







url: https://www.bilibili.com/video/BV1du17YfE5G?vd_source=7a1a0bc74158c6993c7355c5490fc600&p=4&spm_id_from=333.788.videopod.sections
ISPC 性能分析
0~19min 复习了上堂课介绍的 ISPC 内容,其中比较重要的有:
ISPC 不会创造新的线程,只会基于 SIMD
此外,还有关于不同 ISPC 实现的性能分析,如下:
对比两种 ISPC 实现:
类型1:
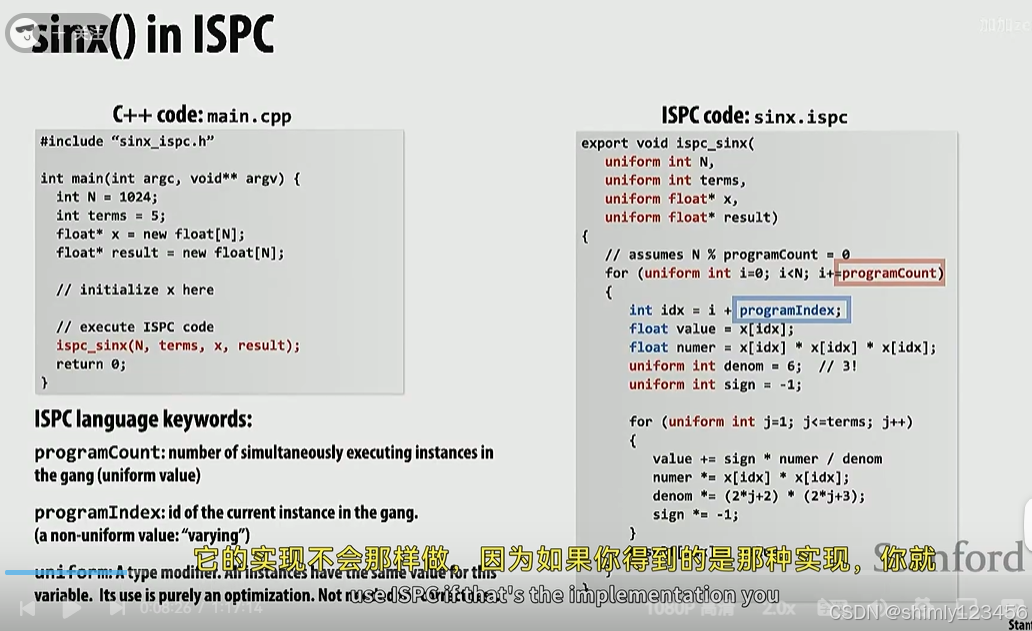
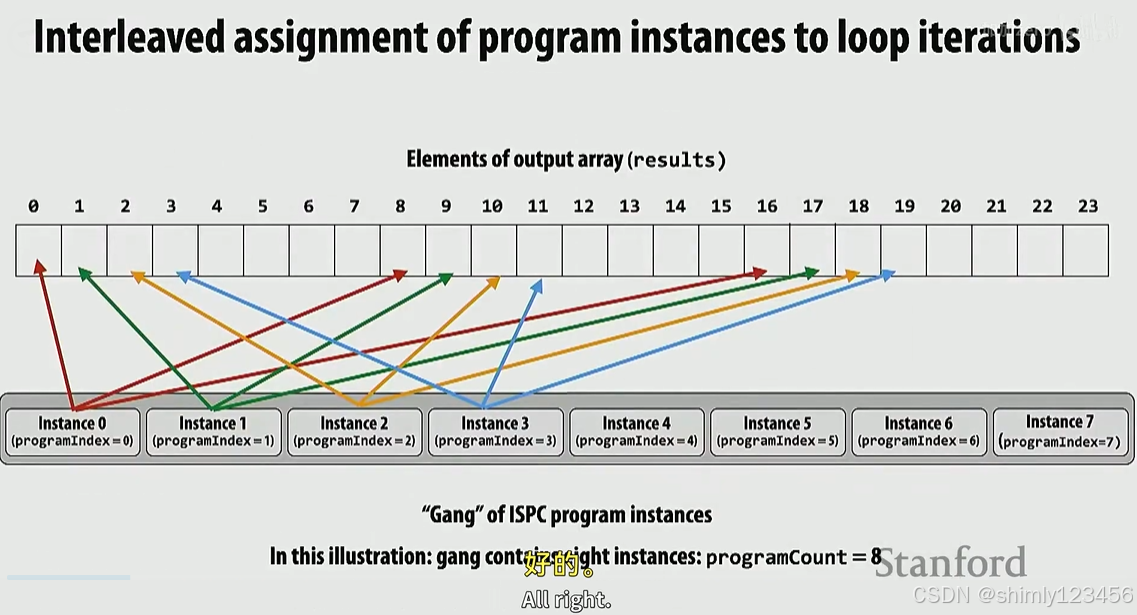
类型2:

