







 本文详细介绍了Kubernetes中kubelet如何利用cgroups进行资源限制,包括系统预留、kube预留、QoS级别和Pod层级的限制策略,以及不同级别的资源分配和转换公式。
本文详细介绍了Kubernetes中kubelet如何利用cgroups进行资源限制,包括系统预留、kube预留、QoS级别和Pod层级的限制策略,以及不同级别的资源分配和转换公式。
前言
容器技术的两大技术基石,想必大家都有所了解,即 namespace 和 cgroups。但你知道 cgroups 是如何在 kubernetes 中发挥作用的吗?kubelet 都设置了哪些 cgroups 参数来实现对容器的资源限制的呢?本文就来扒一扒 Kubernetes kubelet 的 cgroups 资源限制机制。
层级化的资源限制方式
kubelet 基于 cgroups 的树形结构,采用层级式的方式管理容器的资源限制,如下图所示:
Node Level Cgroups
Node 层级的资源限制主要是为了避免容器过度占用系统资源,导致节点资源耗尽,影响系统级(如 systemd)和 Kubernetes 依赖组件(如 kubelet 和 containerd)的正常运行,可以通过预留系统资源的方式,确保容器使用的资源总量在控制的范围内。
system-reserved
- 默认行为:System Reserved Cgroups 默认不配置,需要通过参数显式启用
- 执行时机:每次 kubelet 启动时执行检查和设置
下表描述了 system-reserved 可能设置的 cgroups 限制:

上述表格中的资源限制数值均由参数 --system-reserved 控制,不再赘述。
kube-reserved
- 默认行为:Kube Reserved Cgroups 默认不配置,需要通过参数显式启用
- 执行时机:每次 kubelet 启动时执行检查和设置
下表描述了 kube-reserved 可能设置的 cgroups 限制:
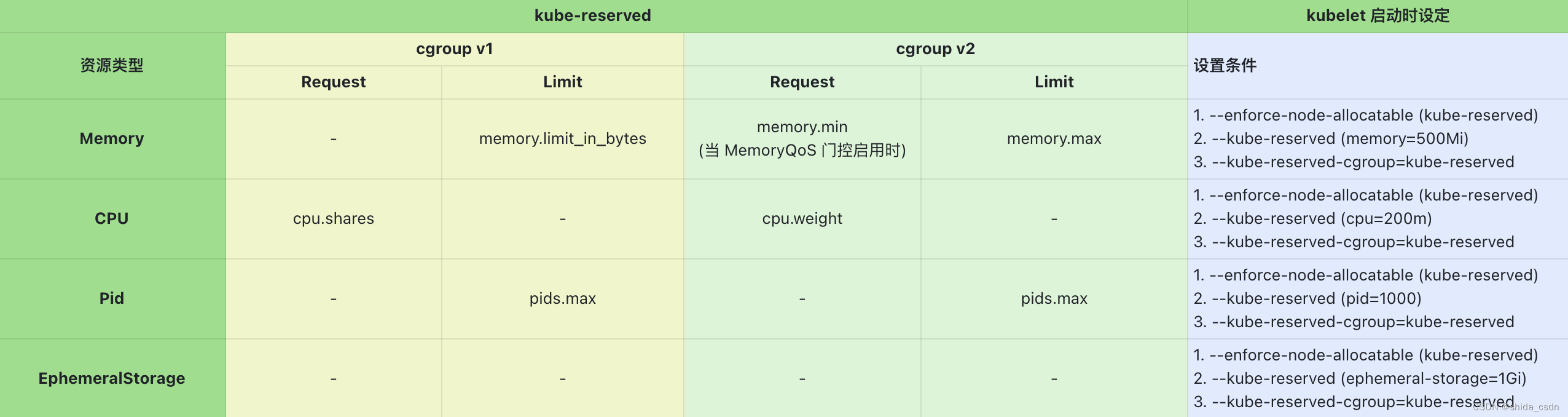
上述表格中的资源限制数值均由参数 --kube-reserved 控制,不再赘述。
kubepods
- 默认行为:kubepods 默认启用配置,且无论如何都会刷新
这是因为作为 Pods 顶级 cgroups 限制,操作系统默认设置的cpu.shares=1024或cpu.weight=100过小,很可能出现 CPU 限流,使容器性能变差,因此需要显式刷新。 - 执行时机:每次 kubelet 启动时执行检查和设置(部分参数同时会被 QoS Manager 周期性和触发式刷新)

