






资源下载地址:https://download.csdn.net/download/sheziqiong/85721314
1 引言
西方语言在语句(或从句)内词汇之间存在分割符(空格),而汉语的词汇在语句中是连续排列的。因此,汉语词汇的切分(分词)在中文信息处理的许多应用领域,如机器翻译、文献检索、文献分类、文献过滤、以及词频统计等,是非常重要的第一步。
自动分词是基于字符串匹配的原理进行的。迄今为止,已经有许多文献对各种分词方法进行探讨,其着重点或为分词的速度方面,或为分词的精度方面以及分词的规范。本文主要探讨分词的速度问题,通过实验对比和理论分析,说明我们所提出的算法是有效的。
目前人们所提出的分词方法,在考虑效率问题时,通常在词典的组织方面进行某种调整,以适应相应的算法,如最大匹配法、最小匹配法、逐词遍历法、以及最佳匹配法等。这些方法中,或将词典按词条长度排序或按词频排序,其目的在于协调算法与数据结构,使之效率最高。客观地说,它们都在一定程度上提高了分词的效率。
本文所介绍的是基于词典的最大向前匹配方法。而在数据结构方面,我们则是将词典组织成自动机形式。
2 数据结构与算法
文献[1,2,3]给出了三种基于词典的最大向前匹配方法的分词算法(相应于文献编号,我们以后分别称其对应的算法为算法1、算法2、和算法3)。我们可以把算法1看作是原始算法,把算法2看作是算法1的改进,而算法3则是算法2的进一步优化。在词典的组织方面,算法2和算法3是按照正常的词典排序(即按汉字的机器内码表示排序),并辅以词条的首字索引,以标明以该字起始词条在词典中的首记录。例如,在一般的词典中,词条的形式如下图所示:
啊 啊哈
啊呀
啊哟
阿 阿爸
阿斗
阿尔巴尼亚
阿飞
阿富汗
…
图1:一般分词词典的形式
在实际存储时,可以在词尾部分删除首字。这样做不仅节省了存储空间,更重要的是缩短了字符串比较的长度。
算法2和算法3对首字的检索都是基于哈希算法;算法2对于词尾部分采用线性搜索,而算法3则采用二分搜索。采用何种搜索算法应根据所用词典中每个首字下的词条数目确定,一般词条数较小时,二者无明显差异。这是由这两种算法本身的特性决定的。实际词典中许多首字下的词条数目很大,因此,采用二分搜索法较优。我们的实验结果也证实了这一点。
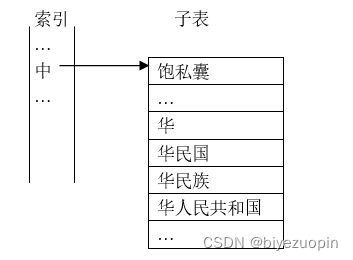
算法2和算法3在词典的组织方面是一致的,即如同普通词典一样,按照汉字的内码递增排序,并以词条的首字建立哈希索引。我们可以将同一首字下的所有词条组织成一个子表结构,如下图所示。
图2:词典的逻辑结构
假设:源文本 source_text=“中华人民共和国成立于1949年。”
分词结果=“中华人民共和国/成立/于/1949/年/。”
分词过程为:
-
从源文本 source_text中取首字head_word = “中”,并设置已切分词汇segmented_word = head_word;
-
从索引中查找该首字。若未找到,则暂将该字作为单字词输出;否则,将其后续字符加入临时变量tail_word =“华”;
-
在以“中”为首字的子表中查找包含tail_word的词条;若查到,则从source_text中取字,继续加入tail_word中,并继续在子表中查找。在此过程中,如果满足条件的词条等于当前的tail_word,则置segmented_word = head_word + tail_word;
-
步骤3中的查找失败时,则以当前segmented_word中的字符串作为输出结果。
算法2和算法3的处理思想是一致的,只是在上述第三步的查找中,算法2采用的是顺序查找,而算法3采用的是二分查找。
在本例中,tail_word从“华”递增到“华人民共和国”的过程中,即使不计查找过程中的比较次数,tail_word与词典中的子表项“华”字比较了1次,同“华人民共和国”比较了5次。其比较长度分别为2、4、6、8、10、12。
“华” (segmented_word = “中华”)
“华人”
“华人民”
“华人民共”
“华人民共和”
“华人民共和国” (segmented_word = “中华人民共和国”)
显然,这种比较过程存在冗余的比较操作。例如,“人”字比较了5次,其中后4次的比较是多余的。因为字符串比较所需的时间同字符串的长度成正比,对于较长的词条,这种现象尤为突出。
为了消除这种冗余操作,我们提出将词典的词尾部分以自动机的形式来组织。为此,我们将组成单词的每个字以一种链表节点的形式存储,其抽象数据结构的定义如下:
Pnode = ^Tnode;
Tnode = record
Brother: Pnode;
Cchar: String[2];
Accepted: Boolean;
Child: Pnode;
End;
这样,上述的例子中,词典的部分内容形式如下(其中T代表True,F代表False;节点左侧为兄弟链,右侧为孩子链):
图3:改进的词典逻辑结构

