










1.简介
这篇文章提出了一种名为Multi-cognitive Visual Adapter(Mona)的新型调优方法,通过仅调整预训练模型中约5%的参数,成功超越了传统的全量微调(full fine-tuning)方法,为视觉识别任务的高效迁移学习提供了一种全新的解决方案。
文章通过详细的实验和分析,展示了Mona在多种视觉任务上的优越性能,证明了其在参数效率和性能提升方面的显著优势,为视觉任务的微调提供了一种新的有效方法。
文章还讨论了Mona-tuning在实际应用中的潜在优势,尤其是在大规模模型时代,全微调不再是视觉任务的最优选择。Mona-tuning通过减少参数数量和提高性能,为视觉任务的迁移学习提供了一种新的高效解决方案。此外,文章还提出了未来的研究方向,包括进一步优化Mona的结构和探索其在更多视觉任务中的应用潜力。
项目主页:CVPR Poster 5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
论文地址:https://arxiv.org/pdf/2408.08345
-
-
2.论文详解
简介
在计算机视觉领域,预训练模型的微调一直是实现高效迁移学习的关键手段。然而,随着模型规模的不断扩大,传统的全量微调方法面临着效率低下和计算成本高昂的问题。尽管近年来delta-tuning方法(即仅调整部分参数或引入轻量级结构进行微调)在自然语言处理中取得了显著进展,但在复杂的视觉任务中,如目标检测、语义分割和实例分割等,这些方法一直未能突破全量微调的性能上限。Mona的出现,打破了这一局限。
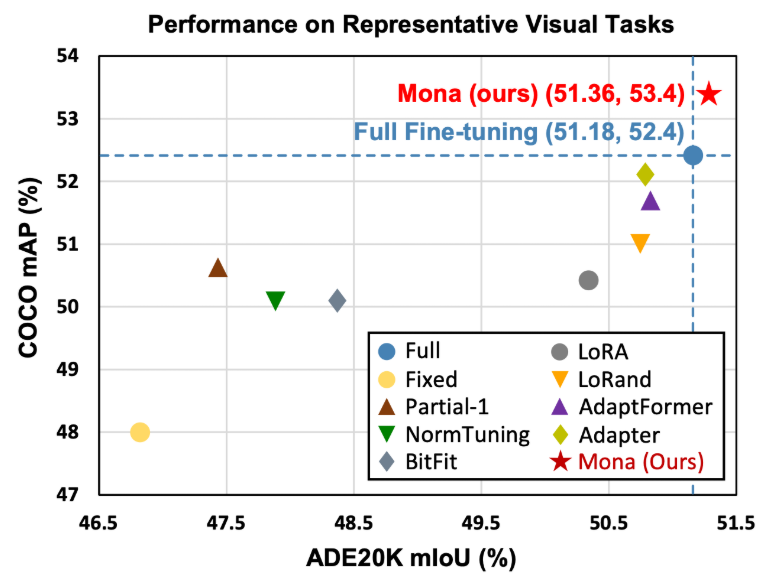
Mona的核心在于其多认知视觉适配器的设计。它通过引入多个视觉友好的滤波器来增强对视觉信号的处理能力,同时通过缩放归一化层来调节输入特征的分布,从而更好地适应新任务的数据分布。这种设计不仅考虑了视觉信号的独特性,还通过多尺度的认知方式,进一步提升了预训练知识向下游任务的迁移效率。实验结果表明,Mona在多个视觉任务上均实现了超越全量微调的性能表现。例如,在COCO数据集的实例分割任务中,Mona相比全量微调实现了1%的性能提升;在Pascal VOC的目标检测任务中,性能提升达到了3.6%;在ADE20K的语义分割任务中,Mona也取得了0.18%的性能增益。
此外,Mona的参数效率极高。在所有实验中,Mona仅调整了预训练模型中约5%的参数,而全量微调则需要调整所有参数。这种参数高效的微调方式不仅显著降低了计算成本,还减少了模型过拟合的风险,尤其适合在数据量有限的任务中应用。例如,在Pascal VOC数据集上,由于数据量相对较少,全量微调容易导致过拟合,而Mona通过固定大部分预训练参数,有效避免了这一问题,从而实现了更好的性能表现。
-
方法
微调
全量微调(full fine-tuning)会更新预训练主干网络中的所有参数,而适配器微调(adapter-tuning)则固定预训练参数,仅更新适配器中的参数。
对于数据集 ,完全微调和适配器微调的优化过程可以分别用公式1和公式2表示:
其中,loss表示训练损失,θ表示整个框架的参数,是适配器微调中固定的参数,ω表示适配器微调中更新的参数,包括适配器中的参数以及主干网络之外的参数。
-
mona
典型的线性适配器在应用于视觉任务时会遇到两个问题。
- 首先,固定的层参数无法微调以匹配新任务的数据分布,导致传递给适配器的特征分布存在偏差。因此,对于适配器来说,优化其来自固定层的输入分布是非常重要的。
- 其次,原始的适配器是为自然语言信号设计的,并没有针对视觉信号进行优化。先前计算机视觉适配器的研究主要基于线性滤波器(主要包括下投影、非线性激活、上投影和跳跃连接),这对于转移视觉知识来说效率不高。为了解决这两个问题,作者进行输入优化并设计了多认知视觉滤波器(multi-cognitive visual filters)。
