_image(output_colored[i:i+1], save_path)其中ir, y, cb, cr的定义可以在dataset/dataset_test.py的Data类的__getitem__()函数下找到,这段代码的主要目的是读取红外图像(IR)和可见光图像(VI),并对它们进行预处理,以便用于后续的图像融合或其他处理任务。
cv2.cvtColor(ir_0, cv2.COLOR_BGR2GRAY):将红外图像从BGR格式转换为灰度图像(单通道)。cv2.cvtColor(vi_0, cv2.COLOR_BGR2YCrCb):将可见光图像从BGR格式转换为YCrCb颜色空间。YCrCb颜色空间将图像分为亮度通道(Y)和两个色度通道(Cr和Cb)。vi_0[0, :, :]:提取Y通道(亮度通道)。vi_0[1, :, :]:提取Cb通道(蓝色色度通道)。vi_0[2, :, :]:提取Cr通道(红色色度通道)。
ir_0 = cv2.imread(ir_path_0) # 读取文件
vi_0 = cv2.imread(vis_path_0)
ir_0 = self.trans(self.totensor(cv2.cvtColor(ir_0, cv2.COLOR_BGR2GRAY)), seed)
vi_0 = self.trans(self.totensor(cv2.cvtColor(vi_0, cv2.COLOR_BGR2YCrCb)), seed) # CHW 将BGR格式的图像vi_0转为YCrCb颜色空间
y_0 = vi_0[0, :, :].unsqueeze(dim=0).clone() # 提取Y通道
cb = vi_0[1, :, :].unsqueeze(dim=0) # 提取Cb三个通道
cr = vi_0[2, :, :].unsqueeze(dim=0) # 提取Cr三个通道YCrCb(也称为YCbCr)是一种颜色编码格式,广泛用于图像和视频处理领域。它将图像的颜色信息分为亮度(Y)和色度(Cr和Cb)两个部分。这种分离方式使得图像的亮度和颜色信息可以独立处理,非常适合于图像压缩、颜色调整和多模态图像融合等任务。
在多模态图像融合任务中,YCrCb格式特别适合用于融合亮度信息,同时保留颜色信息。
其中模型model的结构如下(model_sub/model.py下):
- 其整体结构为类似于U-Net的架构,是论文中提到的子网络。
class Network(nn.Module):
def __init__(self, dim: int = 32):
super(Network, self).__init__()
self.module1 = nn.Sequential(
nn.Conv2d(2, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.downsample1 = nn.MaxPool2d(2)
self.module2 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.downsample2 = nn.MaxPool2d(2)
self.module3 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.adjust_channels4 = nn.Sequential(
nn.Conv2d(dim * 2, dim, kernel_size=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.module4 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.adjust_channels5 = nn.Sequential(
nn.Conv2d(dim * 2, dim, kernel_size=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.module5 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.final_decoder = nn.Sequential(
nn.Conv2d(dim, 1, kernel_size=3, padding=1),
nn.Tanh()
)
def forward(self, vi, ir):
src = torch.cat([vi, ir], dim=1) # 将可见光和红外光的y进行拼接 [b,2,h,w]
x1 = self.module1(src) # [b,32,h,w]
x2 = self.downsample1(x1) # MaxPool [b,32,h/2,w/2]
x2 = self.module2(x2) # [b,32,h/2,w/2]
x3 = self.downsample2(x2) # MaxPool [b,32,h/4,w/4]
x3 = self.module3(x3) # [b,32,h/4,w/4]
x4 = F.interpolate(x3, size=(x2.size(2), x2.size(3)), mode='bilinear', align_corners=False) # 双线性插值方法上采样,并且不保留角点对齐。 [b,32,h/2,w/2]
x4 = torch.cat([x4, x2], dim=1) # [b,64,h/2,w/2]
x4 = self.adjust_channels4(x4) # [b,32,h/2,w/2]
x4 = self.module4(x4) # [b,32,h/2,w/2]
x5 = F.interpolate(x4, size=(x1.size(2), x1.size(3)), mode='bilinear', align_corners=False) # [b,32,h,w]
x5 = torch.cat([x5, x1], dim=1) # [b,64,h,w]
x5 = self.adjust_channels5(x5)
x5 = self.module5(x5) # [b,32,h,w]
out = self.final_decoder(x5) # 最终结果 [b,1,h,w]
intermediate_outputs = (x1, x2, x3, x4, x5) # 中间状态
return out, intermediate_outputs-
train.py
代码首先进入main(),包括初始化实验环境、加载预训练权重、启动训练过程
def main():
...
# 设置数据集
train_data = Data_Teacher(mode='train', use_mask_num=args.use_mask_num, cache_mask_num=args.cache_mask_num, crop_size=args.crop_size, root_dir=args.root_dir)# crop resize flip
train_data_size = len(train_data)
indices = list(range(train_data_size))
train_loader = DataLoader(dataset=train_data, batch_size=args.batch_size,sampler=torch.utils.data.sampler.SubsetRandomSampler(indices),pin_memory=True, num_workers=4, drop_last=False)
...
# 定义教师模型和学生模型
model_teacher = Network_Teacher(mask_num=args.use_mask_num)
model_student = Network_Student()
...
# 分别设置教师模型和学生模型的优化器
optimizer_teacher = torch.optim.Adam(model_teacher.parameters(), lr=args.learning_rate_Teacher)
scheduler_teacher = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_teacher, float(args.epochs)*len(train_loader), eta_min=args.learning_rate_min)
# scheduler_teacher = torch.optim.lr_scheduler.StepLR(optimizer_teacher, step_size=args.student_epoch, gamma = target_lr / args.learning_rate_Teacher)
optimizer_student = torch.optim.Adam(model_student.parameters(), lr=args.learning_rate_Student)
scheduler_student = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer_student, float(args.epochs)*len(train_loader), eta_min=args.learning_rate_min)
...