上述表格中的资源限制数值计算规则如下:
当 --enforce-node-allocatable 包含 pods 且 --cgroups-per-qos=true 时(默认行为):
- Memory Limit = [Node Capacity] - [Kube Reserved] - [System Reserved]
- CPU Shares = [Node Capacity] - [Kube Reserved] - [System Reserved]
- Pid Limit = [Node Capacity] - [Kube Reserved] - [System Reserved]
- HugePages Limit = [Node Capacity] - [Kube Reserved] - [System Reserved]
否则
- Memory Limit = [Node Capacity]
- CPU Shares = [Node Capacity]
- Pid Limit = [Node Capacity]
- HugePages Limit = [Node Capacity]
当启用 cgroups v2 而且开启了 MemoryQoS 门控(默认不启用) 时,设置
- Memory Min = [Guaranteed Memory Request] + [Burstable Memory Request],这个参数由 QOS Manager 独立协程执行,不仅每分钟刷新一次,而且在同步 Pod 变化时也会被显式调用执行。
HugePages Limit 启动时被设置一次,随后也会被 QOS Manager 独立协程执行刷新,不仅每分钟刷新一次,而且在同步 Pod 变化时也会被显式刷新。
QOS Level Cgroups
QOS 层级的资源限制主要是为了区分三类 Pod 的服务等级,确保 guaranteed Pod 的资源不被 burstable 和 besteffort 类型的 Pod 争抢,确保 burstable Pod 的 Request 最低资源占用不被 besteffort 类型的 Pod 争抢,从而确保服务质量遵循 guaranteed > burstable > besteffort 的规则。
guaranteed
guaranteed 类型的 Pod 由于 Request 严格等于 Limit,因此该类型的 Pod 不需要再为其创建一层父级 cgroups 进行资源限制,故这一层在 Kubernetes 系统中实际上是不存在的。或者,你可以认为 kubepods 就等同于 guaranteed cgroups。guaranteed 类型的 Pod 直接挂载在 kubepods cgroups 目录下。
burstable
- 默认行为:默认启用,可以通过设置
--cgroups-per-qos=false禁用 - 执行时机:QOS Manager 独立协程执行刷新,不仅每分钟刷新一次,而且在同步 Pod 变化时也会被显式刷新

- CPU Shares = [burstable 类型 Pods 的 CPU Request 总和]
- HugePages Limit = 最大值(1 << 62 = 4611686018427387904),即不限制
Memory 的设置依赖几个开关,其中:
- 当启用 cgroups v2 而且开启了 MemoryQoS 门控(默认不启用) 时,设置 Memory Min = [Burstable Memory Request],以保留内存资源
- 当启用了 QOSReserved 门控(默认不启用) 时,设置 [Memory Limit] = [Node Available] - [Guaranteed Memory Request]*[百分比]
这里,[Node Available] 指的是节点资源总量减去系统保留资源后可供 Pod 使用的资源总量,[百分比] 来控制 burstable 类型的 Pod 是否可以争抢 Guaranteed 类型 Pod 的 Request 占用内存,100% 表示完全禁止争抢,0% 则表示完全放开,自由竞争。
默认情况下,这些开关处于关闭状态,内存是处于自由竞争的状态。
besteffort
- 默认行为:默认启用,可以通过设置
--cgroups-per-qos=false禁用 - 执行时机:QOS Manager 独立协程执行刷新,不仅每分钟刷新一次,而且在同步 Pod 变化时也会被显式刷新

