






java 8 lamdba
前言
从19年开始接触lambda表达式,一开始比较难于看懂,但是写多了,就会发生代码简洁明了,而且还有很多高级的写法,让代码质量越来越高,下面就开始介绍一下lambda表达式的写法和一些高级写法的介绍
基础类
- 基础函数类
- Function<T,R> 可以存储只有一个入参和返回值得对象方法,T表示入参,R表示返回值,看如下代码,String.valueOf(),是一个String类提供的一个静态方法,这个指向的入参是Integer,出参是String的方法。
下面两行代码,定义了一个String对象,将对象的方法保存到function1
//保存一个初始化string的对象静态方法
Function<Integer, String> function = String::valueOf;
//保存一个切割字符串的对象方法
String s1 = "";
Function<String,String[]> function1 = s1::split;
- Predicate<? super T> 可以存储一个出参是boolean的对象方法,主要Optional和Stream用于过滤方法。
//保存一个比较字符串一直的对象方法
String s1 = "1234";
Predicate<String> predicate = s1::equals;
3.Supplier<? super T> 可以存储一个无参并且有返回值的方法,如下代码
//保存一个创建String对象的方法
Supplier<String> supplier = String::new;
//保存一个字符串长度对象方法
Supplier<Integer> supplier1 = "1234"::length;
4.Consumer<? super T> 只是单个入参,没有出参的方法,看如下代码
class User {
String name;
public void set(String name) {
this.name = name;
}
}
User user = new User();
Consumer<String> consumer = user::set;
正式介绍lambda
- 开始正式介绍lambda涉及到的使用类,总结起来分为两大类,一个是Optional和Stream
1.Optional,主要是处理单个对象的操作
Optional.of()不会去判断出入的对象是否为null,Optional.ofNullable()会去判断传入的对象是否为null,如果是为null,后面的操作都不会执行
//把s值打印出来
String s ="1123";
//如果s不为null就打印出来,为null的就不会被打印出来
s = Optional.ofNullable(s).ifPresent(System.out::println);
//传入的s不可以为null,是否就报错,如果对象不为null将会打印出来
Optional.of(s).ifPresent(System.out::println);
Optional.map(Function<R,T>)主要是主要是执行具体的业务,这个方法在stream里面也存在,使用方式是一样的,如下所示
String s = "123";
//把s字符串后面拼接一个aaa的字符串,并打印出来
Optional.of(s).map(s1 -> s1+"aaa").ifPresent(System.out::println);