显然,这实际上是将词典以二叉树的形式组织起来,只是各节点中增加了接收状态。
在词典中对于特定的首字,前两字相同的词条很少,前三字相同的词条更少。当我们以这种形式组织词典后,除子表的第一层外,各个节点的兄弟数目都很小,对它们的查找采用顺序查找方法较为适宜。对于子表的第一层,则采用二分查找。由于我们无法在一个纯粹的链表结构中进行二分查找,为此,我们可以将子表的首层节点以动态数组形式组织,或装入容器类(Container)的可直接存取的线性表结构中(如C++的vector,Delphi的Tlist等)。
对应于前文所述的算法,其第三步变为:
以二分查找方法在子表首层中查找含tail_word的节点;若查到,从source_text中取后续汉字,继续加入tail_word中,并继续在当前子表的孩子节点中顺序查找该汉字。在此过程中,如果满足条件的节点中Accepted域为真,则置segmented_word = head_word + tail_word;
依此算法,显然不会出现同一词条中的重复比较,且每次比较的字符串(一个汉字)长度均为2。与算法2和算法3相比,在子表首层以下的搜索过程中,每次搜索的范围因词典的组织方式变化而大大缩小,这也在一定程度上提高了分词效率。
3 对比
文献[2,3]都采用了文献[2]所提出的复杂度估算方法,其相应算法的复杂度分别为2.89和1.66。由于在处理3字以上词时搜索空间的缩小(即使对于出现频率最高的双字词,基于最大匹配原则,也需对其后继字符进一步测试比较),本文的算法复杂度显然应低于算法3的1.66。此外,文献[2]所提出的复杂度估算方法并未考虑字符串长度对比较时间的影响。
根据我们的实验测定,算法3比算法2大约快3倍。表1是针对同一组2.576MB文本的分词结果比较,其中的比较次数是指实际调用字符串比较函数的次数,比较总长度是指每次调用字符串比较函数所比较的字符串的总长度,运行环境为Windows2000(奔腾III,800M主频,256M内存)。
| 算法 | 时间(秒) | 切分词数 | 比较次数 | 比较总长度 |
|---|---|---|---|---|
| 算法2 | 31.34 | 521295 | 20664107 | 45567532 |
| 算法3 | 11.76 | 521295 | 4110900 | 12461118 |
| 本文 | 6.32(3.37) | 521295 | 3596760 | 7193520 |
表1 三种算法针对同一组语料的分词实验结果
从表1可以看出,算法2比较次数过多,且字符串比较的总长度过大。而算法3的比较次数和字符串比较的总长度均大于本文算法。同一首字下的所有词条组织成的子表的查找,应采用二分查找。这正是算法3优于算法2的关键之处。而本文算法的优势则体现在比较次数的缩小和被比较字符串的长度缩小,绝无多余的比较,从而在总比较长度上占绝对优势。
从实验结果可以看出,分词时间大约与字符串比较的总长度成正比。实际上,我们的多组对比实验表明,随着被处理语料规模的增大,这种线性比例关系表现得更为明显。
我们的实验所对比的三种算法均至少用C++和Object Pascal两种语言实现,而且为了对比结果客观公正,所用数据结构和算法的实现细节都尽可能一致。文中的实验数据是Delphi版本的结果,其中括号内的时间是在用小于运算代替字符串比较函数时的结果(Object Pascal对字符串的处理能力强于C/C++)。另外,C++的标准模板库(STL)的运行效率很低,我们的其它实验对比表明,C++版本的分词程序在不使用STL时运行速度大约是使用STL时的9倍。
另需说明的是,在本文的算法描述中,为了以文字形式描述方便,引入了几个辅助变量。它们在实际编程时并非必需,例如可以用一些下标变量来完成segmented_word和tail_word的功能。
资源下载地址:https://download.csdn.net/download/sheziqiong/85721314















 1531
1531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