- CPU Shares = 最小值(cgroups v1 value 为 2;cgroups v2 value 为 1)
- HugePages Limit = 最大值(1 << 62 = 4611686018427387904),即不限制
Memory 的设置依赖开关设置:
- 当启用了 QOSReserved 门控(默认不启用) 时,设置 [Memory Limit] = [Burstable Memory Limit] - [Burstable Memory Request]*[百分比]
其中 [Burstable Memory Limit] = [Node Available] - [Guaranteed Memory Request]*[百分比]
即 besteffort 可用内存是节点 Pods 可用内存减去为 Guaranteed 和 Burstable Request 保留内存后,剩余的内存资源
默认情况下,QOSReserved 处于关闭状态,内存处于自由竞争的状态。
注意 besteffort 类型的 Pod 顶层限制 cpu.shares 权重为最小值 2,更容易出现 CPU 限流
Pod Level Cgroups
Pod 层级的资源限制主要是为了限制 Pod 内包含的所有 Container 资源占用不超过设置的资源上限。提供 Pod 层资源限制的主要优点是能够屏蔽底层容器运行时,即便底层 Container Runtime 没能为 Container 正确设置 cgroups 资源限制,kubelet 也能在 Container 的父级 cgroups 把资源使用限制住,防止单个 Pod 异常影响整个节点的稳定性。
Pod level cgroups 是 kubelet 能够直接设置的最底一层 cgroups。
对于 Container 的 cgroups,kubelet 仅仅只是准备 cgroups 配置参数,通过 CRI 传递给 Container Runtime 真正去执行配置。
- 默认行为:默认启用,可以通过设置
--cgroups-per-qos=false禁用 - 执行时机:kubelet 收到 Pod 事件,SyncPod 时设置

