







历经两个月的时间,终于看完了王争的《设计模式之美》。
这本书还是很值得一读的,作者对设计理念、设计模式思考的比较深,而且将这些思想运用到实际的工作中,使设计模式显得不那么空;另外这本书花了很大的篇幅来讲设计的理念,讲的比较通透,这是很难得,因为无论哪种设计模式,最终都会映射回理念,设计理念才是根本性的东西。
通过阅读设计模式相关的书籍,现在已经完成了5篇文章:
后面也会进入设计模式文章的书写,这么做虽然导致学习进度慢了,但是能够将这些知识掌握的更加扎实,那就是值得的。
下面是做的读书笔记,大家有兴趣可以看一下,如果觉得合适,可以去极客时间购买全本。
读书笔记
-
开篇词
- 只会写能用的代码,我们永远成长不成大牛,成长不成最优秀的那批人
- 写好的代码是为未来节省时间
-
为什么说每个程序员都要尽早地学习并掌握设计模式相关知识
- 应对面试中的设计模式相关问题;
- 告别写被人吐槽的烂代码;
- 提高复杂代码的设计和开发能力;
- 让读源码、学框架事半功倍;
- 为你的职场发展做铺垫
-
从哪些维度评判代码质量的好坏?如何具备写出高质量代码的能力?
- 可维护性:所谓“代码易维护”就是指,在不破坏原有代码设计、不引入新的bug的情况下,能够快速地修改或者添加代码。
- 可读性:需要看代码是否符合编码规范、命名是否达意、注释是否详尽、函数是否长短合适、模块划分是否清晰、是否符合高内聚低耦合等等
- 可扩展性:代码的可扩展性表示,我们在不修改或少量修改原有代码的情况下,通过扩展的方式添加新的功能代码。
- 灵活性:如果一段代码易扩展、易复用或者易用,我们都可以称这段代码写得比较灵活。所以,灵活这个词的含义非常宽泛,很多场景下都可以使用
- 简洁性:代码简单、逻辑清晰,也就意味着易读、易维护
- 可复用性:尽量减少重复代码的编写,复用已有的代码
- 可测试性:代码的可测试性差,比较难写单元测试,那基本上就能说明代码设计得有问题
-
面向对象、设计原则、设计模式、编程规范、重构,这五者有何关系?
-
理论一:当谈论面向对象的时候,我们到底在谈论什么?
- 面向对象编程是一种编程范式或编程风格。它以类或对象作为组织代码的基本单元,并将封装、抽象、继承、多态四个特性,作为代码设计和实现的基石。
- 面向对象编程语言是支持类或对象的语法机制,并有现成的语法机制,能方便地实现面向对象编程四大特性(封装、抽象、继承、多态)的编程语言。
-
理论二:封装、抽象、继承、多态分别可以解决哪些编程问题?
- 封装:也叫作信息隐藏或者数据访问保护。类通过暴露有限的访问接口,授权外部仅能通过类提供的方式(或者叫函数)来访问内部信息或者数据。
- 抽象:人类处理复杂性的有效手段
- 继承:继承最大的一个好处就是代码复用,用来表示类之间的is-a关系
- 多态:提高代码的扩展性和复用性
-
理论三:面向对象相比面向过程有哪些优势?面向过程真的过时了吗?
- 面向对象编程比起面向过程编程,更能应对这种复杂类型的程序开发;面向对象编程相比面向过程编程,具有更加丰富的特性(封装、抽象、继承、多态),利用这些特性编写出来的代码,更加易扩展、易复用、易维护;
-
理论四:哪些代码设计看似是面向对象,实际是面向过程的?
面向过程编程风格符合人的流程化思维方式;而面向对象编程风格正好相反,是一种自底向上的思考方式。
- 滥用getter、setter方法
- Constants类、Utils类的设计问题
- 基于贫血模型的开发模式
-
理论五:接口vs抽象类的区别?如何用普通的类模拟抽象类和接口?
- 抽象类实际上就是类,只不过是一种特殊的类,这种类不能被实例化为对象,只能被子类继承。我们知道,继承关系是一种is-a的关系,那抽象类既然属于类,也表示一种is-a的关系。相对于抽象类的is-a关系来说,接口表示一种has-a关系,表示具有某些功能。对于接口,有一个更加形象的叫法,那就是协议(contract)。
- 抽象类更多的是为了代码复用,抽象类能够优雅的保证多态特性
- 接口就更侧重于解耦
- 如果我们要表示一种is-a的关系,并且是为了解决代码复用的问题,我们就用抽象类;如果我们要表示一种has-a关系,并且是为了解决抽象而非代码复用的问题,那我们就可以使用接口。
-
理论六:为什么基于接口而非实现编程?有必要为每个类都定义接口吗?
- 基于接口而非实现编程”这条原则的另一个表述方式,是“基于抽象而非实现编程”。
- 越抽象、越顶层、越脱离具体某一实现的设计,越能提高代码的灵活性,越能应对未来的需求变化。好的代码设计,不仅能应对当下的需求,而且在将来需求发生变化的时候,仍然能够在不破坏原有代码设计的情况下灵活应对。
-
理论七:为何说要多用组合少用继承?如何决定该用组合还是继承?