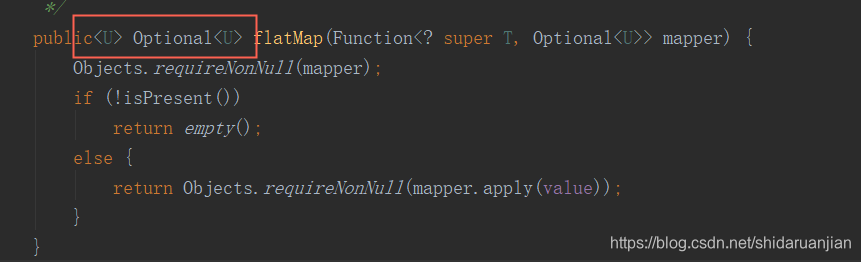
其中还存在一个方法flatMap(),这个方法是处理完毕业务,最终返回值为Optional,可以看看如下代码,目前为止我还没有看到这个方法的可用之处,知道一下就好
Optional.filter(Predicate<? super T> predicate),这个起到了一个过滤的作用,如果不满足这个过滤后续的业务操作不不会进行,在Stream里面也有这个方法,使用的方式也是一样的
String s = "123";
//判断s是否等于123,如果等于就打印出123aaa,不等于就过滤掉,这个操作结束
//,s1+"aaa"这个语句自然也不会执行
Optional.of(s).filter("123"::equals).map(s1 -> s1 + "aaa").
ifPresent(System.out::println);
Optional最终的结束语方法如下所示
| 方法 | 解释 |
|---|---|
| ifPresent() | 没有返回值,主要是把值设置给某一个对象 |
| get () | 获取Optional操作的对象,对象不可以为NULL,否则会报错 |
| orElseGet((Supplier<? extends T>) | 获取Optional操作对象,如果对象NULL,那就执行Supplier传入的对象方法执行获取最终的结果 |
| orElse(T) | 获取Optional操作的对象,如果对象为null,那就返回T传入的对象 |
| orElseThrow(Supplier<? extends Throwable> exceptionSupplier) | 获取Optional操作的对象,如果对象为NULL,实现的对象务必返回一个初始化的异常类 |
String s = "123";
//最终返回aaa_s1
String s1 = Optional.ofNullable(s).filter("12"::equals).map(ss -> ss + "abc").orElse("aaa_s1");
//最终返回aaa_s2
String s2 = Optional.ofNullable(s).filter("12"::equals).map(ss -> ss + "abc").orElseGet(() -> "aaa_s2");
//最终抛出一个RuntimeException异常
String s3 = Optional.ofNullable(s).filter("12"::equals).map(ss -> ss + "abc").orElseThrow(RuntimeException::new);
//最终返回123abc
String s4 = Optional.ofNullable(s).filter("123"::equals).map(ss -> ss + "abc").orElseThrow(RuntimeException::new);
2.Stream 这个是lamdba表达式核心对象,也是最为复杂经常使用到的,他是对一个集合的处理,可以看看如下方法
Optional最终的结束语方法如下所示
| 方法 | 解释 |
|---|---|
| Coolection.Stream(),Stream.of(T …t), | 这个是开始触发一个遍历集合的开始, |
| Stream.generate(Supplier< T > ) | 开启无限次数的遍历,必须要结合limit(),anyMatch()或者noneMatch()相关方法来结束遍历 |
| parallelStream() | 开启多线程的遍历,可以在map()方法存在多线程处理,但是需要在结束流里面将对其结果进行合并,后面会详细讲解 |
| map() | 执行具体业务方法 |
| filter(Predicate<? super T> predicate) | 启动过滤作用,这个是回去过滤遍历里面的单个对象,不会让整个遍历结束 |
| peek(Consumer<? super T> action) | 看得出来的是一个只有入参的对象方法,这个不需要有返回值,所以可以自己把传入的对象进行修改 |
| limit() | 限制遍历的次数 |
| skip() | 开始遍历的位置 |
| distinct | 对集合进行去重,如果是一个自定义的对象,需要去重新对象的equal方法,去重方可生效 |
| sorted(),sorted(Comparator<? super T> comparator) | 对集合进行排序,启动sorted()是需要集合对象基础Comparable接口,反之会报错 |
| anyMatch(),noneMatch(),allMatch() | 这个是整个遍历结束语,其中传入的对象参数就是过滤的对象方法(Predicate<? super T> predicate),分别表示anyMatch(),遍历中其中有一个返回true,整个遍历结束,返回值是true,allMatch(),遍历中其中一个返回false,这个遍历结束,返回的值是false,noneMatch(),遍历中只要不返回true,遍历就不会结束,最后返回值是true |
| reduce() | 聚合操作,只需要是把集合汇集成一个对象,例如计算计算总金额 |
| collect() | lamdba表达式结束语,也就是集合的汇聚的使用方式,提供了极为丰富的API,可以实现任何需求,后面会详细描述 |
需要测试的,可以把下面的对象保存起来,后面的案例会用到这个类
/**
* @author 游建诺
* create by time 2019/6/17
**/
public class OptionalValue<T> {
private int i = -1;
private T value;
public OptionalValue() {
}
public OptionalValue(T t) {
value = t;
}
public int setI(int i) {
this.i = i;
return i;
}
public int add(int i) {
this.i += i;
return this.i;
}
public int add() {
return add(1);
}
public int getI() {
return i;
}
public T setValue(T value) {
this.value = value;
return value;
}
public T getValue() {
return value;
}
}
案例1:创建一个0到10的字符串集合,并且把里面的内容打印出来
List<String> list =
//开启一个遍历,并且从0开始递增
Stream.generate(new OptionalValue<>()::add).
//限制遍历10次
limit(10).
//把integer类型转换成String类型
map(String::valueOf).
//全部存入到list集合里面
collect(java.util.stream.Collectors.toList());
//开启一个遍历,然后打印出里面
list.forEach(System.out::println);

案例2 在上述案例,从大到小打印出来
List<String> list =
//开启一个遍历,并且从0开始递增
Stream.generate(new OptionalValue<>()::add).
//限制遍历10次
limit(10).
//加上排序
sorted(Comparator.reverseOrder()).
//把integer类型转换成String类型
map(String::valueOf).
//全部存入到list集合里面
collect(java.util.stream.Collectors.toList());
//开启一个遍历,然后打印出里面
list.forEach(System.out::println);

