







不废话砸直接开始,想看griffin的功能和应用可以去百度,在此我们只讲安装。安装。安装。此安装的环境是在linux下面编译运行。
1.griffin依赖很多组件,请一定要保证这些组件正常安装和运行,请一定要保证这些组件正常安装和运行,请一定要保证这些组件正常安装和运行。
- JDK 1.8 (以上)
- Maven
- Mysql 数据库 (可以是 PostgreSQL )
- npm
- nodejs (至少8版本,直接最新就行)
- Scala
- Hadoop (2.6.0或更高版本)
- Hive (版本2.x)
- Spark (版本2.x)
- Livy
- ElasticSearch(5.0或更高版本)
- Zookeeper
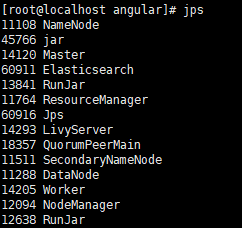
- 运行起来,后台进程如下:
2.下载griffin
github地址:https://github.com/apache/griffin
- 下载: wget https://github.com/apache/griffin/archive/griffin-0.5.0.tar.gz
- 解压: tar -zxf griffin-0.5.0.tar.gz
- 进入项目源码目录: cd griffin-griffin-0.5.0/
3.配置mysql
① 在MySQL服务器中执行命令,创建一个 quartz 库
mysql -u <username> -e "create database quartz" -p
②在下载的源码中griffin-griffin-0.5.0/service/src/main/resources/Init_quartz_mysql_innodb.sql找到sql脚本,上传到Mysql Service, 使用Init_quartz_mysql_innodb.sql在MySQL中初始化 Quartz
mysql -u <username> -p quartz < Init_quartz_mysql_innodb.sql4.Hive配置
①将 hive 的配置文件 hive-site.xml 上传到hdfs
hadoop fs -put $HIVE_HOME/conf/hive-site.xml hdfs:///home/spark_conf/
【注:/home/spark_conf/ 目录如没有自己创建:hadoop fs -mkdir /home】
②hive的一定要启动metastore服务
5.配置Elasticsearch
这里提前在Elasticsearch设置索引,以便将分片数,副本数和其他设置配置为所需的值:
curl -k -H "Content-Type: application/json" -X PUT http://es集群名:9200/griffin \
-d '{
"aliases": {},
"mappings": {
"accuracy": {
"properties": {
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"tmst": {
"type": "date"
}
}
}
},
"settings": {
"index": {
"number_of_replicas": "2",
"number_of_shards": "5"
}
}
}'创建成功后会返回如下信息:
{"acknowledged":true,"shards_acknowledged":true,"index":"griffin"}以上就是其他组件上的一些操作和特殊配置,再说一遍,请一定保证所有依赖组件配置成功启动成功调试成功!!!
6.griffin配置
① 配置application.properties文件
位置:griffin-griffin-0.5.0/service/src/main/resources/application.properties
# Apache Griffin server port (default 8080) 【请一定注意,spark默认端口也是8080,你要么修改spark,要么直接修改griffin的端口】
server.port = 8090
spring.application.name=griffin_service
#db configuration【还支持其他数据库,可以去官网看】
spring.datasource.url=jdbc:mysql://localhost:3306/quartz?autoReconnect=true&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.jpa.generate-ddl=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=true
# Hive metastore
# 这里配置的值为`hive-site.xml`中的 `hive.metastore.uris`配置项的值
hive.metastore.uris=thrift://192.168.43.129:9083
hive.metastore.dbname=hive
hive.hmshandler.retry.attempts=15
hive.hmshandler.retry.interval=2000ms
# Hive cache time
cache.evict.hive.fixedRate.in.milliseconds=900000
# Kafka schema registry 【kafka不是必须的】
kafka.schema.registry.url=http://localhost:8081
# Update job instance state at regular intervals
jobInstance.fixedDelay.in.milliseconds=60000
# Expired time of job instance which is 7 days that is 604800000 milliseconds.Time unit only supports milliseconds
jobInstance.expired.milliseconds=604800000
# schedule predicate job every 5 minutes and repeat 12 times at most
#interval time unit s:second m:minute h:hour d:day,only support these four units
