







最近打算学习一下java的开源搜索引擎Lucene,这一系列会记录下自己的学习过程,有不对的地方请多多指教。
介绍(来自于百度百科)
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
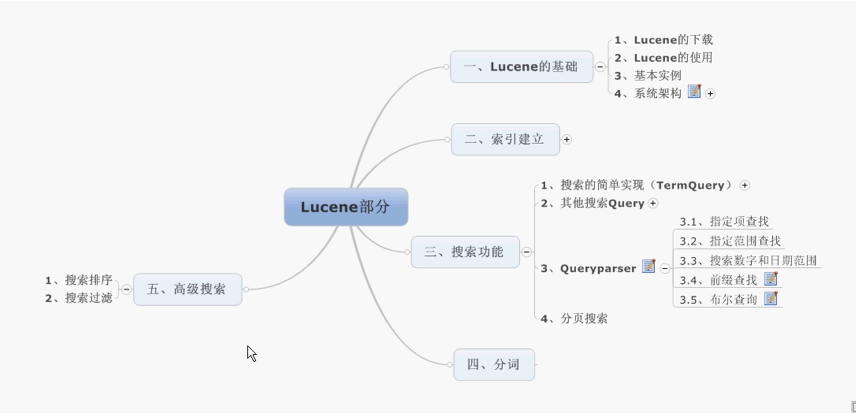
限于学习资源,我用的是Lucene 3.5.0。
一、创建索引初步
创建索引的几个基本步骤:
1、创建Directory
2、创建IndexWriter
3、创建Document
4、为Document添加Field
5、通过IndexWriter添加文档到索引中
初步创建搜索的步骤:
1、创建Directory
2、创建IndexReader
3、根据IndexReader创建IndexSearcher
4、创建搜索的Query
5、根据searcher搜索并且返回TopDocs
6、更具TopDocs获取ScoreDoc对象
7、根据Searcher和ScoreDoc对象获取具体的Document对象
8、根据Document对象获取需要的值
直接写代码吧。首先建立一个java project,所需要的架包是lucene-core-3.5.0.jar、junit-4.7.jar和commons-io-2.1.jar(IO工具包)。
public class HelloLucene {
IndexWriter writer = null;
Directory directory = null;
public void index() {
try {
directory = FSDirectory.open(new File("E:\\lucene\\index01"));//磁盘建立索引目录
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_35,
new StandardAnalyzer(Version.LUCENE_35));//Version.LUCENE_35是版本号
writer = new IndexWriter(directory, iwc);
Document doc = null;
File f = new File("E:\\lucene\\example");//本地文件
for (File file : f.listFiles()) {
doc = new Document();
doc.add(new Field("content", new FileReader(file)));
doc.add(new Field("filename", file.getName(), Field.Store.YES,
Field.Index.NOT_ANALYZED));
doc.add(new Field("path", file.getPath(), Field.Store.YES,
Field.Index.NOT_ANALYZED));
writer.addDocument(doc);//将文档写入索引
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (writer != null)
writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void searcher() {
try {
directory = FSDirectory.open(new File("E:\\lucene\\index01"));
IndexReader reader = IndexReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser(Version.LUCENE_35, "content",
new StandardAnalyzer(Version.LUCENE_35)); //查询“content”域
Query query = parser.parse("java");//查询“java”
TopDocs topDocs = searcher.search(query, 10);//最多显示10条
ScoreDoc scoreDocs[] = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println(doc.get("filename") + "[" + doc.get("path")
+ "]");
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
}测试类使用Junit:
package org.itat.index;
import org.junit.Test;
public class TestLucene {
@Test
public void testIndex(){
HelloLucene lucene = new HelloLucene();
lucene.index(); //索引
}
@Test
public void testSearcher(){
HelloLucene lucene = new HelloLucene();
lucene.searcher(); //搜索
}
}
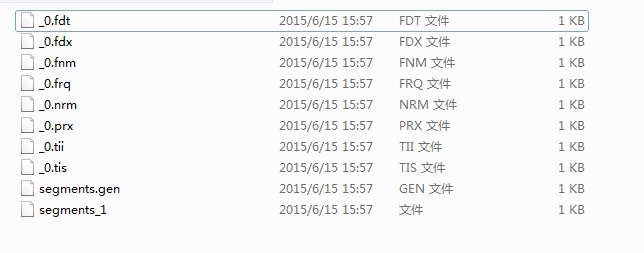
一步一步继续学习。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