案例3.在上述案例,只打印出偶数出来
List<String> list =
//开启一个遍历,并且从0开始递增
Stream.generate(new OptionalValue<>()::add).
//限制遍历10次
limit(10).
//加上排序
sorted(Comparator.reverseOrder()).
//添加过滤,把为偶数的数值通过,奇数过滤掉
filter(s -> s%2 == 0).
//把integer类型转换成String类型
map(String::valueOf).
//全部存入到list集合里面
collect(java.util.stream.Collectors.toList());
//开启一个遍历,然后打印出里面
list.forEach(System.out::println);

案例4 有一个字符串数组,把相同的过滤掉,并且返回一个list集合
String[] arrays = new String[]{"1", "1", "2", "3", "4", "1", "4"};
List<String> list = Stream.of(arrays).distinct()
.collect(toList());
System.out.println(list);

案例5 给定一个集合,把第3位开始打印出后2为数值
String[] arrays = new String[]{"1", "1", "2", "3", "4", "1", "4"};
//从第array[3]开始打印后面两位数值
List<String> list = Stream.of(arrays).skip(3).limit(2)
.collect(toList());
System.out.println(list);

案例6,给定一个集合,对其进行分页,每页的数量为3
//每一页分的次数
int pageSize = 3;
//创建一个0到20的集合
List<String> list = Stream.generate(new OptionalValue<>()::add).limit(20).map(String::valueOf).collect(toList());
//计算需要分多少页
int n = (list.size() / pageSize) + list.size() % pageSize == 0 ? 0 : 1;
List<List<String>> lists =
//开启一个遍历
Stream.generate(new OptionalValue<>()::add)
//限制遍历次数
.limit(n)
//开始去截取字符串数组,这个是最优的写法,耗时最短
//.map(i -> list.subList(i * pageSize, Math.min(list.size() ,i * pageSize + pageSize)))
//采用lamdba表达式的写法
.map(i -> list.stream().skip(i * pageSize).limit(pageSize).collect(toList()))
.collect(toList());
System.out.println(lists);

为了方便对任何对象集合分页,我们可以封装成一个通用方法
public static <T> Stream<List<T>> pageStream(List<T> list, int limit) {
int totalPage = (list.size() / limit) + (list.size() % limit == 0 ? 0 : 1);
OptionalValue<Integer> nextOptionValue = new OptionalValue<>();
return Stream.generate(nextOptionValue::add)
.limit(totalPage)
.map(i -> list.stream().skip(i * limit).limit(limit))
.map(stream -> stream.collect(toList()));
}
案例7:定义一个BigDecimal集合,计算里面的总数
//初始化一个BigDecimal
List<BigDecimal> list =
Stream.generate(new OptionalValue<>()::add).limit(20).map(BigDecimal::new).collect(toList());
BigDecimal total = list.stream()
//默认值是BigDecimal.ZERO,BigDecimal::add:表示加起来
.reduce(BigDecimal.ZERO,BigDecimal::add);
System.out.println(total);

案例8:给定一个字符串集合判断里面是否存在一个字符串3
//初始化一个集合
List<String> list = Stream.of("1","2","4","5").collect(toList());
//判断是否存在集合里面存在3字符串
boolean is = list.stream().anyMatch(s -> "3".equals(s));
System.out.println("集合是否存在3的字符串:"+is);

