









 本文介绍了图在数据结构中的两种表示方式:邻接矩阵和邻接链表,并详细讲解了无向图的邻接矩阵优化。此外,还讨论了图的遍历,包括广度优先搜索(BFS)和深度优先搜索(DFS),并提供了这两种搜索算法的伪代码。最后,提到了图的连通性问题以及如何列出连通集。
本文介绍了图在数据结构中的两种表示方式:邻接矩阵和邻接链表,并详细讲解了无向图的邻接矩阵优化。此外,还讨论了图的遍历,包括广度优先搜索(BFS)和深度优先搜索(DFS),并提供了这两种搜索算法的伪代码。最后,提到了图的连通性问题以及如何列出连通集。
图的表示
图(Graph)是由顶点(Vertex)和边(Edge)构成的一种集合,及 G=(V,E) ,图在数据结构中有两种表示方式:邻接矩阵和邻接链表
邻接矩阵
对于图
G=(V,E)
的邻接矩阵的表示方式,通常是将图G的节点编为
0,1,2,3,...,|V−1|
,这种编号是任意的也可以从1开始进行编号,那么G的邻接矩阵表示由一个
|V|×|V|
的矩阵
A=(aij)
,其满足
aij={10如果e(i, j) ∈ E其他
因此,不管图有多少条边,邻接矩阵的空间需求都为
Θ(V2)
注意:一般将
aij=1
替换成
aij
=weights及顶点
vi
到顶点
vj
的权重
无向图的邻接矩阵
对于无向图,由于顶点
vi
到顶点
vj
与顶点
vj
到顶点
vi
是一样的,因此
A
是一个对称矩阵及
对于无向图用一个长度为
|V|×(|V|+1)2
的一维矩阵
A
存储
i×(i+1)2+j
邻接链表
对于图
G=(V,E)
的邻接矩阵表示为有一个包含
|V|
条的链表数组
Adj
所构成,每一个节点都有一条链表,对于每个节点
u∈V
,邻接链表
Adj[u]
包含所有与节点
u
之间有边相连接的节点
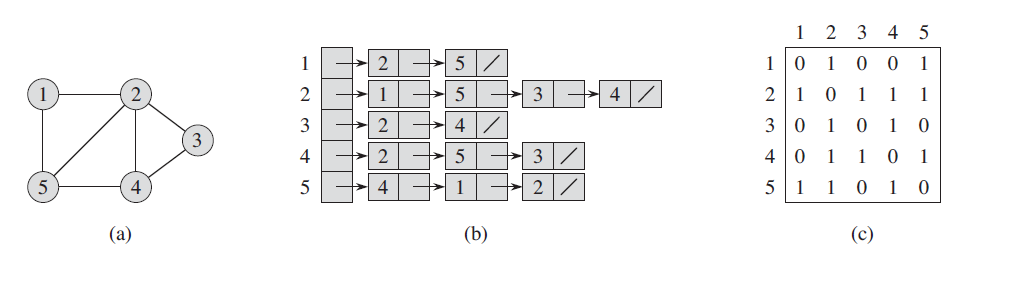
图中(a)表示一个图,(b)表示图的邻接链表的表示方法,(c)为邻接矩阵的表示方法
邻接矩阵 Vs 邻接链表
- 邻接矩阵
- 简单,直观,容易理解
- 很容易判断任意两个定点之间是否右边
- 很容易计算任意顶点的邻接顶点
- 容易计算任意顶点的度
- 但是对于稀疏图 (边的条数
|E| 远远小于 |V|2 ) 来说浪费存储空间- 邻接链表
- 很容易计算任意顶点的邻接顶点
- 节约稀疏图的存储空间
图的遍历
广度优先搜索(Breadth First Search, BFS)
广度优先搜索是最简单的图搜索算法之一,其思想是给定一个开始搜索的顶点s,首先搜索所有与s直接相连接的顶点,然后从在s直接先连接的顶点中选着一个顶点作为s继续搜索直到所有的节点都搜索完成。
例如:对于上图的广度优先搜索为:如果给定顶点1作为开始搜索顶点,那么广度优先首先搜索顶点2和5并且把2和5标记为已经访问。然后在以2为开始搜索顶点,搜索所有与2直接连接的顶点3和4(因为1和5都已经标记为搜索了),此时图中所有的元素都已经被标记了那么结束搜索。
其伪代码为://给定图G和开始搜索节点s BFS(Grahp G, Vertex s) { queue Q; //创建一个队列Q visited[s] = true; //标记该顶点 Q.push(s); //把该顶点入队列 while (!Q.isEmpty()) { //如果队列不为空 s = Q.front(); Q.pop(); // for (每一个s的邻接顶点 v) { //s所有的邻接定点 if (!visited[v]) { //如果该顶点没有被访问 visited[v] = true; Q.push(v) } } // for } //while }深度优先搜索(Depth First Search, DFS)
深度优先搜索总是对最近才发现的顶点v的出发的边进行搜索,直到该节点的所有出发边都被发现为止。一旦顶点v的所有出发边都被发现,搜索则回溯到v的前驱顶点,来搜索该前驱顶点出发的边。该过程一直持续到所有的顶点都被发现了为止。
其伪代码为://深度优先搜索 DFS(Graph G, Vertex v) { visited[v] = true; for (v 的每个连接顶点 u) { if (!visited[u]) { DFS(G, u); } } }图的连通性
样例:列出连通集