由于 Pod 的 QoS 类型不同,不同的资源限制有可能被设置,也可能未被设置,这些参数主要是通过 Pod 容器的 Request 和 Limit 配置决定是否配置对应的 cgroups 参数的。
- [Memory Limit] = [ Pod 容器的 Memory Limit 总和 ],当所有容器都配置 Limit 时生效
- [Memory Min] = [ Pod 容器的 Memory Request 总和 ],至少有一个容器配置了 Memory Request,同时 MemoryQoS 被开启
- [CPU Shares] = [ Pod 容器的 CPU Request 总和 ],如果计算结果低于最小值,则配置为最低 CPU Shares(等同于 besteffort 类型 Pod 的 CPU 权重)
- [CPU Limit] = [ Pod 容器的 CPU Limit 总和 ],当所有容器都配置 Limit 时生效,同时 --cpu-cfs-quota 开启,默认开启
- [Pid Limit] = [kubelet 启动参数设置的限制值],当 --pod-max-pids > 0 时生效,默认 -1 不限制
- [HugePages Limit] = [ Pod 容器的 HugePages Request 总和 ],至少有一个容器配置了 HugePages Request,HugePages 资源的 Request 必须等于 Limit
Container Level Cgroups
Container 层级的资源限制由 Container Runtime(如 Containerd + Runc)实施,kubelet 通过 CRI 接口将需要设置的 cgroups 资源限制传递给底层 Runtime 去执行,实现对每个 Container 的资源限制。
- 默认行为:默认启用
- 执行时机:kubelet 收到 Pod 事件,SyncPod 时设置
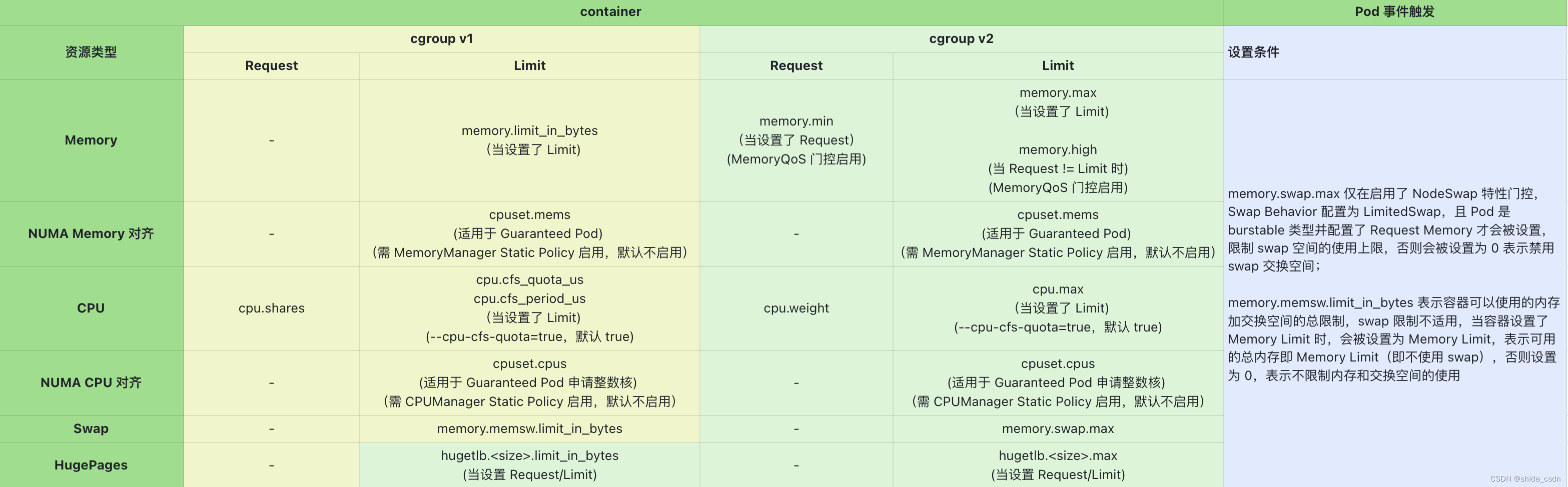
- [Memory Limit] = [ Container 容器的 Memory Limit ]
- [Memory Min] = [ Container 容器的 Memory Request ],依赖 MemoryQoS 门控
- memory.high=floor[(requests.memory + memory throttling factor * (limits.memory or node allocatable memory - requests.memory))/pageSize] * pageSize,其中 memory throttling factor 默认值为 0.9,即内存达到 Limit 的 90% 时,开始限流内存使用,依赖 MemoryQoS 门控
- memory.swap.max=containerMemoryRequest/nodeTotalMemory*totalPodsSwapAvailable,仅适用于 cgroups v2,依赖 NodeSwap 门控和 Swap Behavior 配置,默认禁用 (cgroups v1 不支持 swap 限制,只禁用 swap)
- cpuset.mems=[ 内存分配绑定的 NUMA 节点 ],依赖 Memory Manager 工作且设置为 Static Policy 模式,仅对 Guaranteed 类型 Pod 生效,默认不启用
- [CPU Shares] = [ Container 容器的 CPU Request ],如果计算结果低于最小值,则配置为最低 CPU Shares(等同于 besteffort 类型 Pod 的 CPU 权重)
- [CPU Limit] = [ Container 容器的 CPU Limit ]
- cpuset.cpus=[ CPU 分配绑定的 NUMA 节点 ],依赖 CPU Manager 工作且设置为 Static Policy 模式,仅对 Guaranteed 类型 Pod 生效,默认不启用
- [HugePages Limit] = [ Container 容器的 HugePages Request ],HugePages 资源的 Request 必须等于 Limit
CPU 转换公式
容器的 CPU 资源配置由数字表示:
整数 1 代表 1 core,1 core = 1000m
Linux 系统,默认 1 core 的 cpu.shares 对应值为 1024,由此可以推演出如下公式:
1 core = 1000m => cpu.shares=1024
cpu.shares = [cpu request 的 小 m 表示法]*1024/1000
例如,当 cpu request 为 100m 时,对应的 cpu.shares=100*1024/1000=102(取整数)
对于 cpu limit:
cpu.cfs_quota_us = [cpu limit 的 小 m 表示法]*cpu.cfs_period_us/1000,其中 cpu.cfs_period_us 为固定值,默认为 100ms,即 100000us
从 cgroups v1 的 cpu.shares 转换为 cgroups v2 的 cpu.weight 公式为:
cpu.weight = 1 + ((cpu.shares-2)*9999)/262142
该公式由 cgroups v1 中 cpu.shares 的有效范围 [2-262144] 到 cgroups v2 中 cpu.weight 的有效范围 [1-10000] 的数学映射转换关系推导而来
引用参考
- http://arthurchiao.art/blog/k8s-cgroup-zh















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