# 开始训练
train(model_teacher, model_student, optimizer_teacher, optimizer_student, scheduler_teacher, scheduler_student, device, train_loader)
dataset
接下来我们看看Data_Teacher(即Data)的处理过程
首先是Data类的构造函数,主要功能如下:
- 初始化数据集根目录、裁剪尺寸等参数;收集可见光图像文件名并记录扩展名;检查红外图像数量是否与可见光图像一致;
- 根据训练/测试模式设置数据增强操作;
- 设置掩码缓存相关参数;
- 若存在缓存文件则加载掩码,否则使用SAM模型生成掩码并保存(函数_initialize_sam_and_generate_masks());
- 初始化全零掩码警告标志。
class Data(Dataset):
def __init__(self, mode, use_mask_num=20, cache_mask_num=50, crop_size=(600, 800), cache_dir=None, root_dir=None):
self.root_dir = root_dir
self.crop_size = crop_size
# 获取文件列表并保存扩展名信息
self.img_list = []
self.extensions = {}
for filename in os.listdir(os.path.join(self.root_dir, 'Vis')):
name, ext = os.path.splitext(filename)
self.img_list.append(name)
self.extensions[name] = ext
self.img_dir = root_dir
# 确认红外图像数量与可见光图像数量一致
assert len(os.listdir(os.path.join(self.img_dir, 'Ir'))) == len(self.img_list)
assert mode == 'train' or mode == 'test', "dataset mode not specified"
self.mode = mode
if mode=='train':
# 不使用RandomResizedCrop,我们将自定义裁剪逻辑
self.transform = transforms.Compose([transforms.RandomHorizontalFlip(p=0.5)])
elif mode=='test':
self.transform = transforms.Compose([])
self.cache_mask_num = cache_mask_num # 缓存中每张图片生成的掩码数量
self.use_mask_num = min(use_mask_num, cache_mask_num) # 实际使用的掩码数量,不能超过缓存的数量
self.totensor = transforms.ToTensor()
# 设置缓存目录
self.cache_dir = cache_dir if cache_dir else os.path.join(self.root_dir, 'Mask_cache')
os.makedirs(self.cache_dir, exist_ok=True)
# 初始化掩码缓存
self.mask_cache = {}
# 检查是否有缓存文件 - 注意这里使用cache_mask_num作为缓存文件名的一部分
cache_file = os.path.join(self.cache_dir, f'mask_cache_{mode}_{cache_mask_num}.pkl')
if os.path.exists(cache_file):
print(f"Loading mask cache from {cache_file}")
with open(cache_file, 'rb') as f:
self.mask_cache = pickle.load(f)
print(f"Loaded masks for {len(self.mask_cache)} images (cached: {cache_mask_num}, using: {use_mask_num})")
else:
# 初始化SAM模型并生成所有掩码
print(f"Initializing SAM model and generating {cache_mask_num} masks per image...")
self._initialize_sam_and_generate_masks(cache_file)
# 用于跟踪是否已经打印过全零掩码警告
self.zero_mask_warning_printed = False其中_initialize_sam_and_generate_masks()的功能是:使用SAM模型为红外和可见光图像生成并缓存指定数量的二值掩码,用于后续数据加载时提升效率。具体逻辑如下:
- 初始化SAM模型:加载预训练的vit_b模型,并配置SamAutomaticMaskGenerator参数。
- 生成与排序掩码:分别对红外(Ir)和可见光(Vis)图像生成掩码,并按面积从大到小排序。
- 缓存掩码数据:保留前cache_mask_num个掩码,保存为字典形式存储在self.mask_cache中。
- 最终保存与提示:全部处理完成后将缓存写入文件,并输出完成信息。
class Data(Dataset):
def _initialize_sam_and_generate_masks(self, cache_file):
# 初始化SAM模型
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
sam = sam_model_registry["vit_b"](checkpoint='/media/good/4TB/mn/model/cv/SAGE_IVIF-main/SAM/sam_vit_b_01ec64.pth').to(device)
mask_generator = SamAutomaticMaskGenerator( # 使用 SAM 模型为整个图像生成遮罩。在图像上生成网格点提示,然后过滤低质量和重复的遮罩。使用 ViT-H 主干网的 SAM 可选择默认设置。
model=sam,
points_per_side=128, # 每边采样点数,控制生成掩码的密度
pred_iou_thresh=0.86, # 预测掩码的 IoU 阈值,过滤低质量结果
stability_score_thresh=0.92, # 稳定性评分阈值,确保掩码一致性
crop_n_layers=1, # 对图像进行裁剪处理的层数
crop_n_points_downscale_factor=2, # 裁剪区域的点数下采样因子
min_mask_region_area=100, # 最小掩码区域面积,过滤小区域
output_mode='binary_mask', # 输出模式为二值掩码
)
# 生成所有掩码并缓存
for idx in tqdm(range(len(self.img_list)), desc="Generating masks"):
name_0 = self.img_list[idx]
ext = self.extensions.get(name_0, '.png') # 获取扩展名,默认为.png
ir_path_0 = os.path.join(self.img_dir, 'Ir', name_0 + ext)
vis_path_0 = os.path.join(self.img_dir, 'Vis', name_0 + ext)
# 读取图像
ir_img = cv2.imread(ir_path_0)
vis_img = cv2.imread(vis_path_0)
# 生成掩码 分别对红外(Ir)和可见光(Vis)图像生成掩码
ir_patches = mask_generator.generate(ir_img)
ir_patches.sort(key=lambda x: x['area'], reverse=True) # 面积从大到小排序
vis_patches = mask_generator.generate(vis_img)
vis_patches.sort(key=lambda x: x['area'], reverse=True)
# 存储掩码 - 使用cache_mask_num
ir_masks = []
vis_masks = []
for i in range(min(self.cache_mask_num, len(ir_patches), len(vis_patches))):
ir_masks.append(ir_patches[i]['segmentation'])
vis_masks.append(vis_patches[i]['segmentation'])
self.mask_cache[name_0] = { # 缓存掩码数据
'ir_masks': ir_masks,
'vis_masks': vis_masks
}
# 每100个样本保存一次缓存,防止中断丢失
if (idx + 1) % 100 == 0:
with open(cache_file, 'wb') as f:
pickle.dump(self.mask_cache, f)
# 保存最终缓存
with open(cache_file, 'wb') as f:
pickle.dump(self.mask_cache, f)其中generate()函数用于生成图像中的多个分割掩码,并以列表形式返回每个掩码的详细信息字典。主要功能如下:
- 生成掩码:调用 _generate_masks 方法获取原始掩码数据。
- 后处理:过滤小区域和噪声(若设置了 min_mask_region_area)。
- 编码掩码:根据 output_mode 将掩码转为 COCO RLE 格式或二值掩码数组。
- 构造输出结果:将每个掩码的信息整理成字典,包括面积、边界框、预测 IOU、点坐标、稳定性分数和裁剪框等。
class SamAutomaticMaskGenerator:
@torch.no_grad()
def generate(self, image: np.ndarray) -> List[Dict[str, Any]]:
# Generate masks
mask_data = self._generate_masks(image) # 获取原始掩码数据。
# 过滤小区域和噪声 Filter small disconnected regions and holes in masks
if self.min_mask_region_area > 0:
mask_data = self.postprocess_small_regions(
mask_data,
self.min_mask_region_area,
max(self.box_nms_thresh, self.crop_nms_thresh),
)
# 将掩码转为 COCO RLE 格式或二值掩码数组。 Encode masks
if self.output_mode == "coco_rle":
mask_data["segmentations"] = [coco_encode_rle(rle) for rle in mask_data["rles"]]
elif self.output_mode == "binary_mask":
mask_data["segmentations"] = [rle_to_mask(rle) for rle in mask_data["rles"]]
else:
mask_data["segmentations"] = mask_data["rles"]
# 构造输出结果 Write mask records
curr_anns = []
for idx in range(len(mask_data["segmentations"])):
ann = {
"segmentation": mask_data["segmentations"][idx],
"area": area_from_rle(mask_data["rles"][idx]),
"bbox": box_xyxy_to_xywh(mask_data["boxes"][idx]).tolist(),
"predicted_iou": mask_data["iou_preds"][idx].item(),
"point_coords": [mask_data["points"][idx].tolist()],
"stability_score": mask_data["stability_score"][idx].item(),