给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集。假设顶点从0到N−1编号。进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。
输入格式:
输入第1行给出2个整数N( 0<N≤10 )和E,分别是图的顶点数和边数。随后E行,每行给出一条边的两个端点。每行中的数字之间用1空格分隔
输出格式:
按照” v1,v2,...,vk ”的格式,每行输出一个连通集。先输出DFS的结果,再输出BFS的结果。
输入样例:
8 6
0 7
0 1
2 0
4 1
2 4
3 5
输出样例:
{ 0 1 4 2 7 }
{ 3 5 }
{ 6 }
{ 0 1 2 7 4 }
{ 3 5 }
{ 6 }#include<iostream> #include<vector> #include<queue> using namespace std; int getIndex(int i, int j) { return i >= j ? i*(i+1)/2 + j : j*(j+1)/2 + i; } vector<int> buildGraph(int V, int E) { //vector<vector<int>> adj(V, vector<int>(V, 0)); vector<int> adj(V*(V+1)/2, 0); int v1, v2; while(E--) { cin >> v1 >> v2; //adj[v1][v2] = adj[v2][v1] = 1; adj[getIndex(v1, v2)] = 1; } return adj; } //void dfs(vector<vector<int>> G, int v, vector<bool> &visit) void dfs(vector<int> G, int V, int s, vector<bool> &visit) { visit[s] = true; cout << " " << s ; for (int i = 0; i < V; ++i) { if (G[getIndex(s, i)] && !visit[i]) { dfs(G, V, i, visit); } } } //void bfs(vector<vector<int>> G, int v, vector<bool> &visit) void bfs(vector<int> G, int V, int s, vector<bool> &visit) { queue<int> Q; visit[s] = true; Q.push(s); cout << " " << s; while (!Q.empty()) { int v = Q.front(); Q.pop(); for (int i = 0; i < V; ++i) { // if (G[v][i] && !visit[i]) { if (G[getIndex(v, i)] && !visit[i]){ cout << " " << i; visit[i] = true; Q.push(i); } } } } void listComponets(vector<int> G, int V) { vector<bool> visit(V, false); //创建一个一维数组用于图的搜索 //深度优先搜索 for (int i = 0; i < V; ++i) { if (!visit[i]) { cout << "{"; dfs(G, V, i, visit); cout <<" }"<< endl; } } //广度优先搜索 visit.assign(V, false); for (int i = 0; i < V; ++i) { if (!visit[i]) { cout << "{"; bfs(G, V, i, visit); cout << " }" << endl; } } } int main() { int V, E; // 图的顶点数和变数 cin >> V >> E; auto adj = buildGraph(V, E); listComponets(adj, V); return 0; }以上资料来自:《算法导论》和 数据结构(陈越、何钦铭)
- 邻接链表
















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









