







1.使用分组和计数函数来实现词频统计
@Test
public void test() throws IOException {
//定义要加载的文件位置
String path = "word.txt";
//通过Files.lines获取字符流对象
Stream<String> stream = Files.lines(Path.of(path));
stream = stream.flatMap(x-> Arrays.stream(x.split(" ")));
Map<String, Long> collect = stream.collect(Collectors.groupingBy(x -> x, Collectors.counting()));
System.out.println(collect);
}
其中的自定义文件内容为:

单词之间以空格进行分割。
Stream<String> stream = Files.lines(Path.of(path));
Files.lines() 接收一个 Path 对象,然后读取文件中的每一行转化为流之后赋值给 Stream 对象。
此时的 stream 内容为:[[“Java is very good”],[“python is very young”],[“C++ is very fast”]]。
stream = stream.flatMap(x-> Arrays.stream(x.split(" ")));
使用 stream.flatMap 使流数据扁平化,即在每个x中对字符串以空格进行分割然后返回流对象。运行完后 stream 的内容为:
stream.collect(Collectors.groupingBy(x -> x, Collectors.counting()));
使用 groupingBy 对单词进行分组,此时分组的就是单词的本身,分组的过程中使用下游收集器对分组后的单词进行统计个数后返回一个Map集合,key为单词,value为重复出现次数。执行完输出结果为:
2.使用分组和下游收集器来实现词频统计
@Test
public void test() throws IOException {
//定义要加载的文件位置
String path = "word.txt";
//通过Files.lines获取字符流对象
Stream<String> stream = Files.lines(Path.of(path));
stream = stream.flatMap(x-> Arrays.stream(x.split(" ")));
Map<String, Integer> collect = stream.collect(Collectors.groupingBy(x -> x, Collectors.collectingAndThen(Collectors.toList(), List::size)));
System.out.println(collect);
}
stream.collect(Collectors.groupingBy(x -> x, Collectors.collectingAndThen(Collectors.toList(), List::size)));
collectionAndThen 收集器在收集器后面添加一个最终处理步骤。把所有相同的单词放入一个List集合后,统计集合的大小,此时集合的大小就是相同单词的数量。然后返回以分组的值为key,最终计算结果为value的Map对象。
运行结果同上。
3.使用分组和自定义计数来实现词频统计
@Test
public void test() throws IOException {
//定义要加载的文件位置
String path = "word.txt";
//通过Files.lines获取字符流对象
Stream<String> stream = Files.lines(Path.of(path));
stream = stream.flatMap(x-> Arrays.stream(x.split(" ")));
Map<String, List<String>> collect = stream.collect(Collectors.groupingBy(x -> x));
collect.values().stream().map(x->{
Map<String,Integer> map = new HashMap<>();
map.put(x.get(0),x.size());
return map;
}).forEach(System.out::println);
}
Map<String, List<String>> collect = stream.collect(Collectors.groupingBy(x -> x));
首先根据单词进行分组,分组后的Map集合为:
collect.values().stream().map(x->{
Map<String,Integer> map = new HashMap<>();
map.put(x.get(0),x.size());
return map;
}).forEach(System.out::println);
此时collect,values()的值为: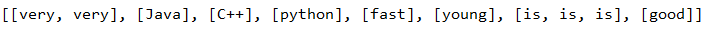
对每个值进行 map.put(x.get(0),x.size) 的计算。以第一个元素为例:此时的x=[“very”,“very”],x.get(0) = “very”, x.size() = 2; 返回的为{“very”,2}的map对象,后遍历输出,结果如上。
4.使用toMap方法实现词频统计
@Test
public void test() throws IOException {
//定义要加载的文件位置
String path = "word.txt";
//通过Files.lines获取字符流对象
Stream<String> stream = Files.lines(Path.of(path));
stream = stream.flatMap(x-> Arrays.stream(x.split(" ")));
Map<String, Integer> collect = stream.collect(Collectors.toMap(x -> x, x -> 1, (oldValue, newValue) -> oldValue + newValue));
System.out.println(collect);
}
Map<String, Integer> collect = stream.collect(Collectors.toMap(x -> x, x -> 1, (oldValue, newValue) -> oldValue + newValue));
toMap 方法的三个参数,第一个为作为 key 的对象,第二个为作为 value 的值,第三个是当 Map 中已有 key 是如何处理 oldValue 和 newValue 之间的关系。
以 “very” 为例:当遇见第一个“very”后相当于执行 put(“very”,1) 操作,当再次执行 put(“very”,1) 操作时会出现异常,此时的处理办法是执行 put(“very”, get(“very”)+1) 操作。即lambda表达式的 (oldValue, newValue) -> oldValue+newValue














 69
69











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