- 在适配器调优(adapter-tuning)中,预训练模型的大部分参数是固定的,只有适配器中的参数会被更新。这种设计的一个主要问题是:固定的层参数无法根据新任务的数据分布进行调整。换句话说,预训练模型在新任务上的特征表示可能与原始训练任务的特征表示存在偏差。这种偏差会直接影响到适配器的性能,因为适配器接收到的特征分布可能并不是最适合新任务的。
为了解决这个问题,作者在适配器中引入了输入优化机制。传统的适配器设计主要基于自然语言处理(NLP)任务,其核心组件是线性滤波器。这些线性滤波器包括下投影(将特征维度降低)、非线性激活(如ReLU或GeLU)、上投影(将特征维度恢复)以及跳跃连接(用于保留原始特征信息)。然而,这些设计在处理视觉信号时存在效率问题。视觉信号(如图像)具有独特的二维结构,而线性滤波器在处理这种结构时并不高效。
例如,图像中的局部特征(如边缘、纹理)和全局特征(如物体形状)对于视觉任务至关重要,但线性滤波器很难有效地捕捉这些信息。相比之下,卷积操作(如深度可分离卷积)在处理图像特征时更为高效,因为它们能够利用局部感受野和多尺度信息。
为了解决这个问题,作者设计了多认知视觉滤波器(multi-cognitive visual filters)。
-
输入优化。作者使Mona能够调整输入分布和来自固定层的输入比例。具体来说,作者在Mona的顶端添加了一个归一化层和两个可学习的权重,s1和s2,以调整输入分布。下图展示了作者的设计,可以表述为:。
先前的研究表明,归一化有助于稳定前向输入分布和反向传播的梯度。作者在实践中发现,LayerNorm(LN)比BatchNorm更好,因此作者在Mona中采用了LN。
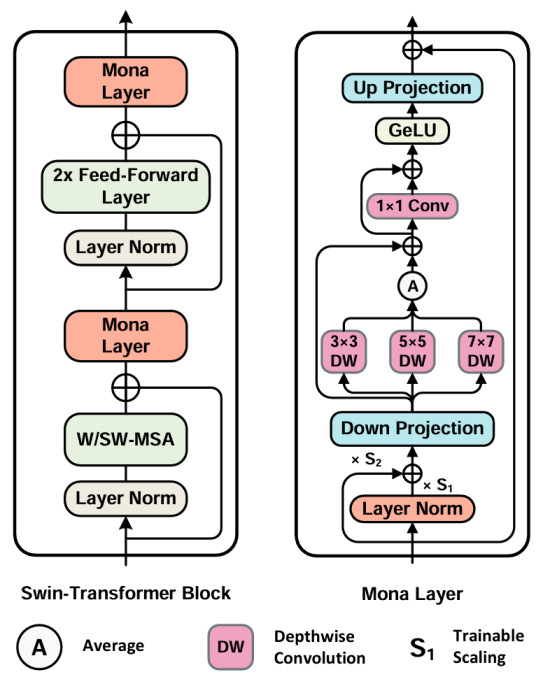
多认知视觉滤波器。对于视觉认知,人眼从不同的尺度处理视觉信号,并将它们整合起来以更好地理解。适配器也应该从多个认知角度处理上游特征,以在下游任务中获得更好的性能。
作者在Mona中引入了多个卷积滤波器以增加认知维度。作者在Mona中采用深度卷积(DepthWise Convolutions,DWConv)而不是标准卷积,以最小化额外的参数大小。具体来说,上游特征在下投影后通过三个DWConv滤波器。卷积核的大小为3×3、5×5和7×7。作者计算来自三个滤波器的平均结果,并使用1×1卷积聚合特征。
作者使用三个深度卷积进行第一次多滤波器卷积,其权重为,然后使用一个点卷积进行第二次卷积,其权重为
。
上述两个卷积步骤可以表述如下:
其中 和
分别表示深度卷积和点卷积。然后,特征通过 GeLU 进行非线性化,并通过上投影恢复。
Mona 的整体计算过程可以表述如下:其中
和
分别表示第 l 个适配器的下投影和上投影,σ 表示 GeLU 激活函数。
-
参数分析
Mona 的参数来自 LN(Layer Normalization)、缩放因子、线性层、DWConv(DepthWise Convolution)和 1×1 卷积。假设适配器的输入维度是 m,下投影后的维度是 n,LN 和缩放因子的参数是 2m + 2,两个线性层的参数是 2mn + m + n,DWConv 层的参数是,而 PWConv(PointWise Convolution)是
。每个 Mona 模块的总参数是:
。
对于每个块,所有 Mona 参数是:。作者将 n 的值设置为一个常数(64),以减少 Mona 中的参数。
-
实验
文章通过广泛的实验验证了Multi-cognitive Visual Adapter(Mona)调优方法在多种视觉任务上的性能表现,并与全量微调(full fine-tuning)及其他delta-tuning方法进行了对比。实验结果表明,Mona在多个具有代表性的视觉任务上均实现了超越全量微调的性能,同时显著减少了新参数的数量,体现了其高效性和优越性。
实验设置:实验涵盖了多种视觉任务,包括实例分割(COCO数据集)、语义分割(ADE20K数据集)、目标检测(Pascal VOC数据集)、定向目标检测(DOTA和STAR数据集)以及图像分类(Oxford 102 Flower、Oxford IIIT Pet和VOC 2007 Classification数据集)。这些任务涵盖了从简单图像分类到复杂目标检测和分割的广泛场景,充分验证了Mona的泛化能力。