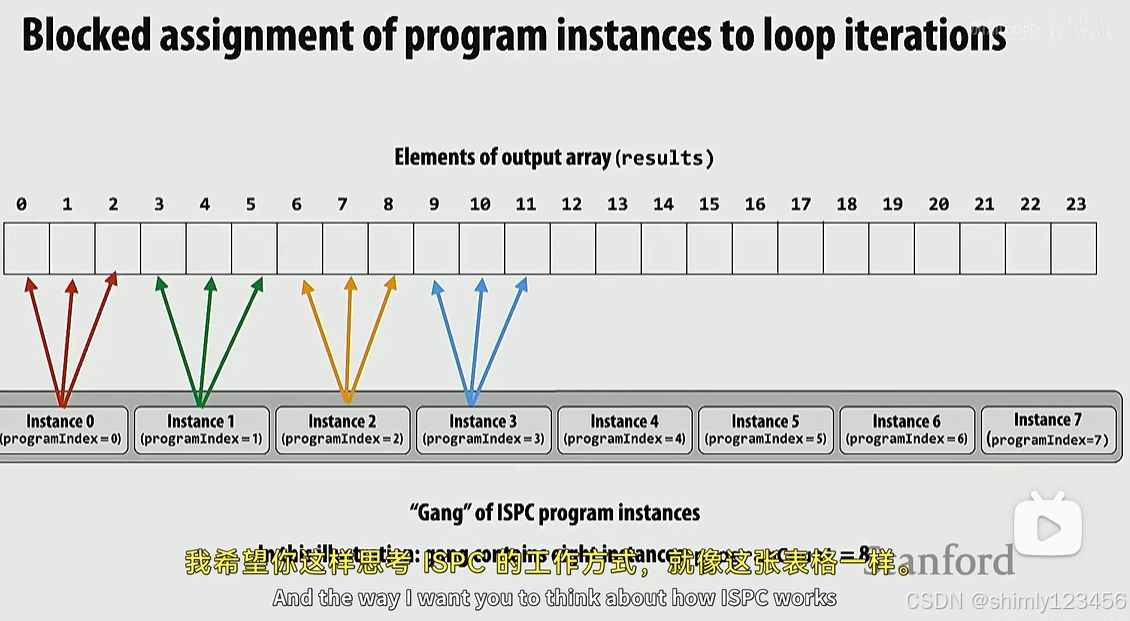
在上述两种 ISPC 类型中,类型1的性能更好,原因如下:
类型1的时间分析:

类型2的时间分析:

由上面可见,类型1在每个时刻访问的内存是连续、相邻的,可以存放在同一个 cache line 中,而类型2 在每个时刻访问的内存是分散的,很可能在多个 cache line 中。因此类型1效率更高。
ISPC 可能会写错
案例1:foreach内,不同迭代的计算是有依赖关系的,这在 openMP 中是很常见的错误

案例2:下面两个实现都会造成编译时错误

正确写法如下:

ISPC 是基于 SIMD 实现的。
目前为止关于 ISPC 的代码,都只在一个core上的一个线程执行。
ISPC 有零一个抽象 “task” 能够达成多核执行的目的。

记住,ISPC 是一种并行编程的抽象方式,但它的抽象实际上比较底层,你可以做一些自定义操作,比如之前提到的两种 ISPC 内部实现方式。高级语言如 numpy 往往不允许程序员做这种细节操作,矢量操作一般被封装到函数里了。
前面内容的总结

并行编程基础
操作系统的上下文切换只在 sleep,内存IO,磁盘IO中有意义。因为操作系统的上下文切换需要数十万周期,而内存IO往往只需要数百周期。CPU的 execution context 切换只需要一个周期。
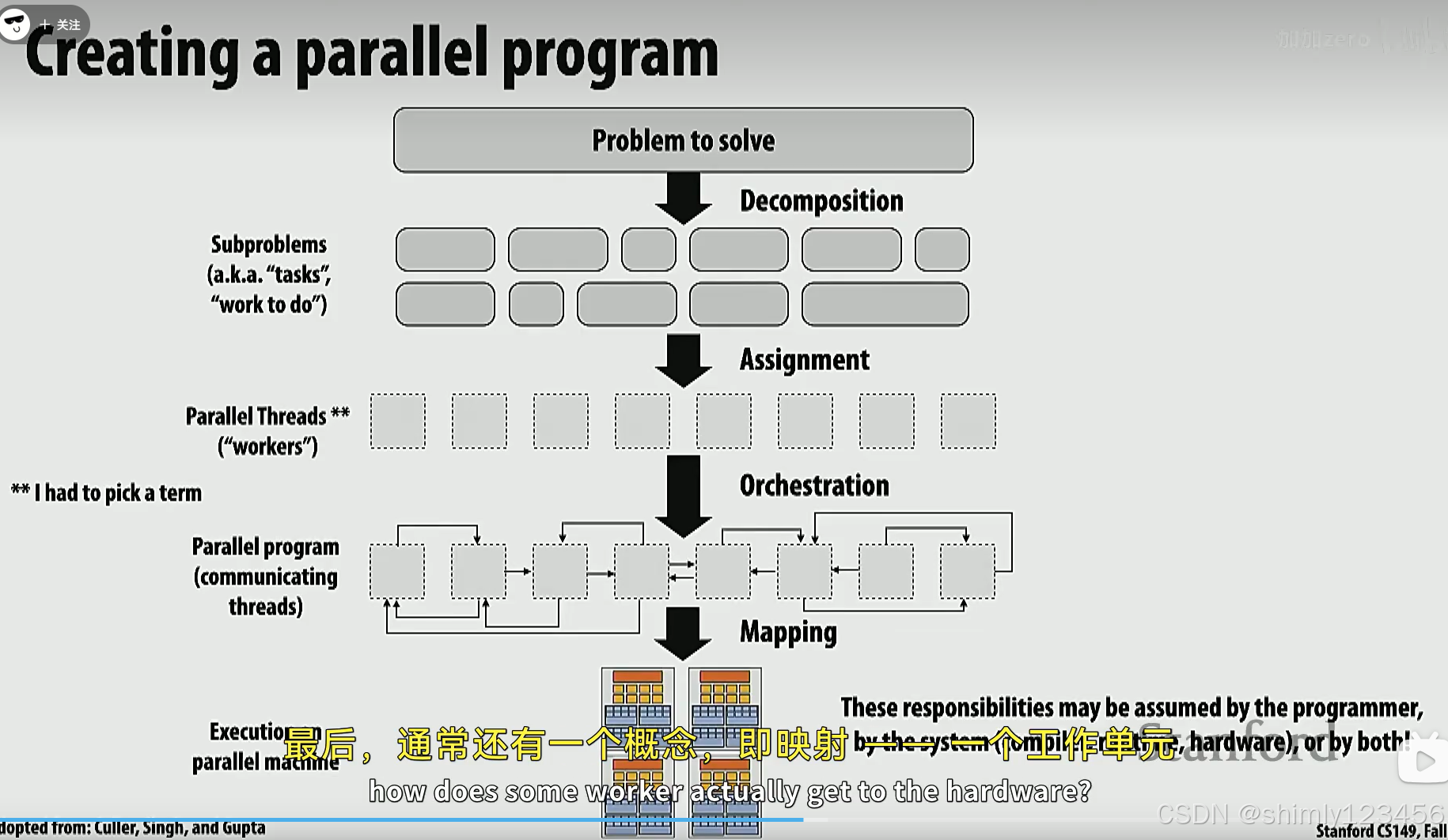
复习加速比公式,和并行编程的步骤