"crop_box": box_xyxy_to_xywh(mask_data["crop_boxes"][idx]).tolist(),
}
curr_anns.append(ann)
return curr_anns
def _generate_masks(self, image: np.ndarray) -> MaskData:
orig_size = image.shape[:2]
crop_boxes, layer_idxs = generate_crop_boxes( # 根据图像尺寸和指定的层数 n_layers,生成多层不同大小的裁剪框(crop boxes),每层包含 (2^i)^2 个裁剪框(i 为层数索引),并控制相邻裁剪框之间的重叠比例。
orig_size, self.crop_n_layers, self.crop_overlap_ratio
)
# Iterate over image crops
data = MaskData()
for crop_box, layer_idx in zip(crop_boxes, layer_idxs):
crop_data = self._process_crop(image, crop_box, layer_idx, orig_size) # 对输入图像的一个裁剪区域进行处理,生成对应的分割掩码,并将其坐标转换回原始图像坐标系。
data.cat(crop_data)
# 去重处理:使用非极大值抑制(NMS)去除不同图像块间重复的掩码,优先保留小图像块的结果 Remove duplicate masks between crops
if len(crop_boxes) > 1:
# Prefer masks from smaller crops
scores = 1 / box_area(data["crop_boxes"])
scores = scores.to(data["boxes"].device)
keep_by_nms = batched_nms(
data["boxes"].float(),
scores,
torch.zeros_like(data["boxes"][:, 0]), # categories
iou_threshold=self.crop_nms_thresh,
)
data.filter(keep_by_nms)
data.to_numpy() # 数据格式转换
return data--
训练 train()
完整代码如下,这段代码实现了教师-学生网络的交替训练流程,主要包括以下功能:
- 初始化TensorBoard日志记录器,用于可视化模型结构和训练过程中的损失;
- 按epoch进行训练循环,根据训练阶段决定是否启用学生网络;
- 交替训练教师网络和学生网络:在指定epoch后,按批次交替更新两个模型;
- 处理数据迭代与重用最后一个batch,防止因数据不均衡导致训练中断;
- 记录并保存模型与训练日志,包括损失值、学习率、模型参数等;
def train(model_teacher, model_student, optimizer_teacher, optimizer_student, scheduler_teacher, scheduler_student, device, train_loader):
# train()用于教师-学生网络的交替训练
# 1.初始化TensorBoard日志记录器,及可视化教师/学生网络的计算图结构。
writer_teacher = SummaryWriter(os.path.join(inference_dir_Teacher, 'train_log'))
input = torch.ones((1, 1, args.crop_size[0], args.crop_size[1])).to(device)
input_2 = torch.ones((1, args.use_mask_num, args.crop_size[0], args.crop_size[1])).to(device)
writer_teacher.add_graph(model_teacher, (input, input, input_2, input_2)) # 将教师网络 model_teacher 的前向传播结构记录到 TensorBoard 中,便于在训练前查看模型结构。
del input
del input_2
writer_student = SummaryWriter(os.path.join(inference_dir_Student, 'train_log'))
input = torch.ones((1, 1, args.crop_size[0], args.crop_size[1])).to(device)
writer_student.add_graph(model_student, (input, input))
del input
total_train_step_teacher = 0
total_train_step_student = 0
# 2.按epoch进行训练循环
for i in range(1, args.epochs+1):
teacher_logger.info("--------------- epoch {} lr {} ---------------".format(i, scheduler_teacher.get_lr()[0]))
student_logger.info("--------------- epoch {} lr {} ---------------".format(i, scheduler_student.get_lr()[0]))
model_teacher.train()
model_student.train()
total_fuse_loss_teacher = 0
total_grad_loss_teacher = 0
total_train_loss_teacher = 0
step_teacher= 0
step_student= 0
total_fuse_loss_student = 0
total_grad_loss_student = 0
total_train_loss_student = 0
total_contrast_loss_student = 0
total_DHs_student = [0] * 2
losses = Losses()
train_iter = iter(train_loader)
batch_idx = 0
# 3.交替训练教师网络和学生网络:在指定epoch后,按批次交替更新两个模型
while True:
try:
# 获取当前批次数据
current_batch_data = next(train_iter)
# 如果学生网络已开始训练,交替使用批次
if i >= args.student_epoch:
# 偶数批次用于学生网络,奇数批次用于教师网络
if batch_idx % 2 == 0:
# 学生网络处理
student_losses = process_student_batch(
current_batch_data, model_teacher, model_student,
optimizer_student, scheduler_student, losses, device,
writer_student, total_train_step_student, step_student,
total_fuse_loss_student, total_grad_loss_student,
total_contrast_loss_student, total_DHs_student, total_train_loss_student
)
# 更新累计损失值
total_fuse_loss_student = student_losses[0]
total_grad_loss_student = student_losses[1]
total_contrast_loss_student = student_losses[2]
total_DHs_student = student_losses[3]
total_train_loss_student = student_losses[4]
step_student += 1
total_train_step_student += 1
else:
# 教师网络处理
teacher_losses = process_teacher_batch(
current_batch_data, model_teacher, model_student,
optimizer_teacher, scheduler_teacher, losses, device, i,
writer_teacher, total_train_step_teacher, step_teacher,
total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher
)
# 更新累计损失值
total_fuse_loss_teacher = teacher_losses[0]
total_grad_loss_teacher = teacher_losses[1]
total_train_loss_teacher = teacher_losses[2]
step_teacher += 1
total_train_step_teacher += 1
else:
# 在学生网络训练前,所有批次都用于教师网络
teacher_losses = process_teacher_batch(
current_batch_data, model_teacher, model_student,
optimizer_teacher, scheduler_teacher, losses, device, i,
writer_teacher, total_train_step_teacher, step_teacher,
total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher
)
# 更新累计损失值
total_fuse_loss_teacher = teacher_losses[0]
total_grad_loss_teacher = teacher_losses[1]
total_train_loss_teacher = teacher_losses[2]
step_teacher += 1
total_train_step_teacher += 1
# 保存当前批次作为上一个批次
last_batch_data = current_batch_data
batch_idx += 1
except StopIteration:
# 4.当迭代器结束时,处理数据迭代与重用最后一个batch,防止因数据不均衡导致训练中断;
if i >= args.student_epoch and batch_idx % 2 == 0 and last_batch_data is not None: # 如果当前是学生网络训练阶段并且上一个批次数据存在
# 则复用上一个批次的数据对学生网络未处理的教师网络部分进行一次训练,以保证教师网络在每个 epoch 中都能得到充分更新,避免因交替训练导致的数据利用不均。
teacher_logger.info("Reusing last batch for teacher at end of epoch")
teacher_losses = process_teacher_batch(
last_batch_data, model_teacher, model_student,
optimizer_teacher, scheduler_teacher, losses, device, i,
writer_teacher, total_train_step_teacher, step_teacher,
total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher
)
# 更新累计损失值
total_fuse_loss_teacher = teacher_losses[0]
total_grad_loss_teacher = teacher_losses[1]
total_train_loss_teacher = teacher_losses[2]
step_teacher += 1
total_train_step_teacher += 1
break
# 5.记录并保存模型与训练日志,包括损失值、学习率、模型参数等;
# 保存模型检查点
if i >= args.student_epoch:
torch.save(model_student.state_dict(), os.path.join(model_path_Student, 'epoch_{}.pt'.format(i)))
student_logger.info('saving epoch {} model'.format(i))
torch.save(model_teacher.state_dict(), os.path.join(model_path_Teacher, 'epoch_{}.pt'.format(i)))
teacher_logger.info('saving epoch {} model'.format(i))
# 记录每个 epoch 的总损失
teacher_logger.info("Teacher:epoch {}: total_fuse_loss: {}, total_grad_loss: {}, total_train_loss: {}".format(
i, total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher))
writer_teacher.add_scalar("total_fuse_loss", total_fuse_loss_teacher, i)
writer_teacher.add_scalar("total_grad_loss", total_grad_loss_teacher, i)
writer_teacher.add_scalar("total_train_loss", total_train_loss_teacher, i)
if i >= args.student_epoch:
student_logger.info("Student:epoch {}: total_fuse_loss: {}, total_grad_loss: {}, total_contrast_loss: {}, total_train_loss: {}".format(
i, total_fuse_loss_student, total_grad_loss_student, total_contrast_loss_student, total_train_loss_student))
student_logger.info("Student:total_DHs: {}".format(total_DHs_student))
writer_student.add_scalar("total_fuse_loss", total_fuse_loss_student, i)
writer_student.add_scalar("total_grad_loss", total_grad_loss_student, i)
writer_student.add_scalar("total_contrast_loss", total_contrast_loss_student, i)
writer_student.add_scalar("total_train_loss", total_train_loss_student, i)
writer_teacher.close()
writer_student.close()接下来,我们一部分一部分地仔细查看。
首先,在代码的开始部分,初始化TensorBoard日志记录器,及可视化教师/学生网络的计算图结构。
# 1.初始化TensorBoard日志记录器,及可视化教师/学生网络的计算图结构。
writer_teacher = SummaryWriter(os.path.join(inference_dir_Teacher, 'train_log'))
input = torch.ones((1, 1, args.crop_size[0], args.crop_size[1])).to(device)
input_2 = torch.ones((1, args.use_mask_num, args.crop_size[0], args.crop_size[1])).to(device)
writer_teacher.add_graph(model_teacher, (input, input, input_2, input_2)) # 将教师网络 model_teacher 的前向传播结构记录到 TensorBoard 中,便于在训练前查看模型结构。
del input
del input_2
writer_student = SummaryWriter(os.path.join(inference_dir_Student, 'train_log'))
input = torch.ones((1, 1, args.crop_size[0], args.crop_size[1])).to(device)
writer_student.add_graph(model_student, (input, input))
del input接着,代码定义了多模态图像融合的总损失,由三部分组成:
- loss_fuse:融合图像与可见光图(y)、红外图(ir)、参考图(ref)的像素差异加权和;
- loss_grad:融合图像与不同输入图像之间的梯度差异加权和;
- loss_contrast:对比度相关损失,用于增强图像结构信息。
最终损失为三者加权和,用于指导模型优化。
for i in range(1, args.epochs+1): # 按epoch进行训练循环
model_teacher.train()
model_student.train()
total_fuse_loss_teacher = 0
total_grad_loss_teacher = 0
total_train_loss_teacher = 0
step_teacher= 0
step_student= 0
total_fuse_loss_student = 0
total_grad_loss_student = 0
total_train_loss_student = 0
total_contrast_loss_student = 0
total_DHs_student = [0] * 2
losses = Losses()其中Losses()如下:
class Losses(nn.Module):
def __init__(self,):
super().__init__()
self.mse = nn.MSELoss()
self.grad = GradientLoss()
self.contrast = ContrastiveLoss()
def cal(self, output, y, ir, ref, y_mask, ir_mask):
loss_fuse = 3*self.mse(output , y ) + 2*self.mse(output , ir ) + 4*self.mse(output, ref) # 融合图像与可见光图(y)、红外图(ir)、参考图(ref)的像素差异加权和
loss_grad = self.grad(output, y, ir) * 9 + self.grad(output, ref, ref) * 3 # 融合图像与不同输入图像之间的梯度差异加权和
loss_contrast, DH_value = self.contrast(output, y, ir, ref, y_mask, ir_mask) # 对比度相关损失,用于增强图像结构信息。
loss_contrast /= 3000
loss = 3*loss_fuse + 3*loss_grad + loss_contrast
return loss, loss_fuse, loss_grad, loss_contrast, DH_value这段代码实现了教师-学生网络的交替训练流程:
- 按epoch进行训练循环,根据训练阶段决定是否启用学生网络;
- 交替训练教师网络和学生网络:在指定epoch后,按批次交替更新两个模型;
- 处理数据迭代与重用最后一个batch,防止因数据不均衡导致训练中断;
for i in range(1, args.epochs+1): # 按epoch进行训练循环
# 此处省略上面的 Loss
while True:
try:
# 获取当前批次数据
current_batch_data = next(train_iter)
# 如果学生网络已开始训练,交替使用批次
if i >= args.student_epoch:
# 偶数批次用于学生网络,奇数批次用于教师网络
if batch_idx % 2 == 0:
# 学生网络处理
student_losses = process_student_batch(
current_batch_data, model_teacher, model_student,
optimizer_student, scheduler_student, losses, device,
writer_student, total_train_step_student, step_student,
total_fuse_loss_student, total_grad_loss_student,
total_contrast_loss_student, total_DHs_student, total_train_loss_student
)
# 更新累计损失值
total_fuse_loss_student = student_losses[0]
total_grad_loss_student = student_losses[1]
total_contrast_loss_student = student_losses[2]
total_DHs_student = student_losses[3]
total_train_loss_student = student_losses[4]
step_student += 1
total_train_step_student += 1
else:
# 教师网络处理
teacher_losses = process_teacher_batch(
current_batch_data, model_teacher, model_student,
optimizer_teacher, scheduler_teacher, losses, device, i,
writer_teacher, total_train_step_teacher, step_teacher,
total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher
)
# 更新累计损失值
total_fuse_loss_teacher = teacher_losses[0]
total_grad_loss_teacher = teacher_losses[1]
total_train_loss_teacher = teacher_losses[2]
step_teacher += 1
total_train_step_teacher += 1
else:
# 在学生网络训练前,所有批次都用于教师网络
teacher_losses = process_teacher_batch(
current_batch_data, model_teacher, model_student,
optimizer_teacher, scheduler_teacher, losses, device, i,
writer_teacher, total_train_step_teacher, step_teacher,
total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher
)
# 更新累计损失值
total_fuse_loss_teacher = teacher_losses[0]
total_grad_loss_teacher = teacher_losses[1]
total_train_loss_teacher = teacher_losses[2]
step_teacher += 1
total_train_step_teacher += 1
# 保存当前批次作为上一个批次
last_batch_data = current_batch_data
batch_idx += 1
except StopIteration:
# 当迭代器结束时
if i >= args.student_epoch and batch_idx % 2 == 0 and last_batch_data is not None: # 如果当前是学生网络训练阶段并且上一个批次数据存在
# 则复用上一个批次的数据对学生网络未处理的教师网络部分进行一次训练,以保证教师网络在每个 epoch 中都能得到充分更新,避免因交替训练导致的数据利用不均。
teacher_logger.info("Reusing last batch for teacher at end of epoch")