预训练模型采用的是在ImageNet-22k上训练的Swin Transformer系列模型,包括Swin-Tiny、Swin-Base和Swin-Large三种不同规模的模型。实验中,Mona仅调整了约5%的参数,而全量微调则调整了所有参数。其他对比方法包括固定参数的基线方法(如仅更新偏置的BitFit和仅更新归一化层的NormTuning)以及带有额外结构的delta-tuning方法(如Adapter、LoRA、AdaptFormer和LoRand)。
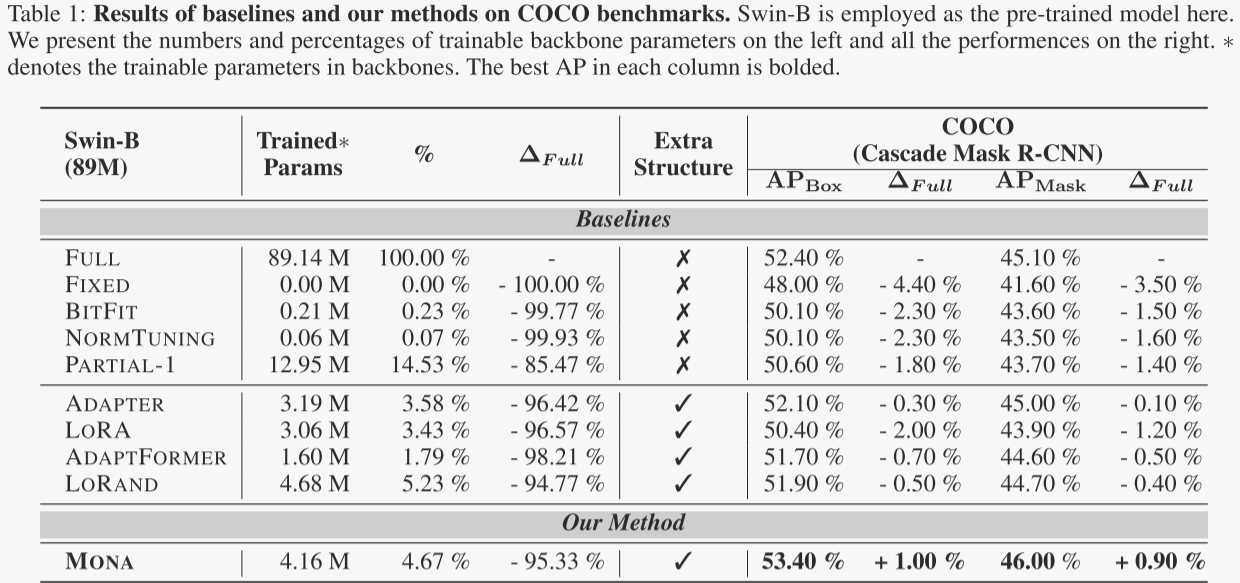
实例分割(COCO数据集)
在COCO数据集的实例分割任务中,Mona实现了53.4%的APBox和46.0%的APMask,相比全量微调分别提升了1.0%和0.9%。这一结果表明,在复杂的实例分割任务中,Mona不仅能够超越全量微调,还能以更少的参数调整实现更好的性能。
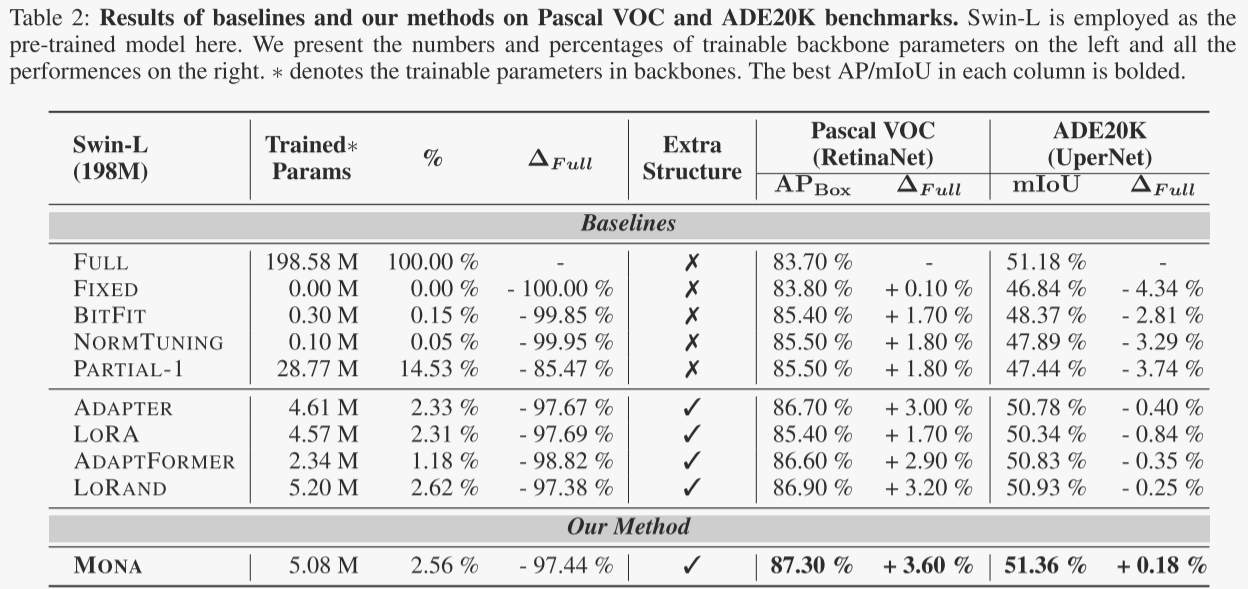
语义分割(ADE20K数据集)与目标检测(Pascal VOC数据集)
在ADE20K数据集的语义分割任务中,Mona达到了51.36%的mIoU,相比全量微调提升了0.18%。尽管提升幅度较小,但这一结果仍然证明了Mona在复杂语义分割任务中的有效性。
在Pascal VOC数据集的目标检测任务中,Mona实现了87.3%的APBox,相比全量微调提升了3.6%。这一显著的性能提升表明,Mona在数据量有限的任务中能够有效避免过拟合,同时充分利用预训练模型的知识。
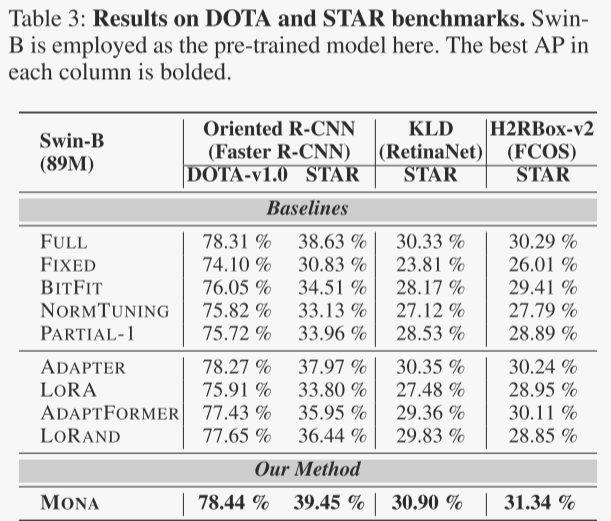
定向目标检测(DOTA和STAR数据集)
在定向目标检测任务中,Mona在DOTA数据集上实现了78.44%的APBox,相比全量微调提升了0.13%。在更具挑战性的STAR数据集上,Mona在多种检测框架下均取得了优于全量微调和其他delta-tuning方法的结果,例如在KLD框架下达到了30.90%的APBox,相比全量微调提升了0.57%。
关键结论
-
性能超越全量微调:Mona在所有实验任务中均实现了超越全量微调的性能表现,尤其是在复杂任务(如实例分割和语义分割)中,Mona的性能提升更为显著。
-
参数效率:Mona仅调整了约5%的参数,而全量微调需要调整所有参数。这表明Mona在保持高性能的同时,显著减少了计算成本和存储需求。
-
泛化能力:Mona不仅在简单图像分类任务中表现出色,还在复杂的目标检测和分割任务中展现了优越性能,证明了其广泛的适用性。
-
模型规模适应性:Mona在不同规模的模型上均表现出一致的性能提升,无论是小型的Swin-T模型,还是大型的Swin-L模型,Mona都能有效提升模型性能。
-
-
3.代码详解
我们以目标检测为例,mona模块位于Swin-Transformer-Object-Detection/mmdet/models/backbones/swin_transformer_mona.py,其代码如下:
class MonaOp(nn.Module):
def __init__(self, in_features):
super().__init__()
self.conv1 = nn.Conv2d(in_features, in_features, kernel_size=3, padding=3 // 2, groups=in_features)
self.conv2 = nn.Conv2d(in_features, in_features, kernel_size=5, padding=5 // 2, groups=in_features)
self.conv3 = nn.Conv2d(in_features, in_features, kernel_size=7, padding=7 // 2, groups=in_features)
