







主要内容
关联规则分析概述
频繁项集、闭项集和关联规则
频繁项集挖掘方法
关联模式评估方法
Apriori算法应用
关联规则挖掘(上)
关联规则挖掘(下)
关联规则分析用于在一个数据集中找出各数据项之间的关联关系,广泛用于购物篮数据、生物信息学、医疗诊断、网页挖掘和科学数据分析中。
一、关联规则分析概述
关联规则分析又称购物篮分析,最早是为了发现超市销售数据库中不同商品之间的关联关系。
采用关联模型比较典型的案例是“尿布与啤酒”的故事。
关联规则分析通过量化的数字描述某物品的出现对其他物品的影响程度,是数据挖掘中较活跃的研究方法之一。目前,常用的关联规则分析算法如表6-1所示。

二、频繁项集、闭项集和关联规则
关联规则分析最早是为了发现超市销售数据库中不同商品间的关联关系。
频繁模式(Frequent Pattern)是指频繁出现在数据集中的模式(如项集,子序列或子结构)。挖掘频繁模式可以揭示数据集的内在的、重要的特性,可以作为很多重要数据挖掘任务的基础,比如:

1.关联规则的表示形式
模式可以用关联规则(Association Rule)的形式表示。例如购买计算机也趋向于同时购买打印机,可以用如下关联规则表示。
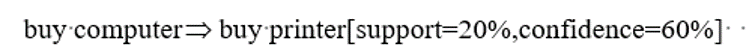
规则的支持度(Support)和置信度(Confidence)是规则兴趣度的两种度量,分别反映规则的有用性和确定性。
2.频繁项集和闭项集

同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则称为强关联规则。

一般来说,关联规则的挖掘可以看作两步的过程:
(1)找出所有频繁项集,该项集的每一个出现的支持度计数≥ min_sup;
(2)由频繁项集产生强关联规则,即满足最小支持度和最小置信度的规则。
由于第2步的开销远小于第1步,因此挖掘关联规则的总体性能由第1步决定。第1步主要是找到所有的频繁k项集,而在找频繁项集的过程中,需要对每个k项集,计算支持度计数以发现频繁项集,k项集的产生过程如图6.1
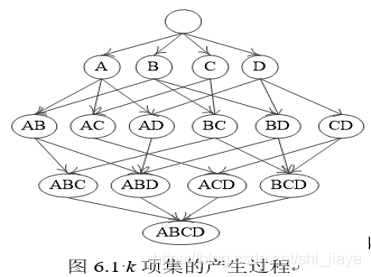

因此,项集的个数太大严重影响算法的效率。为了克服这一困难,引入闭频繁项集和极大频繁项集的概念。
项集X在数据集D中是闭的(Closed),如果不存在X的真超项集Y使得Y与X在D中具有相同的支持度计数。
三、频繁项集挖掘方法
Apriori算法
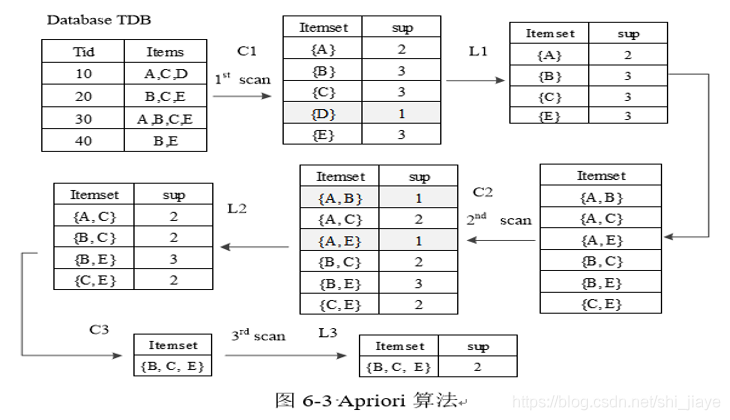
Apriori算法是Agrawal和Srikant于1994年提出,是布尔关联规则挖掘频繁项集的原创性算法,通过限制候选产生发现频繁项集。Apriori算法使用一种称为逐层搜索的迭代方法,其中k项集用于探索(k+1)项集。具体过程描述如下:首先扫描数据库,累计每个项的计数,并收集满足最小支持度的项找出频繁1项集记为L1。然后使用L1找出频繁2项集的集合L2,使用L2找出L3,迭代直到无法再找到频繁k项集为止。找出每个Lk需要一次完整的数据库扫描。
Apriori算法使用一种称为先验性质的特性进行搜索空间的压缩,即频繁项集的所有非空子集也一定是频繁的。
Apriori算法产生k项频繁集的过程主要包括 连接 和 剪枝 两步。

(2)剪枝
Ck是Lk的超集,Ck的成员不一定全部是频繁的,但所有频繁的k项集都包含在Ck中。为了减少计算量,可以使用Apriori性质,即如果一个k项集的(k-1)子集不在Lk-1中,则该候选不可能是频繁的,可以直接从Ck删除。这种子集测试可以使用所有频繁项集的散列树快速完成。
由频繁项集产生关联规则