predicate.job.interval=5m
predicate.job.repeat.count=12
# external properties directory location
external.config.location=
# external BATCH or STREAMING env
external.env.location=
# login strategy ("default" or "ldap")
login.strategy=default
# ldap
ldap.url=ldap://hostname:port
ldap.email=@example.com
ldap.searchBase=DC=org,DC=example
ldap.searchPattern=(sAMAccountName={0})
# hdfs default name【跟你hadoop中core-site.xml中保持一致】
fs.defaultFS=localhost:9000
# elasticsearch
elasticsearch.host=192.168.43.129
elasticsearch.port=9200
elasticsearch.scheme=http
# elasticsearch.user = user
# elasticsearch.password = password
# livy
livy.uri=http://localhost:8998/batches
# yarn url
yarn.uri=http://localhost:8088
# griffin event listener
internal.event.listeners=GriffinJobEventHook②配置quartz.properties文件
位置:griffin-griffin-0.5.0/service/src/main/resources/quartz.properties
org.quartz.scheduler.instanceName=spring-boot-quartz
org.quartz.scheduler.instanceId=AUTO
org.quartz.threadPool.threadCount=5
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
# If you use postgresql as your database,set this property value to org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
# If you use mysql as your database,set this property value to org.quartz.impl.jdbcjobstore.StdJDBCDelegate
# If you use h2 as your database, it's ok to set this property value to StdJDBCDelegate, PostgreSQLDelegate or others
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
org.quartz.jobStore.useProperties=true
org.quartz.jobStore.misfireThreshold=60000
org.quartz.jobStore.tablePrefix=QRTZ_
org.quartz.jobStore.isClustered=true
org.quartz.jobStore.clusterCheckinInterval=20000
③配置sparkProperties.json文件
位置:griffin-griffin-0.5.0/service/src/main/resources/sparkProperties.json
{
"file": "hdfs:///griffin/griffin-measure.jar",
"className": "org.apache.griffin.measure.Application",
"name": "griffin",
"queue": "default",
"numExecutors": 2,
"executorCores": 1,
"driverMemory": "1g",
"executorMemory": "1g",
"conf": {
"spark.yarn.dist.files": "hdfs:///home/spark_conf/hive-site.xml"
},
"files": [
]
}④ 配置env_batch.json文件
位置:griffin-griffin-0.5.0/service/src/main/resources/env/env_batch.json
{
"spark": {
"log.level": "WARN"
},
"sinks": [
{
"type": "CONSOLE",
"config": {
"max.log.lines": 10
}
},
{
"type": "HDFS",
"config": {
"path": "hdfs:///griffin/persist",
"max.persist.lines": 10000,
"max.lines.per.file": 10000
}
},
{
"type": "ELASTICSEARCH",
"config": {
"method": "post",
"api": "http://192.168.43.129:9200/griffin/accuracy",
"connection.timeout": "1m",
"retry": 10
}
}
],
"griffin.checkpoint": []
}
⑤ 配置env_streaming.json文件
位置:griffin-griffin-0.5.0/service/src/main/resources/env/env_streaming.json
{
{
"spark": {
"log.level": "WARN",
"checkpoint.dir": "hdfs:///griffin/checkpoint/${JOB_NAME}",
"init.clear": true,
"batch.interval": "1m",
"process.interval": "5m",