teacher_losses = process_teacher_batch(
last_batch_data, model_teacher, model_student,
optimizer_teacher, scheduler_teacher, losses, device, i,
writer_teacher, total_train_step_teacher, step_teacher,
total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher
)
# 更新累计损失值
total_fuse_loss_teacher = teacher_losses[0]
total_grad_loss_teacher = teacher_losses[1]
total_train_loss_teacher = teacher_losses[2]
step_teacher += 1
total_train_step_teacher += 1
break最后保存模型,并计算总损失
# 保存模型检查点
if i >= args.student_epoch:
torch.save(model_student.state_dict(), os.path.join(model_path_Student, 'epoch_{}.pt'.format(i)))
student_logger.info('saving epoch {} model'.format(i))
torch.save(model_teacher.state_dict(), os.path.join(model_path_Teacher, 'epoch_{}.pt'.format(i)))
teacher_logger.info('saving epoch {} model'.format(i))
# 记录每个 epoch 的总损失
teacher_logger.info("Teacher:epoch {}: total_fuse_loss: {}, total_grad_loss: {}, total_train_loss: {}".format(
i, total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher))
writer_teacher.add_scalar("total_fuse_loss", total_fuse_loss_teacher, i)
writer_teacher.add_scalar("total_grad_loss", total_grad_loss_teacher, i)
writer_teacher.add_scalar("total_train_loss", total_train_loss_teacher, i)-
process_teacher_batch()
该函数 process_teacher_batch 的主要功能是处理教师网络在一个训练批次上的前向传播、损失计算、反向传播及日志记录。其逻辑较复杂,可分点解释如下:
- 数据准备与前向推理:将输入数据移至指定设备(如GPU);使用教师模型进行前向传播,得到输出和中间层特征;计算基础损失(fuse_loss 和 grad_loss)。
- 分割损失添加(从指定epoch开始):将输出图像转换为RGB格式用于分割;分批处理图像以避免内存溢出;若分割成功,则计算分割损失并加入总损失。
- 学生网络损失添加(从指定epoch开始):使用学生模型对相同输入进行推理;计算输出损失和中间层特征的余弦相似度损失;合并后加入教师网络总损失。
- 日志打印与可视化、参数更新与模型保存
完整代码如下:
def process_teacher_batch():
"""处理教师网络的一个批次"""
names, ir_mask, vi_mask, label, ir, y, cb, cr, label_mask = data.values()
ir_mask, vi_mask, ir, y, cb, cr, label_mask = utils.togpu_7(device, ir_mask, vi_mask, ir, y, cb, cr, label_mask)
# 1. 计算教师网络的输出
output_teacher, intermediate_outputs_teacher = model_teacher(y, ir, vi_mask, ir_mask)
fuse_loss_teacher, loss_grad_teacher = model_teacher.loss_cal(output_teacher, y, ir)
loss_teacher = fuse_loss_teacher + loss_grad_teacher
# 2. 如果在分割阶段,添加分割损失
loss_segment = None
if epoch >= args.ini_epoch:
output_colored = utils.YCrCb2RGB(torch.cat((output_teacher, cb, cr), dim=1)) # 转换为rgb图
# 使用一个批处理函数来处理分割,减少内存使用
output_masks = []
try:
for j in range(output_colored.size(0)):
# 分批处理图像以减少内存使用
single_image = output_colored[j]
single_image_np = single_image.detach().cpu().permute(1, 2, 0).numpy()
output_pil = Image.fromarray(np.uint8(single_image_np)) # 将RGB图像转为NumPy数组
# 使用低内存模式进行分割
output_mask = segment(output_pil) # 使用xdecoder对输入图像进行语义分割,得到预测掩码
output_masks.append(output_mask)
# 只有在成功处理所有图像时才计算分割损失
if len(output_masks) == output_colored.size(0):
output_masks = torch.stack(output_masks)
label_mask = label_mask.long()
loss_segment = 0.3*calculate_loss(output_masks, label_mask, device=device) # 计算分割损失
loss_teacher = loss_teacher + loss_segment
except RuntimeError as e:
if 'out of memory' in str(e):
# 如果内存不足,尝试清理内存并跳过分割损失
torch.cuda.empty_cache()
teacher_logger.warning("Skipping segmentation due to OOM")
else:
raise e
# 3. 如果在学生网络训练阶段,添加学生网络的损失
total_loss_student_new = None
if epoch >= args.student_epoch: # 判断是否开始学生网络训练阶段
try:
# 使用当前更新的学生网络处理相同的数据
with torch.no_grad():
output_student, intermediate_outputs_student = model_student(y, ir) # 使用当前学生网络推理,得到输出和中间特征
# 计算学生网络的损失
loss_student_new, fuse_loss_student_new, loss_grad_student_new, contrast_loss_student_new, _ = losses.cal(
output_teacher, y, ir, output_student, vi_mask, ir_mask
)
# 计算中间层损失
loss_middle_new = 0.01*calculate_cosine_similarity_loss(intermediate_outputs_teacher, intermediate_outputs_student)
# 添加到教师的总损失中
total_loss_student_new = 0.1*loss_student_new + loss_middle_new
loss_teacher += total_loss_student_new
# 清理内存
del output_student, intermediate_outputs_student
torch.cuda.empty_cache()
except RuntimeError as e:
if 'out of memory' in str(e):
# 如果内存不足,跳过学生网络的损失
torch.cuda.empty_cache()
teacher_logger.warning("Skipping student loss calculation due to OOM")
else:
raise e
# 4. 打印损失信息
...
# 5. 更新教师网络参数
optimizer_teacher.zero_grad()
loss_teacher.backward()
optimizer_teacher.step()
scheduler_teacher.step()
# 更新累计损失
total_fuse_loss_teacher += fuse_loss_teacher.item()
total_grad_loss_teacher += loss_grad_teacher.item()
total_train_loss_teacher += loss_teacher.item()
# 记录和可视化
if total_train_step_teacher % args.report_freq == 0:
report_path = EXP_path_Teacher
output_colored = utils.YCrCb2RGB(torch.cat((output_teacher, cb, cr), dim=1))
input_vis = utils.YCrCb2RGB(torch.cat((y, cb, cr), dim=1))
y2rgb = torch.cat((y, y, y), dim=1)
torchvision.utils.save_image(input_vis, os.path.join(report_path, 'vis.png'))
torchvision.utils.save_image(y2rgb, os.path.join(report_path, 'y.png'))
torchvision.utils.save_image(ir, os.path.join(report_path, 'ir.png'))
torchvision.utils.save_image(output_teacher, os.path.join(report_path, 'output.png'))
torchvision.utils.save_image(output_colored, os.path.join(color_path_Teacher, 'output_color.png'))
torchvision.utils.save_image(output_colored, os.path.join(color_path_Teacher, f'output_colored{total_train_step_teacher}.png'))
if not os.path.exists(os.path.join(report_path, 'masks')):
os.makedirs(os.path.join(report_path, 'masks'))
vi_mask_split = torch.split(vi_mask, 1, dim=1)
for idx2, y_m in enumerate(vi_mask_split):
torchvision.utils.save_image(y_m, os.path.join(report_path, 'masks', 'vi_{}.png'.format(idx2)))
ir_mask_split = torch.split(ir_mask, 1, dim=1)
for idx2, ir_m in enumerate(ir_mask_split):
torchvision.utils.save_image(ir_m, os.path.join(report_path, 'masks', 'ir_{}.png'.format(idx2)))
...