提高Apriori算法的效率
Apriori算法使用逐层搜索的迭代方法,随着k的递增不断寻找满足最小支持度阈值的“k项集”,第k次迭代从k-1次迭代的结果中查找频繁k项集,每一次迭代都要扫描一次数据库。而且,对候选项集的支持度计算非常繁琐。
为了进一步提高Apriori算法的效率,一般采用减少对数据的扫描次数、缩小产生的候选项集以及改进对候选项集的支持度计算方法等策略。
1.基于hash表的项集计数
2.事务压缩(压缩进一步迭代的事务数)
3.抽样(在给定数据的一个子集挖掘)
4.动态项集计数
频繁模式增长算法
Apriori算法的候选产生-检查方法显著压缩了候选集的规模,但还是可能要产生大量的候选项集。而且,要重复扫描数据库,通过模式匹配检查一个很大的候选集合。
1.FP树原理
频繁模式增长(FP-growth)是一种不产生候选频繁项集的算法,它采用分治策略(Divide and Conquer),在经过第一遍扫描之后,把代表频繁项集的数据库压缩进一棵频繁模式树(FP-tree),同时依然保留其中的关联信息;然后将FP-tree分化成一些条件库,每个库和一个长度为1的频集相关,再对这些条件库分别进行挖掘(降低了I/O开销)。
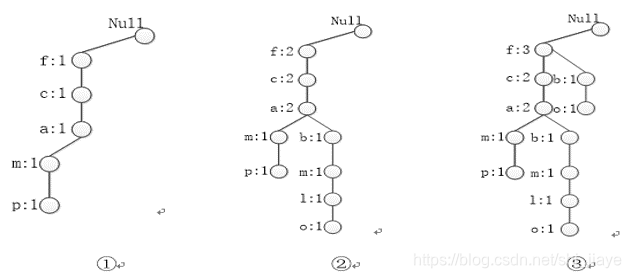
2.FP树构建过程示例
第一次扫描数据库,导出频繁项的集合(1 项集),并将频繁项按支持度计数降序排列。

根据上述生成的项集,构造FP树,如图6-4所示。
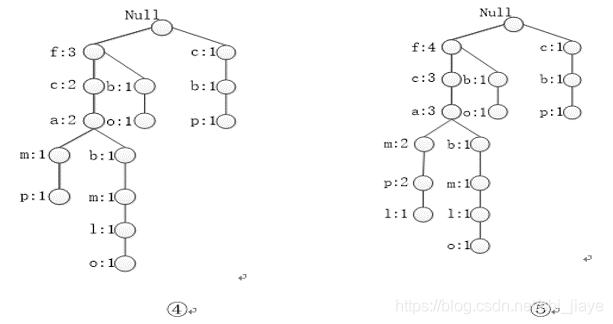
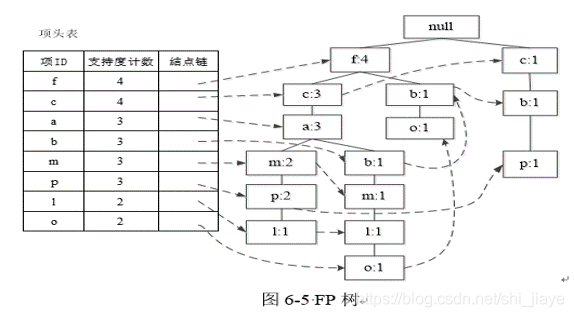
为了方便树的遍历,创建一个项头表,使每项通过一个结点链指向它在树中的位置。扫描所有的事务,得到的FP树如图6-5所示。
3.FP树挖掘
(1)从FP树到条件模式基
从项头表开始挖掘,由频率低的结点开始。在图6.5的FP树中,首先依据结点o在该路径上的支持度更新前缀路径上结点的支持度计数。在此基础上,得到o点的条件模式基{f,c,a,b,m,l:1},{f,b:1}。
构建条件FP树。利用o点的条件模式基得到o点的条件FP树。如果该条件FP树有多条路径,则继续迭代,构造条件FP树。否则,如果该FP树只有一条路径,则直接求以该结点结尾的频繁项集。
FP-growth方法将发现长频繁模式的问题转换化为在较小的条件数据库中递归地搜索一些较短模式,然后连接后缀。它使用最不频繁的项做后缀,提供了较好的选择性,显著降低了搜索开销。
当数据库很大时,构造基于主存的FP树是不现实的,一种有趣的选择是将数据库划分成投影数据库集合,然后在每个投影数据库上构造FP树并进行挖掘。
使用垂直数据格式挖掘频繁项集
Apriori算法和FP-growth算法都从TID项集格式(即{TID:itemset})的事务集中挖掘频繁模式。其中TID是事务标识符,而itemset是事务TID中购买的商品。这种数据格式称为水平数据格式(Horizontal Data Format)。
使用垂直数据格式有效地挖掘频繁项集,它是等价类变换(Equivalenc CLAss Transformation,Eclat)算法的要点。

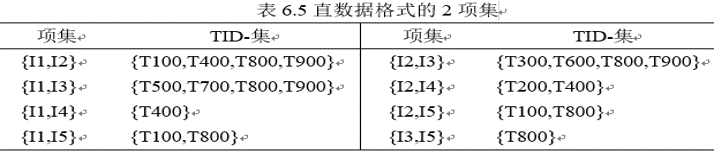

例6.3解释了通过探查垂直数据格式挖掘频繁项集的过程。首先,通过扫描一次数据集,把水平格式的数据转换成垂直格式。项集的支持度计数简单地等于项集的TID集的长度。从k=1开始,可以根据先验性质,使用频繁k项集来构造候选(k+1)项集。通过取频繁k项集的TID集的交,计算对应的(k+1)项集的TID集。重复该过程,每次k增加1,直到不能再找到频繁项集或候选项集。
















 4783
4783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