-
继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性
-
继承主要有三个作用:表示is-a关系,支持多态特性,代码复用。而这三个作用都可以通过组合、接口、委托三个技术手段来达成。除此之外,利用组合还能解决层次过深、过复杂的继承关系影响代码可维护性的问题。
-
-
实战一(上):业务开发常用的基于贫血模型的MVC架构违背OOP吗?
- 只包含数据,不包含业务逻辑的类,就叫作贫血模型
- 数据和对应的业务逻辑被封装到同一个类中,叫充血模型
- 基于贫血模型的传统的开发模式,重Service轻BO;基于充血模型的DDD开发模式,轻Service重Domain
-
实战一(下):如何利用基于充血模型的DDD开发一个虚拟钱包系统?
- 对于支付这样的类似转账的操作,我们在操作两个钱包账户余额之前,先记录交易流水,并且标记为“待执行”,当两个钱包的加减金额都完成之后,我们再回过头来,将交易流水标记为“成功”。在给两个钱包加减金额的过程中,如果有任意一个操作失败,我们就将交易记录的状态标记为“失败”。我们通过后台补漏Job,拉取状态为“失败”或者长时间处于“待执行”状态的交易记录,重新执行或者人工介入处理。
-
实战二(上):如何对接口鉴权这样一个功能开发做面向对象分析?
- 面向对象分析(OOA)、面向对象设计(OOD)、面向对象编程(OOP),是面向对象开发的三个主要环节
-
实战二(下):如何利用面向对象设计和编程开发接口鉴权功能?
- 面向对象分析的产出是详细的需求描述
- 面向对象设计的产出是类
- 划分职责进而识别出有哪些类:罗列名词或者功能点
- 定义类及其属性和方法:我们识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选出真正的方法,把功能点中涉及的名词,作为候选属性,然后同样再进行过滤筛选。
- 定义类与类之间的交互关系:泛化、实现、关联、聚合、组合、依赖,只保留了四个关系:泛化、实现、组合、依赖
- 将类组装起来并提供执行入口
-
理论一:对于单一职责原则,如何判定某个类的职责是否够单一?
- 单一职责原则:一个类只负责完成一个职责或者功能。不要设计大而全的类,要设计粒度小、功能单一的
类。单一职责原则是为了实现代码高内聚、低耦合,提高代码的复用性、可读性、可维护性 - 实际上,在真正的软件开发中,我们也没必要过于未雨绸缪,过度设计。所以,我们可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构。一些常用判断指标:
- 类中的代码行数、函数或者属性过多;
- 类依赖的其他类过多,或者依赖类的其他类过多;
- 私有方法过多;
- 比较难给类起一个合适的名字;
- 类中大量的方法都是集中操作类中的某几个属性。
- 单一职责原则:一个类只负责完成一个职责或者功能。不要设计大而全的类,要设计粒度小、功能单一的
-
理论二:如何做到对扩展开放、修改关闭?扩展和修改各指什么?
- 开闭原则:添加一个新的功能,应该是通过在已有代码基础上扩展代码(新增模块、类、方法、属性等),而非修改已有代码(修改模块、类、方法、属性等)的方式来完成。关于定义,我们有两点要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价来完成新功能的开发。第二点是,同样的代码改动,在粗代码粒度下,可能被认定为“修改”;在细代码粒度下,可能又被认定为“扩展”。
- 最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式
-
理论三:里式替换(LSP)跟多态有何区别?哪些代码违背了LSP?
- 里氏替换原则:子类对象能够替换程序(program)中父类对象出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
- 多态与里氏替换原则的区别:多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种设计原则,是用来指导继承关系中子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
-
理论四:接口隔离原则有哪三种应用?原则中的接口该如何理解?
- 接口隔离原则:客户端不应该强迫依赖它不需要的接口
- 接口隔离原则与单一职责原则的区别:单一职责原则针对的是模块、类、接口的设计。接口隔离原则提供了一种判断接口的职责是否单一的标准:通过调用者如何使用接口来间接地判定。
-
理论五:控制反转、依赖反转、依赖注入,这三者有何区别和联系?
- 控制反转(IOC):框架提供了一个可扩展的代码骨架,用来组装对象、管理整个执行流程。程序员利用框架进行开发的时候,只需要往预留的扩展点上,添加跟自己业务相关的代码,就可以利用框架来驱动整个程序流程的执行。这里的“控制”指的是对程序执行流程的控制,而“反转”指的是在没有使用框架之前,程
序员自己控制整个程序的执行。在使用框架之后,整个程序的执行流程可以通过框架来控制。流程的控制权从程序员“反转”到了框架。 - 依赖注入(DI):不通过new()的方式在类内部创建依赖类对象,而是将依赖的类对象在外部创建好之后,通过构造函数、函数参数等方式传递(或注入)给类使用。
- 通过依赖注入的方式来将依赖的类对象传递进来,这样就提高了代码的扩展性,我们可以灵活地替换依赖的类
- 依赖反转原则(DIP):高层模块不要依赖低层模块。高层模块和低层模块应该通过抽象(abstractions)来互相依赖。除此之外,抽象(abstractions)不要依赖具体实现细节(details),具体实现细节(details)依赖抽象(abstractions)。
- 控制反转(IOC):框架提供了一个可扩展的代码骨架,用来组装对象、管理整个执行流程。程序员利用框架进行开发的时候,只需要往预留的扩展点上,添加跟自己业务相关的代码,就可以利用框架来驱动整个程序流程的执行。这里的“控制”指的是对程序执行流程的控制,而“反转”指的是在没有使用框架之前,程
-
理论六:我为何说KISS、YAGNI原则看似简单,却经常被用错?