示意图,并行编程分为几步:
1.问题分解,分解为可并行的任务
2.为分解出的任务分配线程
3.线程之间会有通信,比如同步之类的
4.具体的任务映射到实际硬件上
问题分解
先来看问题分解
问题分解通常要求拆分出足够的任务来保证机器上的所有计算单元是忙碌的
这里有个主要的挑战:识别数据之间的依赖

程序中不能并行的部分会限制并行加速的效果
最大加速比 <= S
S = 程序耗时中,必定串行部分的耗时比例

下面是一个简单的分解任务例子。
step1 是一个非常容易并行的任务
step2 相对来说没有那么直观的并行方式

仅对 step1 并行时,
串行版本耗时 2N^2
并行版本耗时 N^2/P + N^2
当 P 无限增大时,加速比趋近于 2
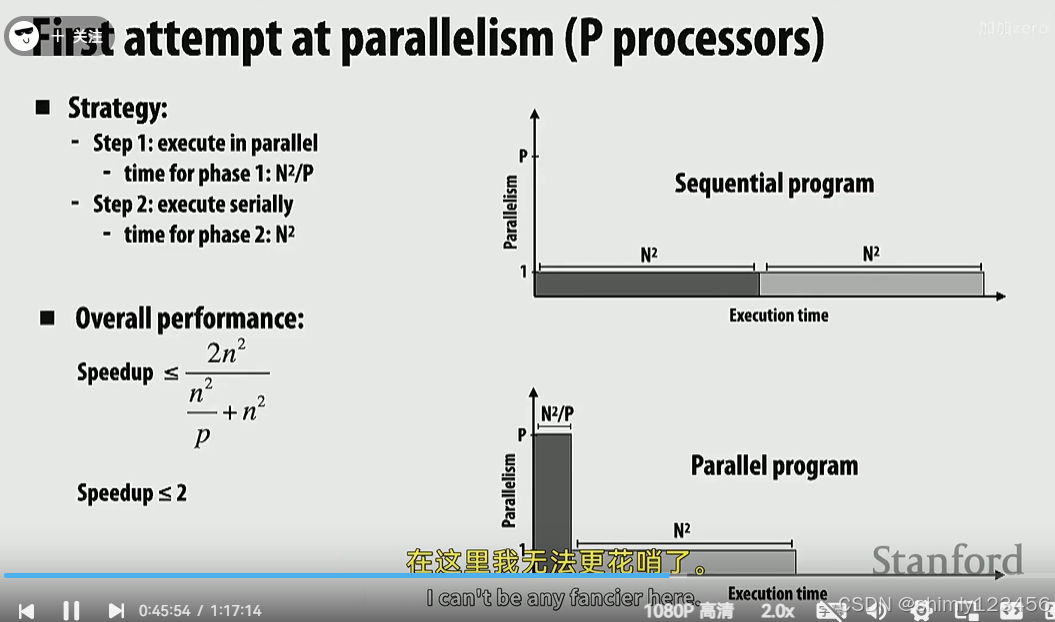
step2 可以通过部分和再总和的方式并行。
当 N >> P 时,加速比趋近于 P (分母的 + P 趋近于0,但分母的 /P 要保留下来)

