







Redis学习笔记系列
- Redis学习笔记(一):下载与安装-Windows、Linux
- Redis学习笔记(二):数据类型和通用操作命令
- Redis学习笔记(三):Java连接Redis(Jedis)以及示例代码
- Redis学习笔记(四):Redis持久化
- Redis学习笔记(五):Redis事务-multi、exec、discard、锁、分布式锁、死锁
- Redis学习笔记(六):删除策略、逐出算法
- Redis学习笔记(七):redis高级数据类型及应用场景-Bitmaps、HyperLogLog、GEO
- Redis学习笔记(八):redis主从复制-建立连接、数据同步、命令传播、复制缓冲区、复制偏移量、心跳机制
- Redis学习笔记(九):哨兵模式-监控、通知、故障转移
- Redis学习笔记(十):Redis集群-结构设计、集群搭建、集群操作、主从下线、主从切换
- Redis学习笔记(十一):企业级解决方案-缓存预热、缓存雪崩、缓存击穿、缓存穿透、性能指标监控
简介
在业务发展过程中遇到峰值瓶颈,比如redis提供的服务可达10万/秒,但是当前业务已经达到20万/秒,或者业务需求内存容量已经超过单机内存…这个时候,就需要使用集群的方式快速解决上述问题
集群作用:
- 分散单台服务器的访问压力,实现负载均衡
- 分散单台服务器的存储压力,实现可扩展性
- 降低单台服务器宕机带来的业务灾难

redis集群结构设计
数据存储设计
- 通过算法设计,计算出key应该保存的位置,官方叫法:槽
- 将所有的存储空间计划切割成16384份,每台主机保存一部分,每份代表的是一个存储空间,不是一个key的保存空间
- 将key按照计算出的结果放到对应的存储空间

集群内部通讯设计 - 各个数据库相互通信,保存各个库中槽的编号数据
- 一次命中,直接返回
- 一次未命中,告知具体位置

redis集群搭建
- 需要在redis.conf中添加以下配置
cluster-enabled yes # 设置加入cluster,成为其中的节点 cluster-config-file nodes-端口号.conf # cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容 cluster-node-timeout 10000 # 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点 cluster-migration-barrier 1 # master连接的slave最小数量
范例(启动6个redis,三主三从,每个主挂一个从,端口6379-6384):
- 将上述配置文件redis.conf配置分别配置6个redis(可使用命令快捷复制:
sed "s/6379/6380/g" redis-6379.conf > redis-6380.conf),并各启动这6个redis - 查看所有Redis是否都启动成功
ps -ef | grep redis

- 将所有redis连接到一起,使用redis/src/redis-trib.rb,该文件启动的前提是系统安装了ruby和rubygems
./redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
# create:代表创建
# 1:数字,代表每个master挂多少个slave
# ip:port:cluster会根据你配置的每个master挂多少个slave,自己计算,哪些是master,哪些是slave,比如上述,一共配置了6个ip:port,那么前3个为master,后3个为slave

- 这个时候可以在redis的数据文件查看生成了6个nodes-端口号.conf的配置文件,可以通过
cat查看

- 在第3步继续输入yes

- 此时redis的集群就已经启动成功,我们可以回到第4步查看,这个时候nodes-端口号.conf发生了什么变化

这个时候,nodes-端口.conf记录了集群中所有redis的信息,包括哪个是自己,哪些是master,哪些是slave
redis设置和获取数据
- 如果还是使用以前的命令连接redis服务器
redis-cli,然后往redis里set数据,则会报错,因为这个时候计算name的槽是5798,位于6380的redis上,而你此时是在6379的redis,设置值失败

- 需要添加
-c表明这是连接到cluster的redis客户端redis-cli -c,这个时候,计算出的name的槽是5798,属于6380的redis,那么它自动会将重定向到6380的redis上

redis集群主从下线与主从切换
slave掉线
如果slave意外掉线了,那么他的master可以识别到,识别时间就是以上配置集群超时时间,这个时候,它的master会打印日志:
Connection with slave 127.0.0.1:6382 lost. # 连接的slave丢失
Marking node 715ea09a37c933e6d3a3acvd97ds5e3e951de6e7 as failing (quorum reached) # 将这个runid的节点标记为丢失
而其它master和slave节点会打印日志:注明runid到runid的失败接收信息

slave又上线恢复了
这个时候,该slave的master又把这个slave连上,并同步数据
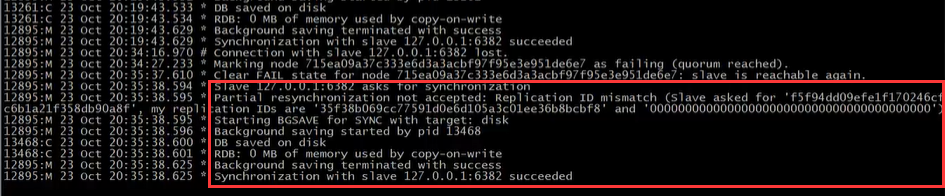
而其它master和slave会标注清除该节点失败记录,恢复连接

master 掉线
如果master意外掉线,那么连接它的slave会识别到,并不断去重连master,每1秒连接一次,一共连接多少次,这个要看配置集群的超时时间,超时了还没连上master,那么自己谋朝篡位,自己当master

可以通过命令 cluster nodes查看节点情况,这个时候,可以发现,原来的master已经标记失败,自己变成了master

master又上线恢复了
当master又恢复上线,这个时候,它就只能当slave了,而它的master就是之前自己的那个slave,并开始同步数据

cluster节点操作命令
- 查看集群节点信息
cluster nodes
- 进入一个从节点redis,切换其主节点
cluster replicate <master-ip>
- 发现一个新节点,新增主节点
cluster meet ip:port
- 忽略一个没有solt的节点
cluster forget <id>
- 手动故障转移
cluster failover
- 捐赠 -
如果觉得还不错,请我喝杯水吧 ^ _ ^ 您的鼓励是我不断前进的动力,如果有错误的地方,欢迎提出批评改正意见,戳我,感谢您的支持
| 支付宝 | 微信 |
|---|---|
 |  |















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