- KISS原则:尽量保持简单
- 不要使用同事可能不懂的技术来实现代码
- 不要重复造轮子,要善于使用已经有的工具类库
- 不要过度优化
- YAGNI原则:你不会需要它
- 要去设计当前用不到的功能
- 不要去编写当前用不到的代码
- 不要做过度设计
- KISS原则:尽量保持简单
-
理论七:重复的代码就一定违背DRY吗?如何提高代码的复用性?
-
DRY原则:Don’t-Repeat-Yourself,不要写重复的代码
-
三种典型的代码重复情况:实现逻辑重复、功能语义重复和代码执行重复
-
代码的实现逻辑是相同的,但语义不同,我们判定它并不违反DRY原则
-
代码的实现逻辑不重复,但语义重复,也就是功能重复,我们认为它违反了DRY原则
-
代码中存在“执行重复”,违反了DRY原则
-
-
提高代码复用性方法
- 减少代码耦合
- 满足单一职责原则
- 模块化
- 业务与非业务逻辑分离
- 通用代码下沉
- 继承、多态、抽象、封装
- 应用模板等设计模式
-
RuleofThree:第一次编写代码的时候,我们不考虑复用性;第二次遇到复用场景的时候,再进行重构使其复用
-
-
理论八:如何用迪米特法则(LOD)实现高内聚、松耦合?
- 高内聚低耦合
- 高内聚:就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中
- 松耦合:在代码中,类与类之间的依赖关系简单清晰
- 迪米特法则:不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口
- 高内聚低耦合
-
实战一(上):针对业务系统的开发,如何做需求分析和设计?
- 面向对象设计聚焦在代码层面(主要是针对类),那系统设计就是聚焦在架构层面(主要是针对模块),两者有很多相似之处。
-
实战一(下):如何实现一个遵从设计原则的积分兑换系统?
- 业务开发包括哪些操作:接口设计、数据库设计和业务模型设计(也就是业务逻辑)
- 为什么要分MVC三层开发
- 分层能起到代码复用的作用
- 分层能起到隔离变化的作用
- 分层能起到隔离关注点的作用
- 分层能提高代码的可测试性
- 分层能应对系统的复杂性
-
实战二(上):针对非业务的通用框架开发,如何做需求分析和设计?
- 软件设计开发是一个迭代的过程,分析、设计和实现这三个阶段的界限划分并不明显
- 框架非功能性需求:框架的易用性、性能、扩展性、容错性、通用性等
- 复杂框架设计技巧:画产品线框图、聚焦简单应用场景、设计实现最小原型、画系统设计图等
- 不管做任何事情,如果我们总是等到所有的东西都想好了再开始,那这件事情可能永远都开始不了。有句老话讲:万事开头难,所以,先迈出第一步很重要
-
实战二(下):如何实现一个支持各种统计规则的性能计数器?
- 面向对象设计和实现要做的事情,就是把合适的代码放到合适的类中
- 选择哪种划分方法,判定的标准是让代码尽量地满足低耦合、高内聚、单一职责、对扩展开放对修改关闭等之前讲的各种设计原则和思想,尽量地做到代码可复用、易读、易扩展、易维护
-
理论一:什么情况下要重构?到底重构什么?又该如何重构?
- 定义:重构是一种对软件内部结构的改善,目的是在不改变软件的可见行为的情况下,使其更易理解,修改成本更低。
- 初级工程师在维护代码,高级工程师在设计代码,资深工程师在重构代码
- 重构大致分为大规模高层次的重构和小规模低层次的重构
-
理论二:为了保证重构不出错,有哪些非常能落地的技术手段?
- 最可落地执行、最有效的保证重构不出错的手段应该就是单元测试
- 为什么要写单元测试
- 单元测试能有效地帮你发现代码中的bug
- 写单元测试能帮你发现代码设计上的问题
- 单元测试是对集成测试的有力补充
- 写单元测试的过程本身就是代码重构的过程
- 阅读单元测试能帮助你快速熟悉代码
- 单元测试是TDD可落地执行的改进方案
-
理论三:什么是代码的可测试性?如何写出可测试性好的代码?