# 保存模型检查点
if total_train_step_teacher % args.test_freq == 0:
torch.save(model_teacher.state_dict(), os.path.join(model_path_Teacher, '{}.pt'.format(total_train_step_teacher)))
teacher_logger.info('saving pt {}'.format(total_train_step_teacher))
# 清理内存
del output_teacher, intermediate_outputs_teacher
torch.cuda.empty_cache()
return total_fuse_loss_teacher, total_grad_loss_teacher, total_train_loss_teacher接下来我们详细看看:
首先使用教师模型进行前向传播,得到输出和中间层特征;然后计算基础损失(fuse_loss 和 grad_loss)
- 前向传播:使用教师网络 model_teacher 对输入数据 y, ir, vi_mask, ir_mask 进行推理,得到输出 output_teacher 和中间层特征 intermediate_outputs_teacher;
- 计算损失:通过 loss_cal 方法计算两个部分的损失:
- fuse_loss_teacher:融合损失,衡量输出与真实值 y 的差异;
- loss_grad_teacher:梯度损失,用于约束图像的边缘或结构信息;
# 1. 计算教师网络的输出
output_teacher, intermediate_outputs_teacher = model_teacher(y, ir, vi_mask, ir_mask)
fuse_loss_teacher, loss_grad_teacher = model_teacher.loss_cal(output_teacher, y, ir)
loss_teacher = fuse_loss_teacher + loss_grad_teacher其中loss_cal()如下:
class Network(nn.Module):
def __init__(self, mask_num=4):
super(Network, self).__init__()
self.mse = nn.MSELoss()
self.grad = GradientLoss()
def loss_cal(self, output, y, ir):
loss = self.mse(output , y ) + self.mse(output , ir )
loss_grad = self.grad(output, y, ir) * 2
return loss, loss_grad接着在训练的后期阶段(epoch >= args.ini_epoch)加入图像分割损失以优化模型
# 2. 如果在分割阶段,添加分割损失
loss_segment = None
if epoch >= args.ini_epoch:
output_colored = utils.YCrCb2RGB(torch.cat((output_teacher, cb, cr), dim=1)) # 转换为rgb图
# 使用一个批处理函数来处理分割,减少内存使用
output_masks = []
try:
for j in range(output_colored.size(0)):
# 分批处理图像以减少内存使用
single_image = output_colored[j]
single_image_np = single_image.detach().cpu().permute(1, 2, 0).numpy()
output_pil = Image.fromarray(np.uint8(single_image_np)) # 将RGB图像转为NumPy数组
# 使用低内存模式进行分割
output_mask = segment(output_pil) # 使用xdecoder对输入图像进行语义分割,得到预测掩码
output_masks.append(output_mask)
# 只有在成功处理所有图像时才计算分割损失
if len(output_masks) == output_colored.size(0):
output_masks = torch.stack(output_masks)
label_mask = label_mask.long()
loss_segment = 0.3*calculate_loss(output_masks, label_mask, device=device) # 计算分割损失
loss_teacher = loss_teacher + loss_segment
其中损失函数如下:
def calculate_loss(inputs, target, device='cuda'):
# 确保 target 是整数类型的张量,并移动到指定设备
target = target.to(device)
if target.dim() == 4 and target.size(1) == 1: # 如果 target 的形状是 [batch_size, 1, height, width],去掉通道维度
target = target.squeeze(1) # 变成 [batch_size, height, width]
# 计算交叉熵损失
criterion = nn.CrossEntropyLoss()
# 计算损失
loss = criterion(inputs, target)
return loss在教师网络训练过程中,当达到指定的epoch后,引入学生网络的损失(包括输出损失和中间层特征的余弦相似度损失),并将其加到教师网络的总损失中以进行联合优化。
- 判断是否开始学生网络训练阶段(if epoch >= args.student_epoch)。
- 使用当前学生网络推理,得到输出和中间特征(model_student(y, ir)),且不计算梯度(with torch.no_grad())。
- 计算学生网络的输出损失(loss_student_new)。
- 计算教师与学生网络中间层特征之间的余弦相似度损失(loss_middle_new),鼓励学生网络模仿教师网络的特征表示。
- 将学生相关损失加到教师总损失中,用于联合训练。
# 3. 如果在学生网络训练阶段,添加学生网络的损失
total_loss_student_new = None
if epoch >= args.student_epoch: # 判断是否开始学生网络训练阶段
try:
# 使用当前更新的学生网络处理相同的数据
with torch.no_grad():
output_student, intermediate_outputs_student = model_student(y, ir) # 使用当前学生网络推理,得到输出和中间特征
# 计算学生网络的损失
loss_student_new, fuse_loss_student_new, loss_grad_student_new, contrast_loss_student_new, _ = losses.cal(
output_teacher, y, ir, output_student, vi_mask, ir_mask
)
# 计算中间层损失
loss_middle_new = 0.01*calculate_cosine_similarity_loss(intermediate_outputs_teacher, intermediate_outputs_student)
# 添加到教师的总损失中
total_loss_student_new = 0.1*loss_student_new + loss_middle_new
loss_teacher += total_loss_student_new
# 清理内存
del output_student, intermediate_outputs_student
torch.cuda.empty_cache()其中中间层损失定义如下:
def calculate_cosine_similarity_loss(intermediate_outputs_student, intermediate_outputs_teacher):
# 确保两个元组长度相等
assert len(intermediate_outputs_student) == len(intermediate_outputs_teacher), "Input tuples must have the same length"
total_loss = 0.0
for student, teacher in zip(intermediate_outputs_student, intermediate_outputs_teacher):
cosine_sim = F.cosine_similarity(student.flatten(1), teacher.flatten(1), dim=1)
cosine_loss = 1 - cosine_sim.mean()
total_loss += cosine_loss
return total_loss-
process_student_batch()
这段代码实现了学生模型的损失计算,和process_teacher_batch类似,包含以下步骤:
- 获取教师网络输出:使用 with torch.no_grad() 禁用梯度计算,前向传播获得教师模型的输出和中间特征。
- 获取学生网络输出:前向传播获得学生模型的输出和中间特征。
- 计算总损失:
- 使用 losses.cal 计算主损失(融合损失、梯度损失、对比损失等)。
- 调用 calculate_cosine_similarity_loss 计算学生与教师中间特征之间的余弦相似度损失。
- 最终损失为 主损失 + 0.3 × 中间层特征损失。
def process_student_batch(data, model_teacher, model_student, optimizer_student, scheduler_student,
losses, device, writer_student, total_train_step_student, step_student,
total_fuse_loss_student, total_grad_loss_student, total_contrast_loss_student,
total_DHs_student, total_train_loss_student):
"""处理学生网络的一个批次"""
names, ir_mask, vi_mask, label, ir, y, cb, cr, label_mask = data.values()
ir_mask, vi_mask, ir, y, cb, cr, label_mask = utils.togpu_7(device, ir_mask, vi_mask, ir, y, cb, cr, label_mask)
# 1. 计算教师网络的输出(用于指导学生网络)
with torch.no_grad():
output_teacher, intermediate_outputs_teacher = model_teacher(y, ir, vi_mask, ir_mask)
# 2. 计算学生网络的输出
output_student, intermediate_outputs_student = model_student(y, ir)
# 3. 计算学生网络的损失
loss_student, fuse_loss_student, loss_grad_student, contrast_loss_student, DH_value_student = losses.cal(
output_student, y, ir, output_teacher, vi_mask, ir_mask