"config": {
"spark.default.parallelism": 4,
"spark.task.maxFailures": 5,
"spark.streaming.kafkaMaxRatePerPartition": 1000,
"spark.streaming.concurrentJobs": 4,
"spark.yarn.maxAppAttempts": 5,
"spark.yarn.am.attemptFailuresValidityInterval": "1h",
"spark.yarn.max.executor.failures": 120,
"spark.yarn.executor.failuresValidityInterval": "1h",
"spark.hadoop.fs.hdfs.impl.disable.cache": true
}
},
"sinks": [
{
"type": "CONSOLE",
"config": {
"max.log.lines": 100
}
},
{
"type": "HDFS",
"config": {
"path": "hdfs:///griffin/persist",
"max.persist.lines": 10000,
"max.lines.per.file": 10000
}
},
{
"type": "ELASTICSEARCH",
"config": {
"method": "post",
"api": "http://es集群:9200/griffin/accuracy"
}
}
],
"griffin.checkpoint": [
{
"type": "zk",
"config": {
"hosts": "zk集群:2181",
"namespace": "griffin/infocache",
"lock.path": "lock",
"mode": "persist",
"init.clear": true,
"close.clear": false
}
}
]
}以上基本griffin的配置完成,简单说明一下,以上配置均为service包中的配置;griffin中最主要的三个包:measure、service、ui,如果你只是实现简单的数据对比,直接用measure模块就可以了,measure模块中的配置文件一般都是依赖组件的默认配置,如果有需要,按需修改。service是沟通measure和UI的模块,UI是前端页面模块,没错,前后端分离设计。
⑥UI模块的配置
修改environment.ts文件
位置:griffin-griffin-0.5.0\ui\angular\src\environments\environment.ts
export const environment = {
production: false,
BACKEND_SERVER: 'http://192.168.43.129:8090',
};注:上面配置的地址要与你在 service模块中application.properties文件中配置的端口一致,其实这个就是UI模块跟service模块的交互地址,如果不写或者你写错,你是登陆不进UI页面的,他找不到请求地址。。。血的教训啊【而且所有资料上都没写这个问题,独此一家】
7.编译griffin
①修改service中的pom.xml,将注释的mysql-connector-java释放开
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.java.version}</version>
</dependency>
②编译: mvn clean install -Dmaven.test.skip=true
8.启动
①在hadoop中创建路径:
hadoop fs -mkdir -p /griffin/persist
hadoop fs -mkdir /griffin/checkpoint注:这两个目录在env_streaming.json,env_batch.json文件中有用,保持一致就行了,官网上就这样
②重命名编译的包名
mv measure/target/measure-0.5.0.jar $GRIFFIN_HOME/griffin-measure.jar
mv service/target/service-0.5.0.jar $GRIFFIN_HOME/griffin-service.jar修改的包名是与你sparkProperties.json文件中的配置一致的,官网上就这样
③将编译好的measure包上传到HDFS
hadoop fs -put $GRIFFIN_HOME/griffin-measure.jar /griffin/③启动service模块
# 启动之前请确保Hive的 metastore 服务正常开启
nohup java -jar $GRIFFIN_HOME/griffin-service.jar>$GRIFFIN_HOME/service.out 2>&1 &
#启动之后我们可以查看启动日志,如果日志中没有错误,则启动成功
tail -f $GRIFFIN_HOME/service.out④启动UI模块
griffin-griffin-0.5.0/ui/angular/node_modules/.bin/ng serve -host 192.168.43.129注:启动时候置顶host,因为我在UI配置文件中修改了localhost却没有用。。。所以直接启动时候指定。
浏览器访问:
默认没有密码,是的一定没有密码,首页如下:
后期启动发现问题:
在livy中的日志发现如下warn:

定位问题是spark缺少配置:
① 设置spark-env.sh文件中的 export SPARK_LOCAL_IP=192.168.43.129 【添加上即可】
②用spark提交griffin的demo任务发现有如下问题:

定位问题是spark中缺少hive的配置,详见spark中配置hive环境:
https://blog.csdn.net/shijinxin3907837/article/details/103315696
好了,已完成,琢磨了好几天,我就奇怪了,为啥官网都没有启动UI那一块的讲解。。。
最后最后,如果您觉得本文章有用请进行友好评论,如果您有疑问请进行友好评论,如果您想沟通请进行友好评论。
如果可以的话请您进行打赏,一两个亿不嫌少。。。真的,比真金还真。














 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