- 通过编写测试用例,反向优化代码设计。可测试性差的代码,本身代码设计得也不够好,很多地方都没有遵守我们之前讲到的设计原则和思想,比如“基于接口而非实现编程”思想、依赖反转原则等。重构之后的代码,不仅可测试性更好,而且从代码设计的角度来说,也遵从了经典的设计原则和思想。
- 主要通过mock、二次封装等方式解依赖外部服务。
- 代码可测性:所谓代码的可测试性,就是针对代码编写单元测试的难易程度。对于一段代码,如果很难为其编写单元测试,或者单元测试写起来很费劲,需要依靠单元测试框架中很高级的特性,那往往就意味着代码设计得不够合理,代码的可测试性不好。
- 编写可测试性代码的最有效手段:依赖注入是编写可测试性代码的最有效手段。通过依赖注入,我们在编写单元测试的时候,可以通过mock的方法解依赖外部服务,这也是我们在编写单元测试的过程中最有技术挑战的地方。
- 常见的Anti-Patterns:代码中包含未决行为逻辑,滥用可变全局变量,滥用静态方法,使用复杂的继承关系,高度耦合的代码
- 确实是太耗时了
-
理论四:如何通过封装、抽象、模块化、中间层等解耦代码?
- 解耦保证代码松耦合、高内聚,是控制代码复杂度的有效手段。
- 衡量标准:把模块与模块、类与类之间的依赖关系画出来,根据依赖关系图的复杂性来判断是否需要解耦重构。
- 解耦方法:封装与抽象、中间层、模块化、设计思想与原则
-
理论五:让你最快速地改善代码质量的20条编程规范(上)
- 命名:命名的关键是能准确达意,要可读可思考
- 注释:注释的目的就是让代码更容易看懂,主要包含三个方面,做什么、为什么、怎么做
-
理论五:让你最快速地改善代码质量的20条编程规范(中)
- 函数、类多大合适:不超过一屏
- 一行代码多长合适:不超过IDE显示的宽度
- 善用空行分割单元块
-
理论五:让你最快速地改善代码质量的20条编程规范(下)
- 将复杂的逻辑提炼拆分成函数和类
- 通过拆分成多个函数或将参数封装为对象的方式,来处理参数过多的情况
- 函数中不要使用参数来做代码执行逻辑的控制
- 函数设计要职责单一
- 移除过深的嵌套层次,方法包括:去掉多余的if或else语句,使用continue、break、return关键字提前退出嵌套,调整执行顺序来减少嵌套,将部分嵌套逻辑抽象成函数。
- 用字面常量取代魔法数。
- 用解释性变量来解释复杂表达式,以此提高代码可读性。
-
实战一(上):通过一段ID生成器代码,学习如何发现代码质量问题
-
实战一(下):手把手带你将ID生成器代码从能用重构为好用”
- 根据checklist来进行优化
- 第一轮重构:提高代码的可读性
- 第二轮重构:提高代码的可测试性
- 第三轮重构:编写完善的单元测试
- 第四轮重构:所有重构完成之后添加注释
-
实战二(上):程序出错该返回啥?NULL、异常、错误码、空对象?
- 函数出错返回数据类型,有4种情况,它们分别是:错误码、NULL值、空对象、异常对象
-
实战二(下):重构ID生成器项目中各函数的异常处理代码
- 作为一名程序员,起码对代码要有追求啊,不然跟咸鱼有啥区别!
-
总结回顾面向对象、设计原则、编程规范、重构技巧等知识点
- 很好的总结,强烈建议一看
-
运用学过的设计原则和思想完善之前讲的性能计数器项目(上)
- 好的设计一定是结构清晰、有条理、逻辑性强,看起来一目了然,读完之后常常有一种原来如此的感觉。差的设计往往逻辑、代码乱塞一通,没有什么设计思路可言,看起来莫名其妙,读完之后一头雾水
-
运用学过的设计原则和思想完善之前讲的性能计数器项目(下)
- 学会这个逐步优化的方法,以及其中涉及的一些编程技巧、设计思路,能够举一反三地用在其他项目中
-
单例模式(上):为什么说支持懒加载的双重检测不比饿汉式更优?
-
单例设计模式(SingletonDesignPattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
-
单例用处:从业务概念上,有些数据在系统中只应该保存一份,就比较适合设计为单例类。比如,系统的配置信息类。除此之外,我们还可以使用单例解决资源访问冲突的问题。
-
实现单例模式关注点:
- 构造函数需要是private访问权限的,这样才能避免外部通过new创建实例;
- 考虑对象创建时的线程安全问题;
- 考虑是否支持延迟加载;
- 考虑getInstance()性能是否高(是否加锁)。
-
单例实现方式:
-
饿汉式的实现方式是:在类加载的时候,instance静态实例就已经创建并初始化好了,所以,instance实例的创建过程是线程安全的
-
懒汉式相对于饿汉式的优势是支持延迟加载。这种方法需要关注线程安全。
-
双重检测
-
静态内部类
-
枚举
-
-
-
单例模式(中):我为什么不推荐使用单例模式?又有何替代方案?
- 单例对OOP特性的支持不友好
- 单例会隐藏类之间的依赖关系
- 单例对代码的扩展性不友好
- 单例对代码的可测试性不友好
- 单例不支持有参数的构造函数
- 替代方案有:静态方法、工厂模式、IOC容器、程序员自己保证等
-
单例模式(下):如何设计实现一个集群环境下的分布式单例模式?
