







Why not DBMS?
- Scale is too large for most commercial Databases
- Cost would be very high
- Low-level storage optimizations help performance significantly
- Hard to map semi-structured data to relational database
- Non-uniform fields makes it difficult to insert/query data
What’s bigtable?
- Scale is too large for most commercial Databases
- Cost would be very high
- Low-level storage optimizations help performance significantly
- Hard to map semi-structured data to relational database
- Non-uniform fields makes it difficult to insert/query data
Goals
- Wide applicability
- Scalability
- High performance
- High availability
Simple data model that supports dynamic control over data layout and format
Data Model
- A Bigtable is a sparse, distributed, persistent multidimensional sorted map.
- The map is indexed by a row key, column key, and a timestamp.
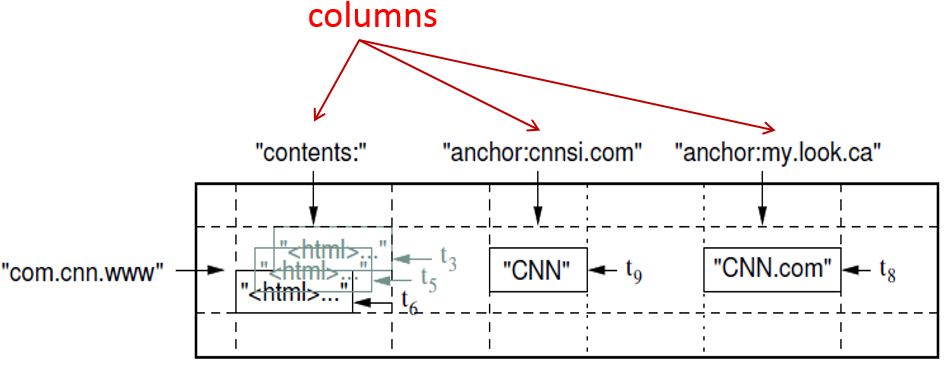
(row:string, column:string, time:int64) → string 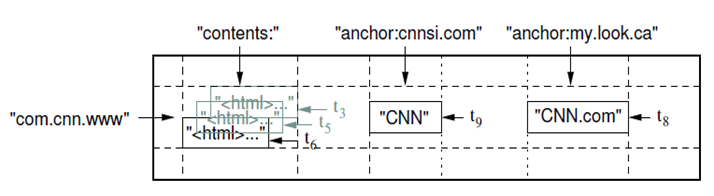 Row
Row
- The row keys in a table are arbitrary strings.
- Data is maintained in lexicographic order by row key
- Each row range is called a tablet, which is the unit of distribution and load balancing.
Column
- Column keys are grouped into sets called column families.
- Data stored in a column family is usually of the same type
- A column key is named using the syntax: family : qualifier.
- Column family names must be printable , but qualifiers may be arbitrary strings.
Timestamp
- Each cell in a Bigtable can contain multiple versions of the same data
- Versions are indexed by 64-bit integer timestamps
- Timestamps can be assigned:
- automatically by Bigtable , or
- explicitly by client applications

API
- Creating and deleting tables and column families.
- Changing cluster , table and column family metadata.
- Support for single row transactions
- Allows cells to be used as integer counters
- Client supplied scripts can be executed in the address space of servers
Implement
Three major components
- Library linked into every client
- Single master server
- Assigning tablets to tablet servers
- Detecting addition and expiration of tablet servers
- Balancing tablet-server load
- Garbage collection files in GFS
- Many tablet servers
- Manages a set of tablets
- Tablet servers handle read and write requests to its table
- Splits tablets that have grown too large
- Clients communicate with tablet server directly for read and write.
- Each table consist of a set of tablets.
- Initially, each table have only one tablets.
- tablets are automatically splited as the table rows.
- Row size can be arbitrary(hundreds of GB)
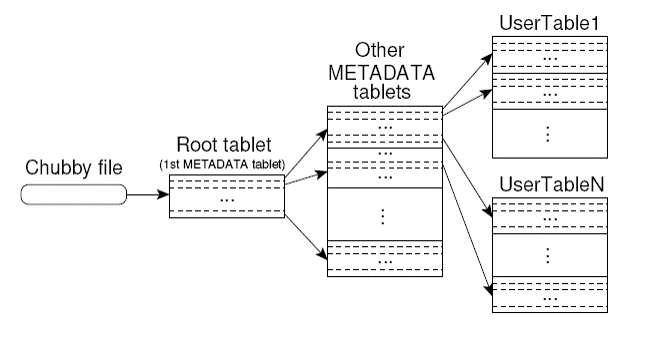
Locating Tablets
Three level hierarchy
- level 1: chubby file containing location of the root tablet.
- level 2. Root tablet contains the location of METADATA tablets.
- level 3: each METADATA tablet contains the location of users tablets.
location of tablet is stored under a row key that encodes table identifier and its end row.
Assinging Tablets
Tablet server startup
- It creates and acquires an exclusive lock on , a uniquely named file on Chubby.
- Master monitors this directory to discover tablet servers.
Tablet server stops serving tablets
- If it loses its exclusive lock.
- Tries to reacquire the lock on its file as long as the file still exists.
- If file no longer exists, the tablet server will never be able to serve again.
Master server startup
- Grabs unique master lock in Chubby.
- Scans the tablet server directory in Chubby.
- Communicates with every live tablet server
- Scans METADATA table to learn set of tablets.
Master is responsible for finding when tablet server is no longer serving its tablets and reassigning those tablets as soon as possible.
- Periodically asks each tablet server for the status of its lock
- If no reply, master tries to acquire the lock itself
- If successful to acquire lock, then tablet server is either dead or having network trouble
Tablet Serving
- Updates committed to a commit log
- Recently committed updates are stored in memory –memtable
- Older updates are stored in a sequence of SSTables.

write option
- Server checks if it is well-formed
- Checks if the sender is authorized
- Write to commit log
- After commit, contents are inserted into Memtable
read option
- Check well-formedness of request.
- Check authorization in Chubby file
- Merge memtable and SSTables to find data
- Return data.
Compaction
In order to control size of memtable, tablet log, and SSTable files, “compaction” is used.
- Minor Compaction.- Move data from memtable to SSTable.
- Merging Compaction. – Merge multiple SSTables and memtable to a single SSTable.
- Major Compaction. – that re-writes all SSTables into exactly one SSTable
Reference
Bigtable: A Distributed Storage System for Structured Data by Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber
http://glinden.blogspot.com/2006/08/google-bigtable-paper.html















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