self.projector = nn.Conv2d(in_features, in_features, kernel_size=1, )
def forward(self, x):
identity = x # 将输入 x 保存为 identity,用于后续残差连接。
conv1_x = self.conv1(x) # 分别通过三个不同的卷积层
conv2_x = self.conv2(x)
conv3_x = self.conv3(x)
x = (conv1_x + conv2_x + conv3_x) / 3.0 + identity # 对三个卷积输出取平均(除以3),并加回原始输入(残差连接)。
identity = x
x = self.projector(x) # 通过 projector 层进一步变换特征。
return identity + x
class Mona(BaseModule):
def __init__(self, in_dim, factor=4):
super().__init__()
self.project1 = nn.Linear(in_dim, 64)
self.nonlinear = F.gelu
self.project2 = nn.Linear(64, in_dim)
self.dropout = nn.Dropout(p=0.1)
self.adapter_conv = MonaOp(64)
self.norm = nn.LayerNorm(in_dim)
self.gamma = nn.Parameter(torch.ones(in_dim) * 1e-6)
self.gammax = nn.Parameter(torch.ones(in_dim))
def forward(self, x, hw_shapes=None):
identity = x
x = self.norm(x) * self.gamma + x * self.gammax # 归一化与缩放
project1 = self.project1(x) # 线性投影
b, n, c = project1.shape
h, w = hw_shapes
project1 = project1.reshape(b, h, w, c).permute(0, 3, 1, 2)
project1 = self.adapter_conv(project1) # 卷积适配
project1 = project1.permute(0, 2, 3, 1).reshape(b, n, c)
nonlinear = self.nonlinear(project1)
nonlinear = self.dropout(nonlinear)
project2 = self.project2(nonlinear)
return identity + project2在swin-transformer中,将mona模块插入前向传播的过程如下:
class SwinTransformerBlock(nn.Module):
def __init__():
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.H = None
self.W = None
self.my_module_1 = Mona(dim, 8)
self.my_module_2 = Mona(dim, 8) # Adapter_FFN(dim, 8)
def forward(self, x, mask_matrix):
B, L, C = x.shape
H, W = self.H, self.W
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# pad feature maps to multiples of window size
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) # 对输入张量 x 在第1和第2维度(H, W)上分别向上、向左滚动(平移)self.shift_size 个位置,实现特征图的窗口化位移操作