- 一个类只允许创建唯一一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。唯一的范围指的是进程内。
- 线程唯一一般通过hashmap来实现
- 集群相当于多个进程构成的一个集合,“集群唯一”就相当于是进程内唯一、进程间也唯一。也就是说,不同的进程间共享同一个对象,不能创建同一个类的多个对象。可以将单例对象序列化并存储到外部共享存储区,获取的时候加锁,用完释放锁。
- “多例”指的就是,一个类可以创建多个对象,但是个数是有限制的,比如只能创建3个对象。在单例类用HashMap存储多个对象,getInstance的时候通过传值选择使用哪个对象。
-
工厂模式(上):我为什么说没事不要随便用工厂模式创建对象?
- 当每个对象的创建逻辑都比较简单的时候,我推荐使用简单工厂模式,将多个对象的创建逻辑放到一个工厂类中
- 当创建逻辑比较复杂,是一个“大工程”的时候,我们就考虑使用工厂模式,封装对象的创建过程,将对象的创建和使用相分离
-
工厂模式(下):如何设计实现一个Dependency-Injection框架?
- DI容器相当于一个大的工厂类,负责在程序启动的时候,根据配置(要创建哪些类对象,每个类对象的创建需要依赖哪些其他类对象)事先创建好对象。当应用程序需要使用某个类对象的时候,直接从容器中获取即可。正是因为它持有一堆对象,所以这个框架才被称为“容器”。
- DI容器的核心功能一般有三个:配置解析、对象创建和对象生命周期管理
- DI容器的实现原理,其核心逻辑主要包括:配置文件解析,以及根据配置文件通过“反射”语法来创建对象
-
建造者模式:详解构造函数、set方法、建造者模式三种对象创建方式
- 工厂模式是用来创建不同但是相关类型的对象(继承同一父类或者接口的一组子类),由给定的参数来决定创建哪种类型的对象。建造者模式是用来创建一种类型的复杂对象,通过设置不同的可选参数,“定制化”地创建不同的对象。
- 创建对象使用建设者模式的原因
- 我们把类的必填属性放到构造函数中,强制创建对象的时候就设置。用通过set()方法设置,那校验这些必填属性是否已经填写的逻辑就无处安放了
- 类的属性之间有一定的依赖关系或者约束条件
- 希望创建不可变对象
-
原型模式:如何最快速地clone一个HashMap散列表?
- 如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式,来创建新对象,以达到节省创建时间的目的。这种基于原型来创建对象的方式就叫作原型设计模式,简称原型模式。
- 原型模式有两种实现方法,深拷贝和浅拷贝。
-
代理模式:代理在RPC、缓存、监控等场景中的应用
- 代理模式(Proxy Design Pattern)在不改变原始类(或叫被代理类)代码的情况下,通过引入代理类来给原始类附加功能。可以让代理类和原始类实现相同接口或者使用继承。
- 所谓动态代理(Dynamic Proxy),就是我们不事先为每个原始类编写代理类,而是在运行的时候,动态地创建原始类对应的代理类,然后在系统中用代理类替换掉原始类。
- 代理模式常用在业务系统中开发一些非功能性需求,比如:监控、统计、鉴权、限流、事务、幂等、日志。我们将这些附加功能与业务功能解耦,放到代理类统一处理,让程序员只需要关注业务方面的开发。除此之外,代理模式还可以用在RPC、缓存等应用场景中。
-
桥接模式:如何实现支持不同类型和渠道的消息推送系统?
- 桥接模式应用场景比较局限,在实际的项目中并没有那么常用
- 桥接模式是这么定义的:“将抽象和实现解耦,让它们可以独立变化。
-
装饰器模式:通过剖析Java-IO类库源码学习装饰器模式
- 装饰器模式主要解决继承关系过于复杂的问题,通过组合来替代继承。它主要的作用是给原始类添加增强功能。
- 第一个比较特殊的地方是:装饰器类和原始类继承同样的父类,这样我们可以对原始类“嵌套”多个装饰器类。
- 第二个比较特殊的地方是:装饰器类是对功能的增强,这也是装饰器模式应用场景的一个重要特点。
- 代理模式中,代理类附加的是跟原始类无关的功能,而在装饰器模式中,装饰器类附加的是跟原始类相关的增强功能。
-
适配器模式:代理、适配器、桥接、装饰,这四个模式有何区别?
- 两种实现方式:类适配器和对象适配器,类适配器使用继承关系来实现,对象适配器使用组合关系来实现
- 实际的开发中,到底该如何选择使用哪一种呢?判断的标准主要有两个,一个是 Adaptee 接口的个数,另一个是 Adaptee 和 ITarget 的契合程度。
- 使用场景
- 封装有缺陷的接口设计
- 统一多个类的接口设计
- 替换依赖的外部系统
- 兼容老版本接口
- 适配不同格式的数据
- **代理模式:**代理模式在不改变原始类接口的条件下,为原始类定义一个代理类,主要目的是控制访问,而非加强功能,这是它跟装饰器模式最大的不同。
- **桥接模式:**桥接模式的目的是将接口部分和实现部分分离,从而让它们可以较为容易、也相对独立地加以改变。
- **装饰器模式:**装饰者模式在不改变原始类接口的情况下,对原始类功能进行增强,并且支持多个装饰器的嵌套使用。
- **适配器模式:**适配器模式是一种事后的补救策略。适配器提供跟原始类不同的接口,而代理模式、装饰器模式提供的都是跟原始类相同的接口。
-
门面模式:如何设计合理的接口粒度以兼顾接口的易用性和通用性?