上述案例只是例举了基础的用法,现在需要来介绍一些高级用法,主要是collect()方法提供的,这个只要是做流的聚合运算,其中有一个重要管理类Collectors,Collectors里面有很多静态方法,可以使用各种需求,这里面着重介绍一下Collector.of(),并且利用这个如何去定义自己的方法,因为这个方法是最最基本的,所有Collector里面的静态方法都是调用这个方法实现的
先定义一个对象User
public static class User{
public String name;
private int year;
private String height;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public String getHeight() {
return height;
}
public void setHeight(String height) {
this.height = height;
}
}
案例1,给定一个user集合,把起转入一个HashMap里面去,并且HashMap对应的key是name
User user1 = new User("张三", 20, "170");
User user2 = new User("李四", 21, "171");
User user3 = new User("王二", 22, "172");
User user4 = new User("二狗", 23, "173");
List<User> users = Stream.of(user1, user2, user3, user4).collect(toList());
Map<String, User> list = users.stream().collect(Collectors.toMap(User::getName, user -> user));
System.out.println(list);
{李四=D.User(name=李四, year=21, height=171), 二狗=D.User(name=二狗, year=23, height=173), 张三=D.User(name=张三, year=20, height=170), 王二=D.User(name=王二, year=22, height=172)}
根据案例一,我们可以采用Collector.of()方法重新实现一遍,
User user1 = new User("张三", 20, "170");
User user2 = new User("李四", 21, "171");
User user3 = new User("王二", 22, "172");
User user4 = new User("二狗", 23, "173");
List<User> users = Stream.of(user1, user2, user3, user4).collect(toList());
//初始化一个HashMap
Supplier<Map<String, User>> supplier = HashMap::new;
//把user对象放入到map里面去
BiConsumer<Map<String, User>, User> accumulator = (map, user) -> map.putIfAbsent(user.getName(), user);
//多线程的时候需要使用这个方法,但是单线程无需关注
BinaryOperator<Map<String, User>> binaryOperator = (map1, map2) -> map1;
Map<String, User> list = users.stream().collect(Collector.of(supplier, accumulator, binaryOperator, IDENTITY_FINISH));
System.out.println(list);
上述案例还可以在进一步的设计,目前是把User按照里面的name为key存入到Map里面,但是如果name存在相同的话,需要把他们都保留下载,所以需要使用Map<String,List< User >>来存储,我们分别使用系统自带的方法和自定义实现的方法
系统自带的
User user1 = new User("张三", 20, "170");
User user2 = new User("张三", 21, "171");
User user3 = new User("王二", 22, "172");
User user4 = new User("二狗", 23, "173");
List<User> users = Stream.of(user1, user2, user3, user4).collect(toList());
Map<String, List<User>> list = users.stream().collect(Collectors.groupingBy(User::getName,toList()));
System.out.println(list);
结果:
{二狗=[D.User(name=二狗, year=23, height=173)], 张三=[D.User(name=张三, year=20, height=170), D.User(name=张三, year=21, height=171)], 王二=[D.User(name=王二, year=22, height=172)]}
定义实现方式
User user1 = new User("张三", 20, "170");
User user2 = new User("张三", 21, "171");
User user3 = new User("王二", 22, "172");
User user4 = new User("二狗", 23, "173");
List<User> users = Stream.of(user1, user2, user3, user4).collect(toList());
//初始化一个HashMap
Supplier<Map<String, List<User>>> supplier = HashMap::new;
//把user对象放入到map里面去
BiConsumer<Map<String, List<User>>, User> accumulator = (map, user) ->
map.computeIfAbsent(user.getName(), name->new ArrayList<>()).add(user);
//多线程的时候需要使用这个方法,但是单线程无需关注
BinaryOperator<Map<String, List<User>>> binaryOperator = (map1, map2) -> map1;
Map<String, List<User>> list = users.stream().collect(Collector.of(supplier, accumulator, binaryOperator, IDENTITY_FINISH));
System.out.println(list);
上述自定义的的方法和相关的类绑定很深,可以自行封装一个泛型的方法,体验一下自己封装的快乐
案例2 采用Collector.of自带的方法,封装一个通过的方法,一方便大家学习参考
现有一个List<List<String> list 将其转换为List<String>,直接上代码了,不多解释
public static <T> Collector<List<T>, List<T>, List<T>> toLinearList() {
Supplier<List<T>> supplier = ArrayList::new;
BiConsumer<List<T>, List<T>> biConsumer =
List::addAll;
BinaryOperator<List<T>> binaryOperator = (emailMainEntities, emailMainEntities2) -> emailMainEntities2;
return Collector.of(supplier, biConsumer, binaryOperator, Collector.Characteristics.IDENTITY_FINISH);
}
如下使用
List<List<String>> lists = Stream.generate(new OptionalValue<>()::add)
.limit(10).map(i -> Stream.generate(new OptionalValue<>()::add).limit(2).map(String::valueOf).collect(toList()))
.collect(toList());
List<String> list = lists.stream().collect(toLinearList());
System.out.println(list);
思考:如果使用系统自带的方法来实现这一的逻辑,联系方式:382034324@qq.com
案例3,现有一个List<String>集合,讲起拼接起来,采用逗号分开,并且字符串前有有中括号包裹起来
List<String> list = Stream.generate(new OptionalValue<>()::add).limit(10).map(String::valueOf).collect(toList());
String s = list.stream().collect(Collectors.joining(",", "[", "]"));
System.out.println(s);

后言
java8 lamdba已经基本上介绍完毕,在开发中尽量使用lamdba来使用,这样才会更容易写出更加优美的代码出来、lamdba表达式还有很多高深的写法值得大家去探索
谢谢大家!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