attn_mask = mask_matrix
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # 将特征划分为多个窗口 nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA 在每个窗口上执行窗口多头自注意力(W-MSA/SW-MSA)
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# 合并窗口 merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C
# 反向循环移位恢复原始顺序 reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0: # 去除Padding
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = self.my_module_1(x,(H,W)) # mona
identity = x
x = self.norm2(x)
# FFN
x = self.mlp(x)
x = identity + self.drop_path(x)
x = self.my_module_2(x,(H,W)) # mona todo: correct
return xSwinTransformer加载mona模块的流程如下:
class SwinTransformer_mona(nn.Module):
def init_weights(self, pretrained=None):
def _init_weights(m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
if isinstance(pretrained, str): # 如果提供了 pretrained 路径,则加载预训练权重
self.apply(_init_weights) # 递归地对当前模块及其所有子模块应用 _init_weights 函数进行权重初始化。
logger = get_root_logger()
load_checkpoint(self, pretrained, strict=False, logger=logger) # 加载预训练权重
elif pretrained is None: # 若未提供预训练路径,则仅执行默认权重初始化
self.apply(_init_weights)
else:
raise TypeError('pretrained must be a str or None')
# freeze 冻结所有不包含 'my_module' 的参数
for name, param in self.named_parameters():
if 'my_module' not in name:
param.requires_grad = False模型权重加载过程如下:
def load_state_dict(module, state_dict, strict=False, logger=None):
unexpected_keys = []
all_missing_keys = []
err_msg = []
metadata = getattr(state_dict, '_metadata', None)
state_dict = state_dict.copy()
if metadata is not None:
state_dict._metadata = metadata
# use _load_from_state_dict to enable checkpoint version control
def load(module, prefix=''):