- 门面模式,也叫外观模式,门面模式为子系统提供一组统一的接口,定义一组高层接口让子系统更易用。
- 接口设计的好坏,直接影响到类、模块、系统是否好用。所以,我们要多花点心思在接口设计上。我经常说,完成接口设计,就相当于完成了一半的开发任务。只要接口设计得好,那代码就差不到哪里去。
- 门面模式可以解决易用性、解决性能问题、解决分布式事务问题
-
组合模式:如何设计实现支持递归遍历的文件系统目录树结构?
- 应用场景特殊,数据必须能表示成树形结构
- 组合模式:将一组对象组织(Compose)成树形结构,以表示一种“部分 - 整体”的层次结构。组合让客户端可以统一单个对象和组合对象的处理逻辑。
- 将一组对象(文件和目录)组织成树形结构,以表示一种‘部分 - 整体’的层次结构(目录与子目录的嵌套结构)。组合模式让客户端可以统一单个对象(文件)和组合对象(目录)的处理逻辑(递归遍历)。
-
享元模式(上):如何利用享元模式优化文本编辑器的内存占用?
- 享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
- 定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。
- 代码结构:它的代码实现非常简单,主要是通过工厂模式,在工厂类中,通过一个 Map 来缓存已经创建过的享元对象,来达到复用的目的。
- 应用单例模式是为了保证对象全局唯一。应用享元模式是为了实现对象复用,节省内存。缓存是为了提高访问效率,而非复用。池化技术中的“复用”理解为“重复使用”,主要是为了节省时间。
-
享元模式(下):剖析享元模式在Java-Integer、String中的应用
- 在 Java Integer 的实现中,-128 到 127 之间的整型对象会被事先创建好,缓存在IntegerCache 类中。
- 在 Java String 类的实现中,JVM 开辟一块存储区专门存储字符串常量,这块存储区叫作字符串常量池,类似于 Integer 中的 IntegerCache。
-
观察者模式(上):详解各种应用场景下观察者模式的不同实现方式
-
创建型设计模式主要解决“对象的创建”问题,结构型设计模式主要解决“类或对象的组合或组装”问题,那
行为型设计模式主要解决的就是“类或对象之间的交互”问题
-
定义:在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知
-
一般情况下,被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者(Observer)
-
设计模式要干的事情就是解耦。创建型模式是将创建和使用代码解耦,结构型模式是将不同功能代码解耦,行为型模式是将不同的行为代码解耦,具体到观察者模式,它是将观察者和被观察者代码解耦
-
-
观察者模式(下):如何实现一个异步非阻塞的EventBus框架?
- 同步阻塞是最经典的实现方式,主要是为了代码解耦;异步非阻塞除了能实现代码解耦之外,还能提高代码的执行效率;进程间的观察者模式解耦更加彻底,一般是基于消息队列来实现,用来实现不同进程间的被观察者和观察者之间的交互。
- 框架的作用有:隐藏实现细节,降低开发难度,做到代码复用,解耦业务与非业务代码,让程序员聚焦业务开发。
- EventBus 翻译为“事件总线”
- 当调用 register() 函数注册观察者的时候,EventBus 通过解析@Subscribe 注解,生成 Observer 注册表。当调用 post() 函数发送消息的时候,EventBus 通过注册表找到相应的可接收消息的函数,然后通过 Java 的反射语法来动态地创建对象、执行函数。对于同步阻塞模式,EventBus 在一个线程内依次执行相应的函数。对于异步非阻塞模式,EventBus 通过一个线程池来执行相应的函数。
- 很多人觉得做业务开发没有技术挑战,实际上,做业务开发也会涉及很多非业务功能的开发,比如今天讲到的 EventBus。在平时的业务开发中,我们要善于抽象这些非业务的、可复用的功能,并积极地把它们实现成通用的框架。
-
模板模式(上):剖析模板模式在JDK、Servlet、JUnit等中的应用
- 模板模式主要是用来解决复用和扩展两个问题。其中,复用指的是,所有的子类可以复用父类中提供的模板方法的代码。扩展指的是,框架通过模板模式提供功能扩展点,让框架用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能。
- 模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。
-
模板模式(下):模板模式与Callback回调函数有何区别和联系?
-
从应用场景上来看,同步回调跟模板模式几乎一致。它们都是在一个大的算法骨架中,自由替换其中由某个步骤,起到代码复用和扩展的目的。而异步回调跟模板模式有较大差别,更像是观察者模式。
-
从代码实现上来看,回调和模板模式完全不同。回调基于组合关系来实现,把一个对象传递给另一个对象,是一种对象之间的关系;模板模式基于继承关系来实现,子类重写父类的抽象方法,是一种类之间的关系。
-
-
策略模式(上):如何避免冗长的if-else/switch分支判断代码?
- 定义:定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)
- 策略模式:解耦策略的定义、创建、使用
-
策略模式(下):如何实现一个支持给不同大小文件排序的小程序?