如下图是 Amdahl 规律的示意图
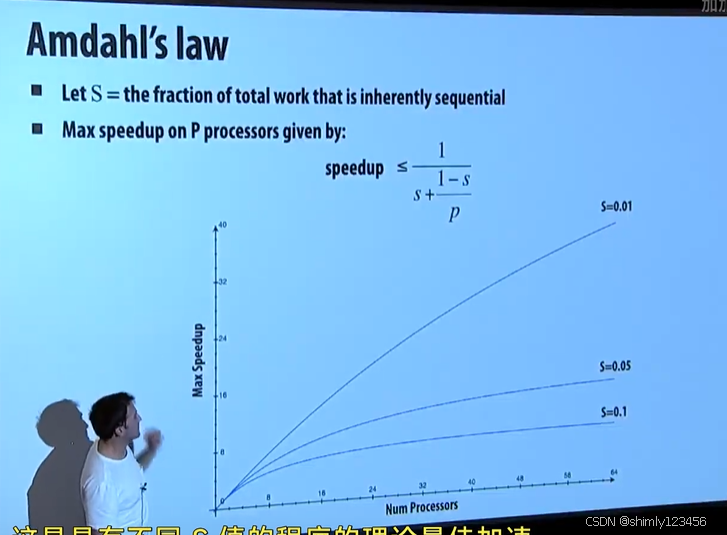
想象你在一个超级计算机上运行一个包含 0.1% 串行指令的代码,这里最大加速比不会超过 1000,无论超级计算机性能多高。

问题分解通常是程序员的活儿,目前还没有能够方便地自动分解任务的编译器,这玩意儿还没出来

任务分配
任务分配这一部分通常可以由编译器/运行时环境自动处理

下图左边的 ISPC 程序是由程序员分配任务,右边的程序是交由 ISPC 分配

任务分配可以由程序员静态分配,如下:

任务分配也可以由编译器 ISPC 动态分配,维护一个任务列表即可。

Orchestration 并行通信/协调
很简单,就是一些同步操作,也许是等待其它操作完成,也许是内存同步(所有之前的内存操作都必须在这一刻写入内存)。
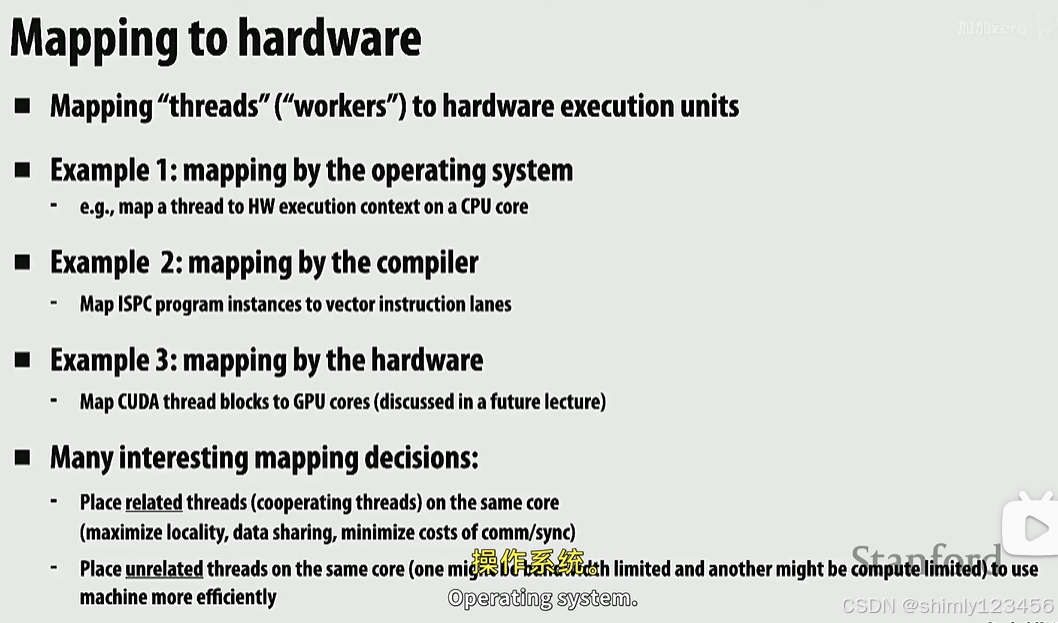
Mapping 映射
我们可以一定程度上决定并行程序在硬件上如何分配,比如:
1.操作系统可以把一个 thread 分配给一个具体的 CPU core
2.编译器可以把一些操作映射成一个 SIMD 指令,或者说把一个 ISPC program instance 映射到一个矢量指令通道
3.CUDA 编程,把任务分配给 GPU
4.可以把关联性强的线程分配到同一个 CPU core 来利用 CPU core 的 cache;或者把计算密集和IO密集的任务分配到同一个 CPU core 上。
一个并行编程例子
以二维网格求解器为例:
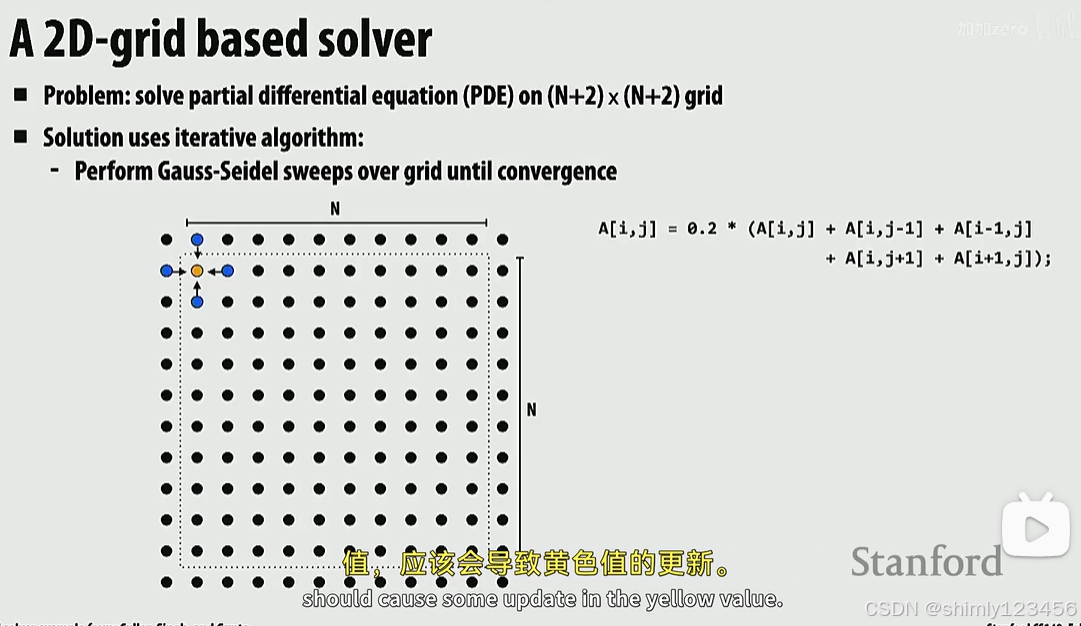
如下代码,我们要从左上到右下更新每个网格的某些值。
那么,此时下面的代码能并行吗?
它们存在着许多依赖:每一个网格的值的依赖于它的上下左右四个网格,这导致并行难以展开

当然,上面的问题仍然可并行,只要我们按照对角线划分所有网格。
每条对角线上的网格的计算是互相之间独立的,这意味着多个 CPU cores 可以在对角线上的网格做并行。做完一条对角线上的计算再切换到下一条对角线。
但是这里涉及到许多同步通信,代码也很难写,哪怕代码写对了性能大概率也不会更好,所以这种方式不好。