)
loss_middle = 0.3*calculate_cosine_similarity_loss(intermediate_outputs_student, intermediate_outputs_teacher)
total_loss_student = loss_student + loss_middle-
模型架构
教师模型
教师模型定义位于model_main/model.py
其中教师模型的主流程如下:
class Network(nn.Module):
def forward(self, vi, ir, vi_mask, ir_mask):
img = torch.cat((vi, ir), dim=1)
# encoder
vi_mask = self.encoder_mask1_vi(vi_mask)
ir_mask = self.encoder_mask1_ir(ir_mask)
img = self.encoder_img1(img)
img0 = img.clone()
vi_mask = self.encoder_mask2_vi(vi_mask)
ir_mask = self.encoder_mask2_ir(ir_mask)
img = self.encoder_img2(img)
img1 = img.clone()
vi_mask1 = vi_mask.clone()
ir_mask1 = ir_mask.clone()
skip_img0 = img.clone()
# 第一个SPA 模块
# 调用封装的函数并获取vi_mask和ir_mask
img, vi_mask, ir_mask = self.process_img_mask_transformers(img, vi_mask, ir_mask, img1, vi_mask1, ir_mask1) # 实现图像与掩码的多尺度特征提取与融合
out_img1 = img.clone()
skip_img1 = img.clone()
# 第二个SPA 模块
img = self.compress_and_downsample_img1(img)
vi_mask = self.downsample_vi_mask1(vi_mask)
ir_mask = self.downsample_ir_mask1(ir_mask)
img1 = img.clone()
vi_mask1 = vi_mask.clone()
ir_mask1 = ir_mask.clone()
img, vi_mask, ir_mask = self.process_img_mask_transformers(img, vi_mask, ir_mask, img1, vi_mask1, ir_mask1)
out_img2 = img.clone()
skip_img2 = img.clone()
# 第三个SPA 模块
img = self.compress_and_downsample_img2(img)
vi_mask = self.downsample_ir_mask2(vi_mask)
ir_mask = self.downsample_ir_mask2(ir_mask)
img1 = img.clone()
vi_mask1 = vi_mask.clone()
ir_mask1 = ir_mask.clone()
img, vi_mask, ir_mask = self.process_img_mask_transformers(img, vi_mask, ir_mask, img1, vi_mask1, ir_mask1)
out_img3 = img.clone()
# 第四个SPA 模块
img = F.interpolate(img, size=(skip_img2.size(2), skip_img2.size(3)), mode='bilinear', align_corners=True)
img = img + skip_img2
img = self.compress_and_downsample_img3(img)
vi_mask = F.interpolate(vi_mask, scale_factor=2.0, mode='bilinear', align_corners=True)
ir_mask = F.interpolate(ir_mask, scale_factor=2.0, mode='bilinear', align_corners=True)
img1 = img.clone()
vi_mask1 = vi_mask.clone()
ir_mask1 = ir_mask.clone()
img, vi_mask, ir_mask = self.process_img_mask_transformers(img, vi_mask, ir_mask, img1, vi_mask1, ir_mask1)
out_img4 = img.clone()
# 第五个SPA 模块
img = F.interpolate(img, scale_factor=2.0, mode='bilinear', align_corners=True)
img = img + skip_img1
img = self.compress_and_downsample_img4(img)
vi_mask = F.interpolate(vi_mask, scale_factor=2.0, mode='bilinear', align_corners=True)
ir_mask = F.interpolate(ir_mask, scale_factor=2.0, mode='bilinear', align_corners=True)
img1 = img.clone()
vi_mask1 = vi_mask.clone()
ir_mask1 = ir_mask.clone()
img, vi_mask, ir_mask = self.process_img_mask_transformers(img, vi_mask, ir_mask, img1, vi_mask1, ir_mask1)
out_img5 = img.clone()
img = torch.cat((img, skip_img0), dim=1)
# decoder
img = F.interpolate(img, size=img0.shape[2:], mode='bilinear', align_corners=True)
img = self.img_decoder1(img)
img = torch.cat((img, img0), dim=1)
img = F.interpolate(img, size=vi.shape[2:], mode='bilinear', align_corners=True)
out = self.img_decoder2(img)
# 将中间输出通道压缩到32,使用独立的卷积层
out_img1 = self.compress_to_32_1(out_img1)
out_img2 = self.compress_to_32_2(out_img2)
out_img3 = self.compress_to_32_3(out_img3)
out_img4 = self.compress_to_32_4(out_img4)
out_img5 = self.compress_to_32_5(out_img5)
intermediate_outputs = (out_img1, out_img2, out_img3, out_img4, out_img5) # 将中间输出作为字典
return out, intermediate_outputs其中,SPA模块的处理过程如下:

def process_img_mask_transformers(self, img, vi_mask, ir_mask, img1, vi_mask1, ir_mask1):
img_size = img.clone()
vi_mask_size = vi_mask.clone()
ir_mask_size = ir_mask.clone()
img = self.downsample_tf_img(img)
img1 = self.downsample_tf_img1(img1)
vi_mask = self.downsample_tf_vi_mask(vi_mask)
vi_mask1 = self.downsample_tf_vi_mask1(vi_mask1)
ir_mask = self.downsample_tf_ir_mask(ir_mask)
ir_mask1 = self.downsample_tf_ir_mask1(ir_mask1)
img, context_list = self.img_transformer1.forward_contextlist(img) # Fsrc的第一个self-attn
vi_mask, _ = self.mask_transformer1_vi.forward_contextlist(vi_mask, context_list) # Fpvis的第一个cross-attn
ir_mask, _ = self.mask_transformer1_ir.forward_contextlist(ir_mask, context_list) # Fsrc的第一个cross-attn
img4 = img.clone()
vi_mask4 = vi_mask.clone()
ir_mask4 = ir_mask.clone()
# 保存cat前的ir_mask和vi_mask
ir_mask_cat = torch.cat((ir_mask, ir_mask1), dim=1)
vi_mask_cat = torch.cat((vi_mask, vi_mask1), dim=1)
ir_mask = self.middle_mask_ir(ir_mask_cat) + ir_mask4
vi_mask = self.middle_mask_vi(vi_mask_cat) + vi_mask4
ir_mask5 = ir_mask.clone()
vi_mask5 = vi_mask.clone()
mask = torch.cat((ir_mask, vi_mask), dim=1)
mask = self.middle_mask(mask) + ir_mask5 + vi_mask5 + vi_mask4 + ir_mask4
img = torch.cat((img, img1), dim=1)
img = self.middle_img(img) + img4
img2 = img.clone()
mask, context_list = self.mask_transformer2.forward_contextlist(mask, context_list) # 合并后的第三个cross-attn
assert len(context_list) != 0
img, _ = self.img_transformer2.forward_contextlist(img, context_list) # Fsrc的第二个self-attn
img = torch.cat((img, img1, img2, mask), dim=1) # 将img, img1, img2, mask拼接起来
img = F.interpolate(img, size=(img_size.size(2), img_size.size(3)), mode='bilinear', align_corners=False)
vi_mask = F.interpolate(vi_mask, size=(vi_mask_size.size(2), vi_mask_size.size(3)), mode='bilinear', align_corners=False)