- 策略模式主要的作用还是解耦策略的定义、创建和使用,控制代码的复杂度,让每个部分都不至于过于复杂、代码量过多。除此之外,对于复杂代码来说,策略模式还能让其满足开闭原则,添加新策略的时候,最小化、集中化代码改动,减少引入 bug 的风险。
-
职责链模式(上):如何实现可灵活扩展算法的敏感信息过滤框架?
- 将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
- 职责链模式有两种常用的实现。一种是使用链表来存储处理器,另一种是使用数组来存储处理器,后面一种实现方式更加简单。
-
职责链模式(下):框架中常用的过滤器、拦截器是如何实现的?
- 职责链模式常用在框架开发中,用来实现框架的过滤器、拦截器功能,让框架的使用者在不需要修改框架源码的情况下,添加新的过滤拦截功能。这也体现了之前讲到的对扩展开放、对修改关闭的设计原则。
-
状态模式:游戏、工作流引擎中常用的状态机是如何实现的?
-
有限状态机,英文翻译是 Finite State Machine,缩写为 FSM,简称为状态机。状态机有3 个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转移条件(Transition-Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
-
状态模式通过将事件触发的状态转移和动作执行,拆分到不同的状态类中,来避免分支判断逻辑。
-
状态机三种实现方式:
-
第一种实现方式叫分支逻辑法。利用 if-else 或者 switch-case 分支逻辑,参照状态转移图,将每一个状态转移原模原样地直译成代码。对于简单的状态机来说,这种实现方式最简单、最直接,是首选。
-
第二种实现方式叫查表法。对于状态很多、状态转移比较复杂的状态机来说,查表法比较合适。通过二维数组来表示状态转移图,能极大地提高代码的可读性和可维护性。
-
第三种实现方式叫状态模式。对于状态并不多、状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能比较复杂的状态机来说,我们首选这种实现方式。
-
-
-
迭代器模式(上):相比直接遍历集合数据,使用迭代器有哪些优势?
-
迭代器中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。待遍历的容器对象通过依赖注入传递到迭代器类中。容器通过 iterator() 方法来创建迭代器。
-
迭代器的三个优势
-
迭代器模式封装集合内部的复杂数据结构,开发者不需要了解如何遍历,直接使用容器提供的迭代器即可;
-
迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一;
-
迭代器模式让添加新的遍历算法更加容易,更符合开闭原则。除此之外,因为迭代器都实现自相同的接口,在开发中,基于接口而非实现编程,替换迭代器也变得更加容易。
-
-
-
迭代器模式(中):遍历集合的同时,为什么不能增删集合元素?
- 迭代器模式主要作用是解耦容器代码和遍历代码
- 一种是遍历的时候不允许增删元素,另一种是增删元素之后让遍历报错。第一种解决方案比较难实现,因为很难确定迭代器使用结束的时间点。第二种解决方案更加合理。Java 语言就是采用的这种解决方案。增删元素之后,我们选择 fail-fast 解决方式,让遍历操作直接抛出运行时异常。
-
迭代器模式(下):如何设计实现一个支持快照功能的iterator?
-
容器既支持快照遍历:在容器中,为每个元素保存两个时间戳,一个是添加时间戳 addTimestamp,一个是删除时间戳 delTimestamp,每个迭代器也保存一个迭代器创建时间戳 snapshotTimestamp
-
让容器既支持快照遍历,又支持随机访问:可以在 ArrayList 中存储两个数组。一个支持标记删除的,用来实现快照遍历功能;一个不支持标记删除的(也就是将要删除的数据直接从数组中移除),用来支持随机访问
-
-
访问者模式(上):手把手带你还原访问者模式诞生的思维过程
- 大部分设计模式的原理和实现都很简单
- 定义:允许一个或者多个操作应用到一组对象上,解耦操作和对象本身
- 一般来说,访问者模式针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下, 我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile)不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类(Extractor、Compressor)中。
-
访问者模式(下):为什么支持双分派的语言不需要访问者模式?
- 访问者模式:这个模式的代码实现比较难,所以应用场景并不多
- 所谓 Single Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的编译时类型来决定。所谓 Double Dispatch,指的是执行哪个对象的方法,根据对象的运行时类型来决定;执行对象的哪个方法,根据方法参数的运行时类型来决定。
- 之所以称为“Double”,是因为执行哪个对象的哪个方法,跟“对象”和“方法参数”两者的运行时类型有关。
- 访问者模式是用 Single Dispatch 来模拟 DoubleDispatch 的实现
-
备忘录模式:对于大对象的备份和恢复,如何优化内存和时间的消耗?
- 备忘录模式的应用场景也比较明确和有限,主要是用来防丢失、撤销、恢复等。
- 定义:在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。
- 对于大对象的备份来说,备份占用的存储空间会比较大,备份和恢复的耗时会比较长。针对这个问题,不同的业务场景有不同的处理方式。比如,只备份必要的恢复信息,结合最新的数据来恢复;再比如,全量备份和增量备份相结合,低频全量备份,高频增量备份,两者结合来做恢复。
-
命令模式:如何利用命令模式实现一个手游后端架构?