# 将state_dict中的权重加载到模型module中 recursively check parallel module in case that the model has a
# complicated structure, e.g., nn.Module(nn.Module(DDP))
if is_module_wrapper(module):
module = module.module
local_metadata = {} if metadata is None else metadata.get(
prefix[:-1], {})
module._load_from_state_dict(state_dict, prefix, local_metadata, True,
all_missing_keys, unexpected_keys,
err_msg)
for name, child in module._modules.items():
if child is not None:
load(child, prefix + name + '.')
load(module)
load = None # break load->load reference cycle
# 过滤掉BN层中的num_batches_tracked参数,不将其计入缺失的键 ignore "num_batches_tracked" of BN layers
missing_keys = [
key for key in all_missing_keys if 'num_batches_tracked' not in key
]
if unexpected_keys: # 记录不匹配的键
err_msg.append('unexpected key in source '
f'state_dict: {", ".join(unexpected_keys)}\n')
if missing_keys:
err_msg.append(
f'missing keys in source state_dict: {", ".join(missing_keys)}\n')
rank, _ = get_dist_info()
if len(err_msg) > 0 and rank == 0: # 在主进程(rank == 0)中输出警告信息或抛出异常,提示模型与状态字典不完全匹配
err_msg.insert(
0, 'The model and loaded state dict do not match exactly\n')
err_msg = '\n'.join(err_msg)
if strict:
raise RuntimeError(err_msg)
elif logger is not None:
logger.warning(err_msg)
else:
print(err_msg)
def load_checkpoint():
checkpoint = _load_checkpoint(filename, map_location) # 加载原始 checkpoint 数据
# OrderedDict is a subclass of dict
if not isinstance(checkpoint, dict):
raise RuntimeError(
f'No state_dict found in checkpoint file {filename}')
# get state_dict from checkpoint
if 'state_dict' in checkpoint: # 提取 state_dict(模型权重)
state_dict = checkpoint['state_dict']
elif 'model' in checkpoint:
state_dict = checkpoint['model']
else:
state_dict = checkpoint
# strip prefix of state_dict
if list(state_dict.keys())[0].startswith('module.'): # 去除权重中不必要的前缀(如 module. 或 encoder.)