通常来说,如果一种算法很难并行,我们会考虑换一种并行友好的算法。
第二种算法:棋盘法。
先计算红点、再计算黑点,重复,直到数据收敛。
这里我们不关心具体的数学原理,但我们 assert 棋盘法和之前的算法最终会收敛到一样的值
棋盘法相比之前的算法可能需要更多的迭代次数才能收敛,但它是并行友好的。

使用棋盘法时,如何划分任务是个问题。
想象在多核处理器上,每个 core 划分到一大块连续的内存。那么在计算区域临界的点时,各个core之间需要的通信就相对少:P2 在计算临界黑点之前要等待P1 和 P3 的红点计算完毕。如果是块状分配,它可以先计算非临界区域内的黑点。

使用框架编程时,程序员通常不关心任务的分配,我们只关心任务的分解,如下图:
程序员给出了红点、黑点的任务分解,随后使用一个 “for_all” 告诉编译器循环内的任务是可并行的
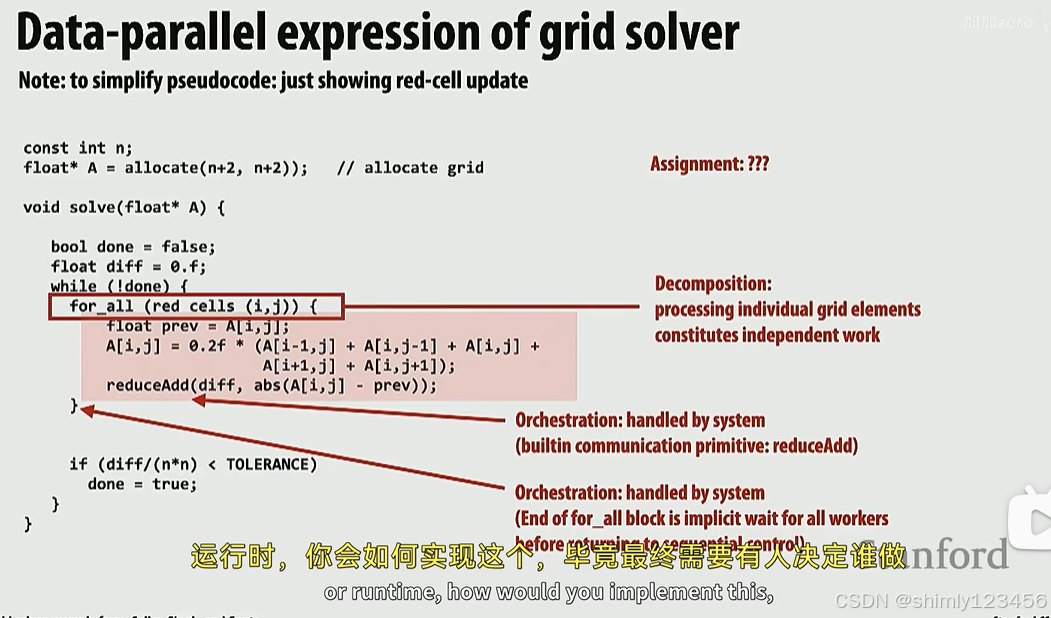
为了让不同 program instance 之间能通信、同步。
通常会使用两个原语:锁、屏障
其实还有内存屏障 (等待所有内存读写操作真正写入到内存里)

需要锁的原因:
一个变量的更新实际上分为三步:
1.load the value to register
2.update register
3.write back the value to memory
这个过程是可以被打断的,如下图的 race condition 就是个例子

但锁会降低性能,所以比较好的方式是,使用私有副本去掉锁。
最后在统合结果的时候才使用锁,降低锁的使用频率,如下:

下图分别使用了三个 barrier,分别用于:
1.保证 diff 初始化完成
2.保证 diff 计算完成
3.保证 diff 逻辑判断完成
这个实现实际上是可以简化的,不要太在乎不理解的部分



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









