







Scrapy采集框架
1 学习目标
1、框架流程和结构设计原理
2、框架爬虫程序编写
3、框架日志模块使用
4、框架请求发送流程
2 scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
2.0 单个爬虫编写
class Spider(object):
def __init__(self):
# 负责全局配置
pass
def url_list(self):
# 负责任务池维护
pass
def request(self):
# 负责网络请求模块
pass
def parse(self):
# 负责解析数据模块
pass
def save(self):
# 负责数据存储
pass
def run(self):
# 负责模块调度
pass2.1 架构介绍

2.2.1 名词解析
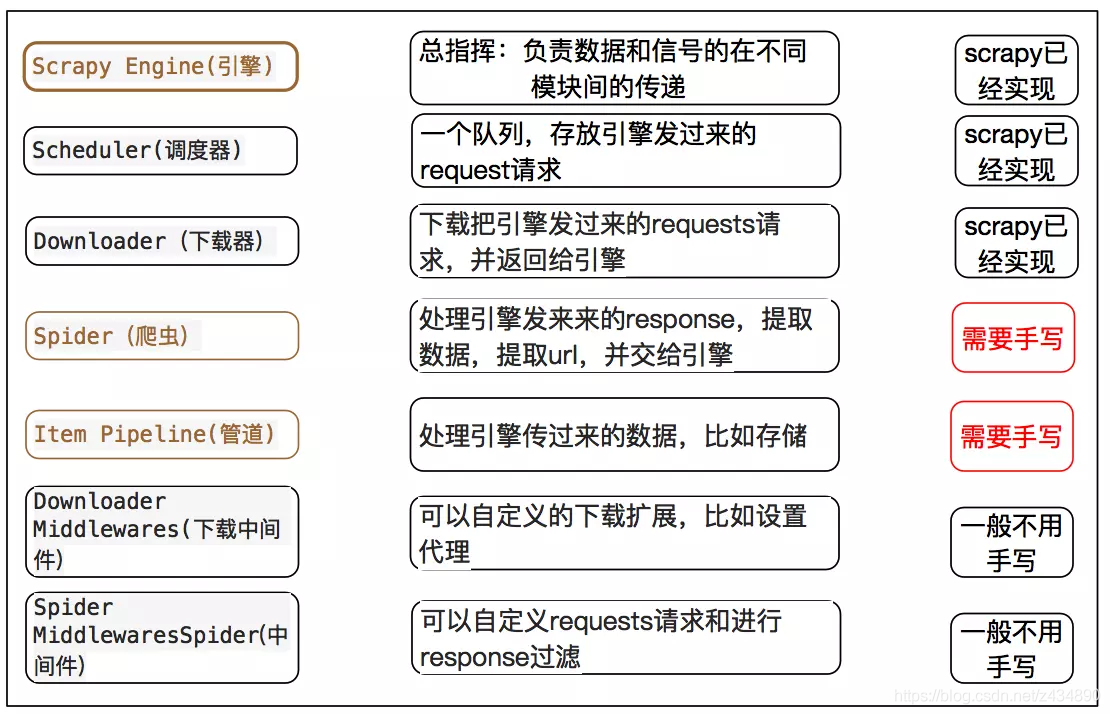
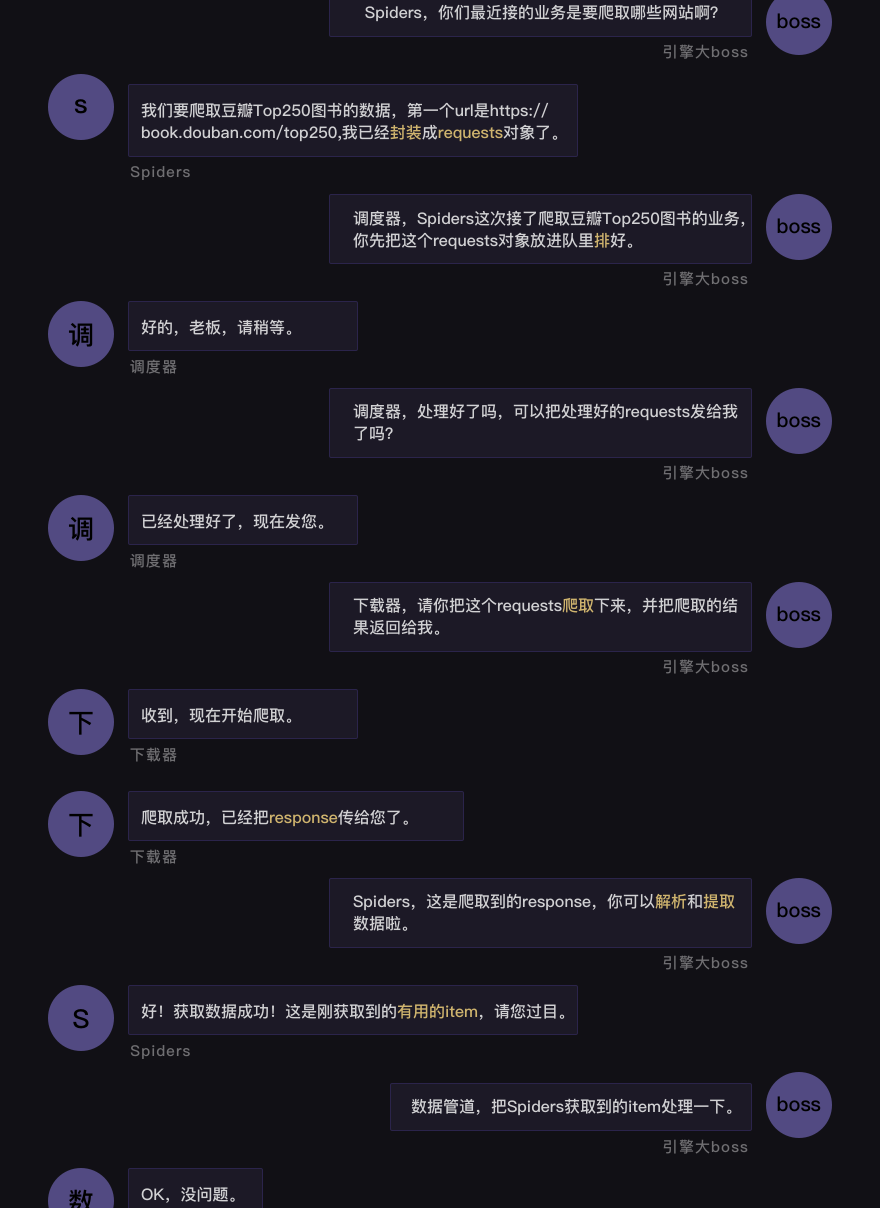
2.2.2 运行逻辑图
3 框架使用
3.1 项目搭建
3.1.1 框架安装
查找历史版本:https://pypi.org/project/Scrapy/#history
pip install scrapy==2.3.03.1.2 项目创建
scrapy startproject xxxx文件介绍
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。3.1.3 创建爬虫
Spider 是自己定义的类,Scrapy 用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始请求,以及怎样处理爬取后的结果的方法
cd 项目路径
scrapy genspider 爬虫名称 目标地址配置文件简介
# Scrapy settings for ScrapyDemo project
# 自动生成的配置,无需关注,不用修改
BOT_NAME = 'ScrapyDemo'
SPIDER_MODULES = ['ScrapyDemo.spiders']
NEWSPIDER_MODULE = 'ScrapyDemo.spiders'
# 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'ScrapyDemo (+http://www.yourdomain.com)'
# 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True
# 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32
# 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3
# 下面两个配置二选一,但其值不能大于CONCURRENT_REQUESTS,默认启用PER_DOMAIN
# 对网站每个域名的最大并发请求,默认8
CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 默认0,对网站每个IP的最大并发请求,会覆盖上面PER_DOMAIN配置,