ir_mask = F.interpolate(ir_mask,size=(ir_mask_size.size(2), ir_mask_size.size(3)), mode='bilinear', align_corners=False)
return img, vi_mask, ir_mask # 返回img, vi_mask, ir_maskSpatialTransformer 类是对图像数据应用 Transformer 模型的模块。下面展示了带上下文键值对的前向传播函数 forward_contextlist (),其支持为每个 Transformer Block 提供不同的上下文键 context_k 和值 context_v。该类在每个 Block 中启用 return_kv=True 来返回注意力机制中的键和值。
class SpatialTransformer(nn.Module):
def __init__():
super().__init__()
self.in_channels = in_channels
inner_dim = n_heads * d_head
self.norm = Normalize(in_channels)
self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
self.transformer_blocks = nn.ModuleList(
[BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
for d in range(depth)]
)
self.proj_out = zero_module(nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0))
def forward_contextlist(self, x, contextlist=None):
if contextlist is None: # PR
contextlist = [[None, None]] * len(self.transformer_blocks)
if len(contextlist) < len(self.transformer_blocks):
contextlist += [[None, None]] * (len(self.transformer_blocks) - len(contextlist))
assert len(contextlist) == len(self.transformer_blocks)
kv_list = []
b, c, h, w = x.shape
x_in = x
x = self.norm(x)
x = self.proj_in(x)
x = rearrange(x, 'b c h w -> b (h w) c')
for block, context in zip(self.transformer_blocks, contextlist):
context_k, context_v = context
x, k, v = block(x, context_k=context_k, context_v=context_v, return_kv=True) # attn
kv_list.append([k, v])
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
x = self.proj_out(x)
return x + x_in, kv_list其中交叉注意力机制的前向传播过程如下:
class CrossAttention(nn.Module):
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
context_dim = default(context_dim, query_dim)
self.scale = dim_head ** -0.5
self.heads = heads
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, query_dim),
nn.Dropout(dropout)
)
def forward_kv(self, x, context_k=None, context_v=None, mask=None):
h = self.heads
q = self.to_q(x)
context_k = default(context_k, x) # 存在则返回context_k, 否则返回x
context_v = default(context_v, x)
k = self.to_k(context_k) # 转换为k
v = self.to_v(context_v)
k1 = k.clone() # kv-cache
v1 = v.clone()
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
if exists(mask):
mask = rearrange(mask, 'b ... -> b (...)')
max_neg_value = -torch.finfo(sim.dtype).max
mask = repeat(mask, 'b j -> (b h) () j', h=h)
sim.masked_fill_(~mask, max_neg_value)
# 计算attention, what we cannot get enough of
attn = sim.softmax(dim=-1)
out = einsum('b i j, b j d -> b i d', attn, v)
out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
return self.to_out(out), k1, v1-
学生模型
其中学生模型的定义和前向传播过程如下:
class Network(nn.Module):
def __init__(self, dim: int = 32):
super(Network, self).__init__()
self.module1 = nn.Sequential(
nn.Conv2d(2, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.downsample1 = nn.MaxPool2d(2)
self.module2 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.downsample2 = nn.MaxPool2d(2)
self.module3 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.adjust_channels4 = nn.Sequential(
nn.Conv2d(dim * 2, dim, kernel_size=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.module4 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.adjust_channels5 = nn.Sequential(
nn.Conv2d(dim * 2, dim, kernel_size=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.module5 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01),
nn.Conv2d(dim, dim, kernel_size=3, padding=1),
nn.BatchNorm2d(dim),
nn.LeakyReLU(negative_slope=0.01)
)
self.final_decoder = nn.Sequential(
nn.Conv2d(dim, 1, kernel_size=3, padding=1),
nn.Tanh()
)
def forward(self, vi, ir):
src = torch.cat([vi, ir], dim=1) # 将可见光和红外光的y进行拼接 [b,2,h,w]
x1 = self.module1(src) # [b,32,h,w]
x2 = self.downsample1(x1) # MaxPool [b,32,h/2,w/2]
x2 = self.module2(x2) # [b,32,h/2,w/2]
x3 = self.downsample2(x2) # MaxPool [b,32,h/4,w/4]
x3 = self.module3(x3) # [b,32,h/4,w/4]
x4 = F.interpolate(x3, size=(x2.size(2), x2.size(3)), mode='bilinear', align_corners=False) # 双线性插值方法上采样,并且不保留角点对齐。 [b,32,h/2,w/2]
x4 = torch.cat([x4, x2], dim=1) # [b,64,h/2,w/2]
x4 = self.adjust_channels4(x4) # [b,32,h/2,w/2]
x4 = self.module4(x4) # [b,32,h/2,w/2]
x5 = F.interpolate(x4, size=(x1.size(2), x1.size(3)), mode='bilinear', align_corners=False) # [b,32,h,w]
x5 = torch.cat([x5, x1], dim=1) # [b,64,h,w]
x5 = self.adjust_channels5(x5)
x5 = self.module5(x5) # [b,32,h,w]
out = self.final_decoder(x5) # 最终结果 [b,1,h,w]
intermediate_outputs = (x1, x2, x3, x4, x5) # 中间状态
return out, intermediate_outputs-
-
4.总结
本文提出了一种名为SAGE(Semantic-enhanced multi-Modality Image Fusion)的新型多模态图像融合方法,旨在通过融合红外和可见光图像来提升场景理解的质量。在多模态图像融合领域,尤其是红外与可见光图像融合中,如何在保持高质量视觉效果的同时适应下游任务的需求是一个关键挑战。尽管早期研究主要关注视觉质量,但如何在融合过程中保留细节信息并适应不同任务仍然是一个难题。
- 本文采用了一种知识蒸馏策略,将由SAM驱动的主网络所编码的信息迁移到一个轻量级的子网络中,从而显著降低了推理成本,同时保持了高质量的融合效果。
- 本文提出了一个双层优化框架,将主网络和子网络作为一个统一的系统进行联合优化,旨在弥合蒸馏过程中的差距,并在SAM的语义先验指导下保持一致的融合效果。
通过在多个数据集上进行广泛的实验,本文证明了所提出方法在平衡高质量视觉效果和对下游任务适应性方面的优越性,同时保持了实际部署的高效性。实验结果表明,SAGE方法在多个基准数据集上均取得了优异的性能,不仅在视觉质量上优于现有的先进方法,而且在语义分割等下游任务中也展现了卓越的适应性。此外,该方法在计算效率方面也表现出显著优势,推理时间更短,计算资源消耗更少。总之,本文提出的SAGE方法为多模态图像融合领域提供了一种高效且实用的解决方案,能够在保持高质量融合结果的同时,显著降低计算复杂度,满足实际应用中的效率需求。
如果你觉得这篇文章的内容对你有帮助,或者让你眼前一亮,不妨点个赞或收藏一下哦!👍
你的每一个点赞和收藏,都是对我最大的支持,也能让更多人看到这些有价值的内容。如果你还有其他想法或问题,欢迎随时交流!感谢你的支持!💖


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