- 命令模式、解释器模式、中介模式。这 3 个模式使用频率低、理解难度大,只在非常特定的应用场景下才会用到
- 定义:命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等(附加控制)功能。
- 命令模式用的最核心的实现手段,是将函数封装成对象
- 客户端发送给服务器的请求,一般都包括两部分内容:指令和数据。其中,指令我们也可以叫作事件,数据是执行这个指令所需的数据。
- 每个设计模式都应该由两部分组成:第一部分是应用场景,即这个模式可以解决哪类问题;第二部分是解决方案,即这个模式的设计思路和具体的代码实现。我们更应该关注的是应用场景。
-
解释器模式:如何设计实现一个自定义接口告警规则功能?
- 解释器模式更加小众,只在一些特定的领域会被用到,比如编译器、规则引擎、正则表达式。
- 定义:解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。
- 它的代码实现的核心思想,就是将语法解析的工作拆分到各个小类中,以此来避免大而全的解析类。一般的做法是,将语法规则拆分成一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
-
中介模式:什么时候用中介模式?什么时候用观察者模式?
- 中介模式的设计思想跟中间层很像,通过引入中介这个中间层,将一组对象之间的交互关系(或者依赖关系)从多对多(网状关系)转换为一对多(星状关系)。
- 定义:中介模式定义了一个单独的(中介)对象,来封装一组对象之间的交互。将这组对象之间的交互委派给与中介对象交互,来避免对象之间的直接交互。
- 观察者模式交互关系一般都是单向的,中介模式的交互关系一般错综复杂
-
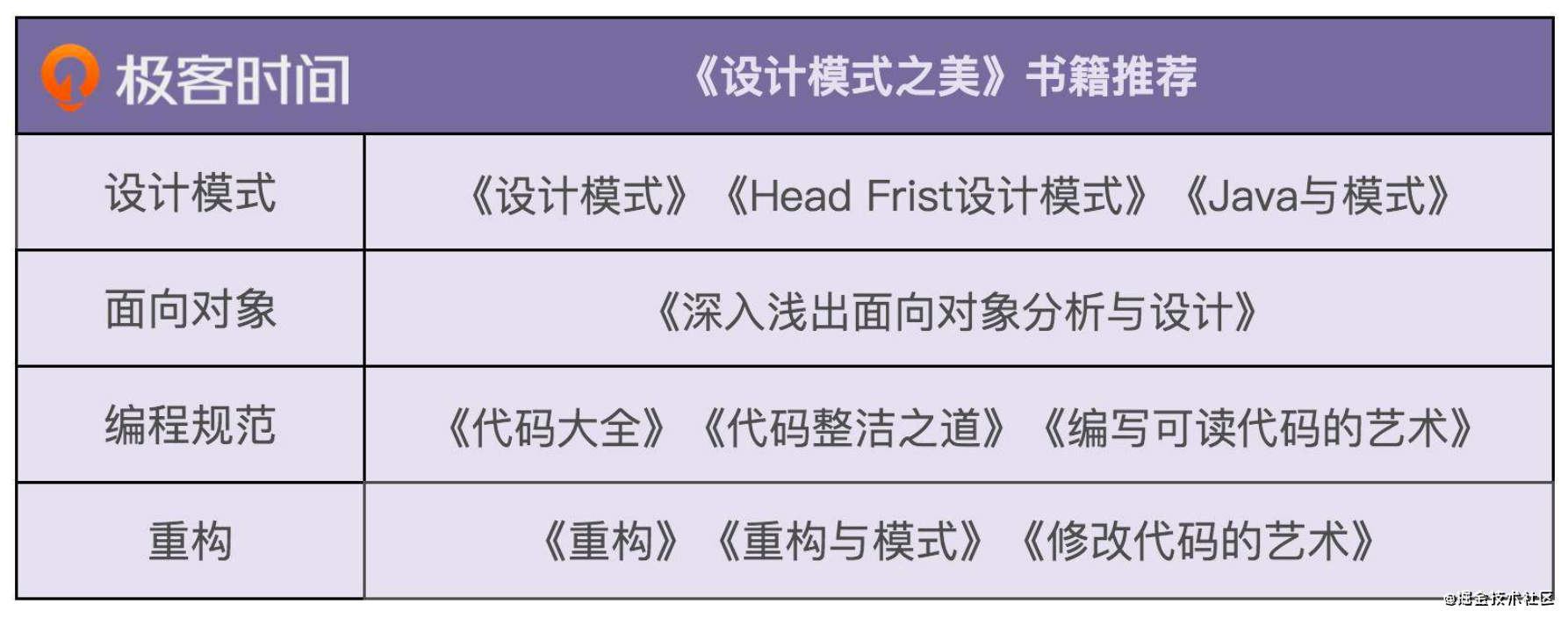
设计模式、重构、编程规范等相关书籍推荐



最后
大家如果喜欢我的文章,可以关注我的公众号(程序员麻辣烫)
我的个人博客为:https://shidawuhen.github.io/

往期文章回顾:
设计模式
语言
架构
存储
网络
工具
读书笔记
思考
















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