state_dict = {k[7:]: v for k, v in state_dict.items()}
# for MoBY, load model of online branch
if sorted(list(state_dict.keys()))[0].startswith('encoder'):
state_dict = {k.replace('encoder.', ''): v for k, v in state_dict.items() if k.startswith('encoder.')}
# 对位置嵌入等特殊层进行尺寸适配处理 reshape absolute position embedding
if state_dict.get('absolute_pos_embed') is not None:
absolute_pos_embed = state_dict['absolute_pos_embed']
N1, L, C1 = absolute_pos_embed.size()
N2, C2, H, W = model.absolute_pos_embed.size()
if N1 != N2 or C1 != C2 or L != H*W:
logger.warning("Error in loading absolute_pos_embed, pass")
else:
state_dict['absolute_pos_embed'] = absolute_pos_embed.view(N2, H, W, C2).permute(0, 3, 1, 2)
# interpolate position bias table if needed
relative_position_bias_table_keys = [k for k in state_dict.keys() if "relative_position_bias_table" in k]
for table_key in relative_position_bias_table_keys:
table_pretrained = state_dict[table_key]
table_current = model.state_dict()[table_key]
L1, nH1 = table_pretrained.size()
L2, nH2 = table_current.size()
if nH1 != nH2:
logger.warning(f"Error in loading {table_key}, pass")
else:
if L1 != L2:
S1 = int(L1 ** 0.5)
S2 = int(L2 ** 0.5)
table_pretrained_resized = F.interpolate(
table_pretrained.permute(1, 0).view(1, nH1, S1, S1),
size=(S2, S2), mode='bicubic')
state_dict[table_key] = table_pretrained_resized.view(nH2, L2).permute(1, 0)
# 使用 load_state_dict 将权重加载到模型中 load state_dict
load_state_dict(model, state_dict, strict, logger)
return checkpoint-
-
4.总结
这篇文章提出了一种名为Multi-cognitive Visual Adapter(Mona)的新型调优方法,通过仅调整预训练模型中约5%的参数,成功超越了传统的全量微调(full fine-tuning)方法,为视觉识别任务的高效迁移学习提供了一种全新的解决方案。
Mona的核心在于其多认知视觉适配器的设计。它通过引入多个视觉友好的滤波器来增强对视觉信号的处理能力,同时通过缩放归一化层来调节输入特征的分布,从而更好地适应新任务的数据分布。这种设计不仅考虑了视觉信号的独特性,还通过多尺度的认知方式,进一步提升了预训练知识向下游任务的迁移效率。
此外,Mona的参数效率极高。在所有实验中,Mona仅调整了预训练模型中约5%的参数,而全量微调则需要调整所有参数。这种参数高效的微调方式不仅显著降低了计算成本,还减少了模型过拟合的风险,尤其适合在数据量有限的任务中应用。
实验结果表明,Mona作为一种新型的delta-tuning方法,通过仅调整少量参数,实现了超越全量微调的性能表现。这一结果不仅证明了Mona在视觉任务中的高效性和优越性,还为未来视觉任务的迁移学习提供了一种全新的思路。随着预训练模型在视觉领域的广泛应用,Mona有望成为未来视觉任务微调的首选方法。
总的来说,Mona的出现为视觉任务的微调提供了一种全新的思路。它通过仅调整少量参数,实现了超越全量微调的性能表现,同时显著降低了计算成本和存储需求。这种高效的微调方法不仅适用于大规模模型,还能帮助资源有限的研究团队和项目组在小型模型上实现高性能的视觉任务。随着预训练模型在视觉领域的广泛应用,Mona有望成为未来视觉任务迁移学习的首选方法。
🌟 亲爱的朋友们,感谢你们一直以来的陪伴与支持!🌟
在这个信息爆炸的时代,我们相遇在知识的海洋,共同探索、学习和成长。每一篇文章、每一个回答,都是我们精心准备的礼物,希望它们能为你带来启发和帮助。
如果你觉得我们的内容对你有所启发,或者你希望在未来的日子里继续与我们同行,不妨动动你的手指,给我们一个👍点赞,💖收藏,或者点击关注👀。你的每一个小动作,都是对我们最大的鼓励和支持!
我们承诺,将继续努力,为你带来更多有价值的内容。让我们携手前行,在知识的旅途中不断发现新的风景!
#点赞支持 #知识分享 #共同成长


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