# 同时DOWNLOAD_DELAY也成了相同IP两个请求间的间隔了
CONCURRENT_REQUESTS_PER_IP = 16
# 禁用cookie,默认是True,启用
COOKIES_ENABLED = False
# 请求头设置,这里基本上不用
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
# 配置启用Spider MiddleWares,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoSpiderMiddleware': 543,
}
# 配置启用Downloader MiddleWares
DOWNLOADER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543,
}
# 配置并启用扩展,主要是一些状态监控
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
# 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {
'ScrapyDemo.pipelines.ScrapydemoPipeline': 300,
}3.2 执行爬虫
3.2.1 终端运行爬虫
- 需要去到项目跟路径执行指令
scrapy crawl xxxx3.2.2 脚本运行
- 在
Scrapy中有一个可以控制终端命令的模块cmdline。导入了这个模块,我们就能操控终端 execute方法能执行终端的命令行
from scrapy import cmdline
cmdline.execute("scrapy crawl xxxx".split())
cmdline.execute(["scrapy","crawl","xxxx"])运行报错
ImportError: cannot import name 'HTTPClientFactory' from 'twisted.web.client' (unknown location)解决:
# 降低Twisted版本
pip install Twisted==20.3.03.3 scrapy shell调试
基本使用
scrapy shell https://dig.chouti.com/数据提取
datas =res.xpath('//div[@class="link-con"]/div')
for i in datas:
print(i.xpath('.//a[@class="link-title link-statistics"]/text()').extract_first())4 实战演示
- 目标地址:https://boo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2761
2761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









